Download as PDF, PPTX


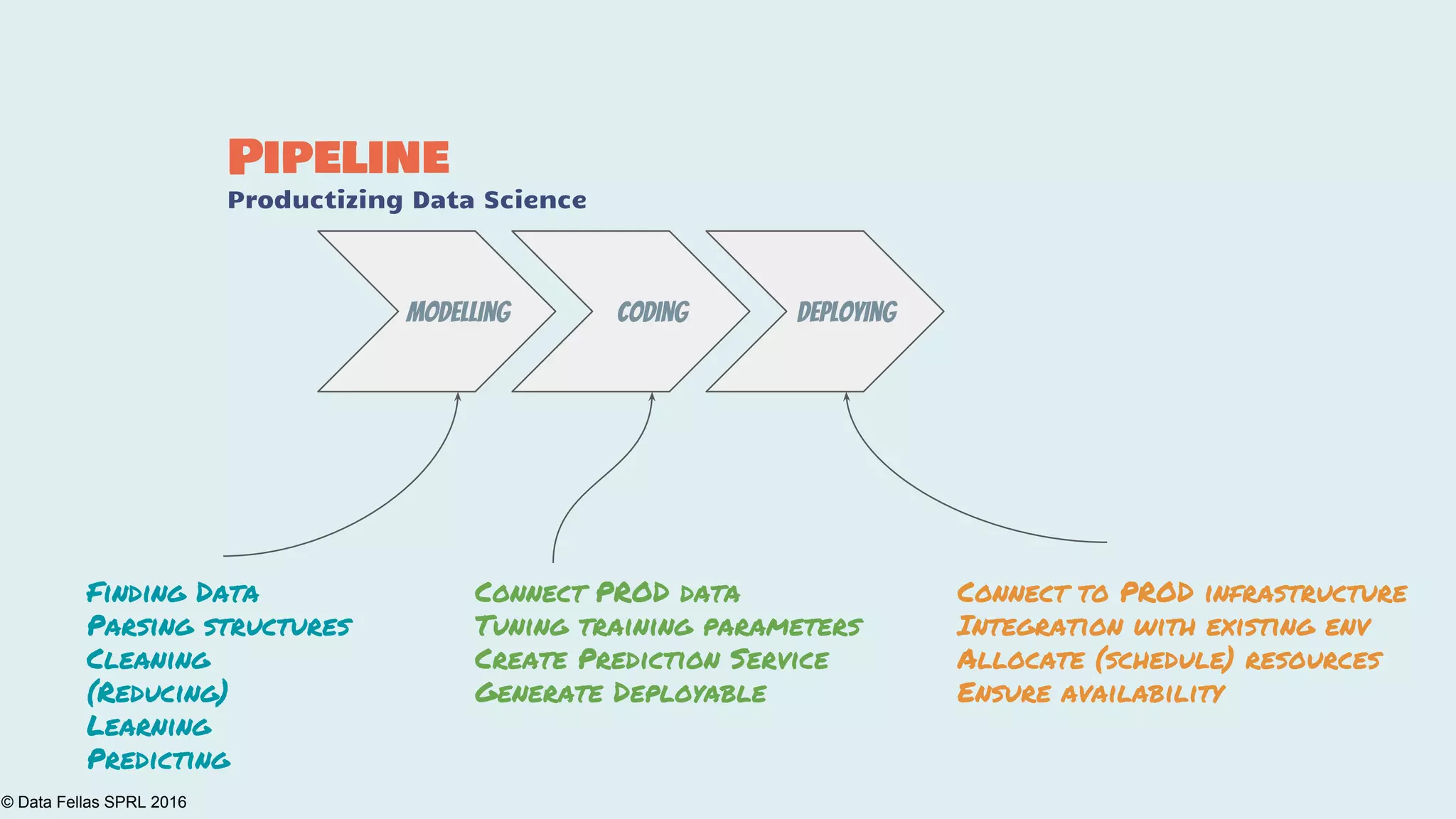


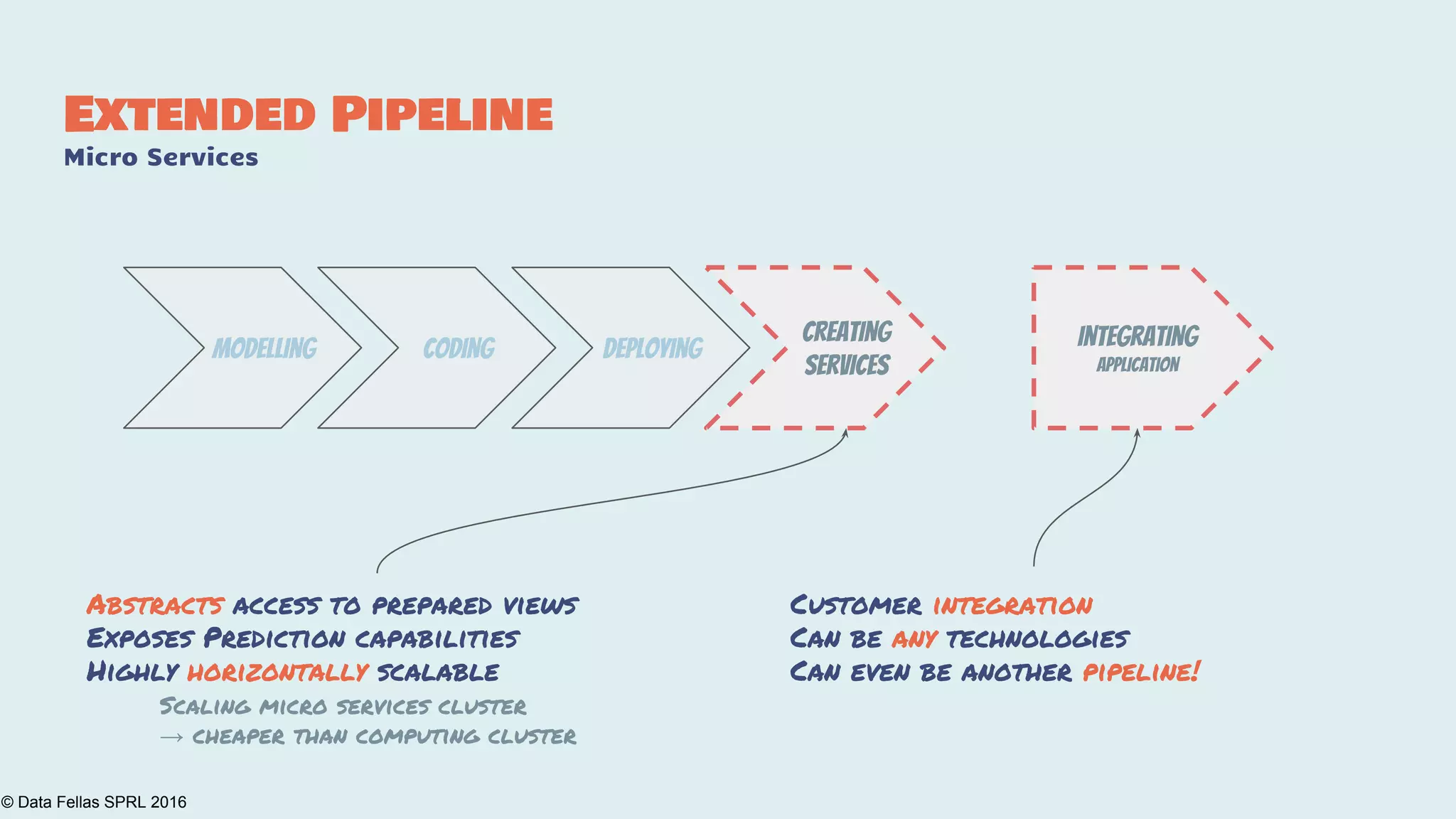
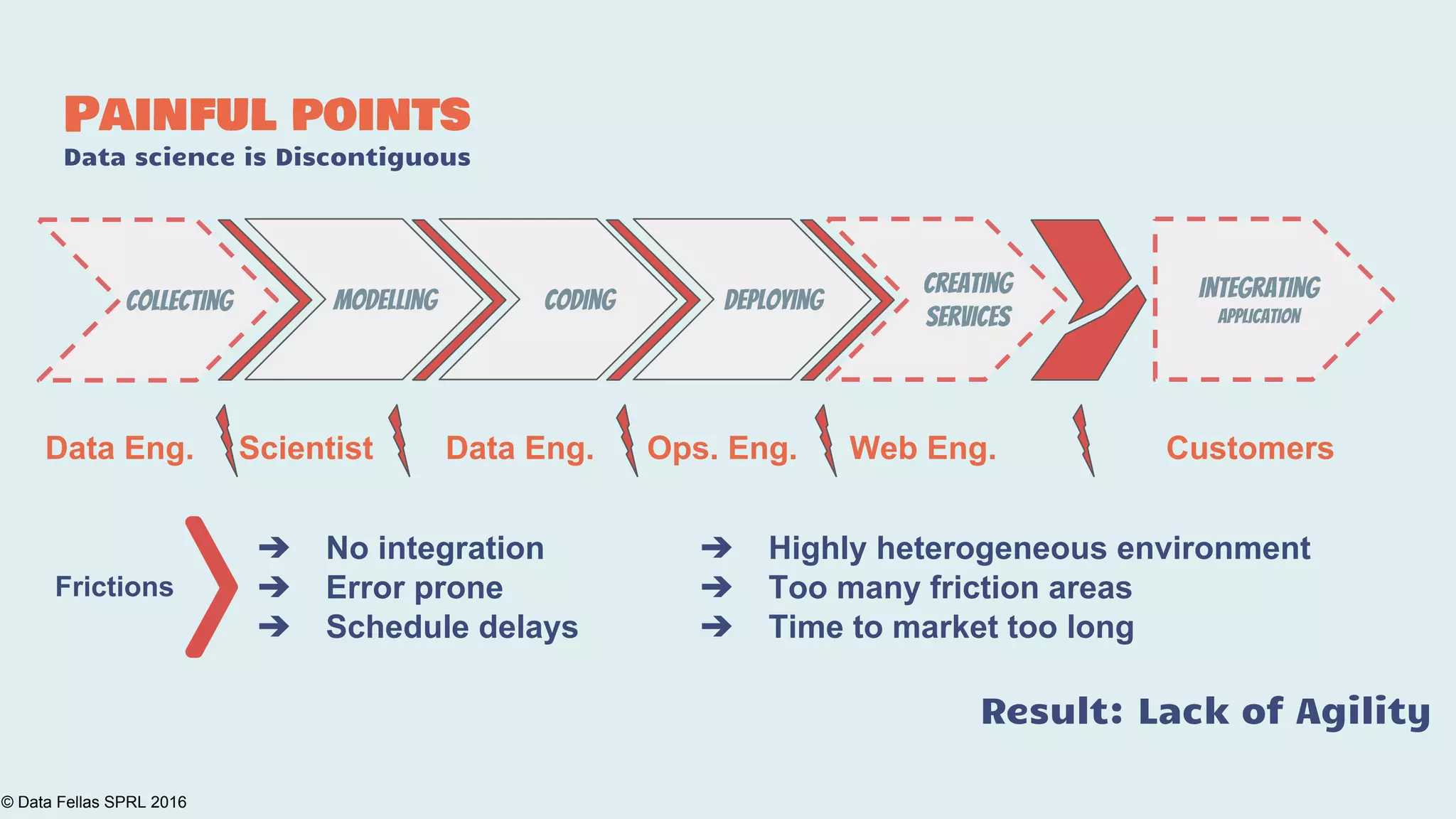
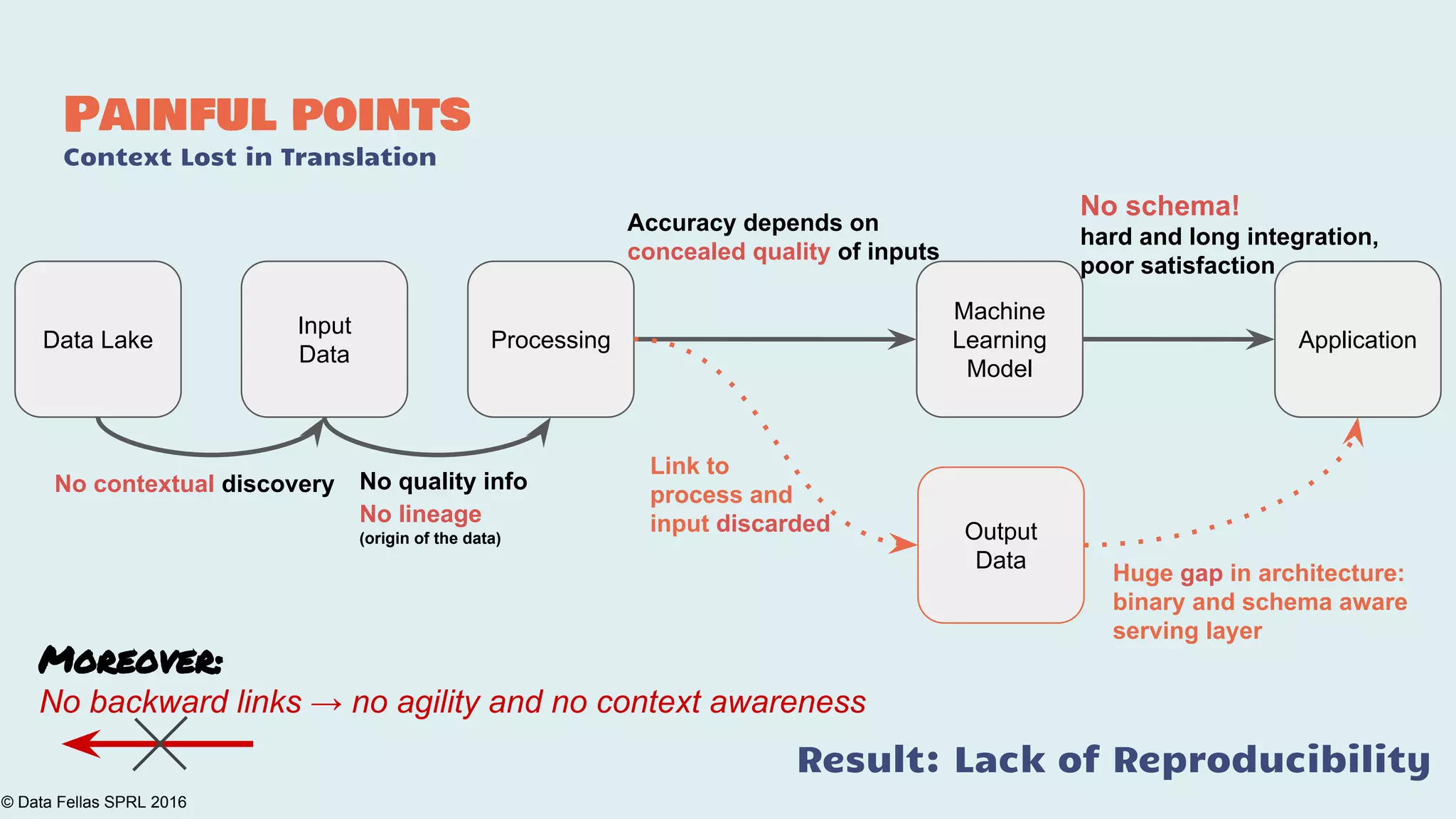

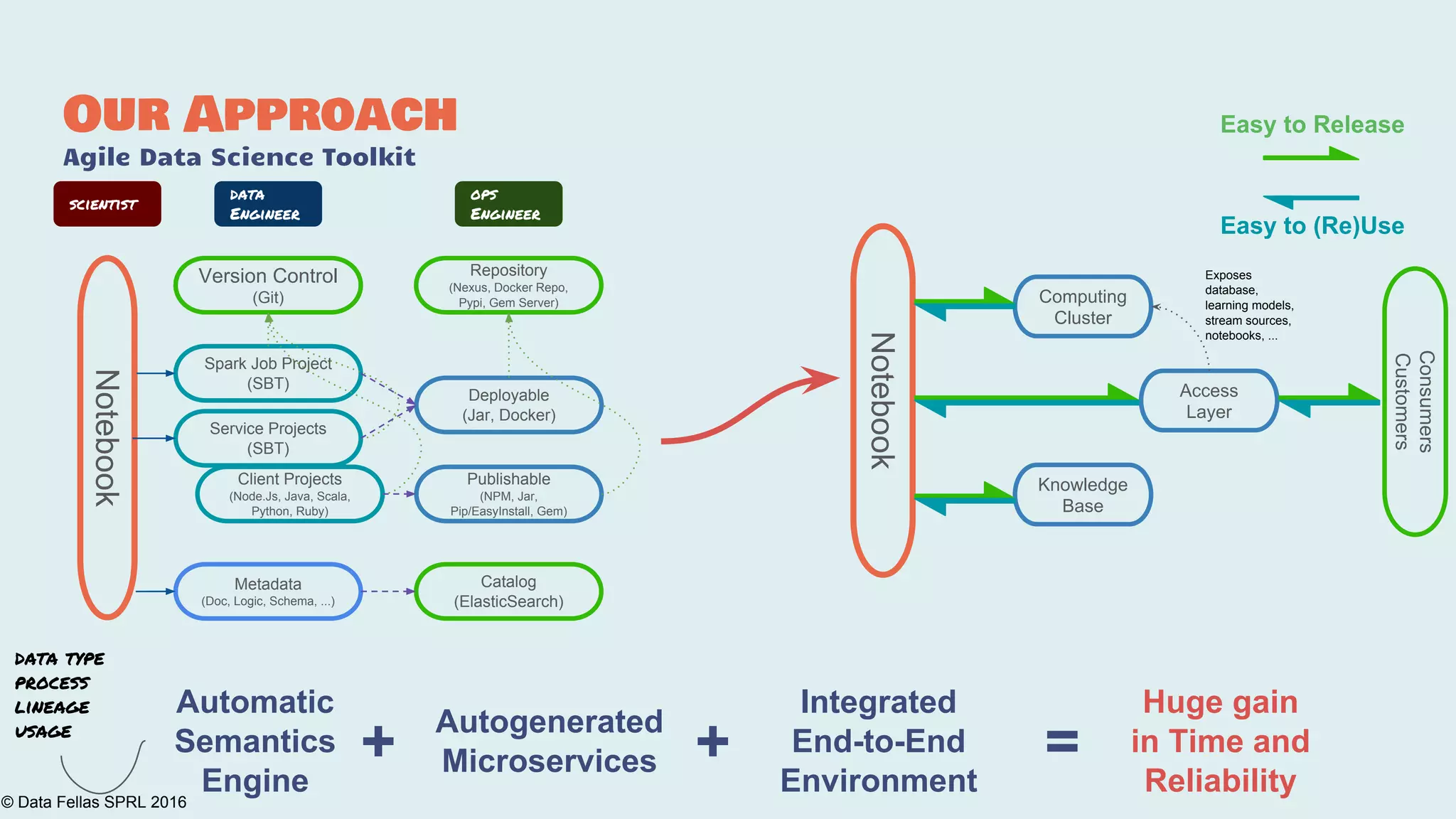
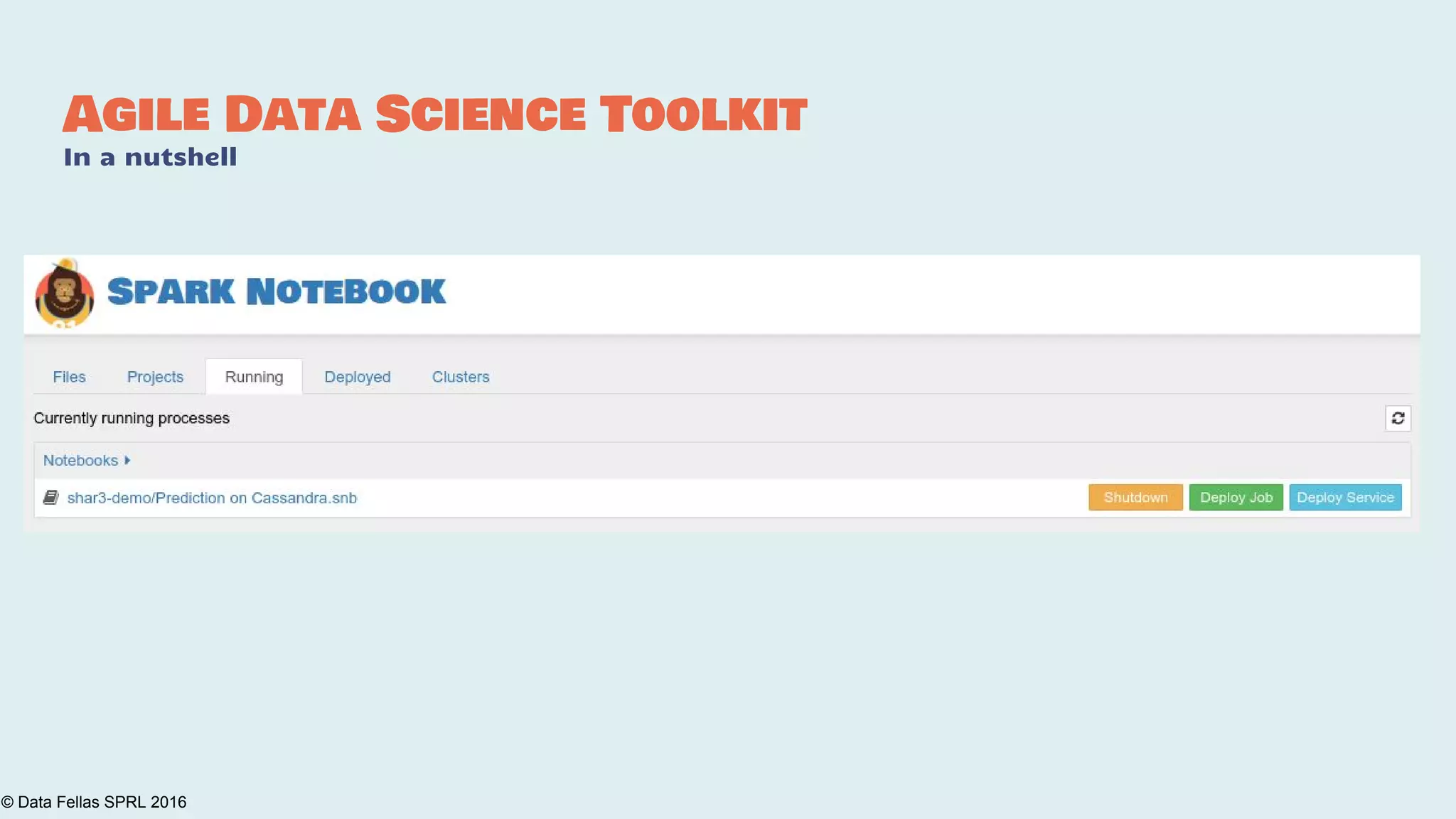
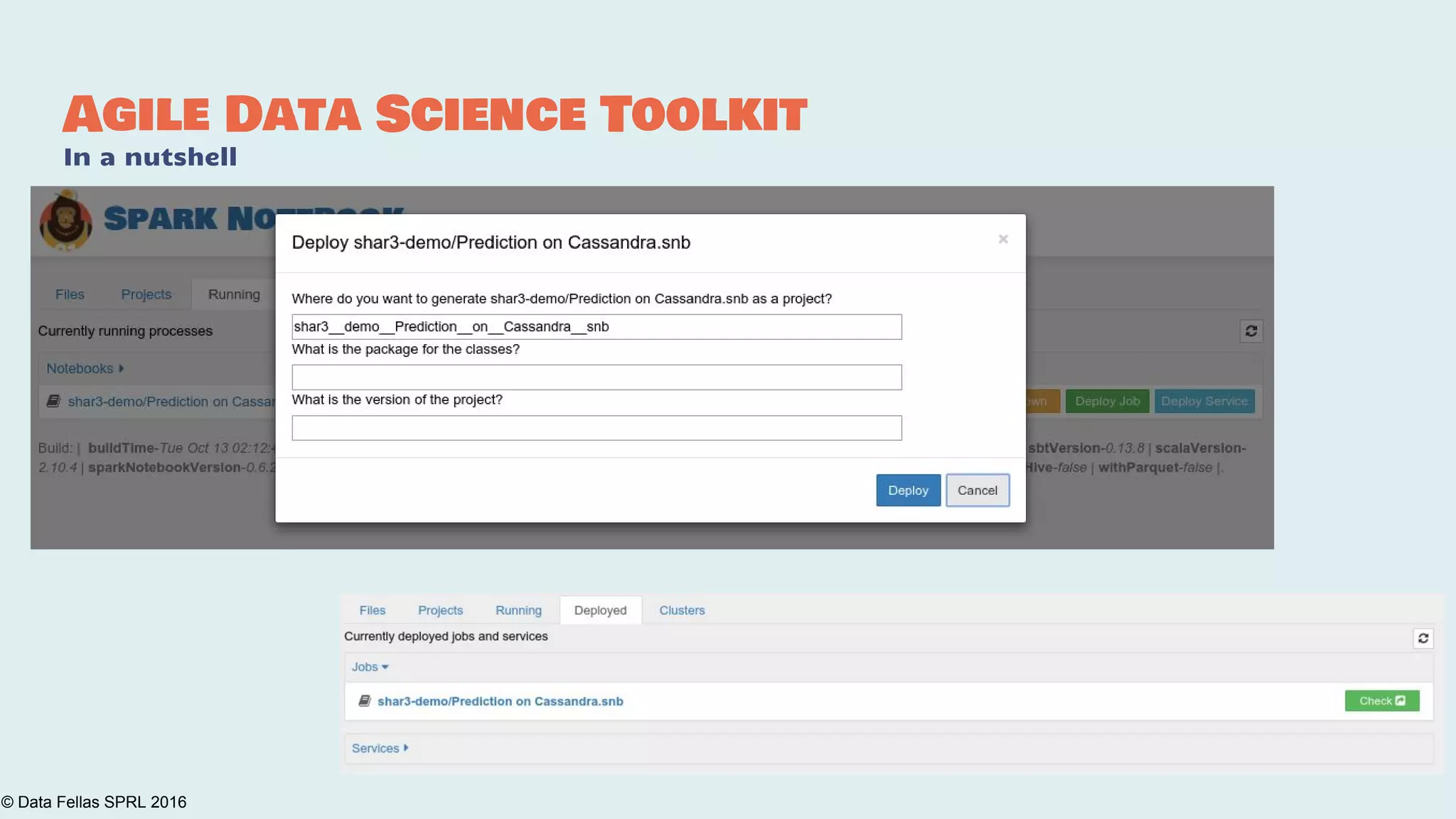
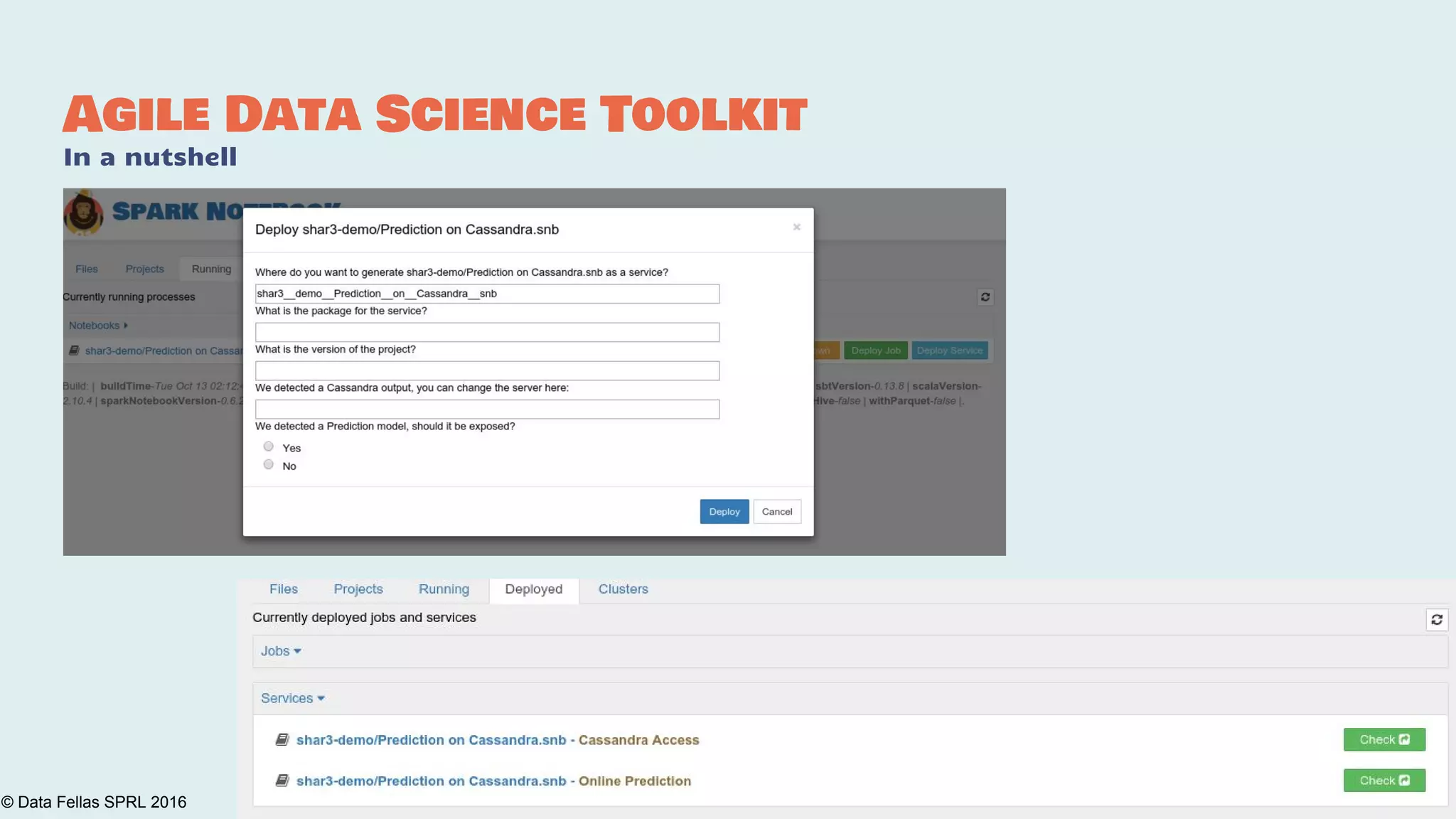
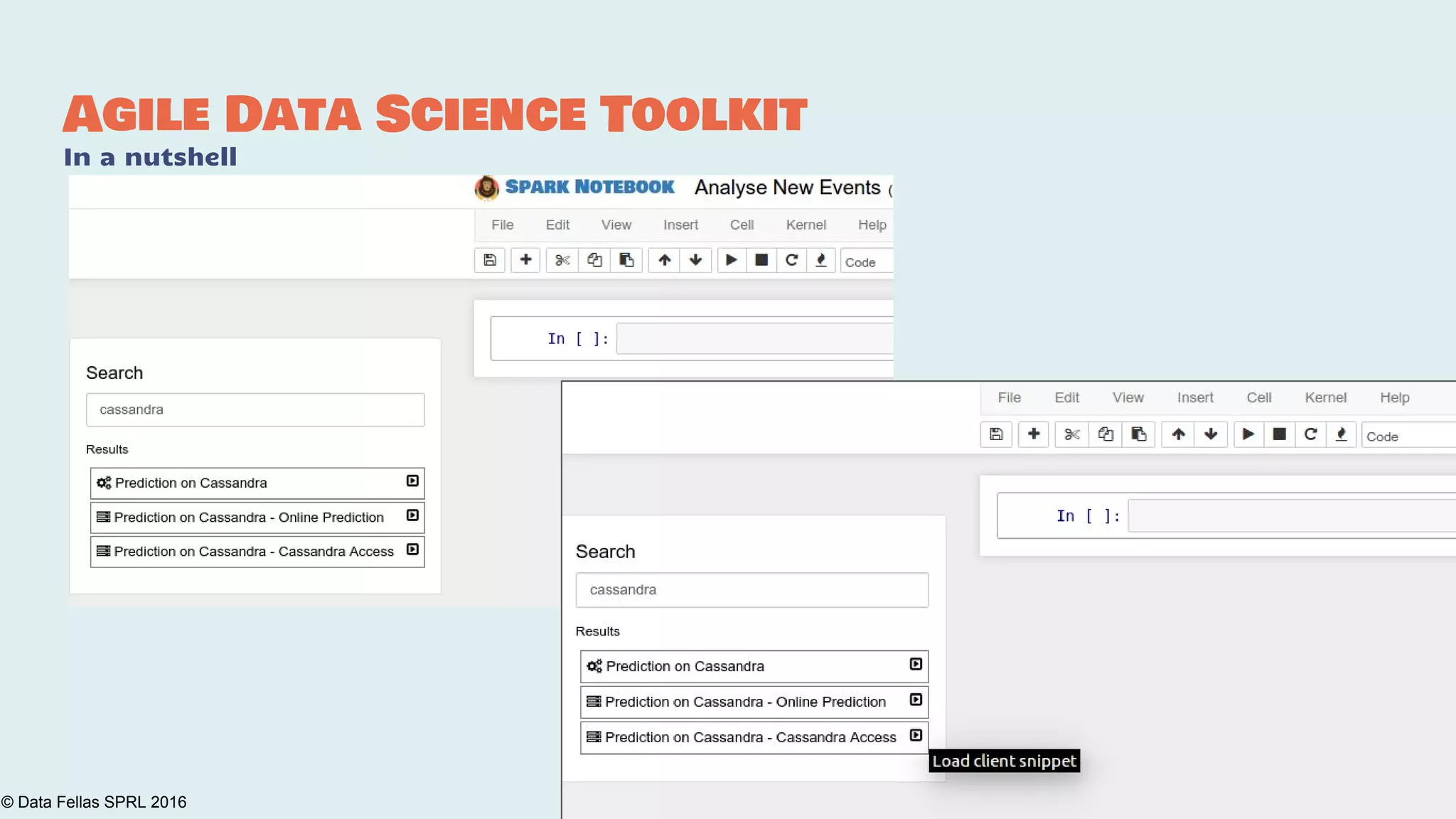
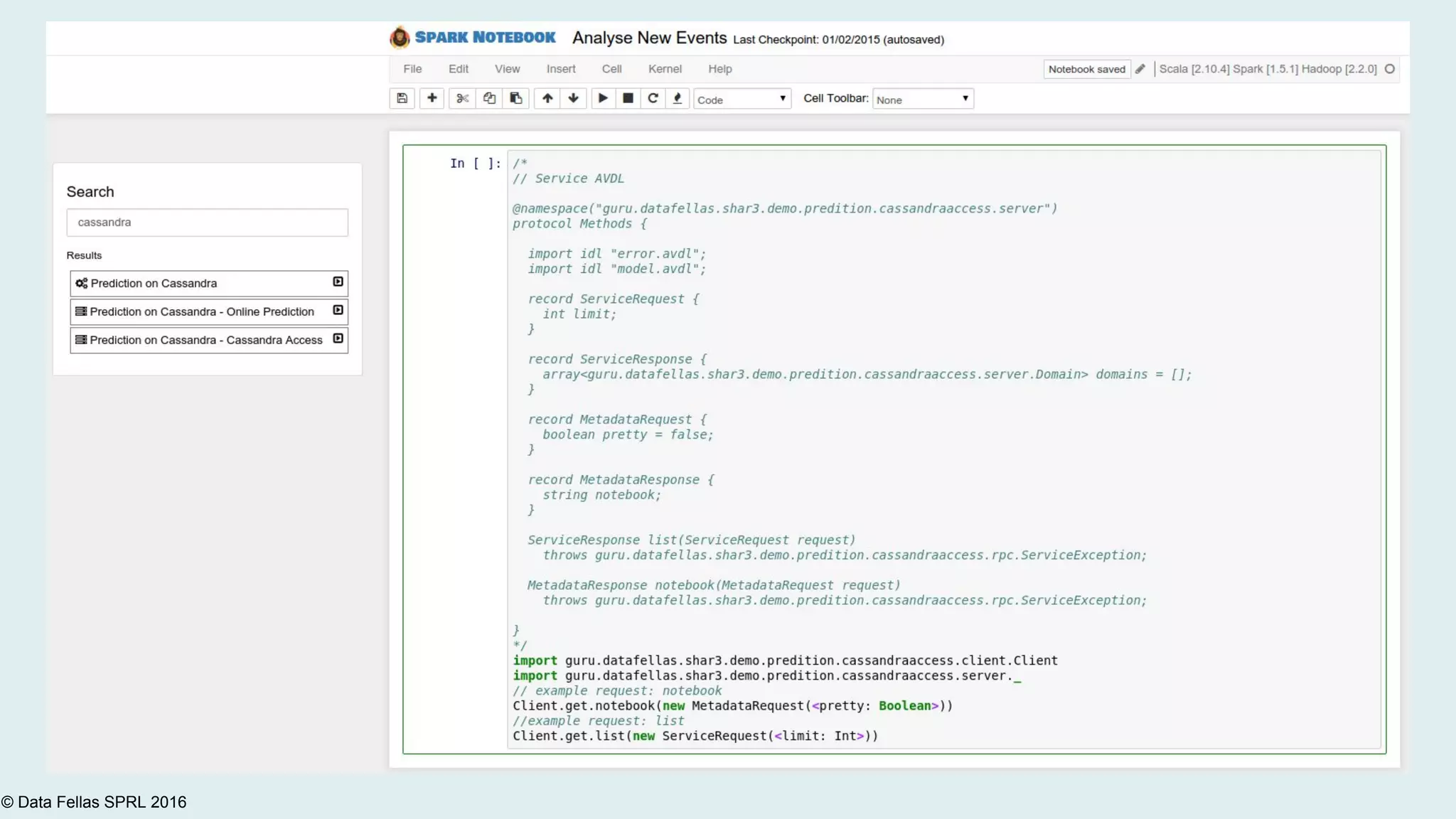






The document discusses the Agile Data Science Toolkit by Data Fellas, aimed at addressing common challenges in data science processes. It outlines the integration of various components like microservices, Spark, and Kafka to create an efficient data pipeline that enhances reliability and accelerates time to market. The toolkit also emphasizes the significance of context and lineage in data handling to improve output quality and reproducibility.