Downloaded 53 times




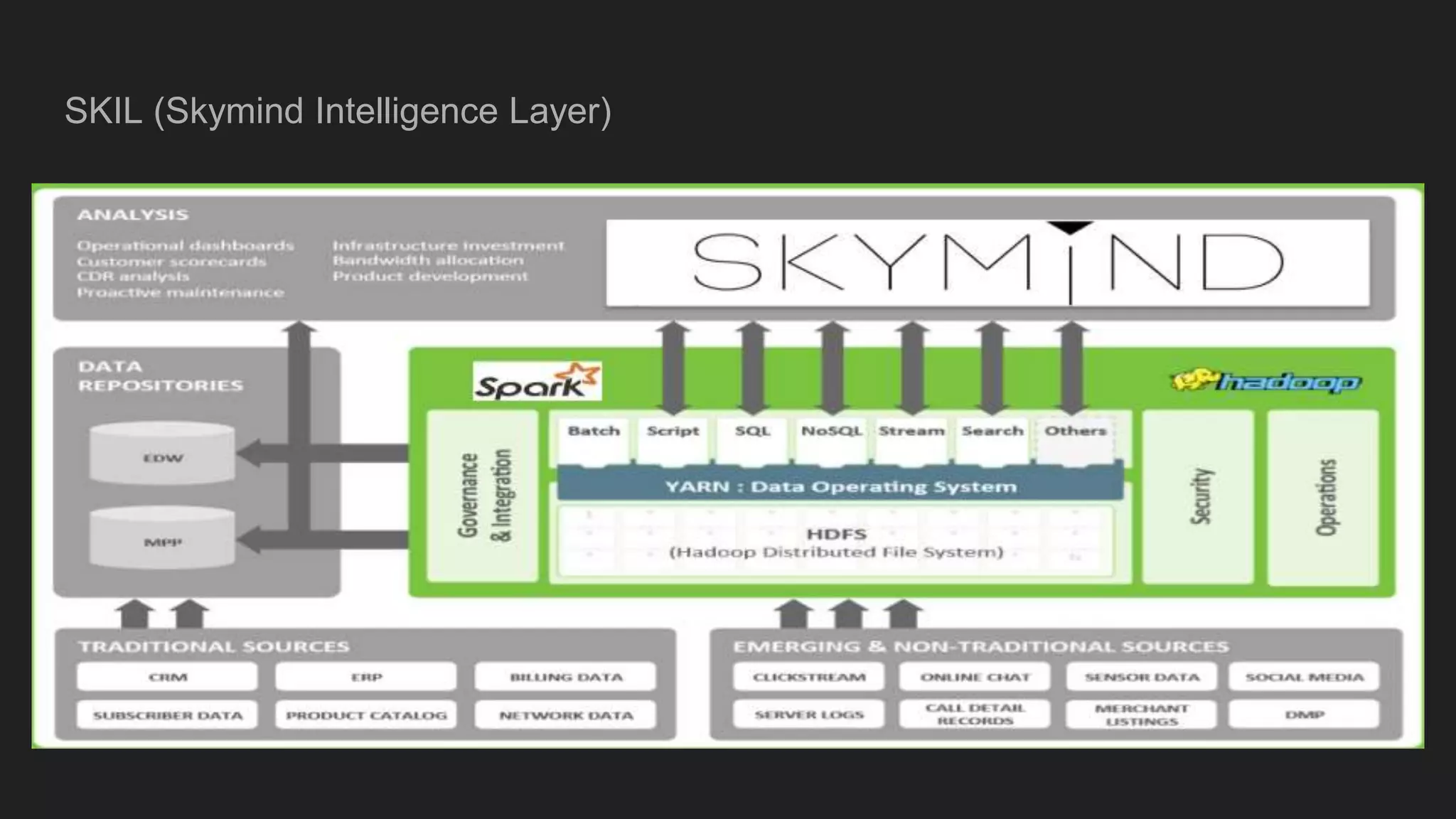








This document discusses DeepLeanring4j, a framework for data parallel deep learning on Spark. It provides an overview of the current landscape of deep learning tools, and proposes a solution using Javacpp, libnd4j, and SKIL (Skymind Intelligence Layer) to leverage Spark and the JVM ecosystem while allowing for heterogeneous compute. Key aspects include efficient access to image and audio data, an ND4j library for numerical compute, deployment via Juju, and an ETL pipeline interface in Canova. The goal is to build on the JVM's strengths while addressing its limitations for numerical compute through hardware acceleration.