Intrigued about the best SQL-on-Hadoop Tools? In our post "8 SQL-on-Hadoop Challenges," we gave an overview of several tools that help to bridge the gap between the two technologies—but without going into too many details. This time we’ll dive in and learn about 12 tools that bring SQL to Hadoop, covering both open-source and commercial solutions.
We've selected these tools for a combination of reasons including price, features, helpful use cases, accessibility, future potential, and more. Without further ado, here's our list of 12 essential SQL-on-Hadoop tools.
Which are the best SQL on Hadoop tools for low-code data collaboration
Apache Hive, Apache Sqoop, and Apache Phoenix are among the best SQL-on-Hadoop tools for enabling low-code data collaboration. Apache Hive provides a SQL-like interface (HiveQL) to query and analyze large Hadoop datasets without writing MapReduce jobs. Apache Sqoop simplifies bulk data transfer between Hadoop and relational databases using minimal coding.
1. Apache Hive

Apache Hive is one of the top SQL-on-Hadoop tools. Initially developed by Facebook, Hive is a data warehouse infrastructure built on top of Hadoop. It allows querying data stored on HDFS for analysis via HQL, an SQL-like language translated to MapReduce jobs.
While it seems to provide SQL functionality, Hive performs batch processing on Hadoop and does not provide interactive querying. It stores metadata in a relational database and requires maintaining a schema for the data. Hive supports several file formats, as well as processing compressed data on Hadoop along with user-defined functions.
G2 Rating: 4.2 / 5
Features: SQL-like querying (HiveQL), works on Hadoop HDFS and other filesystems; supports ORC, Parquet, RCFile; metadata stored separately for faster semantic checks; compression; UDFs; execution via MapReduce, Tez, Spark
Pros:
Cons:
-
Slower performance due to overhead of MapReduce
-
Some limitations from SQL background (e.g., syntax restrictions)
Pricing: Open source, free to use
The bottom line: Hive offers batch processing on Hadoop with an SQL-like language.
Deciding on Hive vs. HBase? Check out our article!
2. Apache Sqoop

One of the most valuable SQL-on-Hadoop Tools, Apache Sqoop allows importing and exporting data from relational databases to Hadoop via JDBC, the standard API for connecting to databases with Java. It can also work without JDBC, as long as the relevant tools allow bulk import/export of data.
Sqoop works by running a query on the relational database and then exporting the resulting rows into files in one of the following formats: text, binary, Avro, or Sequence Files. These files are saved on Hadoop’s HDFS, and can also go from Hadoop back into a relational database. Finally, Sqoop integrates with HCatalog, a table and storage management service for Hadoop that allows querying Sqoop’s imported files via Hive or Pig. (See our Sqoop blog post for more info.)
G2 Rating: 4.3 / 5
Features: CLI tool to transfer bulk data between Hadoop and relational databases; supports incremental loads and exports to Hive or HBase
Pros:
-
Fast parallel data transfers
-
Simple, minimal setup and learning curve
-
Supports incremental imports
Cons:
-
Joins can be slow; partial import failures need special handling
-
Based on MapReduce, so can be sluggish for small jobs
-
Discontinued (moved to Apache Attic in 2021)
Pricing: Open source, free
The bottom line: Sqoop lets you import and export data from SQL databases to and from Apache Hadoop.
The Unified Stack for Modern Data Teams
Get a personalized platform demo & 30-minute Q&A session with a Solution Engineer
3. Apache Phoenix

Apache Phoenix is an SQL skin for interactive queries over HBase. It compiles SQL queries into a series of HBase scans and produces JDBC result sets.
Note that Phoenix requires maintaining a schema that can either be built from scratch or mapped from an existing HBase table. Furthermore, there are several features Phoenix doesn’t support: full transaction support, derived tables, relational operators, and miscellaneous built-in functions (although they can be added manually). The project is mainly maintained by Salesforce, Intel, and Hortonworks.
G2 Rating: 3.7 / 5
Features:
SQL-on-HBase engine providing OLTP capabilities using familiar SQL syntax, leveraging Apache HBase as the storage layer.
Pros:
-
Enables SQL access to HBase, offering ACID support and upsert operations.
-
Good integration with HBase infrastructure.
Cons:
-
Rated lower than many alternatives in ease-of-use and schema management.
-
Errors can be obscure, community support seems slow.
-
Limited to HBase—doesn't natively query across other sources.
Pricing: Open source, free.
The bottom line: Apache Phoenix offers interactive SQL queries over HBase.
4. Apache Impala

Apache Impala is a query engine that runs on top of Hadoop and executes interactive SQL queries on HDFS and HBase. Unlike Apache Hive, which uses batch processing, Impala runs the queries in real-time, thus allowing you to integrate SQL-based business intelligence tools with Hadoop.
Originally developed by the enterprise data cloud company Cloudera, Impala has since become part of the Apache open-source software ecosystem. Impala supports all standard Hadoop file formats, including text, LZO, Sequence Files, Avro, and RCFile. Impala can also run in the cloud via Amazon Elastic MapReduce (EMR).
G2 Rating: NA
Features: MPP SQL engine for Hadoop offering real-time, low-latency queries on HDFS/HBase; supports SELECT, JOIN, aggregates
Pros:
Cons: Fewer public reviews; less known cons in available sources
Pricing: Open source, free
The bottom line: Impala is an open-source solution for interactive SQL queries over HDFS and HBase.
5. Apache Spark SQL

Apache Spark SQL is a module for Apache Spark, an open-source big data processing engine, that helps you query structured data within Spark programs. It is the successor to Apache Shark, a large-scale data warehouse system for Apache Spark that has been defunct for several years.
Spark SQL introduces a concept known as DataFrames, which are equivalent to relational database tables with additional enhancements and optimizations. The Spark SQL module is compatible with many different data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC, and programming languages including Java, Scala, Python and R.
Rating: 4.5 / 5
Features: SQL plus DataFrame API within Spark; supports Java, Scala, Python, R; includes cost-based optimizer, columnar storage, code generation, optimizer ("Catalyst"), fault tolerance
Pros:
-
Powerful data analytics, optimization, and scalability
-
Easy SQL querying over large datasets
-
Great integration with Spark ecosystem; efficient for ETL, machine learning, big data tasks
Cons:
-
Not suited for real-time or small-file workloads
-
Some difficulty in resource management, debugging, missing SQL features
Pricing: Open source, free
The bottom line: Apache Spark SQL is an excellent choice if you need SQL-on-Hadoop capabilities within Apache Spark.
6. Apache Drill

Apache Drill calls itself a "schema-free SQL query engine for Hadoop, NoSQL and cloud storage." Drill makes use of a JSON data model that allows for SQL queries over complex and nested data and non-relational tables. You can use standard SQL queries with Drill, just like you would use to query a relational database.
The open-source Drill project is based on Google's Dremel system for querying large, distributed datasets. Drill has a REST API and integrates with business intelligence applications such as Tableau, Qlik, SAS, and Microsoft Excel.
G2 Rating: NA
Features: Schema-free SQL query engine for Hadoop, NoSQL, cloud storage; supports nested data like JSON, Parquet
Pros/Cons: Limited G2 data; general limitations include a steeper learning curve and less mature data migration or recovery features compared to mainstream tools
Pricing: Open source, free
The bottom line: Apache Drill lets you use SQL to query Hadoop and NoSQL databases.
The Unified Stack for Modern Data Teams
Get a personalized platform demo & 30-minute Q&A session with a Solution Engineer
7. Presto

Presto is an interactive SQL query engine that runs on top of Hive, HBase, and even relational databases and proprietary data stores, helping you combine data from multiple sources across the organization. According to the project website, Presto is "the fastest SQL on Hadoop engine," with the benchmarks to back it up.
Facebook is the main developer behind Presto, and the company uses it to query internal data stores, including a 300-petabyte data warehouse. Other big enterprises such as Airbnb and Dropbox also use Presto in their tech stacks.
G2 Rating: NA
Features:
A high-performance, open-source, distributed SQL engine for interactive analytics across large datasets. It supports querying across multiple data sources (HDFS, S3, MySQL, Cassandra, etc.) and processes data in memory with sub-second response times.
Pros:
-
Fast, scalable analytics over TB to PB of data.
-
Real-time, interactive querying across heterogeneous sources.
Cons:
Pricing: Open source, free.
The bottom line: Presto is Facebook’s enterprise-class solution for interactive SQL queries over Hive and HBase.
8. Citusdata

Citus Data (not to be confused with CitrusDB) is another interactive querying engine with SQL-like functionality that works over Hadoop. Citus is based on Dremel, Google’s version of a real-time analytics database for processing big data. Since its acquisition by Microsoft in 2019, Citus has been available both as open-source software and as the Hyperscale (Citus) deployment option in Azure Database for PostgreSQL.
Unlike Impala and Presto, Citus uses PostgreSQL as the SQL engine that works behind the scenes. Citus can run on-premises or in the cloud, and supports features such as full-text search, geo search, ODBC/JDBC compatibility. Note that as an analytical database, Citus only supports loading the data in batches.
G2 Rating: 4.3 / 5
Features: Extension to PostgreSQL enabling horizontal scaling, distributed SQL, parallelism
Pros:
-
Scales PostgreSQL for real-time, large-scale data workloads
-
Boosts performance significantly (some report up to 300× faster)
Cons:
Pricing: Open source version free; enterprise offerings by Microsoft (no pricing on G2)
The bottom line: Citus offers SQL-on-Hadoop interactive querying with PostgreSQL.
Commercial SQL-on-Hadoop Tools
9. Jethro

Jethro claims to offer "the fastest SQL-on-Hadoop engine for BI" by providing an SQL engine for Hadoop that automatically indexes the data as soon as it gets written to Hadoop. According to Jethro's website, the tool can deliver "up to 100 times faster queries" than tools such as Hive and Impala. Installation and use is simple: Jethro can be added to an existing Hadoop cluster, is non-intrusive, and isn't installed on any of the Hadoop storage nodes.
G2 Rating: NA
Features:
A BI acceleration engine geared to speed up analytics over big data. Offers smart indexing, caching, and supports thousands of concurrent users running SQL queries with interactive performance.
Pros:
Cons:
Pricing: Not disclosed; likely commercial.
The bottom line: Jethro offers fast, non-intrusive SQL-on-Hadoop via auto-indexing.
10. HAWQ

HAWQ is a commercial SQL-on-Hadoop platform by Pivotal, a subsidiary of EMC. It provides a parallel SQL query engine using Pivotal’s Greenplum Analytic Database and Hadoop’s HDFS for data storage. The HAWQ engine is useful for analytics with full transaction support and supports creating external tables on HDFS that read text, Hive, HBase, and Parquet.
G2 Rating: NA
Features:
An SQL-on-Hadoop MPP query engine (based on Greenplum), enabling SQL queries over big data within Hadoop ecosystems.
Pros:
Cons:
Pricing: Not disclosed; likely open-source but possibly enterprise versions.
The bottom line: HAWQ is Pivotal’s SQL-on-Hadoop solution.
11. BigSQL

Big SQL by IBM (not to be confused with Postgres by BigSQL, an open-source project which seems to be defunct) is IBM's SQL-on-Hadoop engine for massively parallel processing (MPP) and advanced data queries. You can use IBM Big SQL to access a wide variety of formats, including relational databases, NoSQL databases, HDFS, and object stores.
IBM Big SQL boosts query performance by distributing queries across multiple nodes in a cluster. Use cases for Big SQL include offloading data from existing Oracle or IBM data warehouses, as well as federated access to relational databases containing data that can't be migrated into Hadoop.
G2 Rating: NA
Features:
An enterprise-grade hybrid SQL-on-Hadoop engine with MPP architecture, ANSI-compliance, secure federation across Hadoop, object stores, NoSQL, and RDBMS.
Pros:
-
Strong performance, broad source compatibility, security, and federation.
-
Offers low-latency queries across diverse data stores.
Cons:
Pricing: Free edition available; enterprise usage typically requires IBM licensing.
The bottom line: IBM Big SQL offers a robust SQL on Hadoop tool for large enterprises.
The Unified Stack for Modern Data Teams
Get a personalized platform demo & 30-minute Q&A session with a Solution Engineer
12. PolyBase
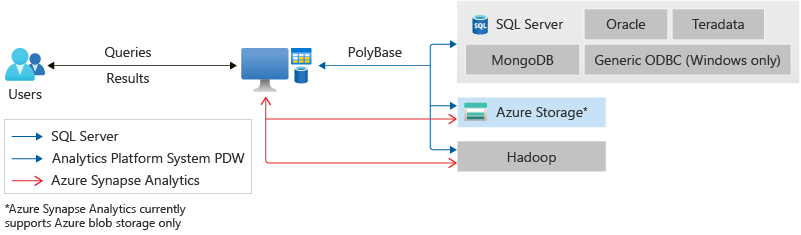
PolyBase is Microsoft's SQL-on-Hadoop tool for processing SQL queries. Microsoft SQL Server customers can use PolyBase to access data in Hadoop and Azure Blob Storage, as well as SQL Server, Oracle, Teradata, and MongoDB databases.
By using the Transact-SQL language, PolyBase users can query data stored in Hadoop, and also import data from and export data to Hadoop. PolyBase's query optimizer can decide to push computation to Hadoop, creating MapReduce jobs that take advantage of Hadoop's distributed nature.
G2 Rating: NA
Features:
Data virtualization engine that enables querying external data—Hadoop, Azure Blob, SQL Server—using T-SQL, enabling scalable data integration and querying.
Pros:
Cons:
Pricing: Included as feature in certain editions of SQL Server or Azure Synapse; no standalone pricing on G2.
The bottom line: PolyBase is a powerful SQL-on-Hadoop tool for users of Microsoft SQL Server.
Comparison of SQL on Hadoop Tools
| Tool | Type | What it is / Focus | Strengths | Limitations |
| Apache Hive | Hadoop SQL | Data warehouse framework for Hadoop | Mature, widely used; supports ETL, analytics; ACID support; integrates with Hadoop stack | Higher latency; historically batch-oriented; less suited for interactive queries |
| Apache Sqoop | Data transfer tool | Bulk transfer between Hadoop and relational DBs | Effective for imports/exports; parallelism; simple CLI integration | Not a query engine; largely superseded by Spark connectors |
| Apache Phoenix | SQL over HBase | SQL interface on HBase | Low-latency SQL on HBase; secondary indexes; transactional workloads | Limited outside HBase; not optimized for analytics |
| Apache Impala | Hadoop SQL | MPP query engine for Hadoop | Interactive SQL on Hadoop; integrates with Hive Metastore; strong with Parquet/ORC | Best in Cloudera ecosystem; weaker for non-columnar formats |
| Apache Spark SQL | Distributed compute | Spark module for structured data | Unified with Spark ML/Streaming; Catalyst optimizer; scalable | More overhead than lightweight query engines; latency not always ideal for BI |
| Apache Drill | Schema-free SQL | Query engine for heterogeneous data | Schema-on-read; works with JSON, NoSQL, HDFS, S3; very flexible | Performance weaker vs. Impala/Presto; smaller adoption |
| Presto (Trino) | Federated SQL | Distributed SQL query engine | High performance; queries across many sources; widely used at scale | Memory-intensive; cluster overhead; not a storage engine |
| Citusdata (Citus) | Postgres extension | Scale-out Postgres across nodes | Retains Postgres ecosystem; distributed tables; real-time analytics | Best for relational data; less fit for data lakes; Azure commercial edition stronger |
| Jethro | BI acceleration | Index + columnar SQL engine for Hadoop | BI-optimized (Tableau/Qlik); index acceleration; interactive queries | Niche adoption; designed mainly for star-schema BI |
| HAWQ | Hadoop SQL | Postgres-based SQL on Hadoop (Pivotal) | Mature SQL (Postgres); MPP; Hadoop integration | Adoption waned; overshadowed by newer engines |
| BigSQL (IBM Db2 Big SQL) | Hadoop SQL | IBM SQL engine for Hadoop | Strong ANSI SQL; federation with Db2, Oracle, Teradata; Hive compatible | Commercial; IBM ecosystem only; limited wider adoption |
| PolyBase | MS SQL external query | Query external data via T-SQL | Seamless in SQL Server/Azure; federates Hadoop, Azure Data Lake | Limited outside Microsoft stack; not general-purpose |
Looking for SQL on Hadoop Guidance? Here's How Integrate.io Can Help
Need a big data guide through the world of Hadoop? Integrate.io's data integration experts know how to help you optimize your big data workflows. Our cloud-based ETL (extract, transform, load) solution delivers simple, visualized data pipelines for automated data flows across a huge range of sources and destinations.
Ready to begin? Contact the Integrate.io team to schedule a demo and risk-free trial, and start experiencing the benefits of the Integrate.io platform for yourself.
FAQs
Q1: Which SQL-on-Hadoop tools offer seamless integration with cloud data warehouses?
-
Apache Impala – A massively parallel SQL engine for Hadoop that integrates with HDFS, HBase, and Kudu, and can feed data into downstream warehouses.
-
Trino (formerly PrestoSQL) – A federated SQL engine capable of querying Hadoop file systems and cloud storage (e.g., S3) alongside databases, making it well-suited for bridging Hadoop and cloud warehouses.
-
IBM Db2 Big SQL – Enterprise-grade SQL-on-Hadoop engine with ANSI compliance, federation features, and optimized performance across Hadoop, object storage, NoSQL, and relational systems.
Q2: Which SQL-on-Hadoop solutions provide sub-60 second latency for data synchronization?
-
Apache Impala – Known for its low-latency query engine designed for interactive Hadoop data analysis.
-
Trino – Built for fast performance and supports near real-time querying on large, distributed datasets.
-
Striim – Though not purely SQL-on-Hadoop, it supports real-time streaming into Hadoop/HDFS and enables sub-minute data delivery into SQL layers.
Q3: What are the top SQL-on-Hadoop solutions for enterprise-grade security?
-
IBM Db2 Big SQL – Provides strong compliance, authentication, authorization, and integration with IBM’s governance ecosystem.
-
Apache Impala – Integrates with Hadoop’s security stack, including Kerberos, LDAP, and Apache Ranger, to enforce fine-grained access control.
-
Trino (and Starburst Enterprise) – Offers secure query access with LDAP/Kerberos integration and enterprise-level governance features.
Q4: How do SQL-on-Hadoop tools differ from traditional data warehouses?
Traditional data warehouses rely on structured, pre-modeled data optimized for OLAP. SQL-on-Hadoop tools, by contrast, enable querying across massive, diverse, and semi-structured datasets directly in Hadoop. They offer schema-on-read flexibility, while warehouses typically use schema-on-write.
Q5: What performance optimizations do these tools provide?
SQL-on-Hadoop engines leverage distributed query execution, columnar storage formats (Parquet, ORC), vectorized execution, and cost-based optimizers. Some also integrate caching layers or pushdown computation to improve query speed on very large datasets.