In this Data Science interview questions guide, you will explore interview questions for Data Science for beginners and experienced professionals. Here you will find the frequently asked questions during the data science interview. Practicing all the questions below will help you explore your career as a data scientist.
What is Data Science?
Data Science is a field that extracts knowledge and insights from structured and unstructured data by using scientific methods, algorithms, processes and systems. It combines expertise from various domains such as statistics, computer science, machine learning, data engineering and domain-specific knowledge to analyze and interpret complex data sets.
After exploring the brief on data science, let's dig into the data science interview questions and answers.
Statistics and Probability
Beginner Level Questions
1. What is Marginal Probability?
Marginal probability is simply the chance of one specific event happening, without worrying about what happens with other events. For example, if you’re looking at the probability of it raining tomorrow, you only care about the chance of rain, not what happens with other weather conditions like wind or temperature.
2. What are the Probability Axioms?
The probability axioms are just basic rules that help us understand how probabilities work. There are three main ones:
- Non-Negativity Axiom: Probabilities can't be negative. The chance of something happening is always 0 or more, never less.
- Normalization Axiom: If something is certain to happen (like the sun rising tomorrow), its probability is 1. So, 1 means "definitely happening."
- Additivity Axiom: If two events can't happen at the same time (like rolling a 3 or a 4 on a die), the chance of either one happening is just the sum of their individual chances.
3. What is the difference between Dependent and Independent Events in Probability?
- Independent Events: Two events are independent if one event doesn't change the likelihood of the other happening. For example, flipping a coin twice – the first flip doesn't affect the second flip. So, the probability of both events happening is just the product of their individual probabilities.
- Dependent Events: Two events are dependent if one event affects the likelihood of the other happening. For example, if you draw a card from a deck and don't put it back (without replacement), the chance of drawing a second card depends on what the first card was. The probability changes because one card was already taken out.
4. What is Conditional Probability?
Conditional probability refers to the probability of an event occurring given that another event has already occurred. Mathematically, it is defined as the probability of event A occurring, given that event B has occurred and is denoted by P(A|B). The formula for conditional probability is:
P(A|B) = \frac{P(A\cap B)}{P(B)}
where:
- P(A|B) is the conditional probability of event A given event B.
- P(A\cap B) is the joint probability of both events A and B occurring simultaneously.
- P(B) is the probability of event B occurring.
5. What is Bayes’ Theorem and when do we use it in Data Science?
Bayes' Theorem helps us figure out the probability of an event happening based on some prior knowledge or evidence. It’s like updating our guess about something when we learn new things. The formula for Bayes' Theorem is:
P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}
Where:
- P(A|B) is the probability of event A happening, given that B has happened.
- P(B|A) is the probability of event B happening, given that A happens.
- P(A) is the probability of event A happening, regardless of B.
- P(B) is the probability of event B happening, regardless of A.
6. Define Variance and Conditional Variance.
- Variance is a way to measure how spread out or different the numbers in a dataset are from the average. If the numbers are all close to the average, the variance is low. If the numbers are spread far apart, the variance is high. Think of it like measuring how much everyone’s test score differs from the average score in a class.
- Conditional Variance is similar, but it looks at how much a variable changes when we know something else about it. For example, imagine you want to know how much people's height varies based on their age. The conditional variance would tell you how much height changes for a specific age group, using the knowledge of age to focus on the variability within that group.
- Mean: The mean is simply the average of a set of numbers. To find it, you add up all the numbers and divide by how many numbers there are. It gives you a central value that represents the overall data.
- Median: The median is the middle number when you arrange the data in order from smallest to largest. If there’s an even number of numbers, you average the two middle numbers. The median is useful because it’s not affected by extremely high or low values, making it a better measure of the "middle" when there are outliers.
- Mode: The mode is the number that appears the most often in your data. You can have one mode, more than one mode or no mode at all if all the numbers appear equally often.
- Standard Deviation: Standard deviation tells us how spread out the numbers are. If the numbers are close to the average, the standard deviation is small. If they’re more spread out, it’s large. It shows us how much variation or "scatter" there is in the data.
8. What is Normal Distribution and Standard Normal Distribution?
- Normal Distribution: A normal distribution is a bell-shaped curve that shows how most data points are close to the average (mean) and the further away you go from the mean, the less likely those data points are. It’s a common pattern in nature like people's heights or test scores.
- Standard Normal Distribution: This is a special type of normal distribution where the mean is 0 and the standard deviation is 1. It helps make comparisons between different sets of data easier because the data is standardized.
9. What is the difference between correlation and causation?
Correlation means that two things are related or happen at the same time, but one doesn’t necessarily cause the other. For example, if people eat more ice cream in summer and also go swimming more, there's a correlation between the two, but eating ice cream doesn’t cause swimming. They just both happen together.
Causation means one thing directly causes the other to happen. For example, if you study more, your test scores will likely improve. In this case, studying causes better test scores. To prove causation, you need more evidence, often from experiments, to show that one thing is actually causing the other.
Click here to learn more about the topic: Correlation vs Causation
- Uniform Distribution: Uniform distribution means that every possible outcome has an equal chance of occurring. For example, when rolling a fair six-sided die, each number (1 through 6) has the same probability of showing up, resulting in a flat line when graphed.
- Bernoulli Distribution: Bernoulli distribution is used in situations where there are only two possible outcomes such as success or failure. A common example is flipping a coin where you either get heads (success) or tails (failure).
- Binomial Distribution: Binomial distribution applies when you perform a set number of independent trials, each with two possible outcomes. It helps calculate the probability of getting a specific number of successes across multiple trials such as flipping a coin 5 times and determining the chance of getting exactly 3 heads.
11. Explain the Exponential Distribution and where it’s commonly used.
The Exponential distribution helps us understand the time between random events that happen at a constant rate. For example, it can show how long you might have to wait for the next customer to arrive at a store or how long a light bulb will last before it burns out.
12. Describe the Poisson Distribution and its characteristics.
The Poisson distribution tells us how often an event happens within a certain period of time or space. It’s used when events happen at a steady rate like how many cars pass by a toll booth in an hour.
Key points:
- It counts the number of events that happen.
- The events happen at a constant rate.
- Each event is independent, meaning one event doesn’t affect the others.
13. Explain the t-distribution and its relationship with the normal distribution.
Thet-distribution is similar to the normal distribution, but it’s used when we don’t have much data and don’t know the exact spread of the population. It’s wider and more spread out than the normal distribution, but as we get more data, it looks more like the normal distribution.
14. Describe the chi-squared distribution.
The chi-squared distributionis used when we want to test how well our data matches a certain pattern or to see if two things are related. It’s often used in tests like checking if dice rolls are fair or if two factors like age and voting preference, are linked.
15. What is the difference between z-test, F-test and t-test?
- Z-test: We use the z-test when we want to compare the average of a sample to a known average of a larger population and we know the population's spread (standard deviation). It’s typically used with large samples or when we have good information about the population.
- T-test: The t-test is similar to the z-test, but it's used when we don't know the population’s spread (standard deviation). It’s often used with smaller samples or when we don’t have enough data to know the population’s spread.
- F-test: The F-test is used when we want to compare how much the data is spread out (variance) in two or more groups. For example, you might use it to see if two different teaching methods lead to different results in students.
16. What is the central limit theorem and why is it significant in statistics?
The Central Limit Theorem (CLT) says that if you take many samples from a population, no matter how the population looks, the average of those samples will start to look like a normal (bell-shaped) distribution as the sample size gets bigger. This is important because it means we can use normal distribution rules to make predictions, even if the population itself doesn’t look normal.
Advanced Level Questions
17. Describe the process of hypothesis testing, including null and alternative hypotheses.
Hypothesis testing helps us decide if a claim about a population is likely to be true, based on sample data.
- Null Hypothesis (H0): This is the "no effect" assumption, meaning nothing is happening or nothing has changed.
- Alternative Hypothesis (H1): This is the opposite, suggesting there is a change or effect.
We collect data and check if it supports the alternative hypothesis or not. If the data shows enough evidence, we reject the null hypothesis.
18. How do you calculate a confidence interval and what does it represent?
A confidence interval gives us a range of values that we believe the true population value lies in, based on our sample data.
To calculate: You first collect sample data, then calculate the sample mean and margin of error (how much the sample result could vary). The confidence interval is the range around the mean where the true population value should be, with a certain level of confidence (like 95%).
19. What is a p-value in statistics?
A p-value tells us how likely it is that we would get the data we have if the null hypothesis were true. A small p-value (less than 0.05) means the data is unlikely under the null hypothesis, so we may reject the null hypothesis. A large p-value means the data fits with the null hypothesis, so we don’t reject it.
20. Explain Type I and Type II errors in hypothesis testing.
- Type I Error (False Positive): Mistakenly reject a true null hypothesis, thinking something has changed when it hasn’t.
- Type II Error (False Negative): Fail to reject a false null hypothesis, missing a real effect.
21. What is the significance level (alpha) in hypothesis testing?
The significance level (alpha) is the threshold you set to decide when to reject the null hypothesis. It shows how much risk you're willing to take for a Type I error (wrongly rejecting the null hypothesis). Commonly, alpha is 0.05, meaning there’s a 5% chance of making a Type I error.
22. How can you calculate the correlation coefficient between two variables?
The correlation coefficient measures how strongly two variables are related.
To calculate it, you:
- Collect data for both variables.
- Find the average for each variable.
- Calculate how much the variables move together (covariance).
- Divide by the standard deviations to standardize the result.
This gives you a number between -1 and 1 where 1 means a perfect positive relationship, -1 means a perfect negative relationship and 0 means no relationship.
- Covariance shows how two variables change together. If both increase together, covariance is positive and if one increases while the other decreases, it’s negative. However, it depends on the scale of the variables, so it's harder to compare across different data.
- Correlation standardizes covariance by using the standard deviations of the variables. It’s easier to interpret because it gives you a number between -1 and 1 that shows the strength and direction of the relationship.
When comparing two population means, we:
1. Set up hypotheses:
- Null hypothesis (H0): The two means are equal.
- Alternative hypothesis (H1): The two means are different.
- Collect data from both populations.
2. Calculate the test statistic (often using a t-test or z-test).
3. Compare the results to see if the difference is statistically significant.
4. If the results show a big enough difference, we reject the null hypothesis.
25. Explain multivariate distribution in data science.
A multivariate distribution involves multiple variables and it helps us model situations where we care about the relationships between those variables. For example, predicting house prices based on factors like size, location and age of the house. It’s a way to see how different features or variables work together and affect the outcome.
26. Describe the concept of conditional probability density function (PDF).
A conditional probability density function (PDF) describes the probability of an event happening, given that we already know some other event has occurred. For example, it tells us the chance of a person getting a disease given they have a certain symptom. It helps us understand how one event affects the probability of another.
The probability that a continuous random variable will take on particular values within a range is described by the Probability Density Function (PDF), whereas the Cumulative Distribution Function (CDF) provides the cumulative probability that the random variable will fall below a given value. Both of these concepts are used in probability theory and statistics to describe and analyse probability distributions. The PDF is the CDF’s derivative and they are related by integration and differentiation.
The statistical method known as ANOVA or Analysis of Variance, is used to examine the variation in a dataset and determine whether there are statistically significant variations between group averages. When comparing the means of several groups or treatments to find out if there are any notable differences, this method is frequently used.
There are several different ways to perform ANOVA tests, each suited for different types of experimental designs and data structures:
- One-Way ANOVA
- Two-Way ANOVA
When conducting ANOVA tests we typically calculate an F-statistic and compare it to a critical value or use it to calculate a p-value.
29. What is the difference between a population and a sample in statistics?
- Population: This is the whole group you want to study. For example, if you're looking at the average height of all students in a school, the population is every student in that school.
- Sample: A sample is just a smaller part of the population. Since it's often not possible to study everyone, you choose a few people from the group to represent the whole population. For example, you might measure the height of 100 students and use that data to estimate the average height of all students.
Machine Learning
Beginner Level Questions
30. What are the different types of machine learning?
Supervised Learning: In supervised learning, the computer is given data that already has the correct answers (called labels). For example, you show it pictures of dogs and cats and each picture is labeled as "dog" or "cat." The computer learns from these labeled examples so it can correctly identify new pictures on its own. It's like teaching with a quiz where the answers are already provided.
Unsupervised Learning: In unsupervised learning, the computer is given data without any answers. It has to figure out patterns or groups by itself. For example, you might give it a bunch of photos and the computer might group all the dog pictures together and all the cat pictures together, even though you didn’t tell it what they were.
31. What is linear regression and what are the different assumptions of linear regression algorithms?
Linear Regression is type of Supervised Learning where we compute a linear relationship between the predictor and response variable. It is based on the linear equation concept given by:
\hat{y} = \beta_1x+\beta_o,
where
- \hat{y} = response / dependent variable
- \beta_1 = slope of the linear regression
- \beta_o = intercept for linear regression
- x = predictor / independent variable(s)
There are 4 assumptions we make about a Linear regression problem:
- Linear relationship : This assumes that there is a linear relationship between predictor and response variable. This means that which changing values of predictor variable, the response variable changes linearly (either increases or decreases).
- Normality : This assumes that the dataset is normally distributed, i.e., the data is symmetric about the mean of the dataset.
- Independence : The features are independent of each other, there is no correlation among the features/predictor variables of the dataset.
- Homoscedasticity : This assumes that the dataset has equal variance for all the predictor variables. This means that the amount of independent variables have no effect on the variance of data.
32. Logistic Regression is a classification technique and why is its name regression not Logistic Classification?
While logistic regression is used for classification it still maintains a regression structure underneath. The key idea is to model the probability of an event occurring (e.g., class 1 in binary classification) using a linear combination of features and then apply a logistic (Sigmoid) function to transform this linear combination into a probability between 0 and 1. This transformation is what makes it suitable for classification tasks.
In short while logistic regression is indeed used for classification, it retains the mathematical and structural characteristics of a regression model.
33. What is the Logistic function (Sigmoid function) in logistic regression?
The logistic function or sigmoid function, is used in logistic regression to predict probabilities. It takes any real number as input and maps it to a value between 0 and 1 which makes it great for predicting binary outcomes like "yes" or "no."
The formula looks like this:
f(x) = \frac{1}{1 + e^{-x}}
The sigmoid function helps us predict the probability of an event happening. If the output is close to 1, we predict one class and if it's close to 0, we predict the other.
 Sigmoid Function
Sigmoid Function34. What is overfitting and how can be overcome this?
Overfitting refers to the result of analysis of a dataset which fits so closely with training data that it fails to generalize with unseen/future data. This happens when the model is trained with noisy data which causes it to learn the noisy features from the training as well.
To avoid Overfitting and overcome this problem in machine learning, one can follow the following rules:
- Feature selection : Sometimes the training data has too many features which might not be necessary for our problem statement. In that case, we use only the necessary features that serve our purpose
- Cross Validation : This technique is a very powerful method to overcome overfitting. In this, the training dataset is divided into a set of mini training batches which are used to tune the model.
- Regularization : Regularization is the technique to supplement the loss with a penalty term so as to reduce overfitting. This penalty term regulates the overall loss function, thus creating a well trained model.
- Ensemble models : These models learn the features and combine the results from different training models into a single prediction.
35. What is a support vector machine (SVM) and what are its key components?
Support Vector machines are a type of Supervised algorithm which can be used for both Regression and Classification problems. In SVMs, the main goal is to find a hyperplane which will be used to segregate different data points into classes. Any new data point will be classified based on this defined hyperplane.
Support Vector machines are highly effective when dealing with high dimensionality space and can handle non linear data very well. But if the number of features are greater than number of data samples, it is susceptible to overfitting.
The key components of SVM are:
- Kernels Function: It is a mapping function used for data points to convert it into high dimensionality feature space.
- Hyperplane: It is the decision boundary which is used to differentiate between the classes of data points.
- Margin: It is the distance between Support Vector and Hyperplane
- C: It is a regularization parameter which is used for margin maximization and misclassification minimization.
36. Explain the k-nearest neighbors (KNN) algorithm.
The k-Nearest Neighbors (KNN) algorithm is a simple and versatile supervised machine learning algorithm used for both classification and regression tasks. KNN makes predictions by memorizing the data points rather than building a model about it. This is why it is also called “lazy learner” or “memory based” model too.
KNN relies on the principle that similar data points tend to belong to the same class or have similar target values. This means that, In the training phase, KNN stores the entire dataset consisting of feature vectors and their corresponding class labels (for classification) or target values (for regression). It then calculates the distances between that point and all the points in the training dataset. (commonly used distance metrics are Euclidean distance and Manhattan distance).
(Note : Choosing an appropriate value for k is crucial. A small k may result in noisy predictions while a large k can smooth out the decision boundaries. The choice of distance metric and feature scaling also impact KNN’s performance.)
37. What is the Naïve Bayes algorithm and what are the different assumptions of Naive Bayes?
The Naïve Bayes algorithm is a probabilistic classification algorithm based on Bayes’ theorem with a “naïve” assumption of feature independence within each class. It is commonly used for both binary and multi-class classification tasks, particularly in situations where simplicity, speed and efficiency are essential.
The main assumptions that Naïve Bayes theorem makes are:
- Feature independence – It assumes that the features involved in Naïve Bayes algorithm are conditionally independent, i.e., the presence/ absence of one feature does not affect any other feature
- Equality – This assumes that the features are equal in terms of importance (or weight).
- Normality – It assumes that the feature distribution is Normal in nature, i.e., the data is distributed equally around its mean.
38. What are Decision Trees and how do they work?
Decision trees are a popular machine learning algorithm used for both classification and regression tasks. They work by creating a tree-like structure of decisions based on input features to make predictions or decisions. Lets dive into its core concepts and how they work briefly:
- Decision trees consist of nodes and edges.
- The tree starts with a root node and branches into internal nodes that represent features or attributes.
- These nodes contain decision rules that split the data into subsets.
- Edges connect nodes and indicate the possible decisions or outcomes.
- Leaf nodes represent the final predictions or decisions.
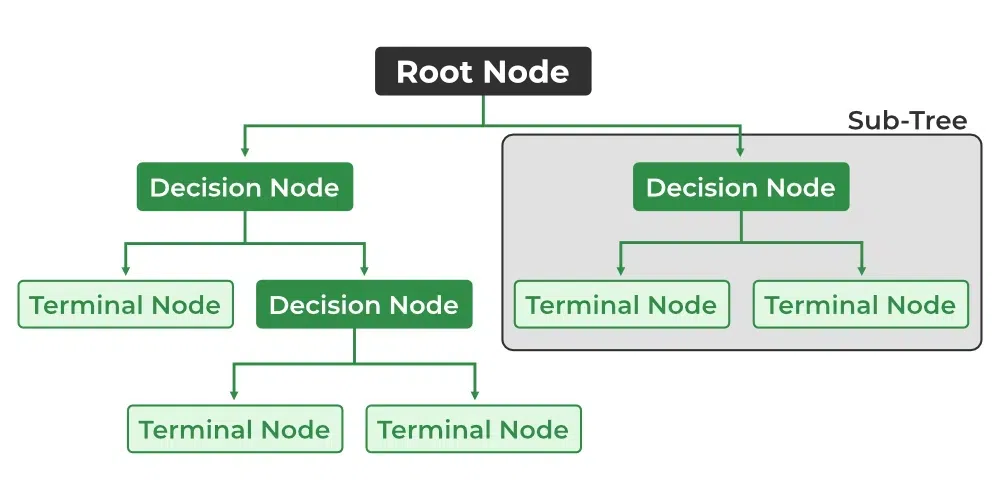
The objective is to increase data homogeneity which is often measured using standards like mean squared error (for regression) or Gini impurity (for classification). Decision trees can handle a variety of attributes and can effectively capture complex data relationships. They can, however, overfit, especially when deep or complex. To reduce overfitting, strategies like pruning and restricting tree depth are applied.
Entropy is like a measure of how mixed or uncertain your data is. If all the data points belong to the same class, entropy is low. If the data is spread out across many different classes, entropy is high. Formula for entropy is:
H(S) = - \sum_{i=1}^{n} p_i \log_2(p_i)
where,
- p_i is the probability of each class in the dataset.
Information Gain tells us how much we reduce that uncertainty after we split the data using a feature. A higher information gain means the feature helps us organize the data better and makes it easier to predict the target class. It's the difference between the uncertainty before and after the split. Formula for information gain is:
\text{Information Gain} = H(S) - \sum_{i=1}^{k} \frac{|S_i|}{|S|} H(S_i)
where,
- H(S) is the entropy before the split,
- H(Si) is the entropy of the subsets after the split,
- |Si| is the number of instances in subset, and
- |S| is the total number of instances in the dataset.
40. What is the difference between the Bagging and Boosting model?
Bagging and Boosting are two techniques used to improve the accuracy of machine learning models by combining multiple models together, but they work in different ways.
In Bagging, we train several models independently on different random parts of the data. Each model makes its own predictions and then we combine those predictions by either averaging or voting. Example: Random Forest Algorithm.
In Boosting, models are trained one after another. Each new model tries to fix the mistakes of the previous one and the final prediction is based on a combination of all models where better models are given more weight. Example: AdaBoost and Gradient Boosting.
41. Describe Random Forests and their advantages over Single-Decision Trees.
Random Forests are an ensemble learning technique that combines multiple decision trees to improve predictive accuracy and reduce overfitting. The advantages it has over single decision trees are:
- Improved Generalization: Single decision trees are prone to overfitting, especially when they become deep and complex. Random Forests mitigate this issue by averaging predictions from multiple trees, resulting in a more generalized model that performs better on unseen data
- Better Handling of High-Dimensional Data : Random Forests are effective at handling datasets with a large number of features. They select a random subset of features for each tree which can improve the performance when there are many irrelevant or noisy features
- Robustness to Outliers: Random Forests are more robust to outliers because they combine predictions from multiple trees which can better handle extreme cases
42. What is K-Means and how does it work?
K-Means is an unsupervised machine learning algorithm used for clustering or grouping similar data points together. It aims to partition a dataset into K clusters where each cluster represents a group of data points that are close to each other in terms of some similarity measure. The working of K-means is as follow:
- Choose the number of clusters K
- For each data point in the dataset, calculate its distance to each of the K centroids and then assign each data point to the cluster whose centroid is closest to it
- Recalculate the centroids of the K clusters based on the current assignment of data points.
- Repeat the above steps until a group of clusters are formed.
43. What is a Confusion Matrix? Explain with an example.
Confusion matrix is a table used to evaluate the performance of a classification model by presenting a comprehensive view of the model’s predictions compared to the actual class labels. It provides valuable information for assessing the model’s accuracy, precision, recall and other performance metrics in a binary or multi-class classification problem.
A famous example demonstration would be Cancer Confusion matrix:
| Actual Cancer | Actual Not Cancer |
|---|
Predicted Cancer | True Positive (TP) | False Positive (FP) |
|---|
Predicted Not Cancer | False Negative (FN) | True Negative (TN) |
|---|
- TP (True Positive) = The number of instances correctly predicted as the positive class
- TN (True Negative) = The number of instances correctly predicted as the negative class
- FP (False Positive) = The number of instances incorrectly predicted as the positive class
- FN (False Negative) = The number of instances incorrectly predicted as the negative class
44. What is a classification report and explain the parameters used to interpret the result of classification tasks with an example.
A classification report is a summary of the performance of a classification model, providing various metrics that help assess the quality of the model’s predictions on a classification task.
The parameters used in a classification report typically include:
- Precision: Precision is the ratio of true positive predictions to the total predicted positives. It measures the accuracy of positive predictions made by the model.
Precision = TP/(TP+FP)
- Recall (Sensitivity or True Positive Rate): Recall is the ratio of true positive predictions to the total actual positives. It measures the model’s ability to identify all positive instances correctly.
Recall = TP / (TP + FN)
- Accuracy: Accuracy is the ratio of correctly predicted instances (both true positives and true negatives) to the total number of instances. It measures the overall correctness of the model’s predictions.
Accuracy = (TP + TN) / (TP + TN + FP + FN)
- F1-Score: The F1-Score is the harmonic mean of precision and recall. It provides a balanced measure of both precision and recall and is particularly useful when dealing with imbalanced datasets.
F1-Score = 2 * (Precision * Recall) / (Precision + Recall)
45. What is Regularization in Machine Learning? State the differences between L1 and L2 regularization.
Regularization is a technique used to prevent a model from becoming too complex and overfitting the training data. It adds a penalty to the model's cost function to keep the model simpler, helping it perform better on new, unseen data.
There are two common types of regularization: L1 and L2
L1 Regularization (Lasso): It adds the absolute value of the model's coefficients to the cost function. L1 encourages sparsity, meaning it can make some feature weights exactly zero, effectively removing those features from the model. This is useful for feature selection.
L2 Regularization (Ridge): It adds the square of the coefficients to the cost function. L2 reduces the size of all coefficients but doesn’t set them to zero, keeping all features in the model but making them less influential.
46. Explain the concepts of Bias-Variance trade-off in machine learning.
When creating predictive models, the bias-variance trade-off is a key concept in machine learning that deals with finding the right balance between two sources of error, bias and variance. It plays a crucial role in model selection and understanding the generalization performance of a machine learning algorithm. Here’s an explanation of these concepts:
- Bias: Bias is simply described as the model’s inability to forecast the real value due of some difference or inaccuracy. These differences between actual or expected values and the predicted values are known as error or bias error or error due to bias.
- Variance: Variance is a measure of data dispersion from its mean location. In machine learning, variance is the amount by which a predictive model’s performance differs when trained on different subsets of the training data. More specifically, variance is the model’s variability in terms of how sensitive it is to another subset of the training dataset, i.e. how much it can adapt on the new subset of the training dataset.
| Low Bias | High Bias |
|---|
Low Variance | Best fit (Ideal Scenario ) | Underfitting |
|---|
High Variance | Overfitting | Not capture the underlying patterns (Worst Case) |
|---|
As a Data Scientist, the goal is to find a model that makes good predictions without overfitting to the data. Low bias means the model fits the data well while low variance means it doesn’t change too much with different data. Too simple a model may not fit the data well (high bias) while too complex a model may overfit (high variance). The bias-variance trade-off is about finding the right balance for the best results.
 Bias-Variance Trade-Off
Bias-Variance Trade-Off47. How does Naive Bayes handle categorical and continuous features?
Naive Bayes is a method that calculates the probability of each class based on the features, assuming that the features are independent of each other.
- For categorical features like colors or yes/no answers, Naive Bayes looks at how often each category appears within each class and uses that information to calculate the probability for each class.
- For continuous features like height or weight, Naive Bayes assumes the data follows a normal (bell curve) distribution. It uses the average and spread (standard deviation) of the data for each class to calculate the probability.
Finally, it selects the class with the highest probability as the prediction for new data.
48. What is Laplace smoothing (add-one smoothing) and why is it used in Naive Bayes?
In Naïve Bayes, the conditional probability of an event given a class label is determined as P(event| class). When using this in a classification problem (let’s say a text classification), there could a word which did not appear in the particular class. In those cases, the probability of feature given a class label will be zero. This could create a big problem when getting predictions out of the training data.
To overcome this problem, we use Laplace smoothing. Laplace smoothing addresses the zero probability problem by adding a small constant (usually 1) to the count of each feature in each class and to the total count of features in each class. Without smoothing, if any feature is missing in a class, the probability of that class given the features becomes zero, making the classifier overly confident and potentially leading to incorrect classifications.
49. What are imbalanced datasets and how can we handle them?
Imbalanced datasets are datasets in which the distribution of class labels (or target values) is heavily skewed, meaning that one class has significantly more instances than any other class. Imbalanced datasets pose challenges because models trained on such data can have a bias toward the majority class, leading to poor performance on the minority class which is often of greater interest. This will lead to the model not generalizing well on the unseen data.
To handle imbalanced datasets, we can approach the following methods:
1. Resampling (Method of either increasing or decreasing the number of samples):
- Up-sampling: In this case, we can increase the classes for minority by either sampling without replacement or generating synthetic examples.
- Down-sampling: Another case would be to randomly cut down the majority class such that it is comparable to minority class.
2. Ensemble methods (using models which are capable of handling imbalanced dataset inherently):
- Bagging : Techniques like Random Forests which can mitigate the impact of class imbalance by constructing multiple decision trees from bootstrapped samples
- Boosting: Algorithms like AdaBoost and XGBoost can give more importance to misclassified minority class examples in each iteration, improving their representation in the final model
50. What are outliers in the dataset and how can we detect and remove them?
An Outlier is a data point that is significantly different from other data points. Usually, Outliers are present in the extremes of the distribution and stand out as compared to their out data point counterparts.
For detecting Outliers we can use the following approaches:
- Visual inspection: This is the easiest way which involves plotting the data points into scatter plot/box plot, etc.
- statistics: By using measure of central tendency, we can determine if a data point falls significantly far from its mean, median, etc. making it a potential outlier.
- Z-score: if a data point has very high Z-score, it can be identified as Outlier
For removing the outliers, we can use the following:
- Removal of outliers manually
- Doing transformations like applying logarithmic transformation or square rooting the outlier
- Performing imputations wherein the outliers are replaced with different values like mean, median, mode, etc.
51. What is the curse of dimensionality and how can we overcome this?
When dealing with a dataset that has high dimensionality (high number of features), we are often encountered with various issues and problems. Some of the issues faced while dealing with dimensionality dataset are listed below:
- Computational expense: The biggest problem with handling a dataset with vast number of features is that it takes a long time to process and train the model on it. This can lead to wastage of both time and monetary resources.
- Data sparsity: Many times data points are far from each other (high sparsity). This makes it harder to find the underlying patterns between features and can be a hinderance in proper analysis
- Visualising issues and Overfitting: It is rather easy to visualize 2d and 3d data. But beyond this order, it is difficult to properly visualize our data. Furthermore, more data features can be correlated and provide misleading information to the model training and cause overfitting.
These issues are what are generally termed as “Curse of Dimensionality”.
To overcome this, we can follow different approaches – some of which are mentioned below:
- Feature Selection: Many a times, not all the features are necessary. It is the user’s job to select out the features that would be necessary in solving a given problem statement.
- Feature engineering: Sometimes, we may need a feature that is the combination of many other features. This method can, in general, reduces the features count in the dataset.
- Dimensionality Reduction techniques: These techniques reduce the number of features in a dataset while preserving as much useful information as possible. Some of the famous Dimensionality reduction techniques are: Principle component analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), etc.
- Regularization: Some regularization techniques like L1 and L2 regularizations are useful when deciding the impact each feature has on the model training.
52. Describe gradient descent and its role in optimizing machine learning models.
Gradient descent is a fundamental optimization algorithm used to minimize a cost or loss function in machine learning and deep learning. Its primary role is to iteratively adjust the parameters of a machine learning model to find the values that minimize the cost function, thereby improving the model’s predictive performance. Here’s how Gradient descent help in optimizing Machine learning models:
- Minimizing Cost functions: The primary goal of gradient descent is to find parameter values that result in the lowest possible loss on the training data.
- Convergence: The algorithm continues to iterate and update the parameters until it meets a predefined convergence criterion which can be a maximum number of iterations or achieving a desired level of accuracy.
- Generalization: Gradient descent ensure that the optimized model generalizes well to new, unseen data.
Advanced Level Questions
53. How does the random forest algorithm handle feature selection?
Mentioned below is how Random forest handles feature selection
- When creating individual trees in the Random Forest ensemble, a subset of features is assigned to each tree which is called Feature Bagging. Feature Bagging introduces randomness and diversity among the trees.
- After the training, the features are assigned a “importance score” based on how well those features performed by reducing the error of the model. Features that consistently contribute to improving the model’s accuracy across multiple trees are deemed more important
- Then the features are ranked based on their importance scores. Features with higher importance scores are considered more influential in making predictions.
54. What is Feature Engineering? Explain the different feature engineering methods.
Feature Engineering can be defined as a method of preprocessing of data for better analysis purpose which involves different steps like selection, transformation, deletion of features to suit our problem at hand. Feature Engineering is a useful tool which can be used for:
- Improving the model’s performance and Data interpretability
- Reduce computational costs
- Include hidden patterns for elevated Analysis results
Some of the different methods of doing feature engineering are mentioned below:
- Principle Component Analysis (PCA) : It identifies orthogonal axes (principal components) in the data that capture the maximum variance, thereby reducing the data features.
- Encoding: It is a technique of converting the data to be represented a numbers with some meaning behind it. It can be done in two ways :
- Feature Transformation: Sometimes, we can create new columns essential for better modelling just by combining or modifying one or more columns.
55. How we will deal with the categorical text values in machine learning?
Often times, we are encountered with data that has Categorical text values. For example, male/female, first-class/second-class/third-class, etc. These Categorical text values can be divided into two types and based on that we deal with them as follows:
- If it is Categorical Nominal Data: If the data does not have any hidden order associated with it (e.g., male/female), we perform One-Hot encoding on the data to convert it into binary sequence of digits
- If it is Categorical Ordinal Data : When there is a pattern associated with the text data, we use Label encoding. In this, the numerical conversion is done based on the order of the text data.
56. What is DBSCAN and how do we use it?
Density-Based Spatial Clustering of Applications with Noise (DBSCAN), is a density-based clustering algorithm used for grouping together data points that are close to each other in high-density regions and labeling data points in low-density regions as outliers or noise. Here is how it works:
- For each data point in the dataset, DBSCAN calculates the distance between that point and all other data points
- DBSCAN identifies dense regions by connecting core points that are within each other’s predefined threshold (eps) neighborhood.
- DBSCAN forms clusters by grouping together data points that are density-reachable from one another.
57. How does the EM (Expectation-Maximization) algorithm work in clustering?
The Expectation-Maximization (EM) algorithm is a probabilistic approach used for clustering data when dealing with mixture models. EM is commonly used when the true cluster assignments are not known and when there is uncertainty about which cluster a data point belongs to. Here is how it works:
- First, the number of clusters K to be formed is specified.
- Then, for each data point, the likelihood of it belonging to each of the K clusters is calculated. This is called the Expectation (E) step
- Based on the previous step, the model parameters are updated. This is called Maximization (M) step.
- Together it is used to check for convergence by comparing the change in log-likelihood or the parameter values between iterations.
- If it converges, then we have achieved our purpose. If not, then the E-step and M-step are repeated until we reach convergence.
58. Explain the concept of silhouette score in clustering evaluation.
Silhouette score is a metric used to evaluate the quality of clusters produced by a clustering algorithm. Here is how it works:
- the average distance between the data point and all other data points in the same cluster is first calculated. Let us call this as (a)
- Then for the same data point, the average distance (b) between the data point and all data points in the nearest neighboring cluster (i.e., the cluster to which it is not assigned)
- silhouette coefficient for each data point is calculated which given by: S = (b – a) / max(a, b)
- if -1<S<0, it signifies that data point is closer to a neighboring cluster than to its own cluster.
- if S is close to zero, data point is on or very close to the decision boundary between two neighboring clusters.
- if 0<S<1, data point is well within its own cluster and far from neighboring clusters.
59. What is the relationship between eigenvalues and eigenvectors in PCA?
In Principal Component Analysis (PCA), eigenvalues and eigenvectors play a crucial role in the transformation of the original data into a new coordinate system. Let us first define the essential terms:
- Eigen Values: Eigenvalues are associated with each eigenvector and represent the magnitude of the variance (spread or extent) of the data along the corresponding eigenvector
- Eigen Vectors: Eigenvectors are the directions or axes in the original feature space along which the data varies the most or exhibits the most variance
The relationship between them is given as:
AV = \lambda{V}, where
- A = Feature matrix
- V = eigen vector
- \lambda = Eigen value.
A larger eigenvalue implies that the corresponding eigenvector captures more of the variance in the data.The sum of all eigenvalues equals the total variance in the original data. Therefore, the proportion of total variance explained by each principal component can be calculated by dividing its eigenvalue by the sum of all eigenvalues
60. What is the Cross Validation technique in Machine Learning?
Cross-validation is a resampling technique used in machine learning to assess and validate the performance of a predictive model. It helps in estimating how well a model is likely to perform on unseen data, making it a crucial step in model evaluation and selection. Cross validation is usually helpful when avoiding overfitting the model. Some of the widely known cross validation techniques are:
- K-Fold Cross-Validation: In this, the data is divided into K subsets and K iterations of training and testing are performed.
- Stratified K-Fold Cross-Validation: This technique ensures that each fold has approximately the same proportion of classes as the original dataset (helpful in handling data imbalance)
- Shuffle-Split Cross-Validation: It randomly shuffles the data and splits it into training and testing sets.
61. What are the ROC and AUC? Explain their significance in binary classification.
Receiver Operating Characteristic (ROC) is a graphical representation of a binary classifier’s performance. It plots the true positive rate (TPR) vs the false positive rate (FPR) at different classification thresholds.
True positive rate (TPR) : It is the ratio of true positive predictions to the total actual positives.
Recall = TP / (TP + FN)
False positive rate (FPR) : It is the ratio of False positive predictions to the total actual positives.
FPR= FP / (TP + FN)
Area Under the Curve (AUC) as the name suggests is the area under the ROC curve. The AUC is a scalar value that quantifies the overall performance of a binary classification model and ranges from 0 to 1 where a model with an AUC of 0.5 indicates random guessing and an AUC of 1 represents a perfect classifier.
 AUC-ROC Curve
AUC-ROC Curve62. Describe Batch Gradient Descent, Stochastic Gradient Descent and Mini-Batch Gradient Descent.
1. Batch Gradient Descent: In Batch Gradient Descent, the entire training dataset is used to compute the gradient of the cost function with respect to the model parameters (weights and biases) in each iteration. This means that all training examples are processed before a single parameter update is made. It converges to a more accurate minimum of the cost function but can be slow, especially in a high dimensionality space.
2. Stochastic Gradient Descent: In Stochastic Gradient Descent, only one randomly selected training example is used to compute the gradient and update the parameters in each iteration. The selection of examples is done independently for each iteration. This is capable of faster updates and can handle large datasets because it processes one example at a time but high variance can cause it to converge slower.
3. Mini-Batch Gradient Descent: Mini-Batch Gradient Descent strikes a balance between BGD and SGD. It divides the training dataset into small, equally-sized subsets called mini-batches. In each iteration, a mini-batch is randomly sampled and the gradient is computed based on this mini-batch. It utilizes parallelism well and takes advantage of modern hardware like GPUs but can still exhibits some level of variance in updates compared to Batch Gradient Descent.
63. Explain the Apriori - Association Rule Mining.
Association Rule Mining is a method used to find patterns or relationships between items in large datasets like identifying which products are often bought together. Apriori is a common algorithm used for this and it works by first finding the most frequently bought items and then looking for combinations of those items that appear together often.
The key idea behind Apriori is the Apriori Property which says that if a group of items is frequently bought together, all smaller groups of those items should also be frequent. For example, if people often buy bread and butter together, Apriori can help identify this pattern and suggest that if someone buys bread, they might also buy butter.
64. How can you prevent Gradient Descent from getting stuck in local minima?
Local minima happen when the algorithm gets stuck in a small minimum point, instead of finding the best solution. To avoid this:
- Good Starting Point: Use techniques like Xavier/Glorot or He initialization to set good starting values for the model’s weights.
- Smart Optimizers: Use optimizers like Adam or RMSProp that adjust the learning speed based on past steps, helping the algorithm move past local minima.
- Randomness with Mini-Batches: Use mini-batch gradient descent which introduces some randomness allowing the algorithm to jump out of local minima.
- Increase Model Complexity: Adding more layers or neurons can create a more complex model, reducing the chance of getting stuck.
- Tune Hyperparameters: Try different settings for the model using methods like random search or grid search to find the best ones.
65. Explain the Gradient Boosting algorithms in Machine Learning.
Gradient Boosting techniques like XGBoost and CatBoost are used for regression and classification problems. It is a boosting algorithm that combines the predictions of weak learners to create a strong model. The key steps involved in gradient boosting are:
- Initialize the model with weak learners such as a decision tree.
- Calculate the difference between the target value and predicted value made by the current model.
- Add a new weak learner to calculate residuals and capture the errors made by the current ensemble.
- Update the model by adding fraction of the new weak learner’s predictions. This updating process can be controlled by learning rate.
- Repeat the process from step 2 to 4, with each iteration focusing on correcting the errors made by the previous model.
SQL and DBMS
Beginner Level Questions
66. What is SQL, and what does it stand for?
SQL stands for Structured Query Language.It is a specialized programming language used for managing and manipulating relational databases. It is designed for tasks related to database management, data retrieval, data manipulation and data definition.
67. Explain the differences between SQL and NoSQL databases.
Both SQL (Structured Query Language) and NoSQL (Not Only SQL) databases, differ in their data structures, schema, query languages and use cases. The following are the main variations between SQL and NoSQL databases.
SQL | NoSQL |
|---|
SQL databases are relational databases, they organise and store data using a structured schema with tables, rows and columns. | NoSQL databases use a number of different types of data models such as document-based (like JSON and BSON), key-value pairs, column families and graphs. |
SQL databases have a set schema, thus before inserting data, we must establish the structure of our data.The schema may need to be changed which might be a difficult process. | NoSQL databases frequently employ a dynamic or schema-less approach, enabling you to insert data without first creating a predetermined schema. |
SQL is a strong and standardised query language that is used by SQL databases. Joins, aggregations and subqueries are only a few of the complicated processes supported by SQL queries. | The query languages or APIs used by NoSQL databases are frequently tailored to the data model. |
68. What are the primary SQL database management systems (DBMS)?
Relational database systems, both open source and commercial, are the main SQL (Structured Query Language) database management systems (DBMS) which are widely used for managing and processing structured data. Some of the most popular SQL database management systems are listed below:
- MySQL
- Microsoft SQL Server
- SQLite
- PostgreSQL
- Oracle Database
- Amazon RDS
69. What is the ER model in SQL?
The structure and relationships between the data entities in a database are represented by the Entity-Relationship (ER) model, a conceptual framework used in database architecture. The ER model is frequently used in combination with SQL for creating the structure of relational databases even though it is not a component of the SQL language itself.
The process of transforming data from one structure, format or representation into another is referred to as data transformation. In order to make the data more suited for a given goal such as analysis, visualisation, reporting or storage, this procedure may involve a variety of actions and changes to the data. Data integration, cleansing and analysis depend heavily on data transformation which is a common stage in data preparation and processing pipelines.
71. What are the main components of a SQL query?
A relational database’s data can be retrieved, modified or managed via a SQL (Structured Query Language) query. The operation of a SQL query is defined by a number of essential components, each of which serves a different function.
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- LIMIT
- JOIN
72. What is a Primary Key?
A relational database table’s main key, also known as a primary keyword, is a column that is unique for each record. It is a distinctive identifier. The primary key of a relational database must be unique. Every row of data must have a primary key value and none of the rows can be null.
73. What is the purpose of the GROUP BY clause and how is it used?
In SQL, the GROUP BY clause is used to create summary rows out of rows that have the same values in a set of specified columns. In order to do computations on groups of rows as opposed to individual rows, it is frequently used in conjunction with aggregate functions like SUM, COUNT, AVG, MAX or MIN. we may produce summary reports and perform more in-depth data analysis using the GROUP BY clause.
74. What is the WHERE clause used for and how is it used to filter data?
In SQL, the WHERE clause is used to filter rows from a table or result set according to predetermined criteria. It enables us to pick only the rows that satisfy particular requirements or follow a pattern. A key element of SQL queries, the WHERE clause is frequently used for data retrieval and manipulation.
75. How do you retrieve distinct values from a column in SQL?
Using the DISTINCT keyword in combination with the SELECT command, we can extract distinct values from a column in SQL. By filtering out duplicate values and returning only unique values from the specified column, the DISTINCT keyword is used.
76. What is the HAVING clause?
To filter query results depending on the output of aggregation functions, the HAVING clause, a SQL clause, is used along with the GROUP BY clause. The HAVING clause filters groups of rows after they have been grouped by one or more columns, in contrast to the WHERE clause which filters rows before they are grouped.
77. How do you handle missing or NULL values in a database table?
Missing or NULL values can arise due to various reasons such as incomplete data entry, optional fields or data extraction processes.
- Replace NULL with Placeholder Values
- Handle NULL Values in Queries
- Use Default Values
Advanced Level Questions
78. Explain the concept of Normalization in database design.
By minimising data duplication and enhancing data integrity, normalisation is a method in database architecture that aids in the effective organisation of data. It include dividing a big, complicated table into smaller, associated tables while making sure that connections between data elements are preserved. The basic objective of normalisation is to reduce data anomalies which can happen when data is stored in an unorganised way and include insertion, update and deletion anomalies.
79. What is Database Denormalization?
Database denormalization is the process of intentionally introducing redundancy into a relational database by merging tables or incorporating redundant data to enhance query performance. Unlike normalization which minimizes data redundancy for consistency, denormalization prioritizes query speed. By reducing the number of joins required, denormalization can improve read performance for complex queries. However, it may lead to data inconsistencies and increased maintenance complexity. Denormalization is often employed in scenarios where read-intensive operations outweigh the importance of maintaining a fully normalized database structure. Careful consideration and trade-offs are essential to strike a balance between performance and data integrity.
80. Define different types of SQL functions.
SQL functions can be categorized into several types based on their functionality.
- Scalar Functions
- Aggregate Functions
- Window Functions
- Table-Valued Functions
- System Functions
- User-Defined Functions
- Conversion Functions
- Conditional Functions
81. Explain the difference between INNER JOIN and LEFT JOIN.
INNER JOIN and LEFT JOIN are two types of SQL JOIN operations used to combine data from multiple tables in a relational database. Here are the some main differences between them.
INNER JOIN | LEFT JOIN |
|---|
Only rows with a match in the designated columns between the two tables being connected are returned by an INNER JOIN. | LEFT JOIN returns all rows from the left table and the matching rows from the right table. |
A row is not included in the result set if there is no match for it in either of the tables. | Columns from the right table’s rows are returned with NULL values if there is no match for that row. |
When we want to retrieve data from both tables depending on a specific criterion, INNER JOIN can be helpful. | It makes sure that every row from the left table appears in the final product, even if there are no matches for that row in the right table. |
82. What are Window Functions in SQL and how do they differ from regular aggregate functions?
Window Functions: A window function performs calculations over a set of rows related to the current row, but it still keeps the original rows in the result. For example, you can use a window function to calculate a running total for each row without losing the row’s original data. Some examples of window functions are ROW_NUMBER(), RANK() and SUM() with the OVER() clause.
Difference from Aggregate Functions: Regular aggregate functions like SUM(), COUNT() and AVG() group rows together and return just one result for each group. But window functions let you calculate across rows while still showing the individual rows. For example, with window functions, you can get a running total on each row while keeping all the details of each row.
In SQL, we can perform mathematical calculations in queries using arithmetic operators and functions. Here are some common methods for performing mathematical calculations.
- Arithmetic Operators
- Mathematical Functions
- Aggregate Functions
- Custom Expressions
84. What is the difference between a JOIN and a SUBQUERY in SQL and when would you use each?
JOIN: A JOIN is used to combine data from two or more tables based on a shared column. For example, if you have a table of customers and a table of orders, you can use a JOIN to link customer information with their orders. There are different types of joins like INNER JOIN (to get matching rows) or LEFT JOIN (to get all rows from the left table and matching ones from the right).
SUBQUERY: A SUBQUERY is a query within another query. It’s used when you need to get a value or a set of values to use in the outer query. For example, you might use a subquery to find customers who spent more than a certain amount, then use that result in another query.
85. What is the difference between a Database and a Data Warehouse?
Database: Consistency and real-time data processing are prioritised and they are optimised for storing, retrieving and managing structured data. Databases are frequently used for administrative functions like order processing, inventory control and customer interactions.
Data Warehouse: Data warehouses are made for processing analytical data. They are designed to facilitate sophisticated querying and reporting by storing and processing massive amounts of historical data from various sources. Business intelligence, data analysis and decision-making all employ data warehouses.
Deep Learning and Artificial Intelligence
Beginner Level Questions
86. Explain the convolution operations of CNN architecture.
In a Convolutional Neural Network (CNN), convolutions help the model find important features in images like edges or textures. Small filters (also called kernels) slide over the image, checking one small part at a time. These filters look for patterns by doing a calculation at each position, creating something called a feature map.
The strides control how far the filter moves at each step. This helps the network recognize the same feature, even if it's in a different part of the image. After convolutions, pooling layers shrink the feature maps, keeping the important details while making the data smaller and faster to process.
In short, convolution operations help CNNs find features in images and recognize patterns, no matter where they are in the image.
87. What is Feed Forward Network and how it is different from Recurrent Neural Network?
Deep learning designs that are basic are feedforward neural networks and recurrent neural networks. They are both employed for different tasks, but their structure and how they handle sequential data differ.
Feed Forward Neural Network
- In FFNN, the information flows in one direction, from input to output, with no loops
- It consists of multiple layers of neurons, typically organized into an input layer, one or more hidden layers and an output layer.
- Each neuron in a layer is connected to every neuron in the subsequent layer through weighted connections.
- FNNs are primarily used for tasks such as classification and regression where they take a fixed-size input and produce a corresponding output
Recurrent Neural Network
- A recurrent neural network is designed to handle sequential data where the order of input elements matters. Unlike FNNs, RNNs have connections that loop back on themselves allowing them to maintain a hidden state that carries information from previous time steps.
- This hidden state enables RNNs to capture temporal dependencies and context in sequential data, making them well-suited for tasks like natural language processing, time series analysis and sequence generation.
- However, standard RNNs have limitations in capturing long-range dependencies due to the vanishing gradient problem.
88. Explain the difference between generative and discriminative models?
Generative models and discriminative models are used for different purposes in machine learning. Generative models try to understand how data is generated, meaning they learn the relationship between input data 𝑋 and target labels 𝑌. This allows them to create new data that looks like the original dataset. These models are often used for generating new images, text or other types of data. Examples of generative models include GANs (Generative Adversarial Networks) and VAEs (Variational Autoencoders).
On the other hand, discriminative modelsfocus on distinguishing between different classes or making predictions based on the input data. They learn the relationship between the input 𝑋 and the target 𝑌 directly, without trying to generate new data. Discriminative models are typically used for tasks like classification where you need to assign a label to new data. Examples include Logistic Regression, Support Vector Machines (SVMs) and CNNs (Convolutional Neural Networks) for image classification.
89. What is the forward and backward propogations in deep learning?
- Forward Propagation: This is the process of passing input data through the network to generate predictions. The data moves from the input layer through hidden layers where each neuron processes the data, applies an activation function and sends the output to the next layer. The final output layer generates the prediction.
- Backward Propagation: After forward propagation, the model calculates the error by comparing the prediction to the actual result. Then, using the chain rule, it calculates the gradients of the error with respect to each parameter (weights and biases). These gradients are used to update the parameters (weights and biases) to reduce the error in future predictions.
90. Describe the use of Markov models in sequential data analysis?
Markov Models are effective methods for capturing and modeling dependencies between successive data points or states in a sequence. They are especially useful when the current condition is dependent on earlier states. The Markov property which asserts that the future state or observation depends on the current state and is independent of all prior states. There are two types of Markov models used in sequential data analysis:
- Markov chains are the simplest form of Markov models, consisting of a set of states and transition probabilities between these states. Each state represents a possible condition or observation and the transition probabilities describe the likelihood of moving from one state to another.
- Hidden Markov Models extend the concept of Markov chains by introducing a hidden layer of states and observable emissions associated with each hidden state. The true state of the system (hidden state) is not directly observable, but the emissions are observable.
Applications:
- HMMs are used to model phonemes and words in speech recognition systems allowing for accurate transcription of spoken language
- HMMs are applied in genomics for gene prediction and sequence alignment tasks. They can identify genes within DNA sequences and align sequences for evolutionary analysis.
- Markov models are used in modeling financial time series data such as stock prices, to capture the dependencies between consecutive observations and make predictions.
91. What is Generative AI?
Generative AI is an abbreviation for Generative Artificial Intelligence which refers to a class of artificial intelligence systems and algorithms that are designed to generate new, unique data or material that is comparable to or indistinguishable from, human-created data. It is a subset of artificial intelligence that focuses on the creative component of AI allowing machines to develop innovative outputs such as writing, graphics, audio and more. There are several generative AI models and methodologies, each adapted to different sorts of data and applications such as:
- Generative AI models such as GPT (Generative Pretrained Transformer) can generate human-like text.” Natural language synthesis, automated content production and chatbot responses are all common uses for these models.
- Images are generated using generative adversarial networks (GANs).” GANs are made up of a generator network that generates images and a discriminator network that determines the authenticity of the generated images. Because of the struggle between the generator and discriminator, high-quality, realistic images are produced.
- Generative AI can also create audio content such as speech synthesis and music composition.” Audio content is generated using models such as WaveGAN and Magenta.
Advanced Level Questions
92. What are different neural network architecture used to generate artificial data in deep learning?
Various neural networks are used to generate artificial data. Here are some of the neural network architectures used for generating artificial data:
- GANs consist of two components – generator and discriminator which are trained simultaneously through adversarial training. They are used to generating high-quality images such as photorealistic faces, artwork and even entire scenes.
- VAEs are generative models that learn a probabilistic mapping from the data space to a latent space. They also consist of encoder and decoder. They are used for generating images, reconstructing missing parts of images and generating new data samples. They are also applied in generating text and audio.
- RNNs are a class of neural networks with recurrent connections that can generate sequences of data. They are often used for sequence-to-sequence tasks. They are used in text generation, speech synthesis, music composition.
- Transformers are a type of neural network architecture that has gained popularity for sequence-to-sequence tasks. They use self-attention mechanisms to capture dependencies between different positions in the input data. They are used in natural language processing tasks like machine translation, text summarization and language generation.
- Autoencoders are neural networks that are trained to reconstruct their input data. Variants like denoising autoencoders and contractive autoencoders can be used for data generation. They are used for image denoising, data inpainting and generating new data samples.
93. What is Deep Reinforcement Learning technique?
Deep Reinforcement Learning (DRL) is a cutting-edge machine learning technique that combines the principles of reinforcement learning with the capability of deep neural networks. Its ability to enable machines to learn difficult tasks independently by interacting with their environments, similar to how people learn via trial and error, has garnered significant attention.
DRL is made up of three fundamental components:
- The agent interacts with the environment and takes decision.
- The environment is the outside world with which the agent interacts and receives feedback.
- The reward signal is a scalar value provided by the environment after each action, guiding the agent toward maximizing cumulative rewards over time.
Applications:
- In robotics, DRL is used to control robots, manipulation and navigation.
- DRL plays a role in self-driving cars and vehicle control
- Can also be used for customized recommendations
94. What is transfer learning and how is it applied in deep learning?
Transfer learning is a technique where a model trained on one task is used to help solve a different, but similar task. Instead of starting from scratch, the model uses what it has already learned from a large dataset to make learning faster and easier for a new task.
The process has two main steps: feature extraction and fine-tuning. First, in feature extraction, the pretrained model is used to get useful features from the new data while ignoring the final prediction layers. Then, in fine-tuning, new layers are added to the model and the model is adjusted to fit the new task by learning from the target data. This helps save time, reduce computing power and improve the model's performance, especially when there's not much data available for the new task.
95. What is difference between Object Detection and Image Segmentation?
Object detection and Image segmentation are both computer vision tasks that entail evaluating and comprehending image content, but they serve different functions and give different sorts of information.
Object Detection:
- Goal of object detection is to identify and locate objects and represent the object in bounding boxes with their respective labels.
- Used in applications like autonomous driving for detecting pedestrians and vehicle
Image Segmentation:
- Focuses on partitioning an image into multiple regions where each segment corresponding to a coherent part of the image.
- Provide pixel level labeling of the entire image
- Used in applications that require pixel level understanding such as medical image analysis for organ and tumor delineation.
96. Explain the concept of word embeddings in Natural Language Processing (NLP).
In NLP, the concept of word embedding is use to capture semantic and contextual information. Word embeddings are dense representations of words or phrases in continuous-valued vectors in a high-dimensional space. Each word is mapped to a vector with the real numbers, these vectors are learned from large corpora of text data.
Word embeddings are based on the Distributional Hypothesis which suggests that words that appear in similar context have similar meanings. This idea is used by word embedding models to generate vector representations that reflect the semantic links between words depending on how frequently they co-occur with other words in the text.
The most common word embeddings techniques are:
- Bag of Words (BOW)
- Word2Vec
- Glove: Global Vector for word representation
- Term frequency-inverse document frequency (TF-IDF)
- BERT
97. What is seq2seq model?
A neural network architecture called a Sequence-to-Sequence (Seq2Seq) model is made to cope with data sequences, making it particularly helpful for jobs involving variable-length input and output sequences. Machine translation, text summarization, question answering and other tasks all benefit from its extensive use in natural language processing.
The Seq2Seq consists of two main components: encoder and decoder. The encoder takes input sequence and converts into fixed length vector . The vector captures features and context of the sequence. The decoder takes the vector as input and generated output sequence. This autoregressive technique frequently entails influencing the subsequent prediction using the preceding one.
98. What is Artificial Neural Networks?
Artificial Neural Networks take inspiration from structure and functioning of human brain. The computational units in ANN are called neurons and these neurons are responsible to process and pass the information to the next layer.
ANN has three main components:
- Input Layer: where the network receives input features.
- Hidden Layer: one or more layers of interconnected neurons responsible for learning patterns in the data
- Output Layer: provides final output on processed information.
Similar Reads
Data Science Tutorial Data Science is a field that combines statistics, machine learning and data visualization to extract meaningful insights from vast amounts of raw data and make informed decisions, helping businesses and industries to optimize their operations and predict future trends.This Data Science tutorial offe
3 min read
Introduction to Machine Learning
What is Data Science?Data science is the study of data that helps us derive useful insight for business decision making. Data Science is all about using tools, techniques, and creativity to uncover insights hidden within data. It combines math, computer science, and domain expertise to tackle real-world challenges in a
8 min read
Top 25 Python Libraries for Data Science in 2025Data Science continues to evolve with new challenges and innovations. In 2025, the role of Python has only grown stronger as it powers data science workflows. It will remain the dominant programming language in the field of data science. Its extensive ecosystem of libraries makes data manipulation,
10 min read
Difference between Structured, Semi-structured and Unstructured dataBig Data includes huge volume, high velocity, and extensible variety of data. There are 3 types: Structured data, Semi-structured data, and Unstructured data. Structured data - Structured data is data whose elements are addressable for effective analysis. It has been organized into a formatted repos
2 min read
Types of Machine LearningMachine learning is the branch of Artificial Intelligence that focuses on developing models and algorithms that let computers learn from data and improve from previous experience without being explicitly programmed for every task.In simple words, ML teaches the systems to think and understand like h
13 min read
What's Data Science Pipeline?Data Science is a field that focuses on extracting knowledge from data sets that are huge in amount. It includes preparing data, doing analysis and presenting findings to make informed decisions in an organization. A pipeline in data science is a set of actions which changes the raw data from variou
3 min read
Applications of Data ScienceData Science is the deep study of a large quantity of data, which involves extracting some meaning from the raw, structured, and unstructured data. Extracting meaningful data from large amounts usesalgorithms processing of data and this processing can be done using statistical techniques and algorit
6 min read
Python for Machine Learning
Learn Data Science Tutorial With PythonData Science has become one of the fastest-growing fields in recent years, helping organizations to make informed decisions, solve problems and understand human behavior. As the volume of data grows so does the demand for skilled data scientists. The most common languages used for data science are P
3 min read
Pandas TutorialPandas is an open-source software library designed for data manipulation and analysis. It provides data structures like series and DataFrames to easily clean, transform and analyze large datasets and integrates with other Python libraries, such as NumPy and Matplotlib. It offers functions for data t
6 min read
NumPy Tutorial - Python LibraryNumPy (short for Numerical Python ) is one of the most fundamental libraries in Python for scientific computing. It provides support for large, multi-dimensional arrays and matrices along with a collection of mathematical functions to operate on arrays.At its core it introduces the ndarray (n-dimens
3 min read
Scikit Learn TutorialScikit-learn (also known as sklearn) is a widely-used open-source Python library for machine learning. It builds on other scientific libraries like NumPy, SciPy and Matplotlib to provide efficient tools for predictive data analysis and data mining.It offers a consistent and simple interface for a ra
3 min read
ML | Data Preprocessing in PythonData preprocessing is a important step in the data science transforming raw data into a clean structured format for analysis. It involves tasks like handling missing values, normalizing data and encoding variables. Mastering preprocessing in Python ensures reliable insights for accurate predictions
6 min read
EDA - Exploratory Data Analysis in PythonExploratory Data Analysis (EDA) is a important step in data analysis which focuses on understanding patterns, trends and relationships through statistical tools and visualizations. Python offers various libraries like pandas, numPy, matplotlib, seaborn and plotly which enables effective exploration
6 min read
Introduction to Statistics
Statistics For Data ScienceStatistics is like a toolkit we use to understand and make sense of information. It helps us collect, organize, analyze and interpret data to find patterns, trends and relationships in the world around us.From analyzing scientific experiments to making informed business decisions, statistics plays a
12 min read
Descriptive StatisticStatistics is the foundation of data science. Descriptive statistics are simple tools that help us understand and summarize data. They show the basic features of a dataset, like the average, highest and lowest values and how spread out the numbers are. It's the first step in making sense of informat
5 min read
What is Inferential Statistics?Inferential statistics is an important tool that allows us to make predictions and conclusions about a population based on sample data. Unlike descriptive statistics, which only summarizes data, inferential statistics lets us test hypotheses, make estimates and measure the uncertainty about our pred
7 min read
Bayes' TheoremBayes' Theorem is a mathematical formula used to determine the conditional probability of an event based on prior knowledge and new evidence. It adjusts probabilities when new information comes in and helps make better decisions in uncertain situations.Bayes' Theorem helps us update probabilities ba
13 min read
Probability Data Distributions in Data ScienceUnderstanding how data behaves is one of the first steps in data science. Before we dive into building models or running analysis, we need to understand how the values in our dataset are spread out and that’s where probability distributions come in.Let us start with a simple example: If you roll a f
8 min read
Parametric Methods in StatisticsParametric statistical methods are those that make assumptions regarding the distribution of the population. These methods presume that the data have a known distribution (e.g., normal, binomial, Poisson) and rely on parameters (e.g., mean and variance) to define the data.Key AssumptionsParametric t
6 min read
Non-Parametric TestsNon-parametric tests are applied in hypothesis testing when the data does not satisfy the assumptions necessary for parametric tests, such as normality or equal variances. These tests are especially helpful for analyzing ordinal data, small sample sizes, or data with outliers.Common Non-Parametric T
5 min read
Hypothesis TestingHypothesis testing compares two opposite ideas about a group of people or things and uses data from a small part of that group (a sample) to decide which idea is more likely true. We collect and study the sample data to check if the claim is correct.Hypothesis TestingFor example, if a company says i
9 min read
ANOVA for Machine LearningANOVA is useful when we need to compare more than two groups and determine whether their means are significantly different. Suppose you're trying to understand which ingredients in a recipe affect its taste. Some ingredients, like spices might have a strong influence while others like a pinch of sal
9 min read
Bayesian Statistics & ProbabilityBayesian statistics sees unknown values as things that can change and updates what we believe about them whenever we get new information. It uses Bayes’ Theorem to combine what we already know with new data to get better estimates. In simple words, it means changing our initial guesses based on the
6 min read
Feature Engineering
Model Evaluation and Tuning
Data Science Practice