计算 Pandas 的百分比变化
Fariba Laiq 2024年2月15日 Pandas

pct_change() 是 Pandas 中的一个函数,默认情况下计算前一行元素之间的百分比变化。在时间序列数据的情况下,这个函数被频繁使用。
此函数的输出是一个 DataFrame,其中包含上一行的百分比变化值。当我们调用这个函数时,我们可以指定其他行作为参数进行比较。
它适用于以下公式。
$$ Pct \space Change = {(Current-Previous) \over Previous}*100 $$
使用 pct_change() 计算 Pandas 的百分比变化
此方法接受四个可选参数,如下所示。
periods- 具有默认值1。它指定要移动的期间以计算百分比变化。fill_method- 指定在计算百分比变化之前如何处理 NA。limit- 指定在停止之前要填充的连续 NA 的数量。freq- 从时间序列 API 中使用的增量(例如'M'或BDay())。
以下是计算两行之间百分比变化的简单代码。我们将使用 DataFrame 对象调用 pct_change() 方法,而不传递任何参数。
# Python 3.x import pandas as pd df = pd.DataFrame([[2, 4, 6], [1, 2, 3], [5, 7, 9]]) print(df.pct_change()) 输出:

在计算 Pandas 的百分比变化之前填充缺失值
例如,我们在 DataFrame 中有 missing 或 None 值。在计算百分比变化时,缺失的数据将由上一行中的相应值填充。
这里,ffill 表示前向填充。
# Python 3.x import pandas as pd df = pd.DataFrame([[2, 4, 6], [1, None, 3], [None, 7, 9]]) print(df.pct_change(fill_method="ffill")) 
计算 Pandas 中 Multi-Index DataFrame 的百分比变化
我们还可以计算多索引 DataFrame 的百分比变化。我们可以使用 groupby() 方法根据某些标准将数据分成组,然后应用 pct_change()。
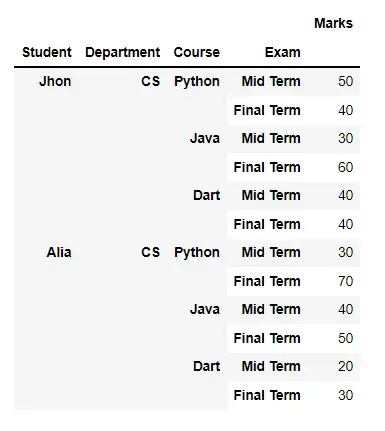
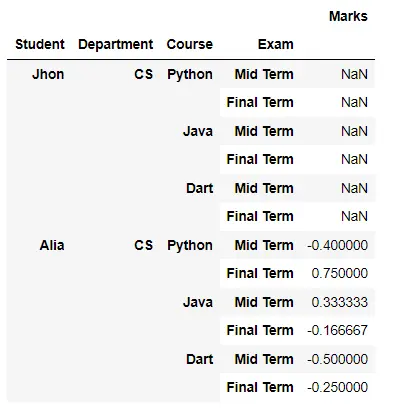
# Python 3.x df = pd.DataFrame( index=pd.MultiIndex.from_product( [ ["Jhon", "Alia"], ["CS"], ["Python", "Java", "Dart"], ["Mid Term", "Final Term"], ], names=["Student", "Department", "Course", "Exam"], ), data={"Marks": [50, 40, 30, 60, 40, 40, 30, 70, 40, 50, 20, 30]}, ) print(df) print(df.groupby(level=[1, 2, 3]).pct_change()) 输出:
Enjoying our tutorials? Subscribe to DelftStack on YouTube to support us in creating more high-quality video guides. Subscribe
作者: Fariba Laiq

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn