






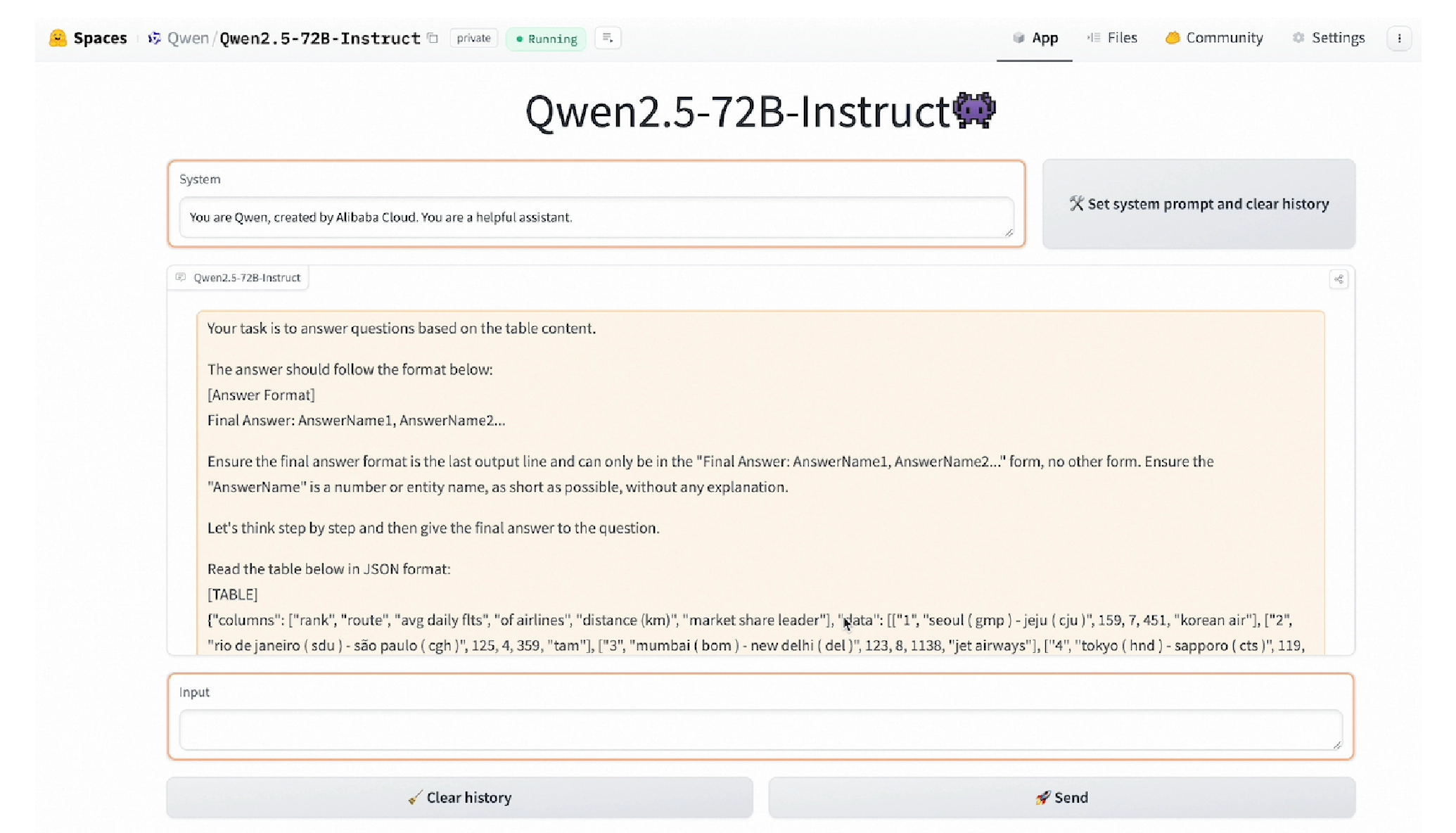


Qwen understands structured data (such as tables) better. This contributes to extracting insightful information from structured data, helping users perform queries, and generating new datasets. For example, Qwen2.5-72B can provide formatted outputs based on the requirement and input data (table in JSON format).
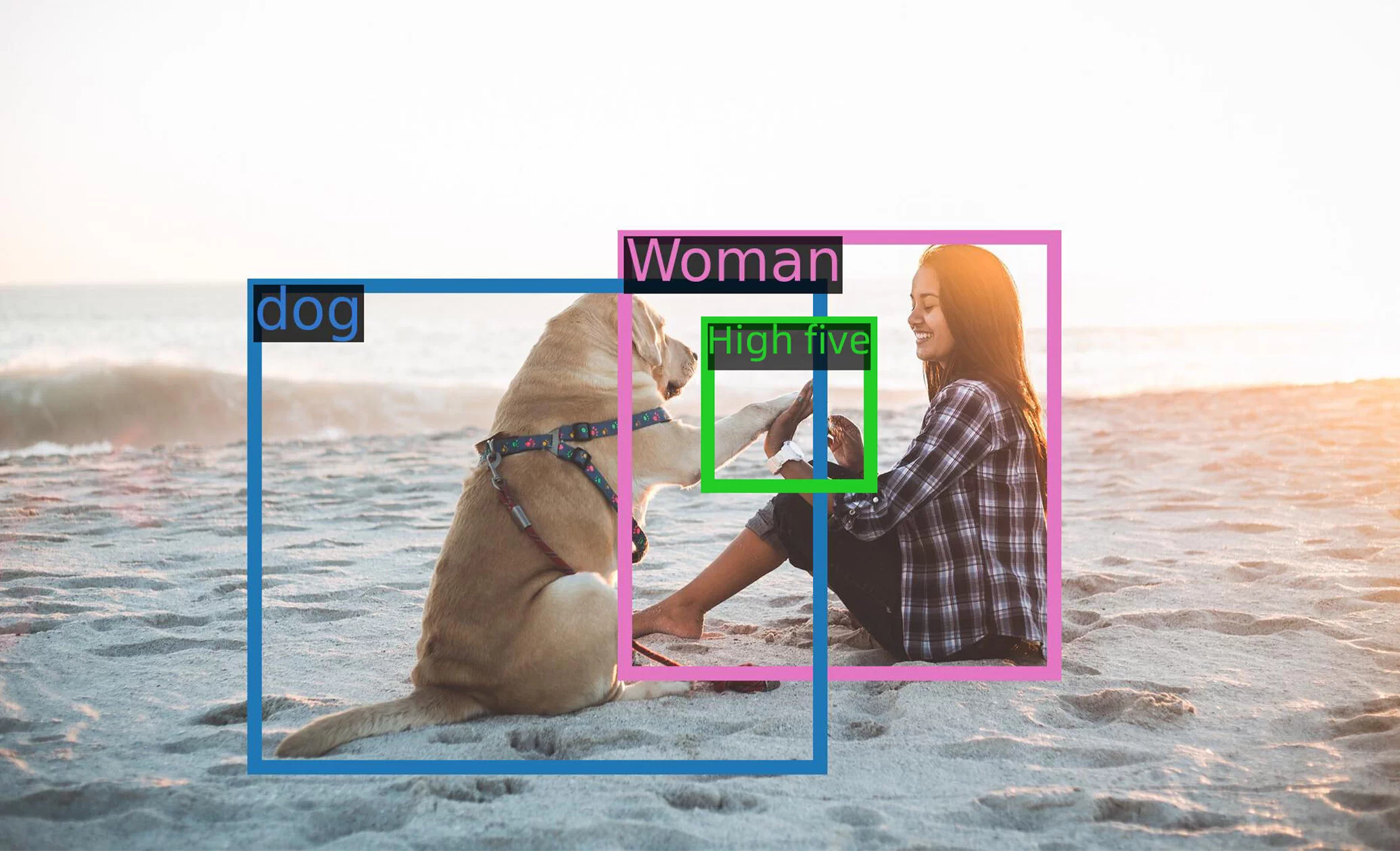
Qwen-VL learns and analyzes objects and texts in images and creates new content based on its learning. For example, it can recognize the woman and the dog in the picture and their gestures (high five).
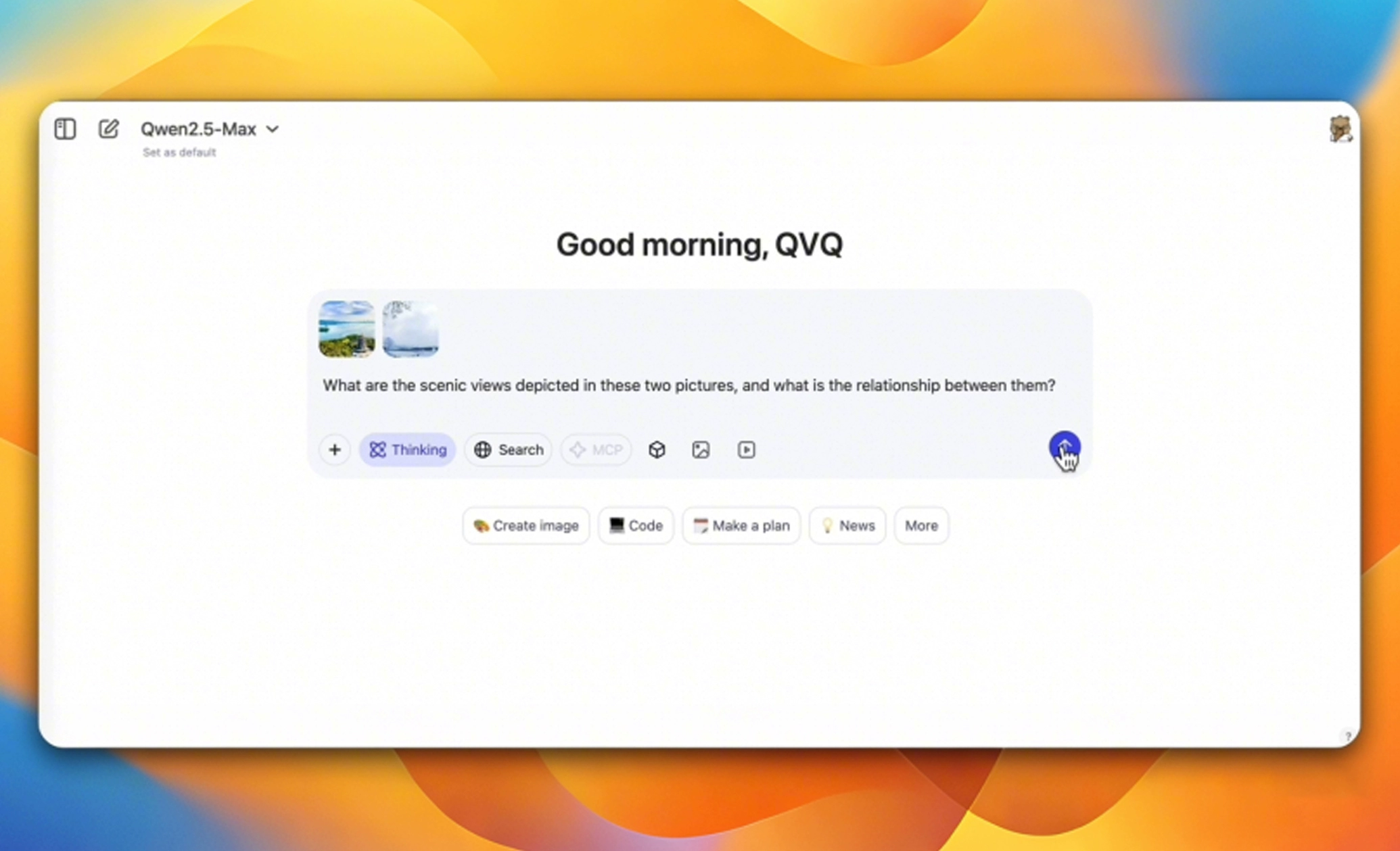
QVQ can analyze and understand the content that the two images depict in real life, understand the user request, analyze the content, and use CoT to “think” and find the connection between the content in these images.
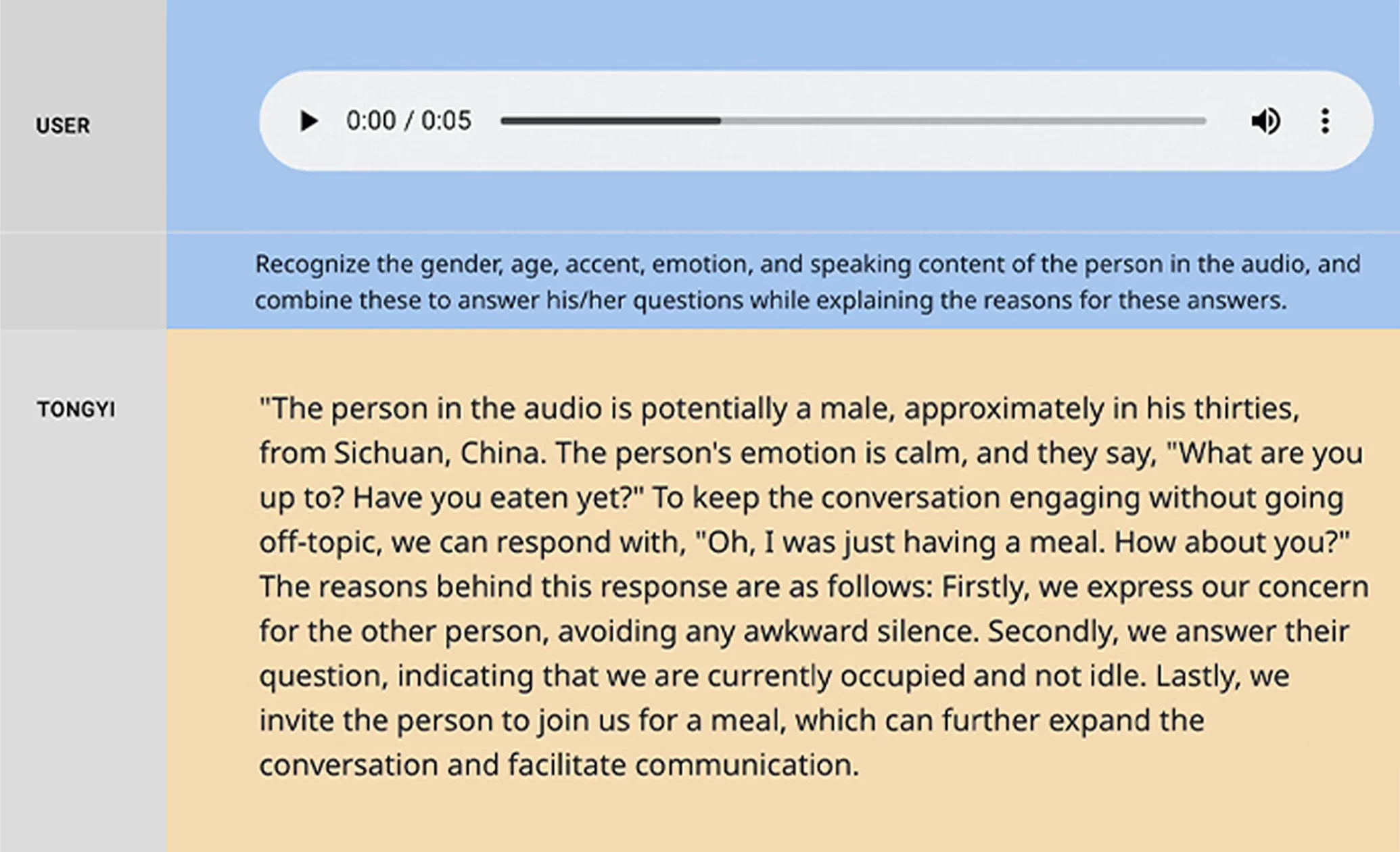
Qwen-Audio can accept diverse types of audio (such as human speech, natural sounds, instrumental music, and songs) and text as inputs, understand the audio content, and summarize information such as music genres and emotions of the speaker. It can also use tools to edit the audio files.
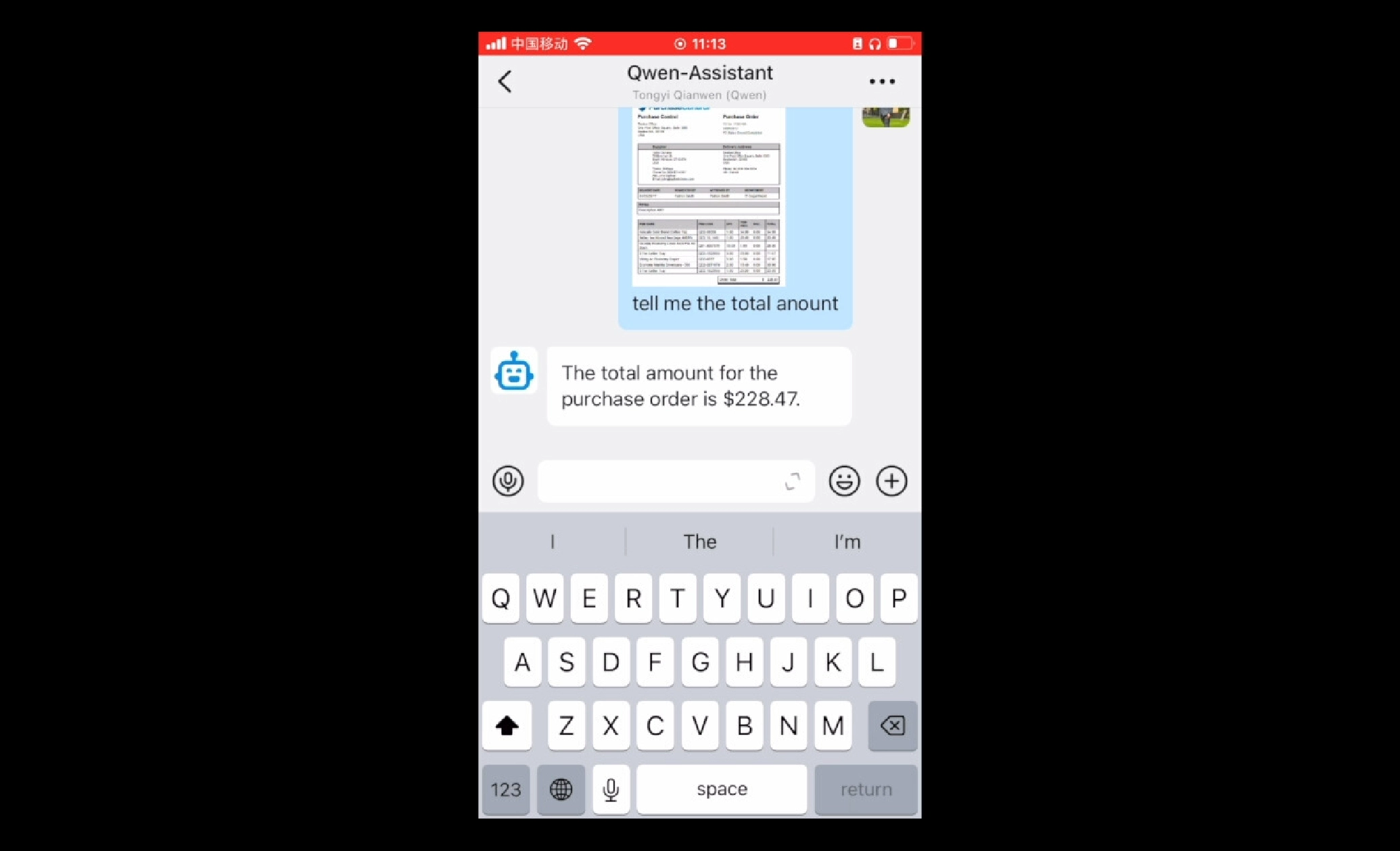
You can use Qwen models (Qwen, Qwen-Audio, and Qwen-VL, etc.) to build a chat assistant that interacts with users intelligently and comprehensively and understands multimodal data, including text, images, audio, and videos.





