

Scraping using headless browser tools like Selenium library for Python is becoming an increasingly popular web scraping technique. Unfortunately, scaling up Selenium-powered scrapers can be a difficult challenge. This is where Selenium Grid for web scraping comes in - a cross-platform testing service for parallel headless browser processing.
In this guide, we'll explain how to use Selenium Grid Python to scrape at scale. We'll cover essential topics like how to install Selenium grid using Docker, managing browser instances and concurrent web scraping using Selenium Grid. Let's dig in!
What is Selenium Grid?
Selenium Grid is a server that runs multiple Selenium tests on the same remote machine. It enables automating multiple tests of web browsers for different operating systems and versions.
The Selenium Grid architecture consists of two main components:
- Hub
A remote server that accepts incoming WebDriver requests as JSON and then routes them to the Nodes for execution. - Node
A virtual device that executes commands based on routing instructions from the Hub. It consists of a specific web browser and version running on a particular operating system.

Selenium Grid nodes enable parallel testing by scaling the number of headless browsers, which can be used to run tests remotely on multiple machines at once using its API through HTTP requests. Unlike the regular Selenium WebDriver, which runs headless browsers using a dedicated WebDriver on the same local machine through the localhost network.
Before we jump into the Selenium Grid Python web scraping details, let's look at the installation process.
Selenium Grid Setup
When it comes to integrating Selenium Grid, the easiest approach is to use Docker. If you don't have Docker installed, you can install it from the official Docker installation page .
To spin up to the Selenium Grid server, we'll use the following docker-compose.yml file:
version: '3.8' services: hub: image: selenium/hub:4.13.0 ports: - 4442:4442 - 4443:4443 - 4444:4444 environment: GRID_MAX_SESSION: 8 chrome_node_1: image: selenium/node-chrome:4.13.0 depends_on: - hub environment: # selenium webdriver bindings SE_EVENT_BUS_HOST: hub SE_EVENT_BUS_PUBLISH_PORT: 4442 SE_EVENT_BUS_SUBSCRIBE_PORT: 4443 SE_NODE_STEREOTYPE: "{\"browserName\":\"chrome\",\"browserVersion\":\"117\",\"platformName\": \"Windows 10\"}" Here, we initialize a Hub and Node services and specify the Node's browser name, version and operating system. If you want to use a specific Hub or Node version, refer to the official Selenium page on Docker for the different browsers available..
After adding the above docker-compose file, run it using the following Docker command:
docker-compose up --build To ensure your installation is correct, go to the Selenium Grid URL on http://localhost:4444 which should result in a Selenium Grid Dashboard view:
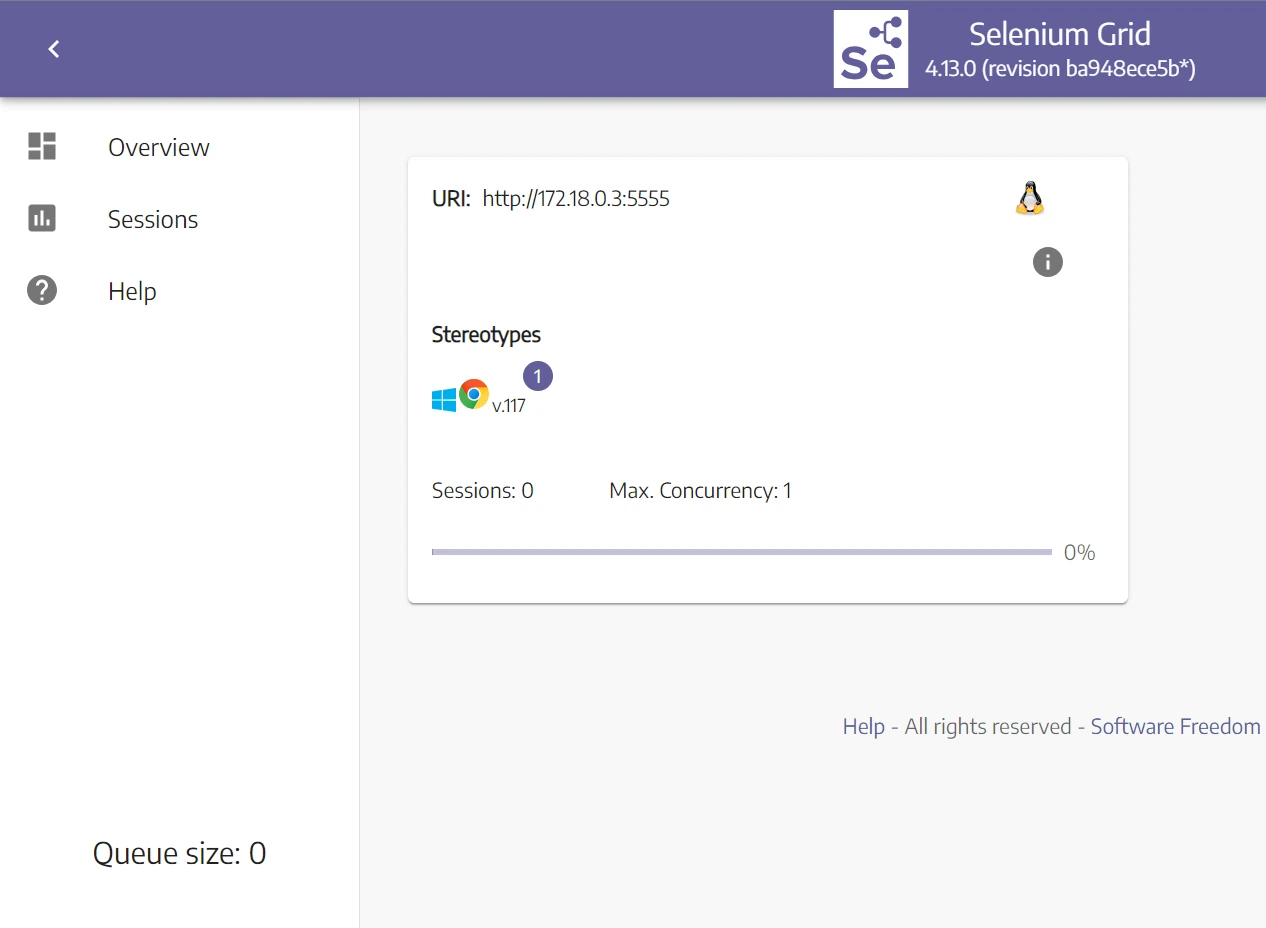
We only have a single Node with the browser specifications declared in the docker-compose file, meaning the processing capabilities are limited to a single testing process. We can also see additional variables, let's go over them:
- Sessions: the number of headless browsers running on a specific Node.
- Max concurrency: the number of sessions that can run in parallel in each Node, which is set to one by default.
- Queue size: the number of sessions waiting in the queue. Since we don't have any sessions in the queue, it's set to zero.
Now that we have Selenium Grid Docker up and running, let's install selenium webdriver bindings via the selenium package and beautifulsoup4 to parse HTML:
pip install selenium bs4 Web Scraping With Selenium Grid
In this Selenium Grid web scraping guide, we'll scrape product data from web-scraping.dev/productso page:
There are several pages on this website and each page contains multiple products. We'll divide our Selenium Grid Scraping code into two parts: product discover and product scraping.
First, we'll crawl over product pages to scrape each product link. Then, we'll scrape all product links concurrently.
Here is how to use Selenium Grid to scrape product links:
from selenium import webdriver from bs4 import BeautifulSoup def get_driver(): options = webdriver.ChromeOptions() # Disable sharing memory across the instances options.add_argument('--disable-dev-shm-usage') # Initialize a remote WebDriver driver = webdriver.Remote( command_executor="http://127.0.0.1:4444/wd/hub", options=options ) return driver def scrape_product_links(): links = [] driver = get_driver() # Iterate over product pages for page_number in range(1, 6): page_link = f"https://web-scraping.dev/products?page={page_number}" # Go to the page link driver.get(page_link) soup = BeautifulSoup(driver.page_source, "html.parser") # Iterate over product boxes for product_box in soup.select("div.row.product"): # Get the link of each product link = product_box.select_one("a").attrs["href"] links.append(link) return links links = scrape_lroduct_links() print(links) Using the get_driver function, we send a request to the Selenium Grid Hub to initialize a remote headless browser. Then, we loop through all product pages to get each product's link using the CSS selector.
Here are the links we got:
Output
[ "https://web-scraping.dev/product/1", "https://web-scraping.dev/product/2", "https://web-scraping.dev/product/3", "https://web-scraping.dev/product/4", "https://web-scraping.dev/product/5", "https://web-scraping.dev/product/6", "https://web-scraping.dev/product/7", "https://web-scraping.dev/product/8", "https://web-scraping.dev/product/9", "https://web-scraping.dev/product/10", "https://web-scraping.dev/product/11", "https://web-scraping.dev/product/12", "https://web-scraping.dev/product/13", "https://web-scraping.dev/product/14", "https://web-scraping.dev/product/15", "https://web-scraping.dev/product/16", "https://web-scraping.dev/product/17", "https://web-scraping.dev/product/18", "https://web-scraping.dev/product/19", "https://web-scraping.dev/product/20", "https://web-scraping.dev/product/21", "https://web-scraping.dev/product/22", "https://web-scraping.dev/product/23", "https://web-scraping.dev/product/24", "https://web-scraping.dev/product/25", ] We successfully scraped all product links using the remote headless browsers. However, our Selenium Grid server isn't scalable as it only allows running one headless browser at a time. For example, let's try to run two headless browsers in parallel:
from selenium import webdriver def get_driver(): options = webdriver.ChromeOptions() options.add_argument('--disable-dev-shm-usage') driver = webdriver.Remote( command_executor="http://127.0.0.1:4444/wd/hub", options=options ) return driver # Initialize two headless browsers at the same time driver1 = get_driver() print("Driver 1 is running") # The below code won't get executed driver2 = get_driver() print("Driver 2 is running") driver1.quit() print("Driver 1 is closed") driver2.quit() print("driver 2 is closed") In the above Python script, we initialize two headless browsers at the same time. The driver1 will run while driver2 will wait in the queue:
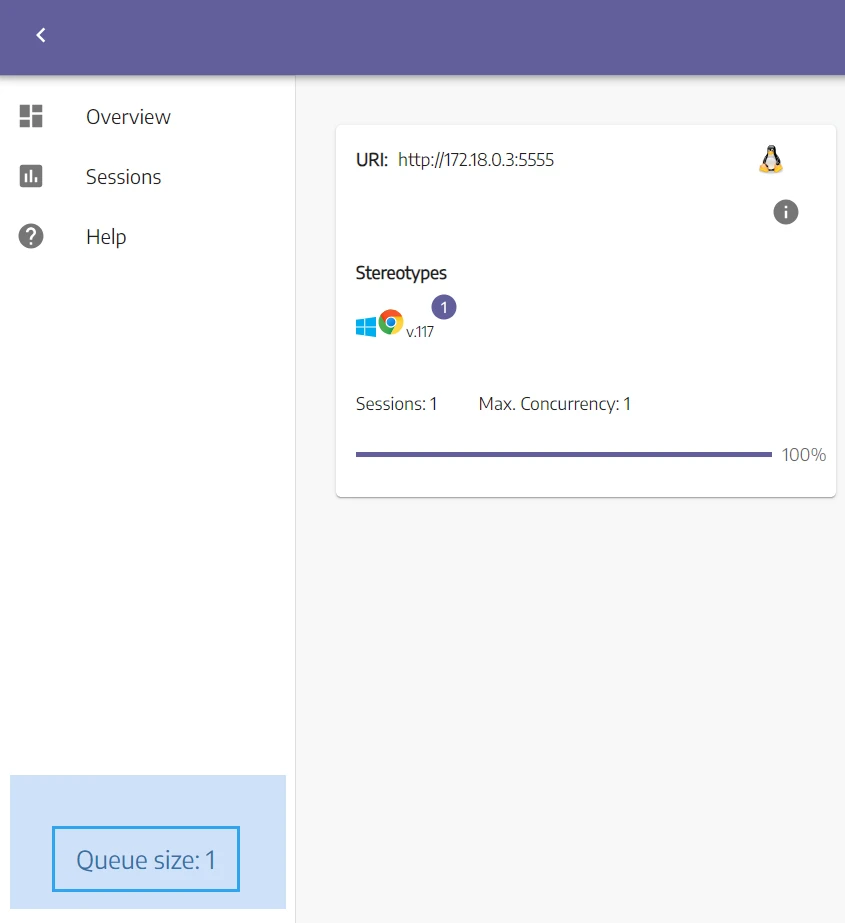
The script will wait for driver2 to get initialized before proceeding with the rest of the code. And since the max concurrency in our Node is set to one, the driver2 will block the script flow.
To solve this issue, we must configure Selenium Grid to spin up more Nodes or change the max concurrency in each Node. Let's see how!
Concurrency in Selenium Grid
Selenium Grid allows for customizing the number of Nodes and the maximum concurrency of each Node. To do that, we'll change the docker-compose.yml file we created earlier with additional services to extend the nodes registered:
version: '3.8' services: hub: image: selenium/hub:4.13.0 ports: - 4442:4442 - 4443:4443 - 4444:4444 environment: GRID_MAX_SESSION: 8 chrome_node_1: image: selenium/node-chrome:4.13.0 depends_on: - hub environment: SE_EVENT_BUS_HOST: hub SE_EVENT_BUS_PUBLISH_PORT: 4442 SE_EVENT_BUS_SUBSCRIBE_PORT: 4443 SE_NODE_MAX_SESSIONS: 2 SE_NODE_STEREOTYPE: "{\"browserName\":\"chrome\",\"browserVersion\":\"117\",\"platformName\": \"Windows 10\"}" chrome_node_2: image: selenium/node-chrome:4.13.0 depends_on: - hub environment: SE_EVENT_BUS_HOST: hub SE_EVENT_BUS_PUBLISH_PORT: 4442 SE_EVENT_BUS_SUBSCRIBE_PORT: 4443 SE_NODE_MAX_SESSIONS: 2 SE_NODE_STEREOTYPE: "{\"browserName\":\"chrome\",\"browserVersion\":\"117\",\"platformName\": \"macOS\"}" We add a chrome Node running on macOS and change the maximum concurrency variable to two concurrent sessions in each Node. This means that we can scrape with four headless browsers in parallel now!
To apply these changes, stop the docker containers and build them again using the following commands:
docker-compose down docker-compose up --build Head over to the Selenium Grid Dashboard, and you will find the new changes reflect multiple browsers available:
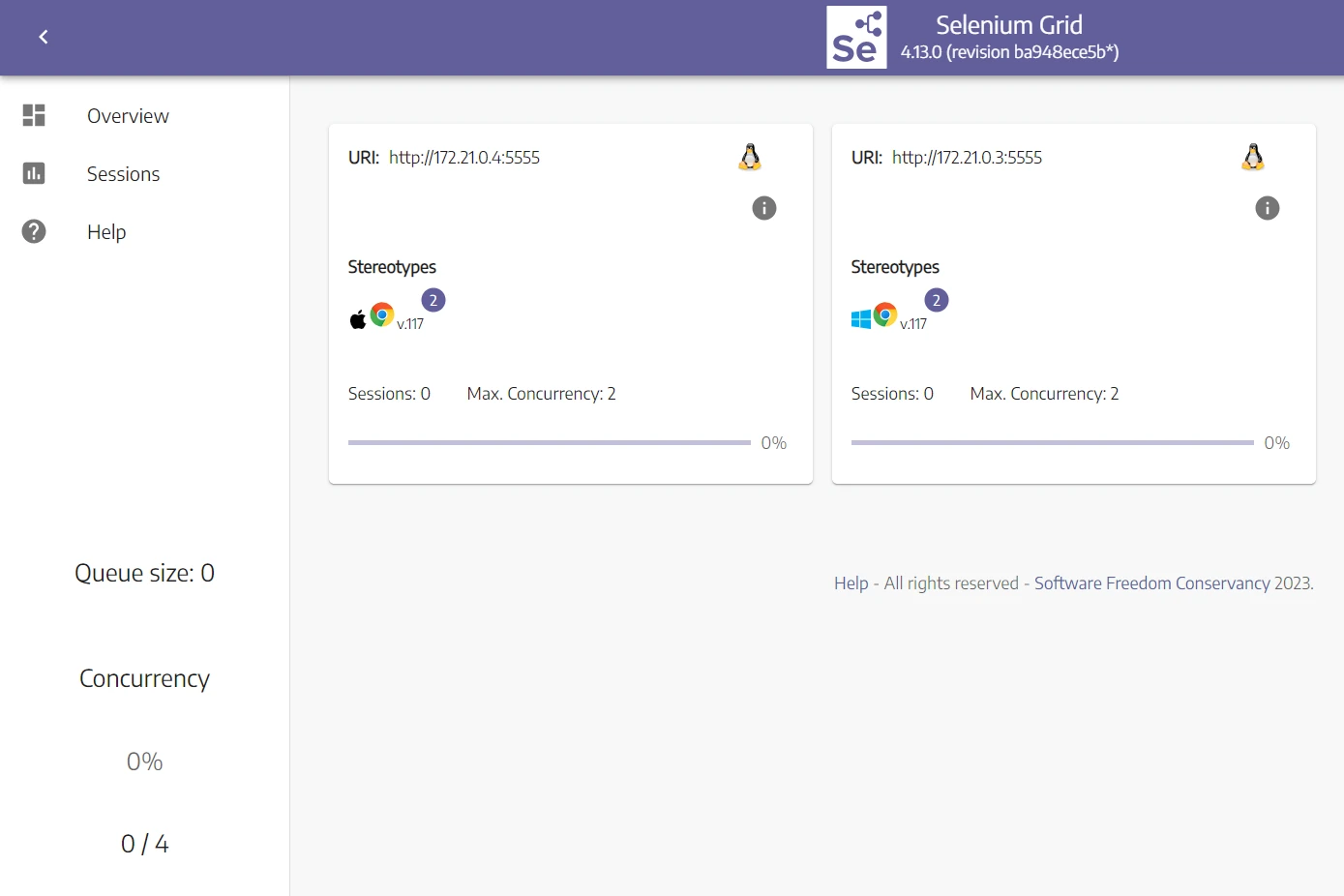
Now, let's try to run two headless browsers at the same time:
from selenium import webdriver def get_driver(): options = webdriver.ChromeOptions() options.add_argument('--disable-dev-shm-usage') driver = webdriver.Remote( command_executor="http://127.0.0.1:4444/wd/hub", options=options ) return driver # Initialize two headless browsers at the same time driver1 = get_driver() print("Driver 1 is running") # The below code will get executed driver2 = get_driver() print("Driver 2 is running") driver1.quit() print("Driver 1 is closed") driver2.quit() print("driver 2 is closed") Each Node will run a headless browser:
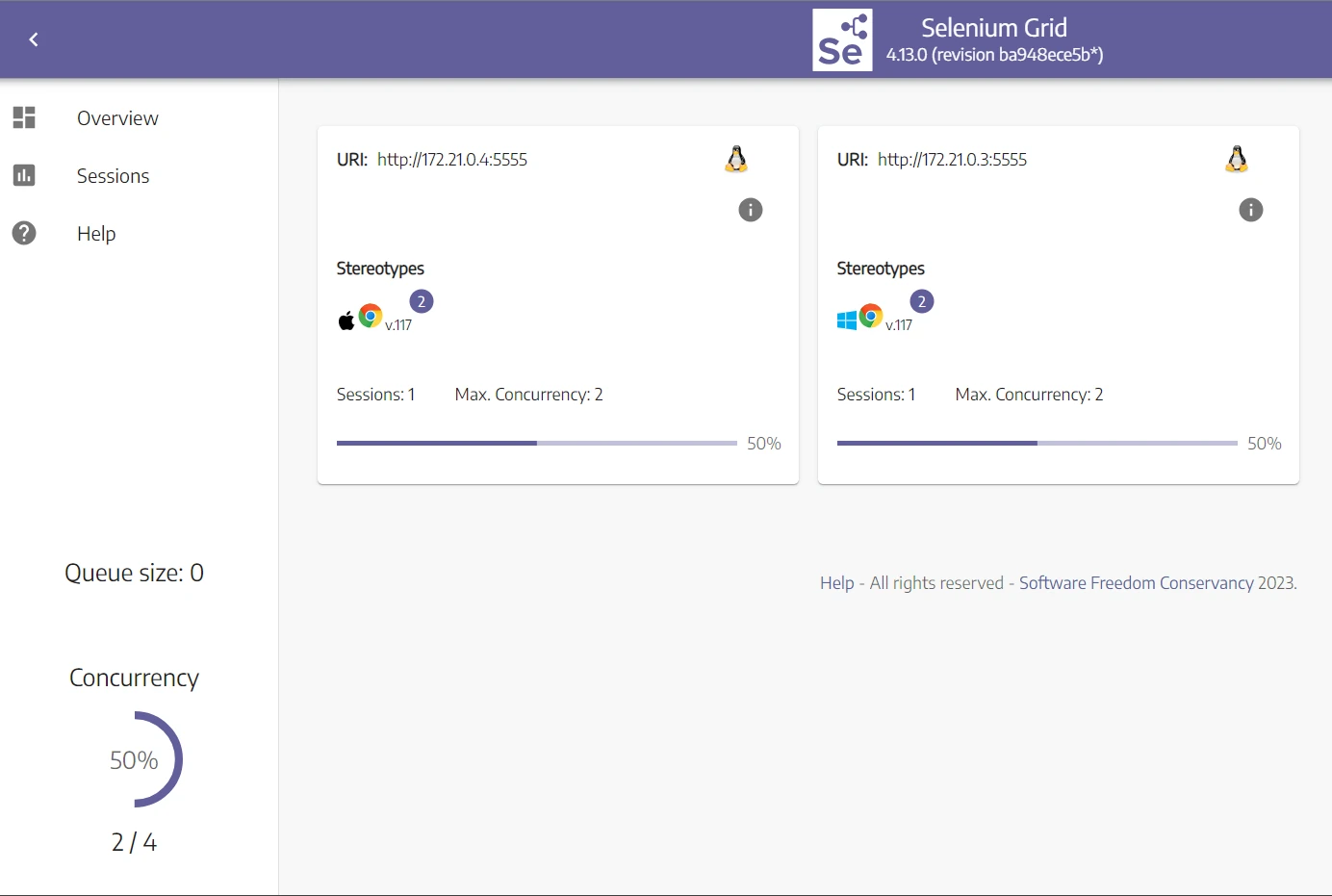
Now that we can run multiple headless browsers in parallel. Let's use it to apply concurrent web scraping with Selenium Grid.
Web Scraping Concurrently with Selenium Grid
Selenium Grid can run multiple node workers in parallel meaning we can use multiple nodes at the same time for concurrent web scraping. This can give our web scrapers a huge boost in speed and performance.
In this section, we'll take a look at how to utilize Selenium through Python threads to scrape using multiple selenium grid workers.
Web Scraping Speed: Processes, Threads and Async
Scaling web scrapers can be difficult - in this article we'll go over the core principles like subprocesses, threads and asyncio and how all of that can be used to speed up web scrapers dozens to hundreds of times.

Now, let's implement concurrent web scraping with Selenium Grid. We'll split the links we got earlier into two batches and scrape them in concurrently:
from concurrent.futures import ThreadPoolExecutor from selenium import webdriver from bs4 import BeautifulSoup import json def get_driver(): options = webdriver.ChromeOptions() options.add_argument("--disable-dev-shm-usage") options.add_argument("--headless") driver = webdriver.Remote( command_executor="http://127.0.0.1:4444/wd/hub", options=options ) return driver def scrape_product_links(): links = [] driver = get_driver() for page_number in range(1, 6): page_link = f"https://web-scraping.dev/products?page={page_number}" driver.get(page_link) soup = BeautifulSoup(driver.page_source, "html.parser") for product_box in soup.select("div.row.product"): link = product_box.select_one("a").attrs["href"] links.append(link) # Close the headless browser instance driver.quit() return links def scrape_product_data(links_array: list, data_array: list, driver_name: str): driver = get_driver() for link in links_array: # Print the current running driver print(driver_name, "is scraping product number", link.split("/")[-1]) driver.get(link) soup = BeautifulSoup(driver.page_source, "html.parser") # Get the product data data_array.append(parse_product_html(soup)) driver.quit() def parse_product_html(soup): product_data = { "product": soup.select_one("h3.card-title").text, "price": soup.select_one("span.product-price").text, # Extract all image links and save it to an array "images": [image["src"] for image in soup.select("div.product-images > img")], } return product_data if __name__ == "__main__": # Get all product links links = scrape_product_links() # Get the middle index to split the links array in half middle_index = len(links) // 2 # List of jobs to get executed executors_list = [] # An empty array to save the data data = [] # Create a ThreadPoolExecutor with a maximum of 4 worker threads with ThreadPoolExecutor(max_workers=4) as executor: # Add the two concurrent tasks to scrape product data from different parts of the 'links' list executors_list.append( executor.submit(scrape_product_data, links[:middle_index], data, "driver1") ) executors_list.append( executor.submit(scrape_product_data, links[middle_index:], data, "driver2") ) # Wait for all tasks to complete for x in executors_list: pass # Print the data in JSON format print(json.dumps(data, indent=4)) We use the scrape_product_links function created earlier to get product links.
Next, we create a ThreadPoolExecutor with a maximum of four thread workers. Then, we add two scrape_product_data functions and append them to the execution list, each function will scrape a link batch.
The above code will create two headless browsers running on Selenium Grid and run the scraping logic concurrently:
driver1 is scraping product number 1 driver2 is scraping product number 13 driver1 is scraping product number 2 driver2 is scraping product number 14 driver1 is scraping product number 3 driver2 is scraping product number 15 driver1 is scraping product number 4 Here are the results we got:
We successfully scraped all products concurrently using Selenium Grid. However, scraping at scale can be complex and requires lots of configurations. Let's explore a more efficient solution!
Web Scraping Concurrently with ScrapFly
Concurrency can be difficult to handle, especially when it comes to headless browser and this is where Scrapfly can help you scale up your browser scrapers.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
By using the ScrapFly concurrency feature, we can easily scale web scrapers by scraping multiple targets together:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse import asyncio from bs4 import BeautifulSoup import json scrapfly = ScrapflyClient(key="Your API key") # Scrape product links sequentially def scrape_product_links(): links = [] for page_number in range(1, 6): page_link = f"https://web-scraping.dev/products?page={page_number}" api_response: ScrapeApiResponse = scrapfly.scrape(scrape_config=ScrapeConfig(url=page_link)) soup = BeautifulSoup(api_response.scrape_result["content"], "html.parser") for product_box in soup.select("div.row.product"): link = product_box.select_one("a").attrs["href"] links.append(link) return links # Parse product data from the HTML def parse_product_html(soup): product_data = { "product": soup.select_one("h3.card-title").text, "price": soup.select_one("span.product-price").text, "images": [image['src'] for image in soup.select("div.product-images > img")] } return product_data # Scrape all product data concurrently async def scrape_product_data(links: list, data_array: list): # Add all links to the concurrent scraping target targets = [ScrapeConfig(url=url) for url in links] async for product_response in scrapfly.concurrent_scrape(scrape_configs=targets): page_content = product_response.content soup = BeautifulSoup(page_content, "html.parser") data_array.append(parse_product_html(soup)) # Empty array to store the data data = [] links = scrape_product_links() # Run the concurrent scraping function asyncio.run(scrape_product_data(links, data)) # Print the result in JSON format print (json.dumps(data, indent=4)) FAQ
To wrap up this guide on Selenium Grid for web scraping, let's take a look at some frequently asked questions.
Is Concurrent Web Scraping using Selenium Grid possible?
Yes, it's possible to integrate Selenium Grid for parallel execution, but it's not possible to execute the Selenium client asynchronously in Python. However, using Python threads or subprocesses, we can run multiple scrapers concurrently. For more see scraping using multiple processors.
What is the difference between Playwright, Selenium Web Driver and Selenium Grid?
Both Playwright and Selenium are automation frameworks that allow for running headless browsers locally. While Selenium Grid is server that complements Selenium WebDriver by allowing for running multiple headless browsers in parallel on a remote machine.
What are the limitations of Selenium Grid for Web Scraping?
Although Selenium Grid can be configured to scale web scrapers, it can't prevent headless browsers from getting blocked. For more information on this matter, refer to our previous article on scraping without getting blocked.
Selenium grid vs Selenium webdriver?
Selenium webdriver is the tool that automates a single web browser instance while Selenium Grid is a tool that orchestrates multiple Selenium webdrivers in parallel.
Selenium Grid For Web Scraping Summary
In summary, Selenium Grid is a remote server that executes WebDriver commands, allowing for running various headless browser scripts in parallel.
In this guide, we've taken a look at a major web scraping problem - how to speed up selenium web scrapers using Selenium Grid service. We started by exploring installing Selenium Grid on docker, its configuration and how to use it for concurrent web scraping with Python. In summary, Selenium Grid is a powerful tool for Selenium scaling but can be challenging to use in concurrent Python.




