

In the world of browser automation, Selenium has long been a key tool for browser automation, but it often involves tedious setups and limited features. SeleniumBase streamlines the process, enhancing Selenium’s capabilities with powerful, user-friendly tools for developers and testers alike.
This guide explores what SeleniumBase is, its features, and its practical use cases. And how it simplifies tasks like web scraping, testing, and screenshot capturing, all while being beginner-friendly and highly adaptable
What is SeleniumBase?
SeleniumBase is an open-source framework built on top of Selenium, providing a more intuitive, feature-rich interface for browser automation. Its primary goal is to simplify complex tasks with prebuilt methods and utilities while adding additional functionality like Cloudflare bypass, proxy integration, and enhanced debugging.Why SeleniumBase?
SeleniumBase takes browser automation to the next level by simplifying workflows, enhancing features, and offering unmatched versatility.
Ease of Use: With its clean and concise syntax, SeleniumBase allows you to achieve in a few lines what might take dozens with traditional Selenium, reducing development time and effort.
Enhanced Features: SeleniumBase expands Selenium’s functionality with built-in tools like seleniumBase screenshot capture, enhanced element locators, and advanced configurations, all designed to make automation more efficient and user-friendly.
Versatility: From robust test automation frameworks to advanced web scraping, SeleniumBase adapts to a variety of automation needs, making it a valuable tool for developers and testers alike.
Use Cases for SeleniumBase
SeleniumBase is a versatile tool designed to simplify browser automation across a wide range of applications. Here are some detailed examples of its use cases, showcasing its adaptability and power:
1. Web Application Testing
SeleniumBase is ideal for automating functional, and end-to-end (E2E) tests for web applications. Its simplified syntax, built-in assertions, and cross-browser support make it easy to simulate user actions and verify application behavior.
- Example: Testing an e-commerce site by simulating user login, adding items to the cart, and completing the checkout process.
- Key Features Used: Assertions, multi-browser testing, and headless mode for CI/CD pipelines.
2. Data Scraping and Extraction
SeleniumBase simplifies web scraping by handling dynamic content, JavaScript rendering, and anti-bot measures like Cloudflare. With its built-in proxy support, it can bypass restrictions and collect data efficiently.
- Example: Scraping product details, prices, and availability from an online store.
- Key Features Used: Dynamic content handling, proxy integration, and Cloudflare bypass.
3. Performance Monitoring
Monitor web application performance by automating repetitive actions and analyzing load times, response times, or element visibility. SeleniumBase can help identify bottlenecks or performance regressions.
- Example: Automating the navigation through critical workflows and measuring load times for key pages.
- Key Features Used: Customizable wait times, JavaScript execution, and detailed logs.
4. Visual Testing
Automate visual testing by capturing screenshots of web pages or individual elements to compare against baselines. SeleniumBase also supports annotated screenshots for better debugging and documentation.
- Example: Verifying UI consistency across browsers and screen resolutions.
- Key Features Used: SeleniumBase screenshot capturing, text overlays, and folder management for test assets.
By understanding these use cases, you can unlock the full potential of SeleniumBase to streamline testing, automate workflows, and solve complex challenges efficiently.
SeleniumBase Features
What sets SeleniumBase apart are the built-in tools and utilities that eliminate the need for external dependencies or custom scripts. Let’s break them down:
| Feature | Description |
|---|---|
| Simplified Syntax | Reduces boilerplate code with cleaner, more intuitive commands. |
| Screenshots | Automate visual testing with a single command to capture webpage screenshots. |
| SeleniumBase Cloudflare Handling | Overcome anti-bot protections effortlessly while scraping protected sites. |
| Proxy Support | Seamlessly configure SeleniumBase proxy for advanced scraping scenarios. |
| Enhanced Element Locators | Use seleniumbase find element methods for more reliable interactions. |
| Cross-Browser Compatibility | Supports Chrome, Firefox, Edge, and Safari with minimal configuration. |
| Options for Testing | Includes integrated testing utilities, customizable options, and reports. |
These features significantly reduce development time while boosting the reliability of your scripts.
SeleniumBase Examples
SeleniumBase provides a streamlined way to automate tasks, making it easy to create complex workflows with minimal code.
Using SeleniumBase for Testing
SeleniumBase integrates seamlessly with testing frameworks like pytest, offering tools such as assertions, reports, and headless browsing.
This example demonstrates a full test for an e-commerce website from official github example
from seleniumbase import BaseCase BaseCase.main(__name__, __file__) class MyTestClass(BaseCase): def test_swag_labs(self): # Open the website self.open("https://www.saucedemo.com") # Log in self.type("#user-name", "standard_user") self.type("#password", "secret_sauce\n") # Verify inventory page self.assert_element("div.inventory_list") self.assert_exact_text("Products", "span.title") # Add a product to the cart self.click('button[name*="backpack"]') self.click("#shopping_cart_container a") # Verify cart page self.assert_exact_text("Your Cart", "span.title") self.assert_text("Backpack", "div.cart_item") # Proceed to checkout self.click("button#checkout") self.type("#first-name", "SeleniumBase") self.type("#last-name", "Automation") self.type("#postal-code", "77123") self.click("input#continue") # Verify checkout overview self.assert_text("Checkout: Overview") self.assert_text("Backpack", "div.cart_item") self.assert_text("29.99", "div.inventory_item_price") # Complete the order self.click("button#finish") self.assert_exact_text("Thank you for your order!", "h2") self.assert_element('img[alt="Pony Express"]') # Log out self.js_click("a#logout_sidebar_link") self.assert_element("div#login_button_container") Output
Here’s how the script executes in real-time:
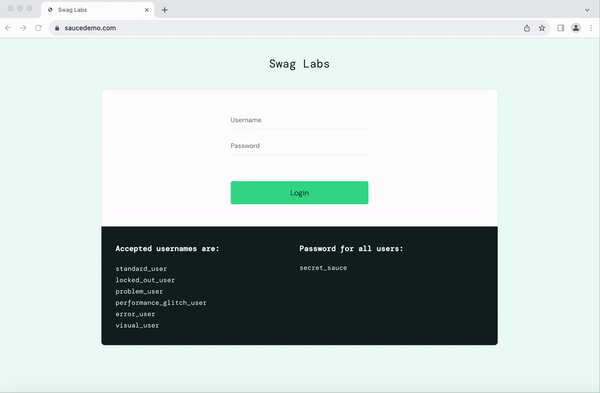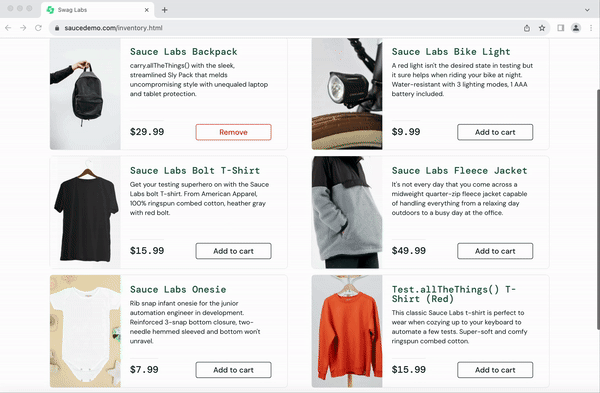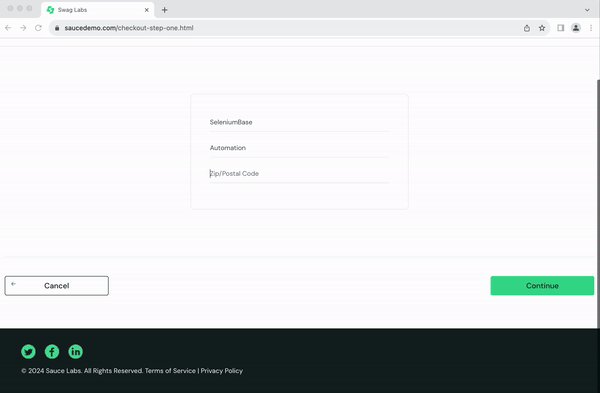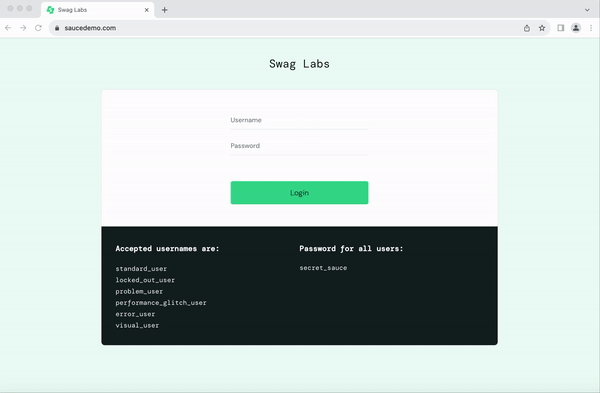
With SeleniumBase, even complex workflows like e-commerce testing become straightforward and manageable.
Using SeleniumBase for Scraping
Web scraping often involves challenges like dynamic content rendering, bot detection mechanisms, and IP-based restrictions. SeleniumBase simplifies these tasks with features designed to handle such complexities, including undetected ChromeDriver mode and proxy integration.
Basic Scraping Example
The following example demonstrates how to scrape data from a product page using SeleniumBase. This basic script extracts the title, description, price, and variants of a product, and saves the data as a JSON file.
import json from seleniumbase import BaseCase class ScrapeProductPage(BaseCase): def test_scrape_product(self): # Open the product page self.open("https://web-scraping.dev/product/1") # Extract product title product_title = self.get_text("h3") # Extract description description = self.get_text(".product-description") # Extract price price = self.get_text("span.product-price") # # Extract variants variant_elements = self.find_elements("a.variant") variants = [variant.text for variant in variant_elements] # Combine all data into a dictionary product_data = { "title": product_title, "description": description, "price": price, "variants": variants, } # Convert the dictionary to JSON and print product_json = json.dumps(product_data, indent=4) print(product_json) # Save JSON to a file with open("product_data.json", "w") as file: file.write(product_json) This example is straightforward and works well for websites with minimal anti-bot measures or static content.
Enhancing Scraping with Undetected ChromeDriver Mode
Some websites detect traditional ChromeDriver usage and block automated interactions. SeleniumBase supports undetected ChromeDriver mode, which allows your scraping tasks to appear as legitimate browser sessions.
Now, that we know what failure looks like let's bypass this challenge using the Undetected ChromeDriver:
import undetected_chromedriver as uc import time # Add the driver options options = uc.ChromeOptions() options.headless = False # Configure the undetected_chromedriver options driver = uc.Chrome(options=options) with driver: # Go to the target website driver.get("https://nowsecure.nl/") # Wait for security check time.sleep(4) # Take a screenshot driver.save_screenshot('screenshot.png') # Close the browsers driver.quit() We initialize an undetected_chromedriver object, go to the target website and take a screenshot. Here is the screenshot we got:
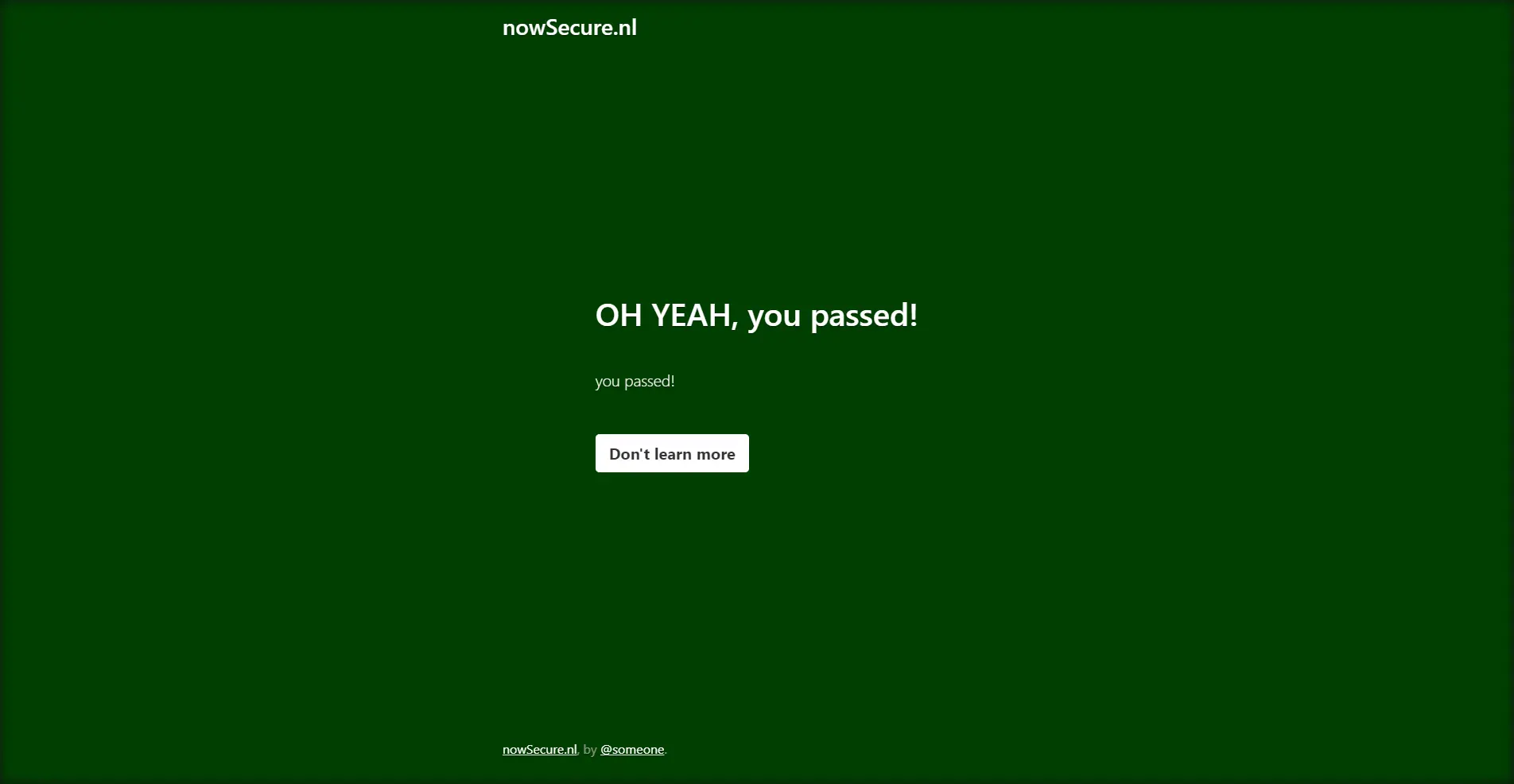
You can learn more about Undetected ChromeDrive in our dedicated article:
Web Scraping Without Blocking With Undetected ChromeDriver
In this tutorial we'll be taking a look at a new popular web scraping tool Undetected ChromeDriver which is a Selenium extension that allows to bypass many scraper blocking techniques.

How to Add Proxies to Undetected ChromeDriver?
Proxies are essential for avoiding IP blocking while scraping by splitting the traffic between multiple IP addresses. Here is how you can add proxies to the Undetected ChromeDriver:
import undetected_chromedriver as uc # Add the driver options options = uc.ChromeOptions() options.headless = False # For proxies without authentication options.add_argument(f'--proxy-server=https://proxy_ip:port') # For proxies with authentication options.add_argument(f'--proxy-server=https://proxy_username:proxy_password@proxy_ip:proxy_port') # Configure that driver options driver = uc.Chrome(options=options) Although you can add proxies to the undetected chrome driver, there is no direct implementation for proxy rotation.
How to Rotate Proxies in Web Scraping
In this article we explore proxy rotation. How does it affect web scraping success and blocking rates and how can we smartly distribute our traffic through a pool of proxies for the best results.

With these advanced features like undetected ChromeDriver and proxy integration, SeleniumBase enables scalable, efficient, and secure scraping for a wide range of use cases.
Using SeleniumBase for Screenshot Capture
Visual debugging, documentation, and error handling often require capturing precise screenshots during automation runs. SeleniumBase offers robust tools for saving images, including elements, sections of pages, and entire web pages, with optional text overlays.
Here’s a detailed example from SeleniumBase’s official documentation that highlights its powerful image-saving capabilities.
import os from seleniumbase import BaseCase BaseCase.main(__name__, __file__) class ImageTests(BaseCase): def test_save_element_as_image(self): self.open("https://xkcd.com/1117/") selector = "#comic" folder = "images_exported" file_name = "comic.png" self.save_element_as_image_file(selector, file_name, folder) print(f'Image saved at: {os.path.join(folder, file_name)}') def test_add_text_overlay(self): self.open("https://xkcd.com/1117/") selector = "#comic" folder = "images_exported" file_name = "image_with_overlay.png" overlay_text = "This is an XKCD comic!" self.save_element_as_image_file(selector, file_name, folder, overlay_text) print(f'Annotated image saved at: {os.path.join(folder, file_name)}') This example demonstrates how SeleniumBase simplifies screenshot capture, allowing users to save specific elements or entire pages with ease. Additionally, the ability to add text overlays enhances the utility of screenshots for debugging, documentation, and reporting purposes.
Power-Up with Scrapfly
ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.

FAQ
To wrap up this guide, here are answers to some frequently asked questions about SeleniumBase.
Can SeleniumBase be used for Web Scraping?
Yes, while SeleniumBase is primarily designed for test automation, it can also be used for web scraping. Its features like Undetected Chromedriver integration, proxy support, and screenshot capture make it a very convenient tool for scraping dynamic websites.
What browsers are supported SeleniumBase?
SeleniumBase works with most of the browser Selenium itself suports: Chrome, Firefox, Edge, and Safari.
Can SeleniumBase be detected by websites?
Yes, while SeleniumBase supports many detection resistance patches like Undetected Chromedriver integration and proxy support it is still easily identifiable by websites as an automation tool. For more see our introduction how how web automation is detected.
Summary
SeleniumBase brings a new level of simplicity and efficiency to browser automation. From streamlined syntax to robust features like screenshots, proxy support, and seleniumBase for Cloudflare handling, it’s a powerful alternative to vanilla Selenium. Whether you’re automating tests or scraping data, SeleniumBase offers everything you need to succeed.




