Why do we really need Llama Stack when popular frameworks like LangChain, LangFlow, and CrewAI already exist?
This is the question we get asked most often. It’s a fair one—after all, those frameworks already give developers rich tooling for retrieval-augmented generation (RAG) and agents.
But we see Llama Stack as more than “another agent framework.” It’s better understood as four distinct layers:
The 4 layers of Llama Stack
1. Build layer (Client SDK/Toolkit)
A familiar surface for building agents. Here it overlaps with LangChain, LangFlow, and CrewAI. Developers can author agents using common abstractions.
Example: An agent built with CrewAI looks like a small project folder with config files and environment variables. See diagram below.
2. Agent artifacts and dependencies
These are the tangible artifacts of agent development. To run these, an agent developer needs a platform that provides the needed runtimes and API end points for model inference, tool calling, or for safety and telemetry. As an illustrative example see Figure 1, which shows a simple agent developed with CrewAI and its dependencies.
Figure 1: An example of artifacts and dependencies for a simple agent developed with CrewAI
And a distinction can also be made for local loop development and deployment, and stage and production deployments (see Figure 2) . Llama Stack enables both a local development and deployment environment, and an option to take advantage of remote endpoints. Furthermore, it allows for platform providers to build stage and production environments with Llama Stack at its core. Llama Stack helps make sure that these artifacts can run consistently—regardless of which backend models or tools you pick.
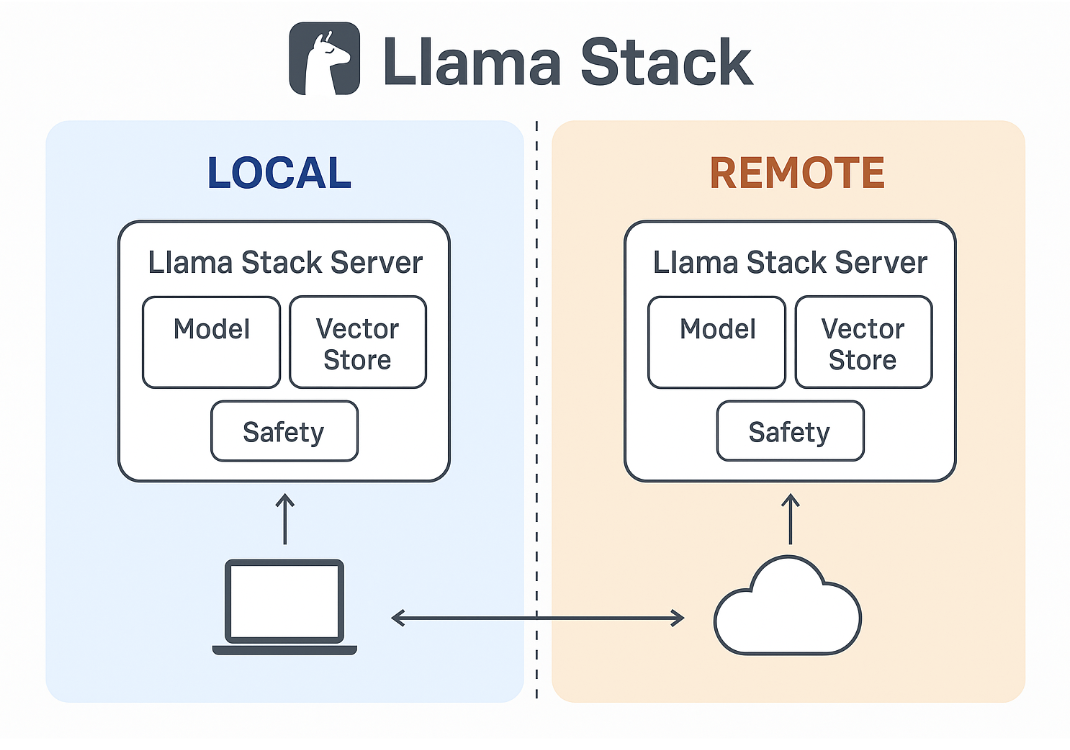
Figure 2: Development of agents with Llama Stack can be done with local providers or remote providers
3. Platform / API layer
A standardized API surface for core AI services, including inference, memory, tool use, post-training, data and synthetic generation, and evaluation. This is the part of Llama Stack that platforms can expose and operate.
It has built-in support for OpenAI-compatible APIs and Model Context Protocol (MCP) . That means developers can incorporate existing agents and tools without rewriting them. In addition, it is noteworthy that Llama Stack is one of the few open implementations of OpenAI’s APIs (for example, OpenAI’s agentic API aka the responses API as well as other OpenAI APIs for file_search, vectorstores and more). Additionally, Llama Stack also has a wider surface that goes beyond OpenAI APIs for functions like eval, fine-tuning, or model-customization, scoring, and dataset management.
Example: You’ve written an agent against the OpenAI Chat Completions API. With Llama Stack Platform and the API server, it runs unmodified—and you can point it at Llama, Qwen, or other model endpoints running in your own cluster/environment on-premises based on open source technologies like vLLM or hosted inference services like AWS Bedrock or Azure OpenAI etc.
4. Provider model
A plugin system for backends—whether open source or proprietary. This allows you to swap a model provider, vector database, or runtime implementation without touching agent code.
Example: Your agent uses a vector store for retrieval. Today it’s Pinecone, tomorrow you want Milvus. With Llama Stack, you swap the provider, not your agent logic.
The Kubernetes analogy
Why compare Llama Stack to Kubernetes?
Kubernetes didn’t just win because it made it easy to run containers. It won because it defined a control plane + plugin contract (CNI for networking, CSI for storage, CRI for runtimes) that operators could depend on. It developed workload APIs (like Deployment) that developers and operators depend on to develop and deploy workloads/applications. Finally, Kubernetes allows for extending the workload APIs with custom resources (CR) for workloads that do not fit the native capabilities offered by the workload APIs. These contracts enabled portability across vendors and clouds.
Llama Stack aims to play the same role for agents: a run-anywhere contract that bridges developers and platforms.
- For developers: The (Llama Stack) APIs that you use and the artifacts you produce (YAML configs, Python tasks, tool bindings) should run without change across environments. Developers can also extend LLama Stack APIs
- For platforms: The underlying infrastructure (models, vector databases, training runtimes, tool APIs) should be pluggable providers.
Think of Kubernetes orchestrating containers, and Llama Stack orchestrating agents and their providers. If successful, Llama Stack could become the “anchor project” around which a broader open source AI ecosystem organizes, much like Kubernetes did for cloud native computing.
The standards question: OpenAI APIs vs. MCP
Right now, OpenAI APIs (chat completions, and now the Responses API) have become the de facto standard for inference. At the same time, MCP has emerged as an open protocol for tool calling.
Here’s the catch: OpenAI APIs are not open standards. MCP is.
That raises an important question for the open source community: how much influence should a single company have over the APIs that shape agent ecosystems?
Llama Stack offers a way to adopt what’s working (OpenAI-compatibility is crucial today) while also advancing open standards (through MCP and beyond). If it succeeds, it could help lay the groundwork so APIs for agents and gen AI don’t remain captive to proprietary interests or as dispersed and diffused open source initiatives.
As a concrete example, with Llama Stack vector_stores/{vector_store_id}/search API, the caller can pass in `search_mode` parameter for hybrid search (semantic + keyword) which is an enhancement over what is available in OpenAI. These are kinds of innovations that open source community projects debate and implement (vs being dependent on one company for these kinds of enhancements).
While Llama Stack was initiated by Meta, there are many organizations and individuals who are already contributing to the project, including Anthropic, OpenAI, NVIDIA, Groq, AI Alliance, and Red Hat.
The governance question
The other piece we don’t talk about enough: governance.
Kubernetes wasn’t just a good technology—it was backed by neutral governance under the Cloud Native Computing Foundation (CNCF), which gave enterprises and vendors confidence to invest. Without that, Kubernetes might have remained “just another orchestration tool.”
For Llama Stack to fulfill its potential, governance will matter too. To that end, Llama Stack now has moved to a neutral standalone Github repo. Where do we go from here? Do we need a CNCF-like governance structure for Llama Stack? When? The answer will determine whether it can truly become the “Kubernetes of agents.”
Why this matters
- For developers: confidence that your agents and tools will keep running even as infrastructure and vendors change.
- For platform operators: portability, interoperability, and freedom from vendor lock-in.
- For the ecosystem: a chance to avoid fragmentation and create a genuine open source center of gravity for agents.
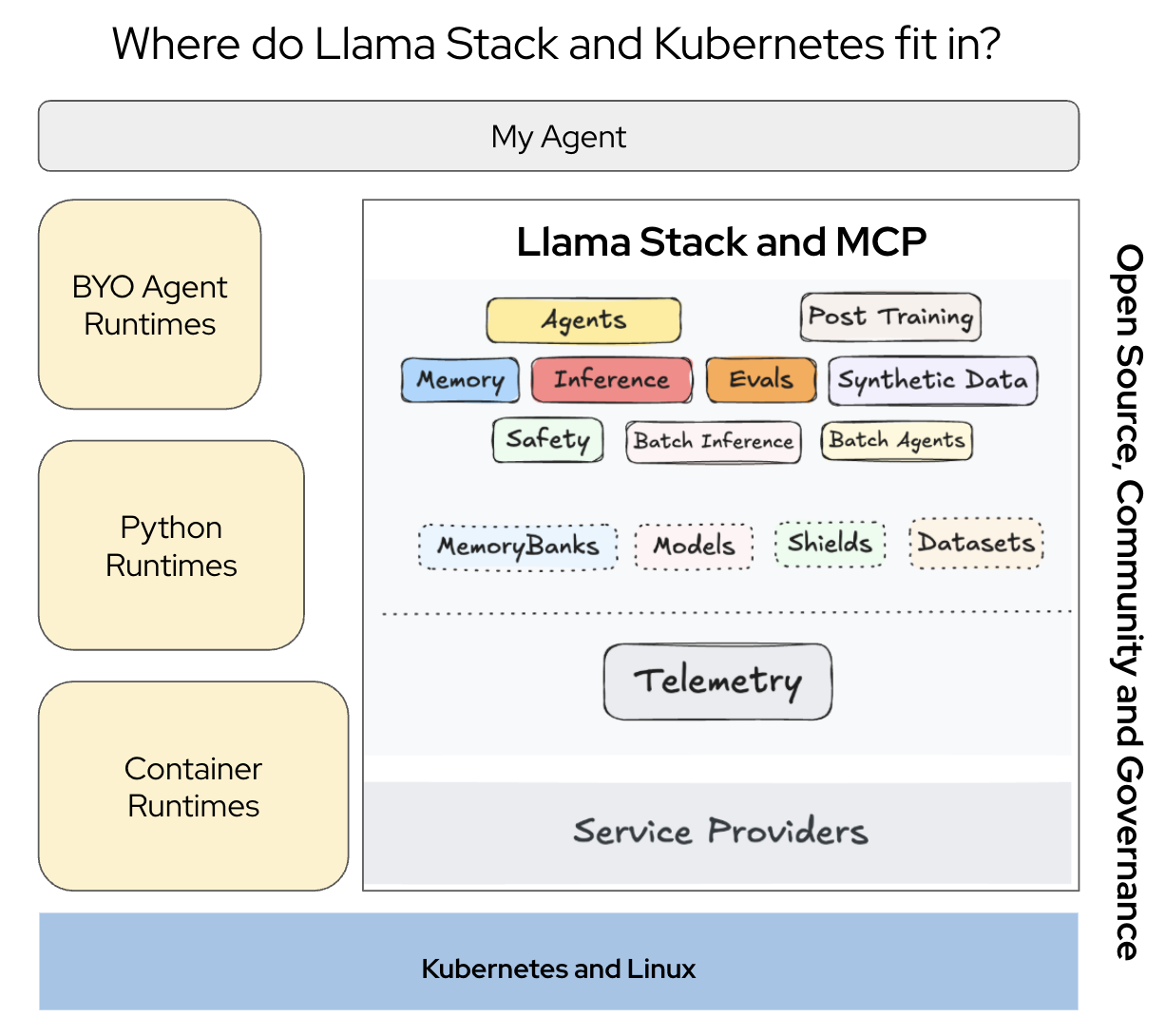
Figure 3: Providers have to design and implement an AI platform that provides runtimes, and AI endpoints that the agent depends on.
Bottom line: Llama Stack is less about replacing your favorite agent library, and more about creating the open, run-anywhere contract beneath them. It builds on what’s working (OpenAI APIs, MCP) but also points toward a future where APIs, standards, and governance are open and community-driven.
That’s the conversation we need to have—because the future of agents shouldn’t just belong to one company.
Resource
The adaptable enterprise: Why AI readiness is disruption readiness
About the authors


Adel Zaalouk is a product manager at Red Hat who enjoys blending business and technology to achieve meaningful outcomes. He has experience working in research and industry, and he's passionate about Red Hat OpenShift, cloud, AI and cloud-native technologies. He's interested in how businesses use OpenShift to solve problems, from helping them get started with containerization to scaling their applications to meet demand.
More like this
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds