Introduction
In this post (notebook) we ingest programming languages creation data from “Programming Language DataBase” and visualize several statistics of it.
We do not examine the data source and we do not want to reason too much about the data using the stats. We started this notebook by just wanting to make the bubble charts (both 2D and 3D.) Nevertheless, we are tempted to say and justify statements like:
- Pareto holds, as usual.
- Language creators tend to do it more than once.
- Beware the Second system effect.
References
Here are reference links with explanations and links to dataset files:
- The Ages of Programming Language Creators (pldb.io)
- Short note about data and related statistics; provides a link to a TSV file with the data.
- The Ages of Programming Language Creators (datawrapper.dwcdn.net)
- “Just a plot”; provides a link to a CSV file with the data.
- The Ages of Programming Language Creators (Reddit)
- Link(s) and discussion.
Setup
use Data::Importers; use Data::Reshapers; use Data::Summarizers; use Data::TypeSystem; use JavaScript::D3;Data ingestion
Here we ingest the TSV file:
my $url = "https://pldb.io/posts/age.tsv";
my @dsData = data-import($url, headers => 'auto');
deduce-type(@dsData)
# Vector(Assoc(Atom((Str)), Atom((Str)), 13), 214)
Here we define a preferred order of the columns:
my @field-names = ['id', 'name', |(@dsData.head.keys (-) <id name>).keys.sort];
# [id name ageAtCreation appeared creators foundationScore inboundLinksCount measurements numberOfJobsEstimate numberOfUsersEstimate pldbScore rank tags]
Convert suitable column values to integers:
@dsData = @dsData.map({
$_<ageAtCreation> = $_<ageAtCreation>.UInt;
$_<rank> = $_<rank>.Int;
$_<pldbScore> = $_<pldbScore>.Int;
$_<appeared> = $_<appeared>.Int;
$_<numberOfUsersEstimate> = $_<numberOfUsersEstimate>.Int;
$_<numberOfJobsEstimate> = $_<numberOfJobsEstimate>.Int;
$_<foundationScore> = $_<foundationScore>.Int;
$_<measurements> = $_<measurements>.Int;
$_<inboundLinksCount> = $_<inboundLinksCount>.Int;
$_
}).Array;
deduce-type(@dsData)
# Vector(Struct([ageAtCreation, appeared, creators, foundationScore, id, inboundLinksCount, measurements, name, numberOfJobsEstimate, numberOfUsersEstimate, pldbScore, rank, tags], [Int, Int, Str, Int, Str, Int, Int, Str, Int, Int, Int, Int, Str]), 214)
Show summary:
sink records-summary(@dsData, max-tallies => 7, field-names => @field-names.sort[^7]); sink records-summary(@dsData, max-tallies => 7, field-names => @field-names.sort[7..12]);
Focus languages to be used in the plots below:
my @focusLangs = ["C++", "Fortran", "Java", "Mathematica", "Perl 6", "Raku", "SQL", "Wolfram Language"];
# [C++ Fortran Java Mathematica Perl 6 Raku SQL Wolfram Language]
Here we find the most important tags (used in the plots below):
my @topTags = @dsData.map(*<tags>).&tally.sort({ $_.value }).reverse.head(7)>>.key;
# [pl dataNotation textMarkup library grammarLanguage queryLanguage stylesheetLanguage]
Here we add the column “group” based on the focus languages and most important tags:
@dsData = @dsData.map({
$_<group> = do if $_<name> ∈ @focusLangs { "focus" } elsif $_<tags> ∈ @topTags { $_<tags> } else { "other" };
$_
});
deduce-type(@dsData)
# Vector(Struct([ageAtCreation, appeared, creators, foundationScore, group, id, inboundLinksCount, measurements, name, numberOfJobsEstimate, numberOfUsersEstimate, pldbScore, rank, tags], [Int, Int, Str, Int, Str, Str, Int, Int, Str, Int, Int, Int, Int, Str]), 214)
Distributions
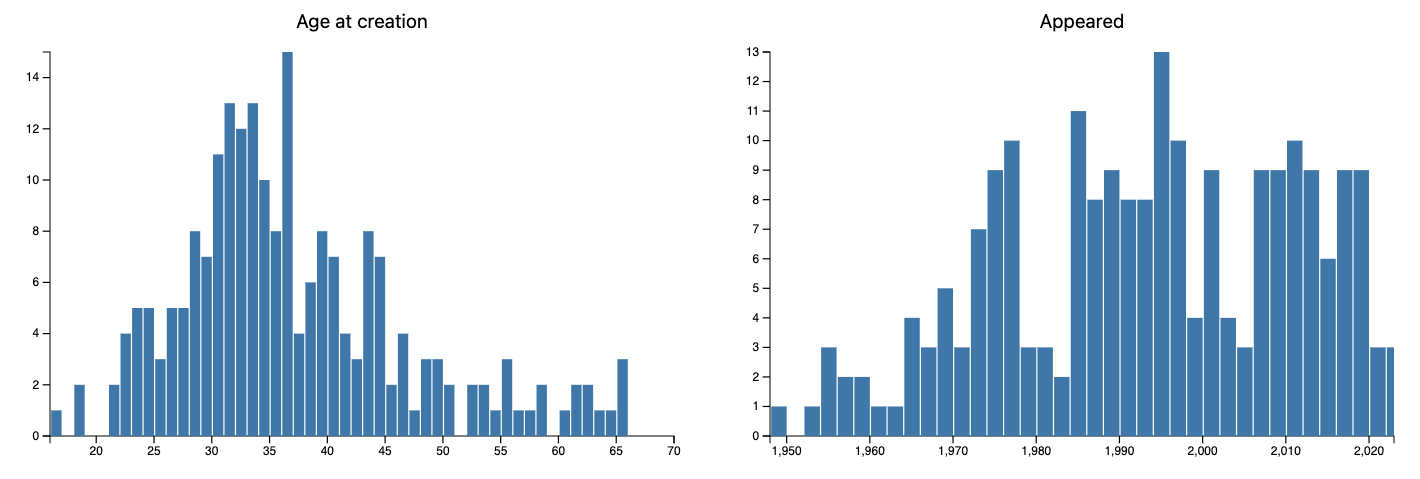
Here are the distributions of the variables/columns:
- age at creation
- i.e. “How old was the creator?”
- appeared”
- i.e. “In what year the programming language was proclaimed?”
#% js
my %opts = title-color => 'Silver', background => 'none', bins => 40, format => 'html', div-id => 'hist';
js-d3-histogram(@dsData.map(*<ageAtCreation>), title => 'Age at creation', |%opts)
~
js-d3-histogram(@dsData.map(*<appeared>), title => 'Appeared', |%opts)
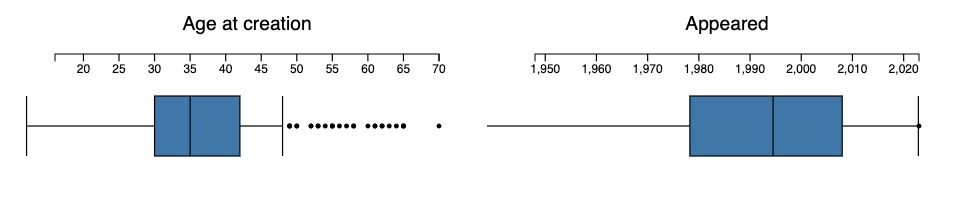
Here are corresponding Box-Whisker plots:
#% js
my %opts = :horizontal, :outliers, title-color => 'Silver', stroke-color => 'White', background => 'none', width => 400, format => 'html', div-id => 'box';
js-d3-box-whisker-chart(@dsData.map(*<ageAtCreation>), title => 'Age at creation', |%opts)
~
js-d3-box-whisker-chart(@dsData.map(*<appeared>), title => 'Appeared', |%opts)
Here are tables of the corresponding statistics:
my @field-names = <ageAtCreation appeared>;
sink records-summary(select-columns(@dsData, @field-names), :@field-names)
# +---------------------+-----------------------+
# | ageAtCreation | appeared |
# +---------------------+-----------------------+
# | Min => 16 | Min => 1948 |
# | 1st-Qu => 30 | 1st-Qu => 1978 |
# | Mean => 36.766355 | Mean => 1993.009346 |
# | Median => 35 | Median => 1994.5 |
# | 3rd-Qu => 42 | 3rd-Qu => 2008 |
# | Max => 70 | Max => 2023 |
# +---------------------+-----------------------+
Pareto principle manifestation
Number of creations
Here is the Pareto principle statistic for the number of created (or renamed) programming languages per creator:
my %creations = @dsData.map(*<creators>).&tally;
my @paretoStats = pareto-principle-statistic(%creations);
@paretoStats.head(6)
# (Niklaus Wirth => 0.037383 Breck Yunits => 0.070093 John Backus => 0.093458 Chris Lattner => 0.11215 Larry Wall => 0.130841 Tim Berners-Lee => 0.149533)
Here is the corresponding plot:
#% js
js-d3-list-plot( @paretoStats>>.value,
title => 'Pareto principle: number languages per creators team',
title-color => 'Silver',
background => 'none',
:grid-lines,
format => 'html',
div-id => 'langPareto'
)
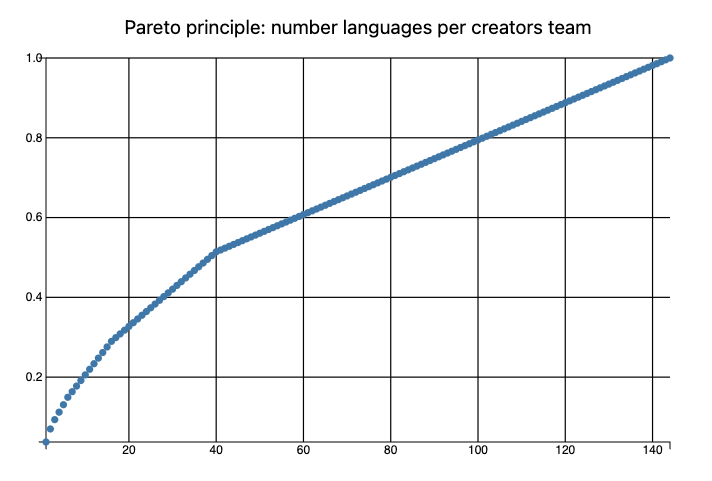
Remark: We can see that ≈30% of the creators correspond to ≈50% of the languages.
Popularity
Obviously, programmers can and do use more than one programming language. Nevertheless, it is interesting to see the Pareto principle plot for the languages “mind share” based on the number of users estimates.
#% js
my %users = @dsData.map({ $_<name> => $_<numberOfUsersEstimate>.Int });
my @paretoStats = pareto-principle-statistic(%users);
say @paretoStats.head(8);
js-d3-list-plot( @paretoStats>>.value,
title => 'Pareto principle: number users per language',
title-color => 'Silver',
background => 'none',
:grid-lines,
format => 'html',
div-id => 'popPareto'
)
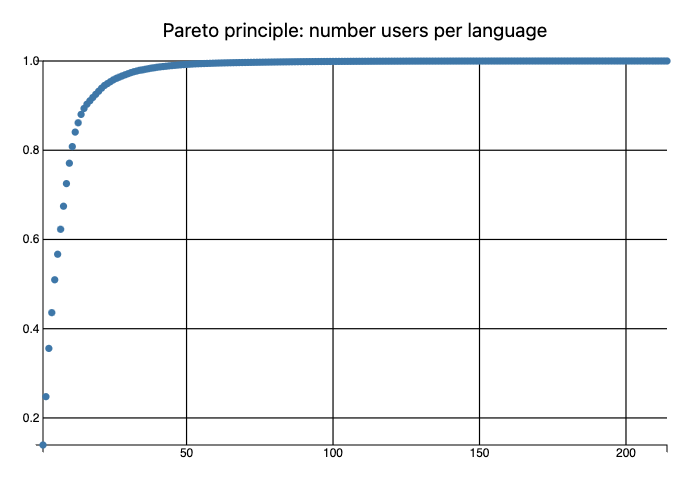
Remark: Again, the plot above is “wrong” — programmers use more than one programming language.
Correlations
In order to see meaningful correlation, pairwise plots we take logarithms of the large value columns:
my @corColnames = <appeared ageAtCreation numberOfUsersEstimate numberOfJobsEstimate rank measurements>;
my @dsDataVar = select-columns(@dsData, @corColnames);
@dsDataVar = @dsDataVar.map({
my %h = $_.clone;
%h<numberOfUsersEstimate> = log(%h<numberOfUsersEstimate> + 1, 10);
%h<numberOfJobsEstimate> = log(%h<numberOfJobsEstimate> + 1, 10);
%h
}).Array;
deduce-type(@dsDataVar)
# Vector(Struct([ageAtCreation, appeared, measurements, numberOfJobsEstimate, numberOfUsersEstimate, rank], [Int, Int, Int, Num, Num, Int]), 214)
Here make a Cartesian product of the focus columns and make scatter points plot for each pair of that product:
#% js
(@corColnames X @corColnames)>>.reverse>>.Array.map( -> $c {
my @points = @dsDataVar.map({ %( x => $_{$c.head}, y => $_{$c.tail} ) });
js-d3-list-plot( @points, width => 180, height => 180, x-label => $c.head, y-label => $c.tail, format => 'html', div-id => 'cor')
}).join("\n")

Remark: Given the names of the data columns and the corresponding obvious interpretations we can say that the stronger correlations make sense.
Bubble chart 2D
In this section we make an informative 2D bubble chart with (tooltips).
Here we make a dataset for the bubble chart:
my @dsData2 = @dsData.map({
%( x => $_<appeared>, y => $_<ageAtCreation>, z => log($_<numberOfUsersEstimate>, 10), group => $_<group>, label => "<b>{$_<name>}</b> by {$_<creators>}")
});
deduce-type(@dsData2)
# Vector(Struct([group, label, x, y, z], [Str, Str, Int, Int, Num]), 214)
Here is the bubble chart:
#% js
js-d3-bubble-chart(@dsData2,
z-range-min => 1,
z-range-max => 16,
title-color => 'Silver',
title-font-size => 20,
x-label => "appeared",
y-label => "lg(rank)",
title => 'Age at creation',
width => 1200,
margins => { left => 60, bottom => 50, right => 200},
background => 'none',
:grid-lines,
format => 'html',
div-id => 'bubbleLang'
);
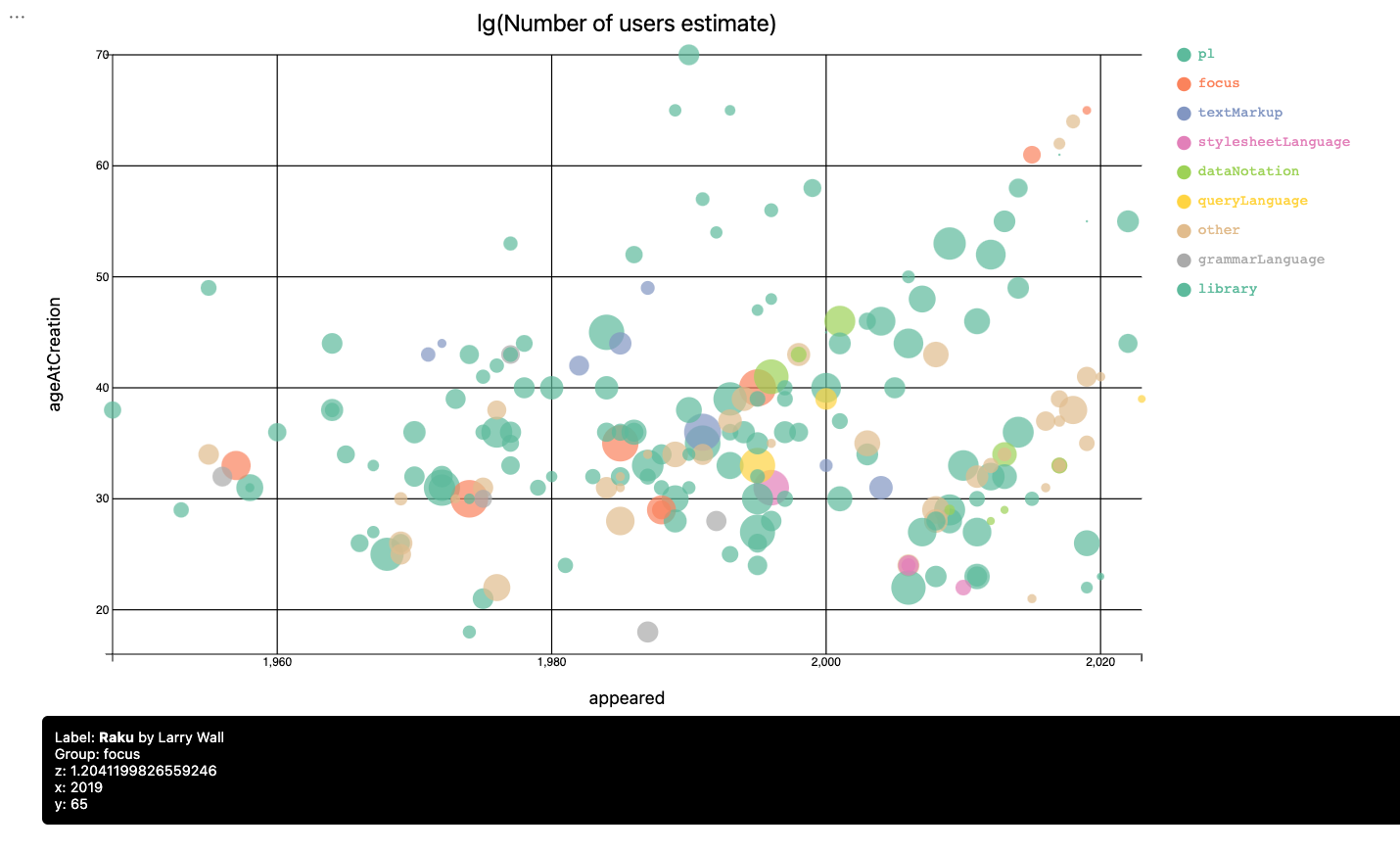
Remark: The programming language J is a clear outlier because of creators’ ages.
Second system effect traces
In this section we try — and fail — to demonstrate that the more programming languages a team of creators makes the less successful those languages are. (Maybe, because they are more cumbersome and suffer the Second system effect?)
Remark: This section is mostly made “for fun.” It is not true that each sets of languages per creators team is made of comparable languages. For example, complementary languages can be in the same set. (See, HTTP, HTML, URL.) Some sets are just made of the same language but with different names. (See, Perl 6 and Raku, and Mathematica and Wolfram Language.) Also, older languages would have the First mover advantage.
Make creators to index association:
my %creators = @dsData.map(*<creators>).&tally.pairs.grep(*.value > 1);
my %nameToIndex = %creators.keys.sort Z=> ^%creators.elems;
%nameToIndex.elems
# 40
Make a bubble chart dataset with relative popularity per creators team:
my @nUsers = @dsData.grep({ %creators{$_<creators>}:exists });
@nUsers = |group-by(@nUsers, <creators>).map({
my $m = max(1, $_.value.map(*<numberOfUsersEstimate>).max.sqrt);
$_.value.map({ %( x => $_<appeared>, y => %nameToIndex{$_<creators>}, z => $_<numberOfUsersEstimate>.sqrt/$m, group => $_<creators>, label => "<b>{$_<name>}</b>" ) })
})>>.Array.flat;
@nUsers .= sort(*<group>);
deduce-type(@nUsers)
# Vector(Struct([group, label, x, y, z], [Str, Str, Int, Int, Num]), 110)
Here is the corresponding bubble chart:
#% js
js-d3-bubble-chart(@nUsers,
z-range-min => 1,
z-range-max => 16,
title => 'Second system effect',
title-color => 'Silver',
title-font-size => 20,
x-label => "appeared",
y-label => "creators",
z-range-min => 3,
z-range-max => 10,
width => 1000,
height => 900,
margins => { left => 60, bottom => 50, right => 200},
background => 'none',
grid-lines => (Whatever, %nameToIndex.elems),
opacity => 0.9,
format => 'html',
div-id => 'secondBubble'
);
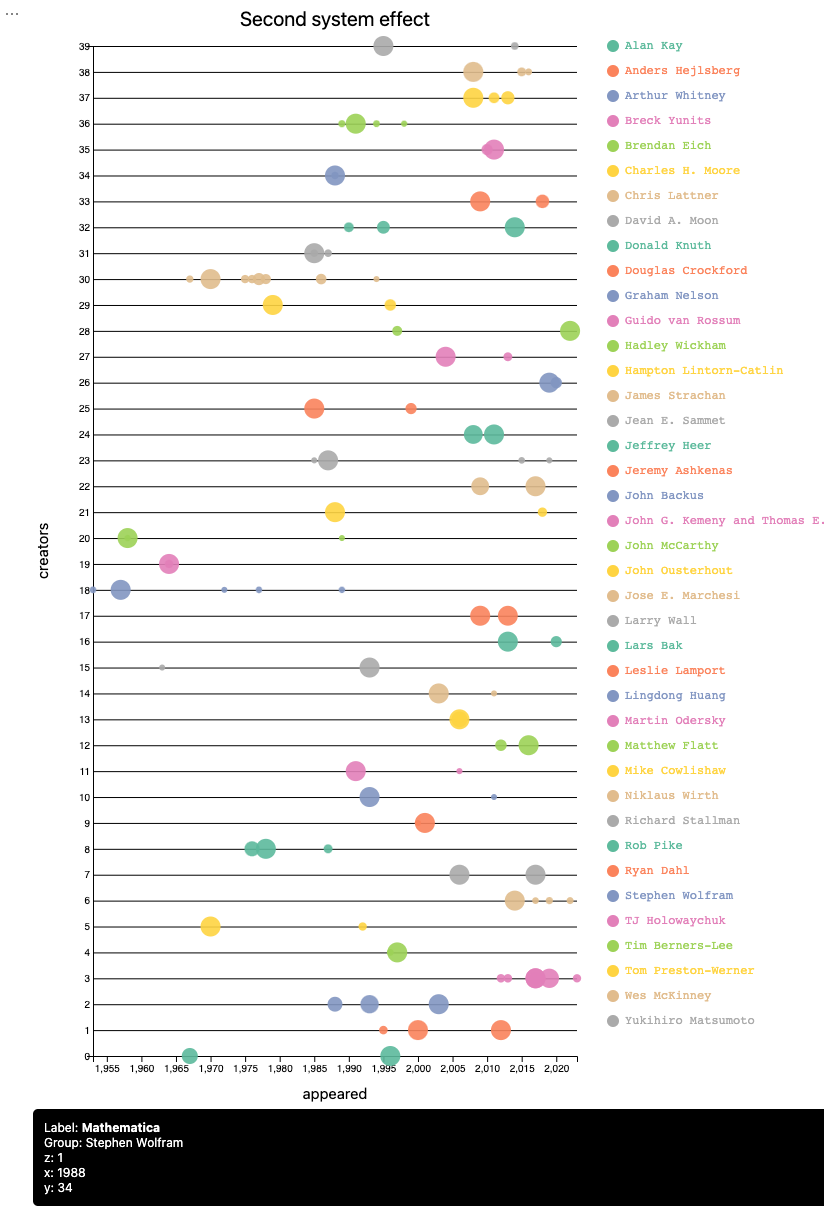
From the plot above we cannot decisively say that:
The most recent creation of a team of programming language creators is not team’s most popular creation.
That statement, though, does hold for a fair amount of cases.
References
Articles, notebooks
[AA1] Anton Antonov, “Age at creation for programming languages stats”, (2024), MathematicaForPrediction at WordPress.
[AAn1] Anton Antonov, “Computational exploration for the ages of programming language creators dataset”, (2024), Wolfram Community.
Packages
[AAp1] Anton Antonov, Data::Importers Raku package, (2024), GitHub/antononcube.
[AAp2] Anton Antonov, Data::Reshapers Raku package, (2021-2024), GitHub/antononcube.
[AAp3] Anton Antonov, Data::Summarizers Raku package, (2021-2023), GitHub/antononcube.
[AAp4] Anton Antonov, JavaScript::D3 Raku package, (2022-2024), GitHub/antononcube.
[AAp5] Anton Antonov, Jupyter::Chatbook Raku package, (2023-2024), GitHub/antononcube.
Videos
[AAv1] Anton Antonov, “Exploratory Data Analysis with Raku”, (2024), YouTube/@AAA4Prediction.
2 thoughts on “Age at creation for programming languages stats”