何をするか
血糖値データをpytorchのLSTMで予測してみます
なぜするか
理由その壱:技術的な興味
- 機械学習用のデータはネットを探すと色々と落ちていて、分析用ソースコードもたくさんあり、モデルもいい感じに作ってくれてたり、ハイパーパラメータチューニング後だったりで簡単に好スコアが出る。実際の生データからの分析(の苦労) をしてみたい。
- まともな機械学習のコードを書くのは初、、、e資格を受けるためのお勉強
理由その弐:血糖管理
- あわよくば、カーボ(炭水化物量)と今までの推移から打つべきインスリン量を提案して欲しい(かなり先の目標)
どうやってするのか
- 利用するデータ:
- 自分の血糖値のデータ
- 分析に使うもの:
- pytorch-lightning
データの取得
- このエントリで記述した構成のMongoDBからデータを抜いてきます
- 2020/11/28-2020/12/5まで(時々抜けはあるけれども)の5分おきの血糖値データ
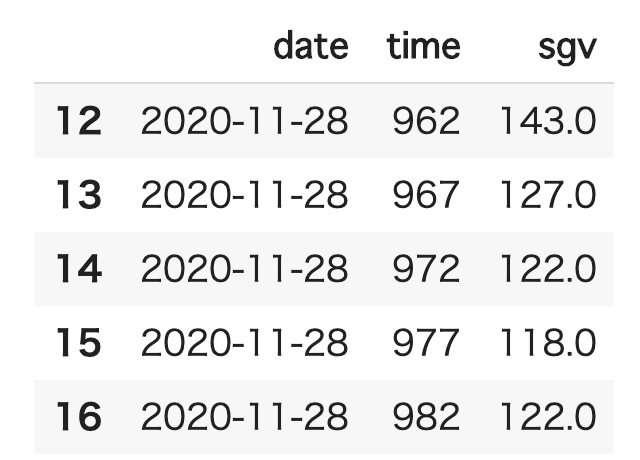
- グラフはこんな感じ(日付毎に色付け)、結構担当医に怒られる感じのグラフ
分析用コード
訓練用データ6、検証用データ2、テストデータ2に分ける
# 6:2:2に分ける n_train = int(len(x) * 0.6) n_val = int(len(x) * 0.2) x_train, t_train = x[0: n_train], t[0: n_train] x_val, t_val = x[n_train: n_train+n_val], t[n_train: n_train+n_val] x_test, t_test = x[n_train+n_val:], t[n_train+n_val:] # train, validation, testにまとめる train = torch.utils.data.TensorDataset(x_train, t_train) val = torch.utils.data.TensorDataset(x_val, t_val) test = torch.utils.data.TensorDataset(x_test, t_test) お決まりのNet(訓練用、検証用、テスト用)
import torch.nn as nn import torch.nn.functional as F import pytorch_lightning as pl from pytorch_lightning import Trainer # 学習データの処理 class TrainNet(pl.LightningModule): @pl.data_loader def train_dataloader(self): return torch.utils.data.DataLoader(train, self.batch_size, num_workers=self.num_workers) def training_step(self, batch, batch_nb): x, t = batch y = self.forward(x) loss = self.lossfun(y, t) tensorboard_logs = {'train_loss': loss} results = {'loss': loss, 'log':tensorboard_logs} return results # 学習データの処理 class ValidationNet(pl.LightningModule): @pl.data_loader def val_dataloader(self): return torch.utils.data.DataLoader(val, self.batch_size) def validation_step(self, batch, batch_nb): x, t = batch y = self.forward(x) loss = self.lossfun(y, t) results = {'val_loss': loss} return results def validation_end(self, outputs): avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean() tensorboard_logs = {'val_loss': avg_loss} results = {'val_loss': avg_loss, 'log':tensorboard_logs} return results # テストデータの処理 class TestNet(pl.LightningModule): @pl.data_loader def test_dataloader(self): return torch.utils.data.DataLoader(test, self.batch_size) def test_step(self, batch, batch_nb): x, t = batch y = self.forward(x) loss = self.lossfun(y, t) results = {'test_loss': loss} return results def test_end(self, outputs): avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean() tensorboard_logs = {'test_loss': avg_loss} results = {'test_loss': avg_loss, 'log':tensorboard_logs} return results LSTM
- OptimizerはAdam、loss関数はMSELossを使う
# LSTM モデルの作成 class LSTM(TrainNet, ValidationNet, TestNet): def __init__(self, input_size=1, hidden_size=10, output_size=1, batch_size=32, num_workers=1): super().__init__() self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True) self.linear = nn.Linear(hidden_size, output_size) self.batch_size = batch_size self.num_workers = num_workers def forward(self, x): x = x.view(x.size(0), 1, 1) x, (h, c) = self.lstm(x) x = self.linear(x.view(x.size(0), -1)) return x def lossfun(self, y, t): return F.mse_loss(y.float(), t.float()) def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=0.01) 訓練
from pytorch_lightning.callbacks import ModelCheckpoint # 再現性を確保するためシードを固定する torch.manual_seed(0) # モデルをインスタンス化 net = LSTM() # モデルのパラメータの保存場所を指定 checkpoint_callback = ModelCheckpoint( filepath='drive/MyDrive/glu_analysis/weights.ckpt', verbose=True, monitor='val_loss', mode='min' ) # 学習の実行 trainer = Trainer(checkpoint_callback=checkpoint_callback, min_epochs=1000) trainer.fit(net) 推論
# チェックポイントからモデルのパラメータをロード checkpoint = torch.load('drive/MyDrive/glu_analysis/weights.ckpt/_ckpt_epoch_219.ckpt') # インスタンスを作成、モデルのパラメータをセット model = LSTM() model.load_state_dict(checkpoint['state_dict']) # 推論モードにする model.eval() model.freeze() # テストデータを食べさせる outputs = model(x_test) tensorboardで可視化
(※logを後から出力したので、上記の実行の結果とは変わっている可能性あり)
%load_ext tensorboard %tensorboard --logdir ./lightning_logs/version_1/ 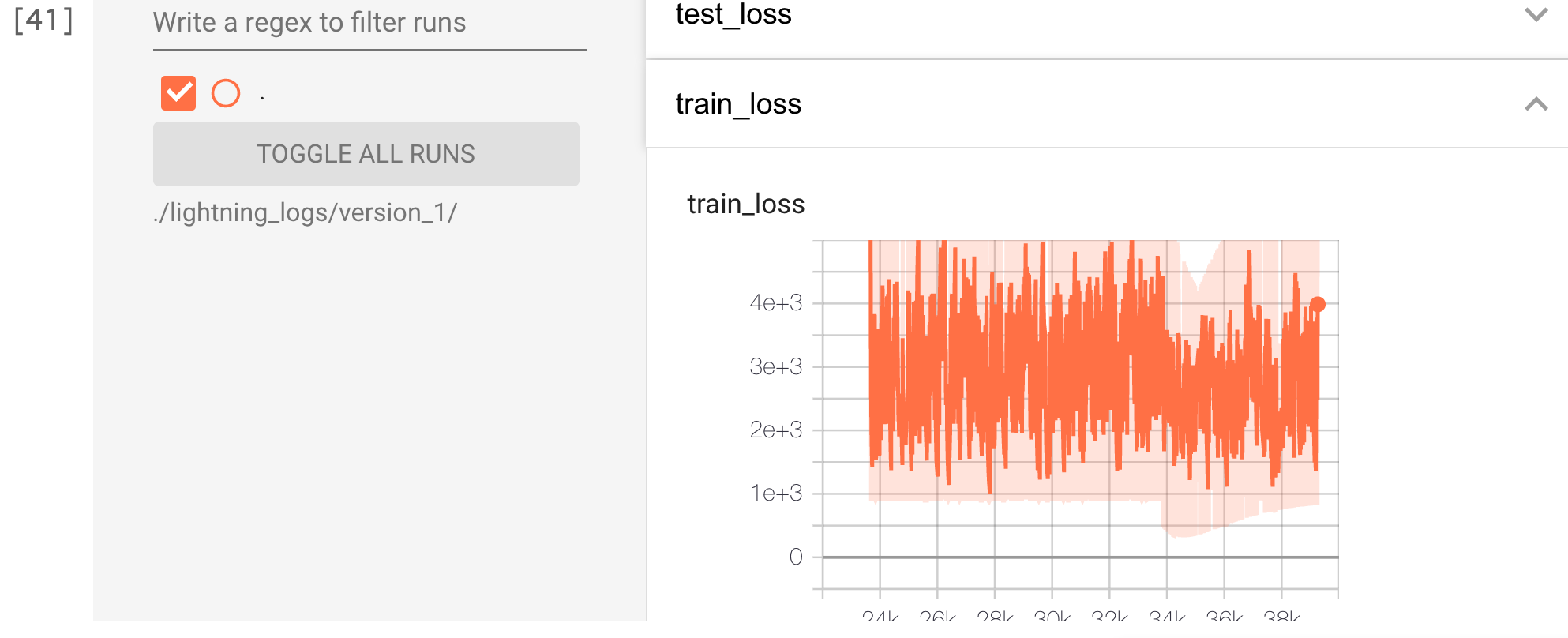 イマイチっぽい感じ、、、
イマイチっぽい感じ、、、 予測結果(青:予測、オレンジ:実際)
- ちょっとだけ、下がってるところが予測できているけれど、なかなかそのままでは難しい。
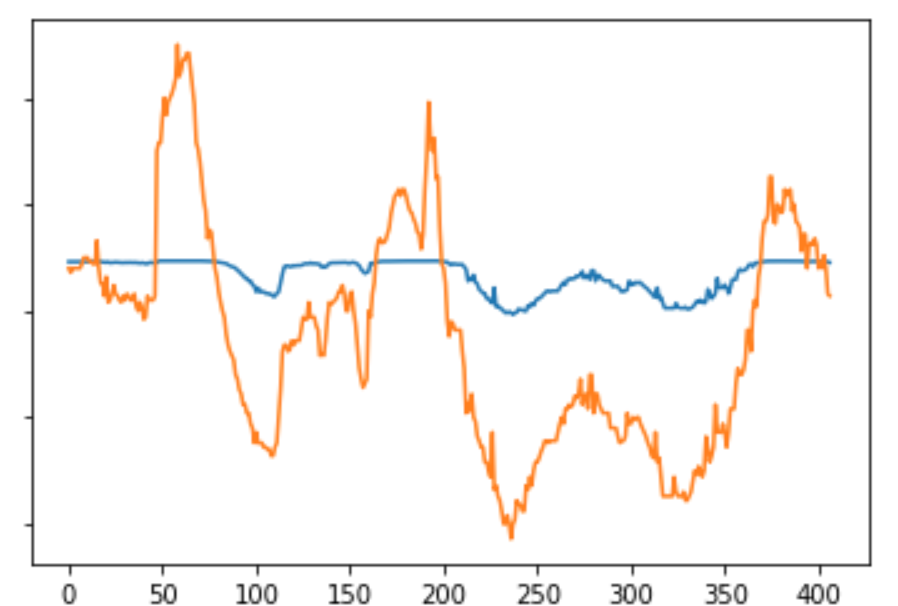
- 実は正直傾向があうとは思っていなかった、、、、、今までのデータからご飯の時間が予測されているということか、、、、!?
今後
- とりあえず初めて一連の流れが通せたので今後色々と改善していきたい。
- 次のステップは、statemodelを使って、トレンド成分等を分けて分析する。
- 外部入力として、インスリン量(基礎インスリン料含む)や、カーボ(炭水化物)を入れて予測できないものか、、、