Summer is slowly fading, and that means one thing: the PostgreSQL conference season in Europe is officially back. After PGDay Austria on September 4 and PGDay UK on September 9, the next stop was PGDay Lowlandsin Rotterdam on September 12. Three conferences in such a short time is a clear sign that the community is back in full swing after the summer break. And honestly—it felt great to be part of it again.
The Journey to Rotterdam
My conference adventure began a little earlier than the official start. I first traveled from Austria to Belgium to visit our partner Zebanza together with Jan Karremans. We met at their new office at Piros (in Everberg) for a strategic alignment session. It’s always rewarding to step out of the online bubble and sit together in person—discussing strategy, exchanging ideas, and building stronger ties.
From there, our journey continued to Amsterdam for a customer meeting, followed by another strategy session with our partner Nibble IT.
The plan sounded simple: hop on one train, work a bit along the way, and arrive fresh and prepared. But the Dutch railway system had other ideas. The direct connection was canceled, and we ended up taking four trains instead of one.
What could have been a stressful detour actually turned into a positive surprise. It gave me more time to enjoy the ride, watch the changing landscapes of Belgium and the Netherlands, and reflect on the upcoming days. Sometimes, detours are exactly what you need.
PGDay Lowlands Warmup Meetup
The official start of PGDay Lowlands happened the evening before the main event, with the warmup meetup. It combined short talks, pizza, and drinks—a casual setting that perfectly set the stage for the main conference.
For me, this was the first moment to reconnect with familiar faces from the PostgreSQL community, meet new ones, and exchange ideas in a relaxed atmosphere.
If you manage a PostgreSQL database with heavy write activity, one of the most important components to understand is the Write-Ahead Log (WAL). WAL is the foundation of PostgreSQL’s durability and crash recovery as it records every change before it’s applied to the main data files. But because WAL writes are synchronous and frequent, they can also become a serious performance bottleneck when they share the same disk with regular data I/O.
In this guide, we’ll first break down what WAL is and how it works internally, then walk through the exact steps to move pg_wal to a dedicated disk. You’ll also learn how to validate the setup and roll back safely if needed.
What Exactly is the WAL?
PostgreSQL operates on a simple principle:
No modification to a data file can happen until the logical change describing it has been permanently recorded in the WAL.
WAL is a sequential record of all changes made to the database. It ensures that a record of every change exists on stable storage before the actual data pages on disk are updated.
How WAL works internally
When we run an insert query, it’s first inserted into the appropriate table page within PostgreSQL’s shared memory area (the buffer pool). This memory page is now “dirty” because it differs from the version on disk.
Before this dirty page can be flushed back to its permanent location on disk, the database engine creates a WAL record. This isn’t the SQL command itself, but a low-level, binary representation of the exact change made. Each WAL record contains:
Transaction ID – Which transaction made the change
Page information – Which database page was modified
Redo information – How to reconstruct the change
Undo information – How to reverse the change (for rollbacks)
CRC checksum – For detecting corruption
This WAL record is first written to a small, fast area in memory called the WAL Buff
A new minor release for the beloved tool to build and manage multiple PostgreSQL instances.
pgenv 1.4.3 is out!
pgenv 1.4.3 is out! This minor release fixes a problem in the build of release candidate versions (e.g., 18rc1) by stripping out all the text part from a version number using a Bash regular expression.
With three locale providers (libc, icu and builtin), a PostgreSQL instance has potentially three different versions of Unicode at the same time. In this post, let's see when it matters and how to find which Unicode versions we are using.
Thank you to everyone who came to listen to my talk, "Postgres Partitioning Best Practices", at Euruko in Viana do Castelo, Portugal on 18 September 2025.
Thank you for all the questions and conversations, and thank you, especially, to the real-life Sofia - the person who found me to say
"Your talk described exactly what I went through, and I wish I'd been able to watch a talk like this before I started."
I'm sorry this talk came too late to save you some pain, but it's good to know it will be helpful to other people in the same situation.
Here are the slides and transcript from the talk. I'll share the recording once it's available.
Oh, and I fixed the seemingly random chapter numbers to convince folks that I can actually count!
One final note before I get into the actual content: I've included just very brief alt-text for each slide image, but I've also added any code or other essential information into the body of the blog post.
Postgres Partitioning Best Practices
As an aside, you may or may not know that Crunchy Data is now part of Snowflake, and this was the first outing for my Snowflake t-shirt, but that's a story for another day!
I always feel like an interloper at Ruby conferences, because I'm not a developer.
I like to show this diagram of my career so far, just to prove that I do at least know about databases!
I was a DBA for about 20 years before becoming a database consultant and now senior solutions architect.
I’m also on the PostgreSQL Europe board of directors and I’m leading the PostgreSQL Europe Diversity Task Force so feel free to find me to talk to me about that.
Introduction
What am I talking about today, and why should you care about it?
Maybe you're thinking about partitioning your huge database tables to make them easier to manage.
Perhaps you want to know how partitioning works and what the best practices are,
or maybe you're just wondering what table partitioning is all about.
PostgreSQL 18 is around the corner and it is time to take a look at one of the most important improvements that have been added to the core engine. We are of course talking about the introduction of asynchronous I/O (AIO), which has been a huge topic over the years.
Synchronous vs. asynchronous I/O
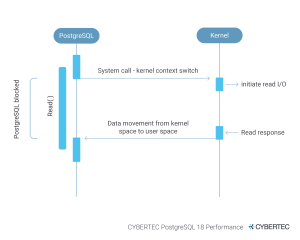
Let's dive into this and understand what the fuzz is all about. The standard I/O model works roughly like this:
PostgreSQL opens a file and reads one 8k block after the other. Yes, the kernel will do readahead and so on, but essentially the process is:
request an 8k block from the OS
wait until it arrives
process the block
This process is repeated. In real life, this means that the database cannot do calculations while we are waiting for the data to arrive. That is the curse of synchronous I/O. So, wouldn’t it be cool if the OS could already produce the data while the database is doing its calculations? The goal of AIO is to make reading and processing happen in parallel.
Here is a picture that illustrates this in more detail:
How does this work? The database schedules I/O and asks to provide it for later use. In the meantime, processing of already existing data can happen. This greatly reduces the latency the system will face. Obviously this is not beneficial to all operations, but it can greatly speed up things such as sequential scans, bitmap scans and so on.
In reality, one can expect better I/O performance - especially when running large scale operations.
However, let us not stick to theoretical explanations and move on to a more practical showcase.
Testing asynchronous I/O in PostgreSQL 18
The first thing one can do in PostgreSQL 18 and beyond is to actually configure the I/O method we are looking at. Here is how it works:
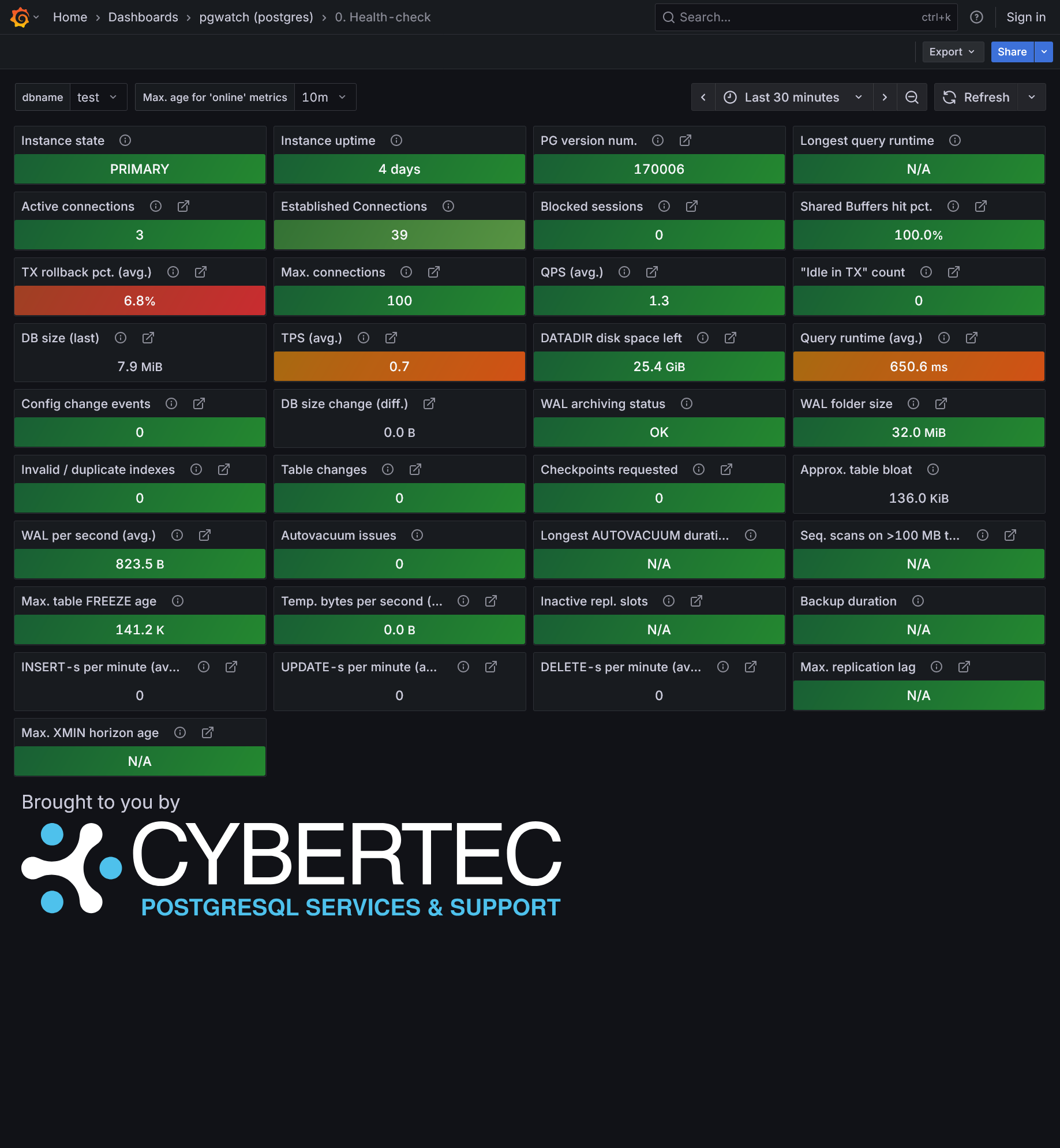
pgwatch v4? Yes, after a long time of silence, we are finally releasing a new major version!
Why version 4?
What happened to pgwatch v3!? It was released less than a year ago!
If Firefox can have version 142 and Chrome version 139 (and those numbers are probably already outdated by the time of publishing), why should we care about strict versioning? 🙂
On a more serious note, we decided to stick to the PostgreSQL major versioning scheme, so pgwatch major releases will now follow PostgreSQL major releases.
Why not pgwatch v18 then? Because we are not that ambitious. 🙂
But seriously, we don't want to confuse users by signaling that the new pgwatch will only work with the latest PostgreSQL version, as this is not the case. Plus, pgwatch supports all PostgreSQL forks (like Greenplum, Amazon Aurora, etc.) and poolers, pgBackRest, and so on, and so forth. The imagination is the only limitation here!
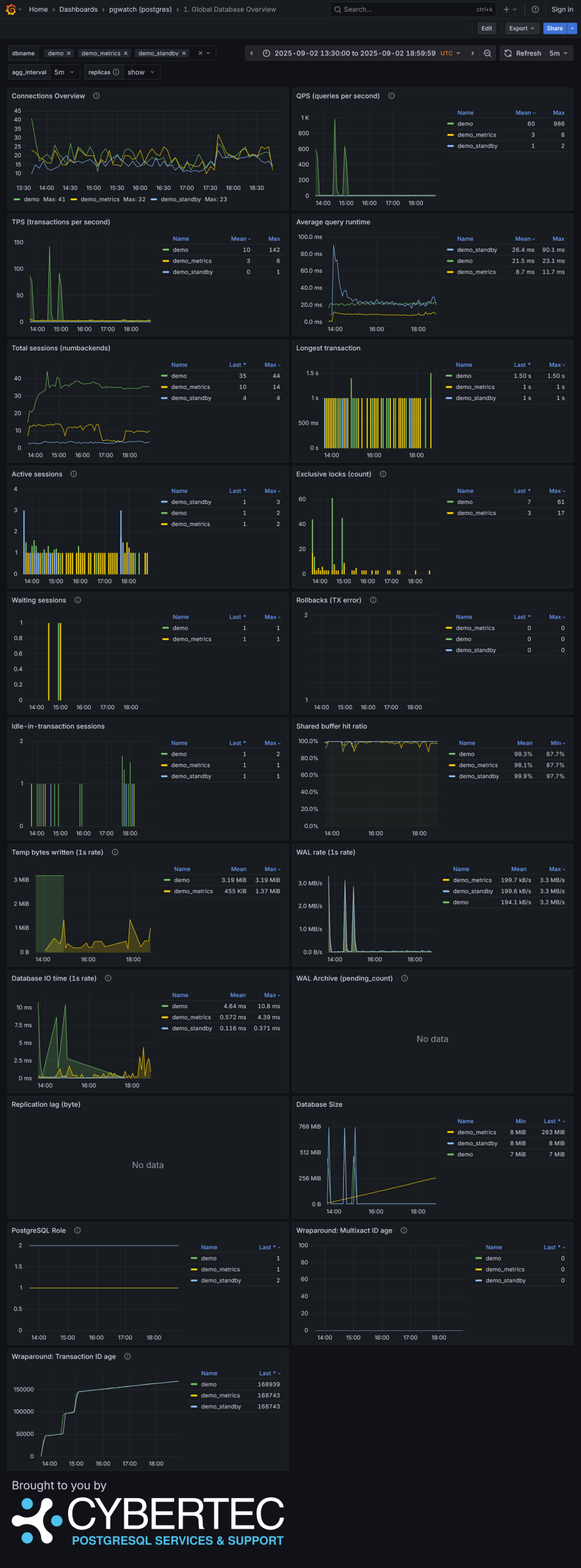
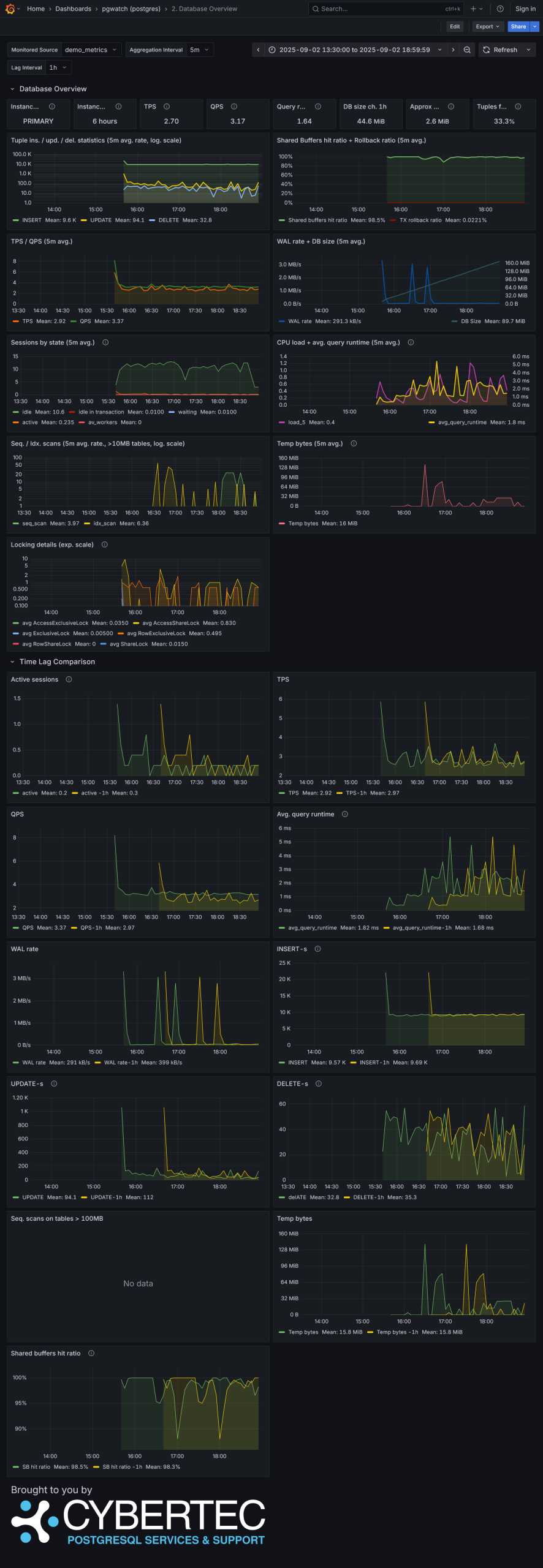
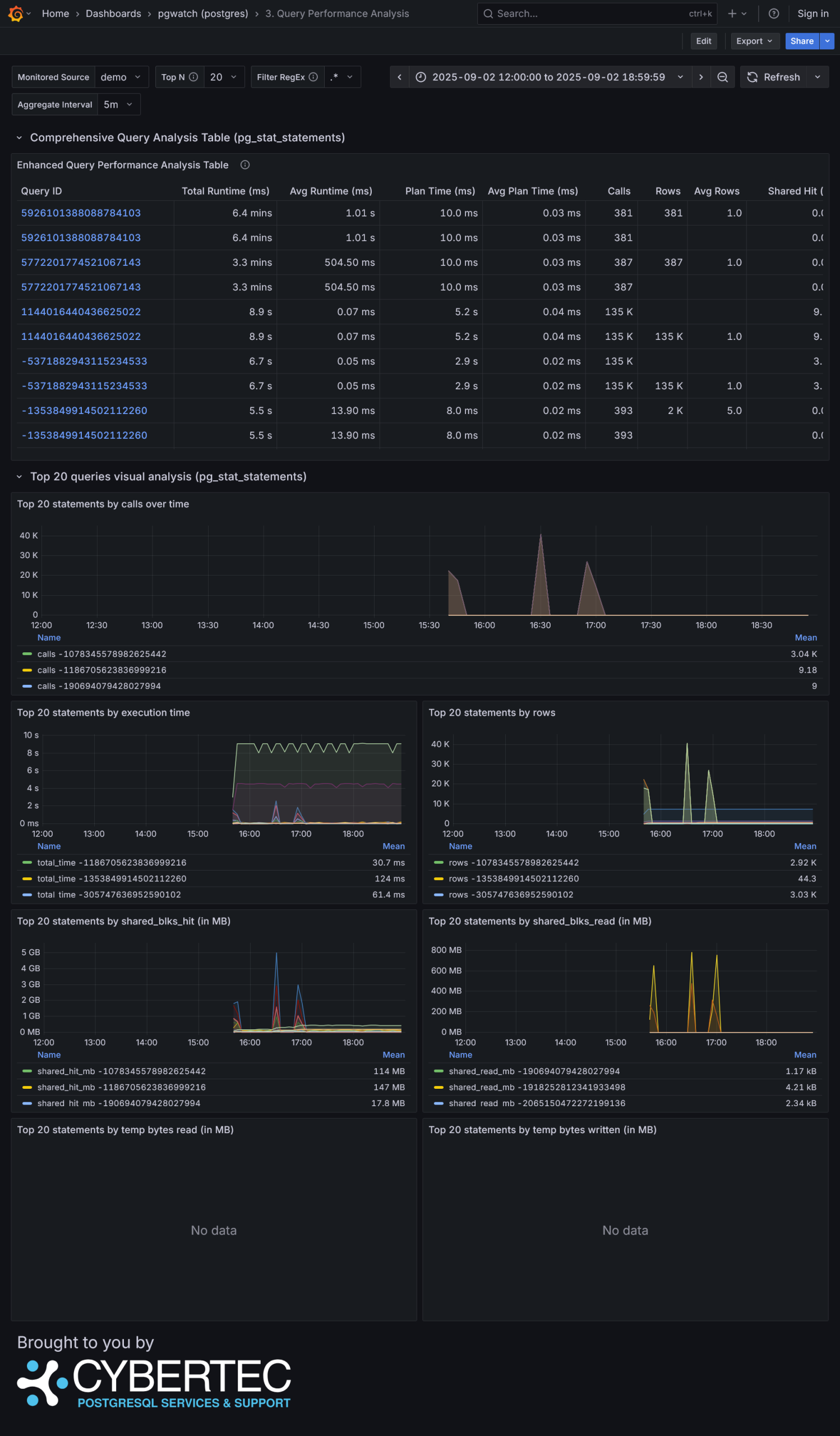
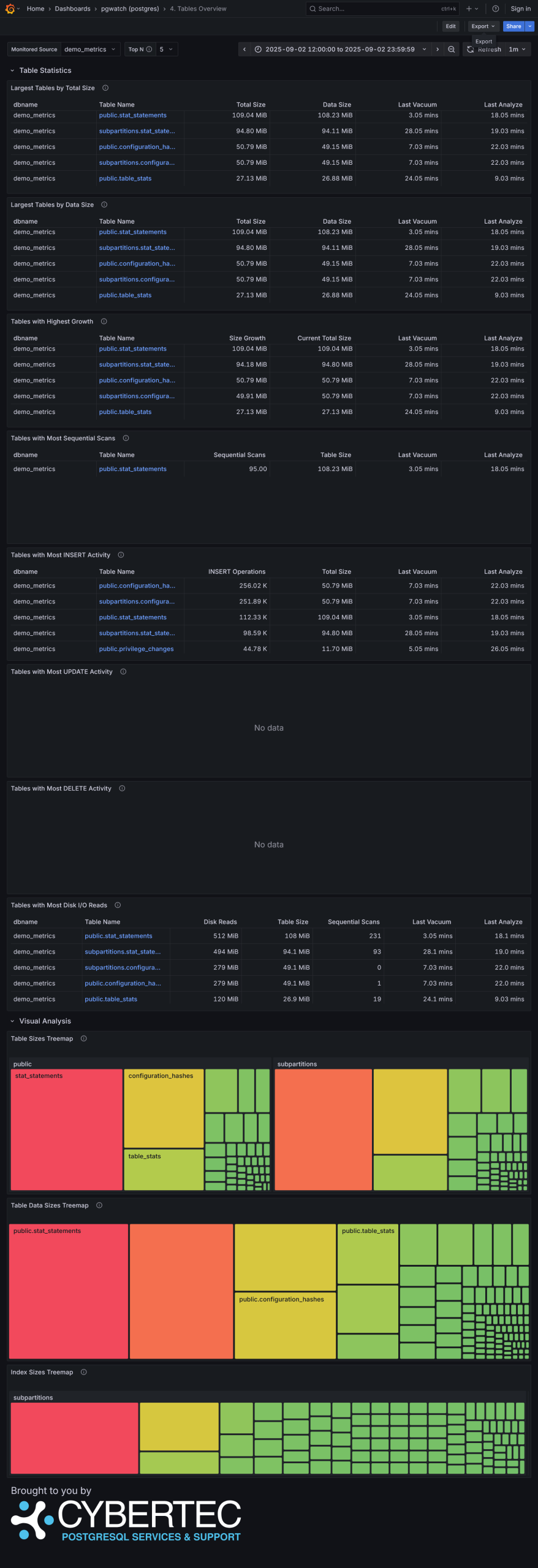
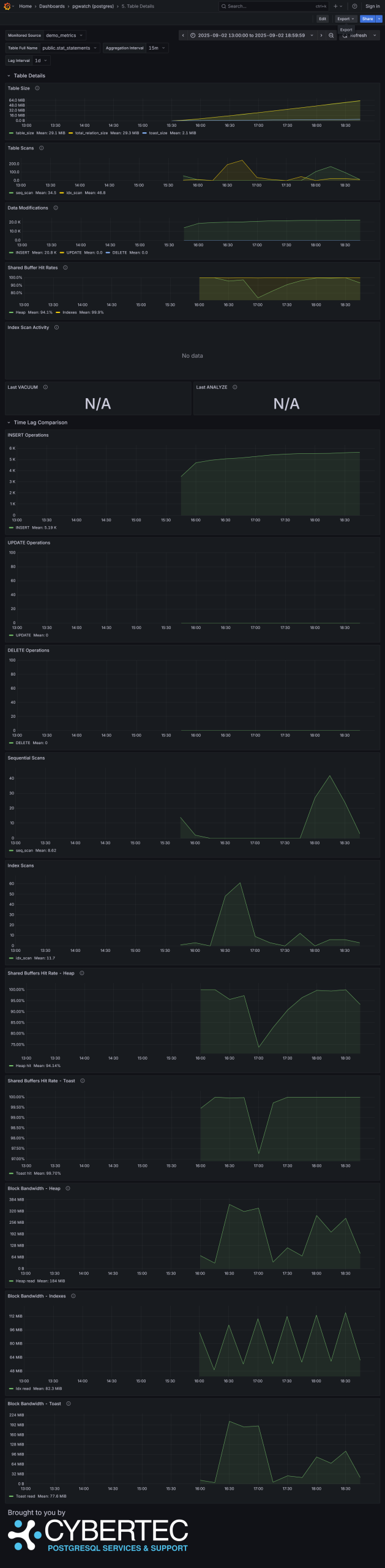
"All Green" Health check Improved Global Database Overview with 21 panels! Enhanced Database Overview New Query Performance Analysis with enhanced table with 17 metrics and 8 visualization panels Brand new Tables Overview with 8 different tables and 4 treemap visualization panels Detail Table Overview
gRPC Sink
- 🎁 New gRPC Sink (GSoC 2025 project) allows you to build a custom measurement storage and/or analytic layer; - 🔐 Added basic auth support - 📘 Added documentation - 🔄 Improved error handling (don't fail on DB r
I am glad we had an option to replay this talk from PG Day Chicago one more time! If you didn’t have a chance to join us, here is the recording – enjoy!
On 9th of September 2025, Dean Rasheed committed patch: Add date and timestamp variants of random(min, max). This adds 3 new variants of the random() function: random(min date, max date) returns date random(min timestamp, max timestamp) returns timestamp random(min timestamptz, max timestamptz) returns timestamptz Each returns a random value x in the … Continue reading "Waiting for PostgreSQL 19 – Add date and timestamp variants of random(min, max)."
I am excited to announce PostGIS 3.6 and GEOS 3.14.
The PostGIS spatial extension to PostgreSQL and the GEOS computational geometry library taken together provide much of the functionality of PostGIS, and are the open source focus of the (Crunchy Data) Snowflake PostGIS team.
Each year we work hard to ensure a release before the autumn PostgreSQL release, to ensure that the latest and greatest PostGIS and GEOS ready to be packaged with the latest PostgreSQL. All the critical issues are closed and the software tested and ready to go.
The 2025 release includes:
Automated cleaning of dirty polygonal coverages!
Many new 3D functions from the CGAL library are exposed in SQL.
Enhanced logging of GDAL raster access for easier debugging and development.
Simplified handling of PostgreSQL interrupts for better reliability.
Numerous fixes for performance and bugs in GEOS and PostGIS.
A “coverage” is a set of polygons that uniquely tile an area. There are lots of coverages in real life data. States are a coverage. Counties are a coverage. Parcels are a coverage. For any coverage, every point is either in one-and-only-one member of the coverage, or not in the coverage. No area should be covered twice.
A “classic” problem in spatial data management is “coverage cleaning” – repairing situations where there are gaps and/or overlaps in a polygonal coverage.
What has been missing is any way to automatically repair invalid coverages – coverages with overlapping polygons, or with small gaps between polygons. End users have had to export their dirty data and run it through external tools like Mapshaper to get clean coverages.
PGDay UK took place, September 9, at the Cavendish Conference Center.
Organizers:
Chris Ellis
Devrim Gunduz
Dave Page
Talk Selection Committee:
Ayse Bilge Ince
Dave Pitts
Gülçin Yıldırım Jelinek
Alastair Turner (chair, voting)
Volunteers:
Dave Pitts (room host)
Floor Drees (Code of Conduct team, room host)
Vik Fearing (registration)
Magnus Hagander (registration)
Speakers:
Bruce Momjian - Future Postgres Challenges
Andrew Farries – Postgres schema migrations using the expand/contract pattern Andrew Farries
Michael Banck – PostgreSQL Performance Tuning
Marta Palandri - Serving Literary Knowledge as Data: Building and Documenting DH APIs with PostgreSQL
Ellyne Phneah – Explaining PostgreSQL Like I’m Five (or 85)
Jan Karremans – PostgreSQL Certification – The PostgreSQL Way
Mehmet Yılmaz – Adaptive Partitioning: Balancing OLTP & OLAP with Citus
Jimmy Angelakos – Row-Level Security sucks. Can we make it usable?
The PostgreSQL UG NL meetup took place September 11, at the Lunatech offices in Rotterdam. Stefan Fercot and Chris Ellis delivered talks on PgBouncer and the (mis)use of some Postgres features respectively, and there were lightning talks by Jan Karremans (on the Open Alliance for PostgreSQL Education), Josef Machytka (on the credativ-pg-migrator project), and Kaarel Moppel (on pgbadger alternative pgweasel).
PGDay Lowlands took place September 12 at the Rotterdam Blijdorp Zoo.
Recently a great presentation “1000x: The Power of an Interface for Performance” from Joran Dirk Greef from TigerBeetle made the rounds. If I may summarize, the gist of the presentation was that the correct programming model can mean many orders of magnitude performance difference. As the presentation did not explore this, I wanted to see how far we get by adjusting our programming style on boring old relational databases.
As my aim is not to engage in competitive benchmarking I will not try to reproduce the exact benchmark used in the talk. Rather I will be using our trusty old pgbench, which implements workload described in TPC-B. Not at all coincidentally, this is almost exactly Jim Gray’s DebitCredit workload referenced in the talk. Here is the benchmark script used:
\set aid random(1, 100000 * :scale) \set bid random(1, 1 * :scale) \set tid random(1, 10 * :scale) \set delta random(-5000, 5000) BEGIN; UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid; SELECT abalance FROM pgbench_accounts WHERE aid = :aid; UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid; UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid; INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP); END;
The important tunable parameter here is the scale factor. This determines the size of the database - about 17MB per increment - but also the number of branches. The general wisdom is that one shouldn’t benchmark the database with a low scale factor, because then you get bad performance due to contention. But bad performance due to contention on hot rows is exactly what happens in real world transaction systems. So instead of increasing the scale factor, I’m going to keep it at 10 to have something equivalent to 10% contention, and will look into increasing performance using other means.
The benchmark was done using PostgreSQL 18 running on Ryzen 9 9900X and a Samsung 990 Pro NVMe drive. The only tuning
PostgreSQL 19 changes this week New GUC debug_print_raw_parse Option max_retention_duration added for subscriptions COPY : hint added for COPY TO when a WHERE clause was provided, noting that COPY (SELECT ... WHERE ...) TO can be used instead PostgreSQL 18 changes this week
PostgreSQL 18 RC1 has been released ( announcement ).
If you ever get the error message “database is not accepting commands”, you are dangerously close to transaction ID wraparound. Most PostgreSQL users understand the principle behind transaction ID wraparound, but I recently realized that even many PostgreSQL power users have a wrong idea of how to fix the problem. So I decided to write about it in some more detail.
How do you end up with “database is not accepting commands”?
If you end up with this error, your application will have down time while you manually repair the problem. In this state, you can still run queries, but you cannot perform any more data modifications. Few people ever get that far, because PostgreSQL has several lines of defense before it has to take this last, invasive measure:
if a table contains live rows older than autovacuum_freeze_max_age transactions (200 million by default), PostgreSQL will launch an anti-wraparound autovacuum worker
if a table contains live rows older than vacuum_failsafe_age transactions (1.6 billion by default), PostgreSQL will launch an emergency anti-wraparound autovacuum worker that skips the index cleanup step and runs as fast as it can
40 million transactions before transaction ID wraparound, you will get warnings in the log
Only if none of these safeties can prevent the problem will PostgreSQL stop data modifications.
There are a few ways to prevent PostgreSQL from fixing the problem by itself:
keep a database transaction open forever
keep a prepared transaction around without committing it or rolling it back
keep an orphaned replication slot with the standby server having hot_standby_feedback enabled
have data corruption that makes VACUUM fail
What is the proper measure against “database is not accepting commands”?
I decided to make this the 1.0 Version. The First commit is from 2017-08-11, the extension is now more than eight years old.
News
The project started as a personal repository. When I left GitHub, see Leaving GitHub and GitHub is History for details, I decided to move it to a project on its own on Codeberg.
Website
The website on pgsql-tweaks.org has been setup first with the HTML help page of the project.
Now it is a real website realised with Jekyll. Future changes of pgsql_tweaks will be blogged on pgsql-tweaks.org/blog. The source code is part of the project on Codeberg.
Also the documentation has been changed from a single Markdown file to a website, also realised with Jekyll on rtfm.pgsql-tweaks.org. RTFM stands for Read The Fine Manual. The source code is part of the project on Codeberg.
Contribution
This move also opens the possibilities to contribute to the project. The documentation has now detailed information about how to contribute:
Instead of the current default schema, the extension is now created in its own schema. This solves conflicts with other extensions, as has been the case in the past with pgtap, see pgTAP Issue 340 for details.
Documentation for View pg_unused_indexes
The view has not been documented in previous versions.
The PostgreSQL code base has been around for almost 3 decades, and as recent commit 710e6c43 shows, there is still some legacy cruft from the initial import/conversion in need of cleanup:
Remove unneeded casts of BufferGetPage() result BufferGetPage() already returns type Page, so casting it to Page doesn't achieve anything. A sizable number of call sites does this casting; remove that. This was already done inconsistently in the code in the first import in 1996 (but didn't exist in the pre-1995 code), and it was then apparently just copied around.
This a harmless, cosmetic cleanup, but I thought it was an interesting reminder of the longevity of the code.
PostgreSQL 19 changes this week
Main item of note this week is that the C requirement has been raised from C99 to C11 (commit f5e0186f ).
PostgreSQL 18 changes this week
The release schedule has been tentatively announced :
18rc1 : 2025-09-04 18.0 : 2025-09-25
Note that these dates assume no unexpected issues are found with the current code.
How many people/services have superuser access to your PostgreSQL cluster(s)? Did you ever ask why your software engineers might need it? Or your BI team? Why those use cases require same privileges as someone who can drop your databases?
The answer isn't because these operations are inherently dangerous - it's because PostgreSQL historically offered limited options for operational access or simply because not enough people are aware of the options. So the common practice is to either got basic permissions or handover the keys to the kingdom.
PostgreSQL's built-in predefined roles solve this problem by providing purpose-built privileges for common maintenance tasks. Instead of granting superuser access for routine operations, you can delegate specific capabilities
monitoring teams get comprehensive observability access, backup services get data reading capabilities, and maintenance scripts get precisely the permissions they need, nothing more.
PostgreSQL's built-in administrative roles are purpose-built permission sets that solve the superuser dilemma for common maintenance tasks. Out of the box, there are 15 predefined roles that provide granular access to specific operational capabilities without requiring full superuser privileges.
While you can view their list and description in official documentation, in this article we will explore them bit more thoroughly and at the same time look into system catalogs to understand them better. The individual roles can be grouped by their functionality and most of them are quite easy to grasp, ranging from simple monitoring access to powerful filesystem operations that require careful consideration.
Next month, I'll be hosting 2 or 3 discussions of Thomas Munro's talk, Investigating Multithreaded PostgreSQL, given at 2025.pgconf.dev (talk description here). If you're interested in joining us, please sign up using this form and I will send you an invite to one of the sessions. Thanks to Thomas for agreeing to attend the sessions. As usual, nobody is too inexperienced to join us, and nobody is too experienced. We have everyone from total newcomers to interested committers.
Postgres 18 is adding asynchronous i/o. This means faster reads for many use cases. This is also part of a bigger series of performance improvements planned for future Postgres, part of which may be multi-threading. Expect to see more on this in coming versions.
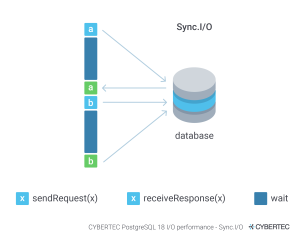
What is async I/O?
When data isn’t in the shared memory buffers already, Postgres reads from disk, and I/O is needed to retrieve data. Synchronous I/O means that each individual request to the disk is waited on for completion before moving on to something else. For busy databases with a lot of activity, this can be a bottleneck.
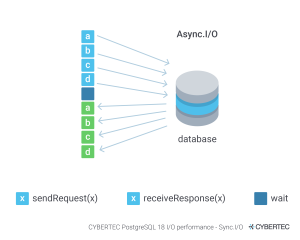
Postgres 18 will introduce asynchronous I/O, allowing workers to optimize idle time and improve system throughput by batching reads. Currently, Postgres relies on the operating system for intelligent I/O handling, expecting OS or storage read-ahead for sequential scans and using features like Linux's posix_fadvise for other read types like Bitmap Index Scans. Moving this work into the database with asynchronous I/O will provide a more predictable and better-performing method for batching operations at the database level. Additionally, a new system view, pg_aios, will be available to provide data about the asynchronous I/O system.
Postgres writes will continue to be synchronous - since this is needed for ACID compliance.
If async i/o seems confusing, think of it like ordering food at a restaurant. In a synchronous model, you would place your order and stand at the counter, waiting, until your food is ready before you can do anything else. In an asynchronous model, you place your order, receive a buzzer, and are free to go back to your table and chat with friends until the buzzer goes off, signaling that your food is ready to be picked up.
Async I/O will affect:
sequential scans
bitmap heap scans (following the bitmap index scan)
It's been a while since the last performance check of Transparent Data Encryption (TDE) in Cybertec's PGEE distribution - that was in 2016. Of course, the question is still interesting, so I did some benchmarks.
Since the difference is really small between running without any extras, with data checksums turned on, and with both encryption and checksums turned on, we need to pick a configuration that will stress-test these features the most. So in the spirit of making PostgreSQL deliberately run slow, I went with only 1MB of shared_buffers with a pgbench workload of scale factor 50. The 770MB of database size will easily fit into RAM. However, having such a small buffer cache setting will cause a lot of cache misses with pages re-read from the OS disk cache, checksums checked, and the page decrypted again. To further increase the effect, I ran pgbench --skip-some-updates so the smaller, in-cache-anyway pgbench tables are not touched. Overall, this yields a pretty consistent buffer cache hit rate of only 82.8%.
Here are the PGEE 17.6 tps (transactions per second) numbers averaged over a few 1-minute 3-client pgbench runs for different combinations of data checksums on/off, TDE off, and the various supported key bit lengths:
My trip to pgday.at started Wednesday at the airport in Düsseldorf. I was there on time, and the plane started with an estimated flight time of about 90 minutes. About half an hour into the flight, the captain announced that we would be landing in 30 minutes - in Düsseldorf, because of some unspecified technical problems. Three hours after the original departure time, the plane made another attempt, and we made it to Vienna.
On the plane I had already met Dirk Krautschick who had the great honor of bringing Slonik (in the form of a big extra bag) to the conference, and we took a taxi to the hotel. On the taxi, the next surprise happened: Hans-Jürgen Schönig unfortunately couldn't make it to the conference, and his talks had to be replaced. I had submitted a talk to the conference, but it was not accepted, and neither queued on the reserve list. But two speakers on the reserve list had cancelled, and another was already giving a talk in parallel to the slot that had to be filled, so Pavlo messaged me if I could hold the talk - well of course I could. Before, I didn't have any specific plans for the evening yet, but suddenly I was a speaker, so I joined the folks going to the speakers dinner at the Wiener Grill Haus two corners from the hotel. It was a very nice evening, chatting with a lot of folks from the PostgreSQL community that I had not seen for a while.
Thursday was the conference day. The hotel was a short walk from the venue, the Apothekertrakt in Vienna's Schloss Schönbrunn. The courtyard was already filled with visitors registering for the conference. Since I originally didn't have a talk scheduled, I had signed up to volunteer for a shift as room host. We got our badge and swag bag, and I changed into the "crew" T-shirt.
The opening and sponsor keynotes took place in the main room, the Orangerie. We were over 100 people in the room, but apparently still not enough to really fill it, so the acoustics with some echo made it a bit difficult to understand everything. I hope that part ca
This article has been published with explicit permission from Jesús Espino. It's a copy of a post originally published on his LinkedIn account on September 16, 2024.
This has been my first time talking at a Postgres conference, and it has been amazing. I must admit that I felt really small there, surrounded by speakers from projects like Omnigres, Timescale, OnGres, or Yugabyte. Still, I think there was value in my talk about understanding the inner workings of a SQL query inside Postgres.
One important thing to notice is that Ibiza is a great place for a conference. It is a gorgeous environment, very well connected internationally, and with a very relaxed vibe. It sounds like Ibiza is for a party, but I think that is a huge misrepresentation of what Ibiza is.
But let's jump into the conference itself. It was a relatively small conference regarding people—I would say less than 100 (I don't know the exact numbers). What was amazing was having more opportunity to talk with almost everybody. Also, the conference was a single-track conference with pros and cons, but I have to admit that I enjoyed almost every talk, so my main concern with single-track conferences is gone.
The first day
We started the conference with a quick introduction to the event by Álvaro Hernández Tortosa and 🎙Bart Farrell (Who was also the MC and photographer for the conference).
The first day of the conference started with Tania Ash and Andrei Zaichikov sharing their experience with massive migrations to PostgreSQL in big regulated organizations. They talked about the methodology they used there (Manada). They also discussed the technical problem and the organizational part and how important it is to tackle it all together.
The second one was from Mayuresh B., who discussed the possible tricky situations when migrating from Oracle to PostgreSQL. For example, Oracle RAC is not equivalent to Patroni. Or the fact that Oracle has some subquery caching that doesn't exist in PostgreSQL can catch you off-guard after wha
It is that time of the year again. The first release candidate of PostgreSQL 18 is out, and things look promising. We should expect General Availability in the next 2-4 weeks.
Exciting times!
Over the past many years and as many releases, the PostgreSQL community has done a phenomenal job of being disciplined about the annual release process. And we have done so averaging 150+ new features with each release!
For the upcoming v18, here are the top three features I am most excited about:
#1 – Asynchronous I/IO
PostgreSQL 18 introduces a significant under‑the‑hood change with itsAsynchronous I/O (AIO)subsystem, which fundamentally alters how the database performs disk reads.
What asynchronous I/O does
Historically, PostgreSQL issued synchronous disk reads: each backend process would call the operating system, wait for the data to arrive, and then continue processing. This “one book at a time” model left CPUs idle whenever storage was slow (especially on network‑attached disks), limiting throughput. The new subsystem lets a backend queue multiple read requests at once, allowing other work to continue while data is being fetched. When the requested blocks are ready, PostgreSQL copies them directly into shared buffers, eliminating reliance on the kernel’s readahead heuristics.
How it works
1. io_method – A new server setting chooses the implementation:
syncreplicates the old synchronous behaviour.
workeruses dedicated I/O worker processes. The main backend enqueues read requests and continues execution while these workers interact with the kernel. You can configure the number of workers viaio_workers.
io_uring(Linux only) leverages the kernel’s high‑performance io_uring API to submit and complete I/O requests without separate worker processes.
2. Tuning and monitoring– New variablesio_combine_limitandio_max_combine_limitdetermine how many adjacent
Recently, I read Laurenz Albe's blog about case insensitive string search. He recommended case insensitive collations saying, "it won't be any more expensive (and maybe more intuitive) than the current techniques of using upper() or the citext extension are today". In other words, a custom collation can be used instead of citext to achieve case insensivity with a lower performance penalty. Today we will be testing it.
We created the collation as case insensitive but accent sensitive beceause citext works in the same way.
create extension citext; CREATE TABLE demo2 ( word citext ); INSERT INTO demo1 VALUES ('apple'), ('APPLE'), ('Åpple'), ('Apple'); INSERT INTO demo2 VALUES ('apple'), ('APPLE'), ('Åpple'), ('Apple');
Then duplicate all these records until we have ~32m rows for both tables.
insert into demo1 select * from demo1; insert into demo1 select * from demo1; . . . select count(*) from demo2; count 33554432 (1 row) select count(*) from demo5; count 33554432 (1 row) create index x on demo1(word); create index y on demo2(word); update demo1 set word = 'applex' where ctid = '(0,1)'; update demo2 set word = 'applex' where ctid = '(0,1)';
Comparison For Different Operators
"=" Operator
The following results show the average execution time after executing them 20 times:
explain(analyze) select * from demo1 where word = 'applex'; QUERY PLAN ----------------------------------------------------------------------------------------------------------------- Index Only Scan using x on demo1 (cost=0.56..4.58 rows=1 width=6) (actual time=0.092..0.096 rows=1.00 loops=1) Index Cond: (word = 'applex'::text) Heap Fetches: 1 Index Searches: 1 Buffers: sh
In November last year after nearly two decades at my previous gig, I came to the conclusion that I didn’t want to work at what seemed to be rapidly becoming an AI-focused company and moved to pgEdge where the focus is well and truly on distributed PostgreSQL and Postgres generally. Distributed databases (and particularly Postgres of course) have always been a passion of mine – even being a key topic of my master’s dissertation many years ago.Moving to pgEdge was a breath of fresh air. Not only did I get to work with some outstanding engineers and other folks on Postgres, but a good number of them were friends and colleagues that I’d worked with in the past. I’ve since had the privilege of hiring even more colleagues from the Postgres world, and look forward to expanding the team even further with more fantastic engineers from the PostgreSQL and wider database communities.There was a wrinkle in my ideal view of how things should be though - the key components of pgEdge were “source available” and not Open Source. That means the source code to our replication engine known as Spock and key extensions such as Snowflake which provides cluster-wide unique sequence values and Lolor which enables logical replication of large objects, had a proprietary licence – known as the pgEdge Community License – which allowed you to view and modify the source code, but limited how you could actually use it. Well, I’m pleased to be able to say that that is no longer the case. All the core components of pgEdge Distributed Postgres, along with any other pgEdge repositories that previously used the pgEdge Community License have now been re-licenced under the permissive PostgreSQL License, as approved by the Open Source Initiative!We’re proud to be able to make this change to support Open Source software and contribute to the PostgreSQL ecosystem, and I’m looking forward to seeing us continue to expand our contributions as much as we can.So, if you want to try out multimaster distributed Postgres, and get involved with the development
Case-insensitive search is one of the most common issues I encounter when helping customers migrate from Oracle or SQL Server to PostgreSQL. Unlike Oracle (with NLS_SORT) or SQL Server (with case-insensitive collations), PostgreSQL does not natively support case-insensitive search. Developers typically rely on workarounds such as:
Let’s us create a sample tables with columns having collate collate_ci.
create table testcollation(col1 text collate collate_ci); insert into testcollation values ('a'); insert into testcollation values ('A'); select * from testcollation where col1 = 'a'; col1 ------ a A (2 rows)
using nondeterministic collation help’s us implement case insensitive comparison with equality operator’s. But let’s see how it will works for like or ilike operators for wild card based searches.
→ Handle Wild Operators Failure (Like).
Using nondeterministic collations help us achieve case-sensitives search but when used with wildcards operators (like or ilike) it fails as it is not supported till PostgreSQL 17 version.
postgres=> select * from testcollation where col1 like 'a%'; ERROR: nondeterministic collations are not supported for LIKE
TPC-C is supposedly the most objective performance measurement of OLTP database systems… and I’ve used it quite a fair bit over the years as well…yet, running it on Postgres is sadly not exactly as smooth as things typically are with Postgres 😔 If to compare at least with the wonderful...









 Ian Barwick - 8
Ian Barwick - 8