oneAPI Implementations
oneAPI delivers a common developer experience across diverse architectures (CPU, GPU, FPGA and accelerators) for faster application performance, more productivity, and greater innovation.


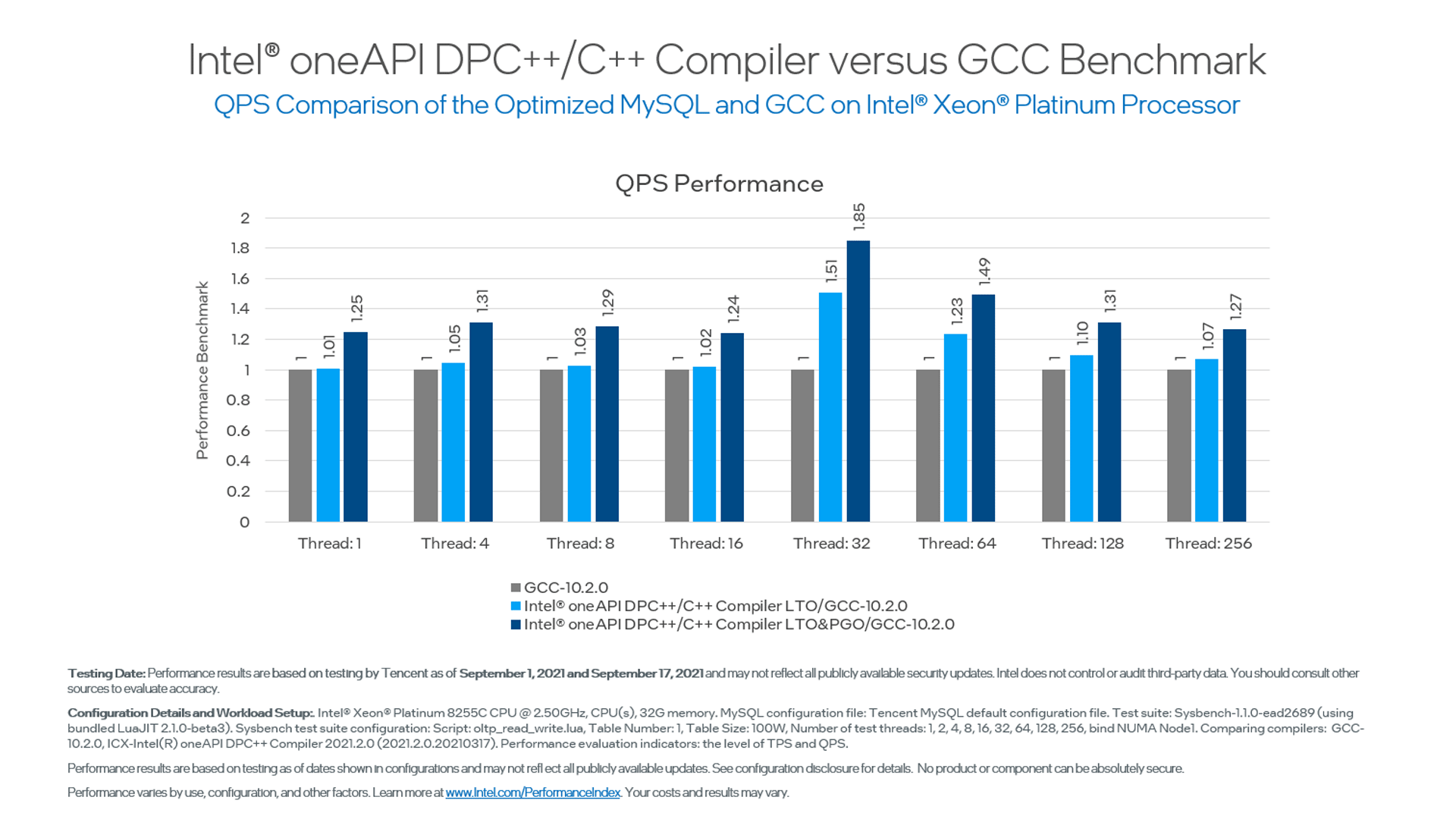
Tencent collaborated with Intel to build a high-performance MySQL on Intel® Xeon® Processors and optimized by the Intel® oneAPI DPC++/C++ Compiler, an advanced compiler in the Intel® oneAPI Base Toolkit.
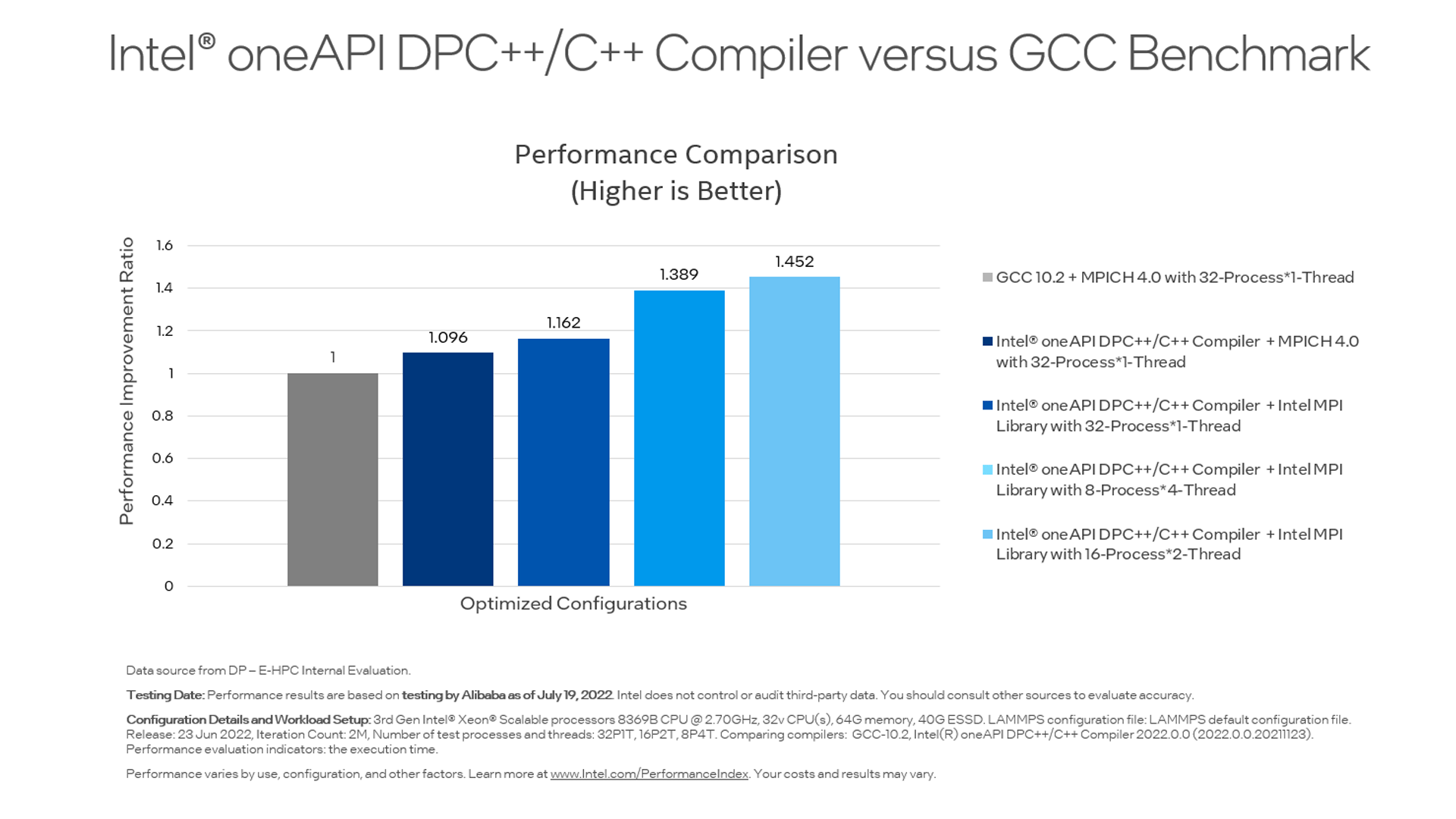
DP needed to run LAMMPS workloads, which are particularly challenging due to their inherent complex simulations and changing dynamics. Using the combination of Alibaba’s E-HPC Cloud Service and Intel® hardware and oneAPI software, DP Technology achieved about 45.2% performance improvement.

Enabling software developers to write code once, and then tune it for multiple accelerator platforms, is the holy grail for the high-performance computing (HPC) and supercomputing industry. Such a breakthrough would eliminate writing separate code for multiple accelerator platforms, a time-consuming and costly exercise that takes talented developers away from working on critical projects.

Claiming the title of world’s fastest performance for the number of deep learning models trained per time unit for CosmoFlow, Fujitsu and RIKEN take first place for MLPerf HPC Benchmark with supercomputer Fugaku. By applying technology to programs used on the system that reduce the mutual interference of communication between CPUs, they were able to train the system at a rate of 1.29 deep learning models per minute – approximately 1.77 times faster than other systems.
At the Supercomputing SC21 conference last year there were many research papers and presentations to help us learn more about how SYCL is being used across the industry. One of the sessions that stood out for me was presented by Dr. Vincent Pascuzzi from Brookhaven National Laboratory whose research paper was co-authored with Mehdi Goli, VP Research at Codeplay® and outlined the collaboration that is being done to advance research using the Large Hadron Collider.

Software developers now have a tool for running heterogeneous hardware to maximize computing power for a range of workloads across all devices – thanks to the oneAPI specification. To achieve advanced computing capabilities, they’re replacing coding obstacles with a single, open-source programming model for CPUs, GPUs, FPGAs, and more.

The new collaboration puts teeth into Intel’s promises of hardware-agnostic AI.
Intel and Argonne National Laboratory said they will co-design and validate exascale-class applications using the chipmaker’s GPUs, microarchitecture and developer tools.

The National Energy Research Scientific Computing Center (NERSC) at Lawrence Berkeley National Laboratory (Berkeley Lab), in collaboration with the Argonne Leadership Computing Facility (ALCF) at Argonne National Laboratory, has signed a contract with Codeplay Software to enhance the LLVM SYCL™ GPU compiler capabilities for NVIDIA® A100 GPUs.