Create Language Translator using Deep Learning
With this Machine Learning Project, we will be building a language translator system. We are going to build this model using the Sequential model and encoder-decoder. Language translator is a system in which we passed the input in one language and get the result in some other language. This type of system is very useful when you go to some other country and language is an issue for you. This system can be converted into an app and can be easily used by people.
So, let’s start with the project.
Language Translation
This is a tool that converts languages from English to French. This tool is useful for those users who want to translate a few sentences for chatting purposes as well as those who need to translate English into French regularly. We hope this translator will be useful to both types of users. Aside from the speed and stability provided by Google’s Translator tool, this online software provides both. For writing purposes, the Translation Tool can even act as a dictionary.
The results may not always be as accurate as you would like, but don’t worry as research in this field is ongoing to bring you new revelations. So we will update it consistently as new discoveries come up. In translation, there are inherent difficulties because the distinctions between grammatical, syntactic, and morphological aspects of the languages. Despite the fact that these languages have different translation mechanisms, a wide gulf remains between them.
The Model Architecture
With regard to NLP, the goal of a seq2seq model is to calculate the probability of an output sequence of words based on an input sequence of words. The dog is big > the big is dog is useful for machine translation as we may have a bunch of potential translations. It is also possible that we need to choose a word that is appropriate to a given sequence, such as running late for work vs. jogging late for work.
Our model needs to encode each sequence of words into a vector that is easy to digest by the model, and then decode that vector into our target language. Although we could use one model to encode and decode, then the input length may not align with the output length, for example “my mum loves France” becomes “ma maman aime la france” – requiring an extra word. There is no guarantee that these output sequence lengths will be known in advance.
After that, the decoder takes the last hidden vector (c=ht), the previous hidden state (ht-1), and the expected prediction (yt-1). Since the softmax is also calculated from the last hidden vector of the encoder, it may seem strange that we use the previous predicted output word, but by doing so, it allows the softmax to factor into the current prediction (yt). Yt-1 also provides a definitive answer rather than a probability distribution, thus preventing a repeated word.
In this machine learning project, we will train data using the Long Short-Term Memory (LSTM) method, and evaluate the output subjectively.
Schmidhuber and Hochreiter proposed the LSTM unit. There have been several modifications to LSTM since its inception. The image below shows the schematic for the LSTM block. An output activation function is enabled by peephole connections and three gates (input, forget, and output). Recurrent connections are made between the block input and the block output.
Project Prerequisites
The required modules for this project are :
- Pandas – pip install pandas
- Numpy- pip install numpy
- Sklearn – pip install sklearn
- Tensorflow – pip install tensorflow
Language Translator Project
This dataset contains sentences in English and their conversion into the French language. Please download language translator deep learning code along with the dataset from the following link: Language Translator Project
Steps to Implement Language Translator
1. Here, we are importing all the modules.
import string import re from numpy import array, argmax, random, take import pandas as pd from keras.models import Sequential from keras.layers import Dense, LSTM, Embedding, RepeatVector from keras.preprocessing.text import Tokenizer from keras.callbacks import ModelCheckpoint from keras_preprocessing.sequence import pad_sequences from keras.models import load_model from keras import optimizers import matplotlib.pyplot as plt %matplotlib inline pd.set_option('display.max_colwidth',200) 2. Here we are reading the text file and storing it in a variable.
data_path = 'eng-fra.txt' with open(data_path,'r',encoding='utf-8') as f: lines = f.read() lines
3. Here we are converting our paragraphs into lines so that it will be easy to work on it.
def para_to_lines(text): sen = text.strip().split('\n') sen = [i.split('\t') for i in sen] return sen fra_eng = para_to_lines(lines) fra_eng[:2] 4. Here we have just dropped some rows because otherwise, it will take really long time to process the model and we have removed the punctuation and full stop from our data.
fra_eng = array(fra_eng) fra_eng = fra_eng[:90000,:] fra_eng = fra_eng[:,[0,1]] fra_eng[:,0] = [s.translate(str.maketrans('','',string.punctuation)) for s in fra_eng[:,0]] fra_eng[:,1] = [s.translate(str.maketrans('','',string.punctuation)) for s in fra_eng[:,1]] for i in range(len(fra_eng)): fra_eng[i,0] = fra_eng[i,0].lower() fra_eng[i,1] = fra_eng[i,1].lower() fra_eng 5. Here we are defining our tokenization function which will take the text as the input. We will pass English and french differently and get separate tokenizers for both of them.
def tokenization(lines): tokenizer = Tokenizer(); tokenizer.fit_on_texts(lines) return tokenizer eng_tokenizer = tokenization(fra_eng[:,0]) eng_vocab_size = len(eng_tokenizer.word_index) + 1 eng_length = 8 fra_tokenizer = tokenization(fra_eng[:,1]) fra_vocab_size = len(fra_tokenizer.word_index) + 1 fra_length = 8
6. Here is our encoder function. It will take the tokenizer and the length of the text which we want to encode.
def encode_sequence(tokenizer,length,lines): seq = tokenizer.texts_to_sequences(lines) seq = pad_sequences(seq, maxlen = length, padding='post') return seq
7. Here we are dividing our data into testing and training data. Also we are defining our model that we are going to use in this project.
from sklearn.model_selection import train_test_split train, test = train_test_split(fra_eng, test_size=0.2, random_state = 12) trainX = encode_sequence(fra_tokenizer, fra_length, train[:,1]) trainY = encode_sequence(eng_tokenizer, eng_length, train[:,0]) testX = encode_sequence(fra_tokenizer, fra_length, test[:,1]) testY = encode_sequence(eng_tokenizer, eng_length, test[:,0]) def define_model(in_vocab, out_vocab, in_timesteps, out_timesteps, units): model = Sequential() model.add(Embedding(in_vocab,units,input_length=in_timesteps, mask_zero = True)) model.add(LSTM(units)) model.add(RepeatVector(out_timesteps)) model.add(LSTM(units,return_sequences=True)) model.add(Dense(out_vocab,activation = 'softmax')) return model model = define_model(fra_vocab_size, eng_vocab_size, fra_length,eng_length, 512) rms = optimizers.RMSprop(lr=0.001) model.compile(optimizer = rms, loss= 'sparse_categorical_crossentropy') history = model.fit(trainX, trainY.reshape(trainY.shape[0],trainY.shape[1],1), epochs=10,batch_size=512, validation_split = 0.2) preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
8. Here is a decoder function. It will take the tokenizer and will convert the word for us from French to English or vice-versa. After that, we are calling this function on English tokenizer, and then we are converting the output and storing it into a list.
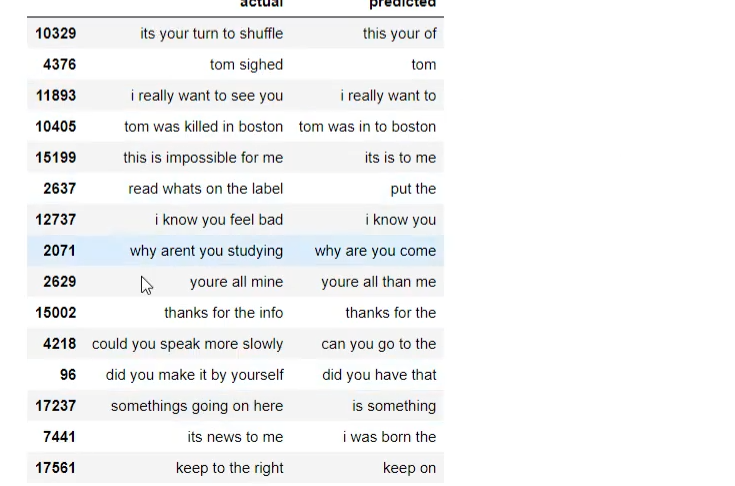
def get_word(n, tokenizer): for word, index in tokenizer.word_index.items(): if index==n: return word return None preds_text = [] for i in preds: temp = [] for j in range(len(i)): t = get_word(i[j],eng_tokenizer) if j>0: if(t==get_word(i[j-1], eng_tokenizer)) or (t==None): temp.append('') else: temp.append(t) else: if(t==None): temp.append('') else: temp.append(t) preds_text.append(' '.join(temp)) pred_df = pd.DataFrame({'actual':test[:,0], 'predicted':preds_text}) pred_df.sample(15) Language Translator Output
Summary
In this Machine Learning project, we learned how to build a language translation system. In this project, we have used tokenization and the Sequential model for translating the language. We hope you have learned something new in this project.