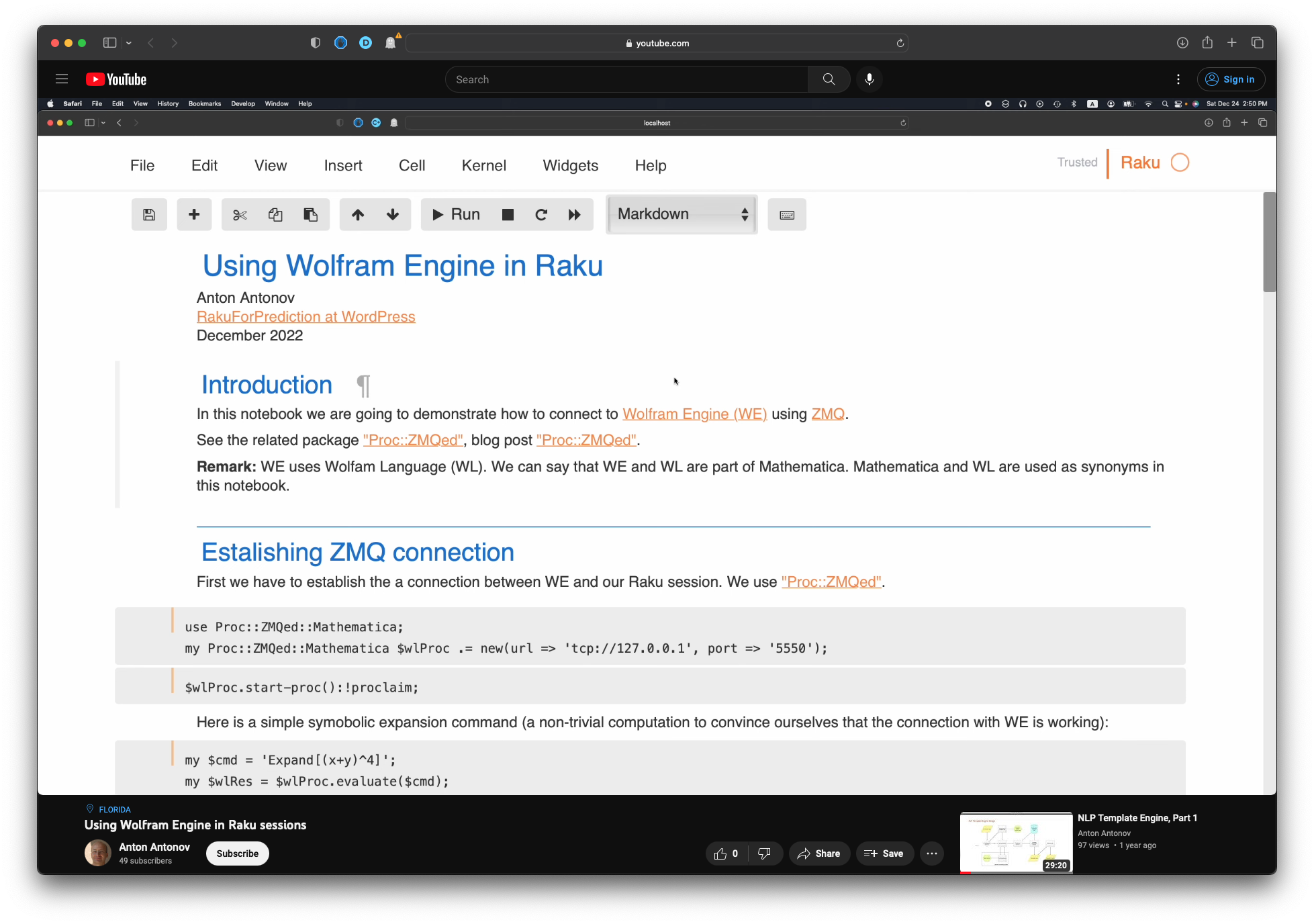
Introduction
In this article we proclaim the preparation and availability of interactive interfaces to two Time Series Search Engines (TSSEs) over COVID-19 data. One TSSE is based on Apple Mobility Trends data, [APPL1]; the other on The New York Times COVID-19 data, [NYT1].
Here are links to interactive interfaces of the TSSEs hosted (and publicly available) at shinyapps.io by RStudio:
Motivation: The primary motivation for making the TSSEs and their interactive interfaces is to use them as exploratory tools. Combined with relevant data analysis (e.g. [AA1, AA2]) the TSSEs should help to form better intuition and feel of the spread of COVID-19 and related data aggregation, public reactions, and government polices.
The rest of the article is structured as follows:
- Brief descriptions the overall process, the data
- Brief descriptions the search engines structure and implementation
- Discussions of a few search examples and their (possible) interpretations
The overall process
For both search engines the overall process has the same steps:
- Ingest the data
- Do basic (and advanced) data analysis
- Make (and publish) reports detailing the data ingestion and transformation steps
- Enhance the data with transformed versions of it or with additional related data
- Make a Time Series Sparse Matrix Recommender (TSSMR)
- Make a Time Series Search Engine Interactive Interface (TSSEII)
- Make the interactive interface easily accessible over the World Wide Web
Here is a flow chart that corresponds to the steps listed above:

Data
The Apple data
The Apple Mobility Trends data is taken from Apple’s site, see [APPL1]. The data ingestion, basic data analysis, time series seasonality demonstration, (graph) clusterings are given in [AA1]. (Here is a link to the corresponding R-notebook .)
The weather data was taken using the Mathematica function WeatherData, [WRI1].
(It was too much work to get the weather data using some of the well known weather data R packages.)
The New York Times data
The New York Times COVID-19 data is taken from GitHub, see [NYT1]. The data ingestion, basic data analysis, and visualizations are given in [AA2]. (Here is a link to the corresponding R-notebook .)
The search engines
The following sub-sections have screenshots of the TSSE interactive interfaces.
I did experiment with combining the data of the two engines, but did not turn out to be particularly useful. It seems that is more interesting and useful to enhance the Apple data engine with temperature data, and to enhance The New Your Times engine with the (consecutive) differences of the time series.
Structure
The interactive interfaces have three panels:
- Nearest Neighbors
- Gives the time series nearest neighbors for the time series of selected entity.
- Has interactive controls for entity selection and filtering.
- Trend Finding
- Gives the time series that adhere to a specified named trend.
- Has interactive controls for trend curves selection and entity filtering.
- Notes
- Gives references and data objects summary.
Implementation
Both TSSEs are implemented using the R packages “SparseMatrixRecommender”, [AAp1], and “SparseMatrixRecommenderInterfaces”, [AAp2].
The package “SparseMatrixRecommender” provides functions to create and use Sparse Matrix Recommender (SMR) objects. Both TSSEs use underlying SMR objects.
The package “SparseMatrixRecommenderInterfaces” provides functions to generate the server and client functions for the Shiny framework by RStudio.
As it was mentioned above, both TSSEs are published at shinyapps.io. The corresponding source codes can be found in [AAr1].
The Apple data TSSE has four types of time series (“entities”). The first three are normalized volumes of Apple maps requests while driving, transit transport use, and walking. (See [AA1] for more details.) The fourth is daily mean temperature at different geo-locations.
Here are screenshots of the panels “Nearest Neighbors” and “Trend Finding” (at interface launch):


The New York Times TSSE has four types of time series (aggregated) cases and deaths, and their corresponding time series differences.
Here are screenshots of the panels “Nearest Neighbors” and “Trend Finding” (at interface launch):


Examples
In this section we discuss in some detail several examples of using each of the TSSEs.
Apple data search engine examples
Here are a few observations from [AA1]:
- The COVID-19 lockdowns are clearly reflected in the time series.
- The time series from the Apple Mobility Trends data shows strong weekly seasonality. Roughly speaking, people go to places they are not familiar with on Fridays and Saturdays. Other work week days people are more familiar with their trips. Since much lesser number of requests are made on Sundays, we can conjecture that many people stay at home or visit very familiar locations.
Here are a few assumptions:
- Where people frequently go (work, school, groceries shopping, etc.) they do not need directions that much.
- People request directions when they have more free time and will for “leisure trips.”
- During vacations people are more likely to be in places they are less familiar with.
- People are more likely to take leisure trips when the weather is good. (Warm, not raining, etc.)
Nice, France vs Florida, USA
Consider the results of the Nearest Neighbors panel for Nice, France.
Since French tend to go on vacation in July and August ([SS1, INSEE1]) we can see that driving, transit, and walking in Nice have pronounced peaks during that time:



Of course, we also observe the lockdown period in that geographical area.
Compare those time series with the time series from driving in Florida, USA:

We can see that people in Florida, USA have driving patterns unrelated to the typical weather seasons and vacation periods.
(Further TSSE queries show that there is a negative correlation with the temperature in south Florida and the volumes of Apple Maps directions requests.)
Italy and Balkan countries driving
We can see that according to the data people who have access to both iPhones and cars in Italy and the Balkan countries Bulgaria, Greece, and Romania have similar directions requests patterns:

(The similarities can be explained with at least a few “obvious” facts, but we are going to restrain ourselves.)
The New York Times data search engine examples
In Broward county, Florida, USA and Cook county, Illinois, USA we can see two waves of infections in the difference time series:


References
Data
[APPL1] Apple Inc., Mobility Trends Reports, (2020), apple.com.
[NYT1] The New York Times, Coronavirus (Covid-19) Data in the United States, (2020), GitHub.
[WRI1] Wolfram Research (2008), WeatherData, Wolfram Language function.
Articles
[AA1] Anton Antonov, “Apple mobility trends data visualization (for COVID-19)”, (2020), SystemModeling at GitHub/antononcube.
[AA2] Anton Antonov, “NY Times COVID-19 data visualization”, (2020), SystemModeling at GitHub/antononcube.
[INSEE1] Institut national de la statistique et des études économiques, “En 2010, les salariés ont pris en moyenne six semaines de congé”, (2012).
[SS1] Sam Schechner and Lee Harris, “What Happens When All of France Takes Vacation? 438 Miles of Traffic”, (2019), The Wall Street Journal
Packages, repositories
[AAp1] Anton Antonov, Sparse Matrix Recommender framework functions, (2019), R-packages at GitHub/antononcube.
[AAp2] Anton Antonov, Sparse Matrix Recommender framework interface functions, (2019), R-packages at GitHub/antononcube.
[AAr1] Anton Antonov, Coronavirus propagation dynamics, (2020), SystemModeling at GitHub/antononcube.