In the Useful Authors group, I learned to test my book’s content by teaching it first. To some extent, I did that on this blog. But that doesn’t work as well as doing it in a way where you can get a reaction. This lets you figure out if what you plan to write will resonate with your audience.
With Swimming in Tech Debt, my main way of teaching the book was to talk about tech debt with my clients and my developer friends. I would also make LinkedIn posts with excerpts from what I was writing. So much of the book, though, is based on past conversations I had had for decades at work. Some of those conversations were meant as “teaching” via training, feedback, or mentorship. A lot of it was just figuring it out as a group.
I also shared chapters online in places where it was easy to give feedback (like helpthisbook.com). Some readers have invited me to speak to groups inside of their companies. Part 4 of the book (for CTOs) started as a presentation. I was also asked for an excerpt by the Pragmatic Engineer. His audience’s reaction in comments and emails helped shape the book. It let me know which parts were the most useful and worth expanding on.
One thing I didn’t do early enough was to turn my pre-book notes into conference pitches. I finally did do that after the first draft was done, and next week, I’ll be sharing that with QA professionals at STARWEST.
In all of these cases, you are the proxy for your book before you write it. You just tell people the things you plan to write. You are hoping that it leads to a conversation where you learn if your ideas are worth writing about.
I am sharing this in the spirit of posts like this, this, and this that give insight into what it’s like to have a popular Show HN post. Like those posts, I have stats, but I didn’t make my post very strategically, so I don’t have much advice about that. What happened to me was more accidental (as I will describe), but I have some ideas on what worked.
Timeline
On September 6th, I woke up to find that I had pre-sold 50 copies of Swimming in Tech Debt overnight. For context, at this point I had sold about 125 copies, mostly to people on my mailing list, my personal network, and through LinkedIn. That had started on August 16th with most of the sales in the first week. My daily sales were in the single digits, so the 50 was a big surprise.
My first instinct was that there was some kind of problem. But, I did a quick search and saw the Hacker News post, so I clicked it.
Even though I could see that it had a lot of upvotes and discussion, it was surprising to me because I had posted the “Show HN” four days prior. It had gotten a few votes, no comments, and had scrolled off the bottom of the Show HN front page. I had forgotten about it.
I noticed two things about this post immediately: (1) it had a new date (2) the “Show HN” had been removed from the post title. The post was still attributed to me, but I had not reposted it. I don’t know how this happened, but my post history shows two posts. The newer one eventually had the “Show HN” put back in, but not by me.
I went into the discussion and saw some good and bad feedback on the book (and also for HelpThisBook.com (HTB)—the site I was using to host the book). To be honest, my initial reaction was defensiveness on the bad feedback. But, I replied to everything in the way I would want addressed: answering questions, thanking people, and explaining my point-of-view to those with criticism.
Stats
I am not privy to all of the statistics because I don’t run HelpThisBook (HTB), which I get access to as benefit of being in the Useful Authors Group started by Rob Fitzpatrick, author of Write Useful Books. (Note: our group is running a free 6-week writing sprint starting on September 18th. Hope to see you there).
Here’s what I can see in the data I have access to:
There have been 23,000 clicks to this version of the book. I don’t have referral information, but the vast majority have to be from HN (and the various HN mirrors).
On HTB, I can see readers progressing through the book. A few people finish every day (maybe they buy, I don’t know), and several more are finding it and starting to read each day. They can highlight and give feedback, which they are doing. I used this feature a lot while developing the book (at a much smaller scale) to help make sure the book was engaging readers.
There is a huge drop-off at the first chapter. Perhaps this is due to the HTB UX (it was somewhat criticized in the HN comments). It is also undoubtedly because of the content itself (and is normal, IMO).
On the Amazon KDP site, I can see that in the first day, there were over 100 books sold, and as of now, the total since that day is almost 300, with the daily sales being more like 10-20.
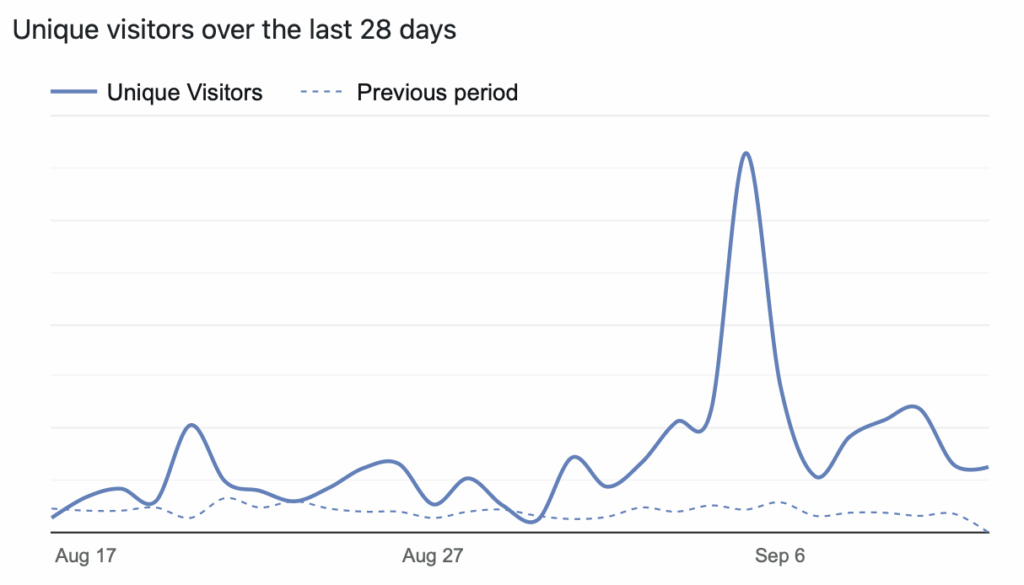
My personal site statistics had a bump compared to the four weeks prior. So far, that has been sustained (but I am also sending more email).
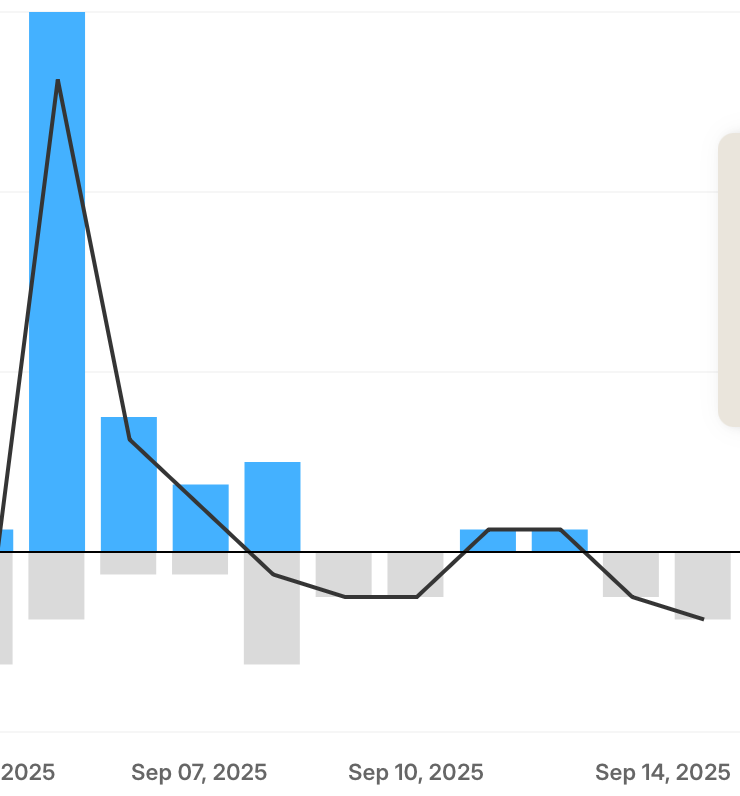
My mailing list subscribers increased too (the tall bar is 24 new subscribers). I am sending excerpts from the next part each day, which is causing some unsubscribes, but if they don’t like the e-mail, then they definitely won’t like the book. I want to make sure that they have every chance of getting the book at $0.99 if they want it.
These are modest, but they are very meaningful to me.
What Makes a Good Show HN Post
In my experience in reading Show HN, the most important thing is having something worth showing. I hope that that’s the main reason this post did well. But, I can’t deny that something happened (either a glitch or moderator changes) that boosted this post’s chances.
I also think that early comments (good and bad) also helped it get traction. When I first went to the post, the top comment was a very funny response about writing and tech debt. There were a few very negative posts, which I engaged with respectfully. Since I had already gotten 50 sales, I knew that the book had at least resonated with some. Tech debt is a topic that people have strong feelings about—I think that drove early comments.
You can’t control any of that, but what you can do is to be ready when it does. Having something for people to do (sign up for a newsletter or buy a book) helps you make something out of the traffic than just hits to your blog. Although HTB was a great choice for gathering feedback from beta readers, if I were posting finished work, I might choose a simpler option where I would have more control over the experience and access to the stats.
What’s Next
I just made the final version of the EPUB for Amazon and set the release date to September 16th. My plan is to leave it a $0.99 for a few days as a kind of soft launch. I don’t want to raise the price until it has reviews.
Then, I will work on the print book. I hope it will be done in October. If you want to be notified of when it is ready, the best way is to sign up to my mailing list. You will also get immediate access to some of the content from Part 3 (HTB only has Parts 1 and 2).
In my book, Swimming in Tech Debt, I write that I don’t think we (engineers) should be explaining tech debt to our non-engineering peers. But that only applies to our tech debt (because it’s boring). Now that they are vibe coding, I do want them to understand their own.
I talk to a lot of vibe coders who are running into the problems caused by tech debt in their projects. They don’t and can’t read code, so my definition of tech debt is hard to convey to them. But, I’ve come up with an analogy that I think works.
Imagine that I “vibe design” a concert poster. I go to DALL-E, give it a prompt and it generates an image for me. I look at it and think it’s 80% of the way there, but I want to make changes. So, I prompt again with more details and it gets closer. I try again, and again, and again, but as I go on, I start to see that some of the things that were right in early versions are gone now. I think to myself, maybe I should take the best version and try to fix it myself in a design tool.
But, then I run into a problem. DALL-E generated pixels, not a design file. It doesn’t have layers. It’s not even using fonts and text components. I just want to rotate a background shape a few degrees and fix a typo, but that’s not possible. Or what if instead of an InDesign file, it can only generate PageMaker files. They are organized perfectly, but in an older technology that I can’t use.
Changes that should be easy are hard (or impossible). Choices that were sane don’t make sense today. All of those aspects of this digital file that are hard to change are very similar to what coders experience with tech debt. It only matters if you want to make changes. It’s the resistance you feel when you try.
The irony is that the same things that made it hard for us is making it hard for the AI too. I can’t tell it to rotate a red triangle in the background because there is not triangle there, just a bunch of pixels. It can’t fix the typo because there aren’t any letters. If it had generated a sane representation, we wouldn’t need to look at because it might have been able to change it for us.
I’ve been writing on this blog for over 20 years. I’ve also released some open-source and a few apps. You have probably never heard of them.
But, when I decided to write a book in January 2024, I joined the Useful Books community, which stresses doing marketing and product design (on your book) up front. It’s paid off.
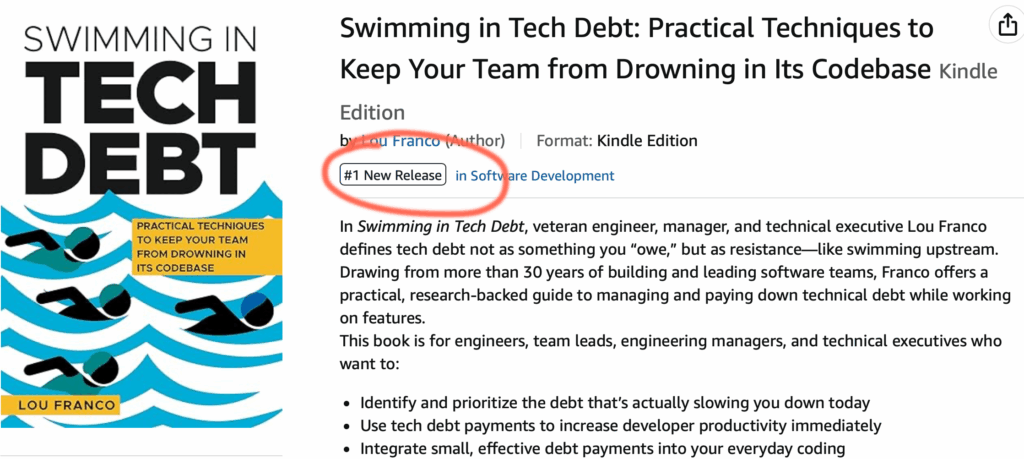
I opened Swimming in Tech Debt for pre-sales a week ago. On Monday, I woke up to being #1 in my category on Amazon.
In retrospect, these were the most important marketing moves I did:
Pick an audience (tech team leads) and then pick a conversation about a problem that they regularly have (tech debt) and write the book that would be your solution to that problem (what you would say in that conversation). The goal is to be recommended by your readers when the topic comes up.
Write in public and share it. I started in January 2024 and shared what I had in February and March. If I had not done that, the book would be 50 pages and finished in June 2024. It wouldn’t be as good and no one would have heard of it (see my previous projects).
Increase the surface area of luck. I posted my chapters in all of my communities to get feedback. Gergely Orosz happened to see it and asked me to pitch for his newsletter that reaches more than one million readers (many in my target audience).
Build an e-mail list. I used Kit (formerly ConvertKit). That list is the reason I reached #1 in my category today. They have been reading chapters and giving feedback all along, so I am very encouraged that they bought the book (because they know it best).
In Tech Debt Detectors and Use Your First Commit to Fix CRAP I explained the concept of combining low code coverage with high code complexity to highlight functions that are risky to change. I mostly do this in my IDE to warn me before I change code, but it’s also useful to use it to do a global search for risky functions.
My main project is in typescript and uses jest and eslint. Here’s how I automated a search for risky functions.
Step 1: Get a list of high complexity functions
Note: by complexity, I am referring to the number of independent paths through a function, which is calculated by counting branches, loops, and boolean expressions.
Eslint has rule that allows you to set a maximum complexity. In my package.json, I call eslint via yarn this way:
"lint": "eslint \"**/*.{ts,tsx}\""
I added a line that does this but with a complexity rule
What I need now is a way to find the coverage of a function given its name. If I run jest via yarn like this:
yarn test --coverage
it will generate a json file called coverage/coverage-final.json which has all of the coverage data. It’s a complex JSON file, but if you install jq via brew, you can use this script to see if it has coverage lower than 80% (credit: ChatGPT)
Onboard a new developer: To fix, they need to refactor and unit-test the functions. They can likely do this without knowing much about your system. This allows them to concentrate on learning your PR processes.
Identify risky estimates: Anyone creating an estimate of a project that will change code should see if the files and functions they intend to change are risky.
Plan tech debt remediation projects: In my book, Swimming in Tech Debt, I outline a process for building and managing a tech debt backlog. You could use a list like this to build backlog items to tackle.
Build a dashboard: It would be nice to show the rest of the org that the number of risky functions you have is decreasing over time.
In PR Authors Have a lot of Control on PR Idle Time, I made the argument that there is work the author could do before they PR their work that would get a PR review started faster. I followed up in A Good Pull Request Convinces You That it is Correct to show how to make the review faster once it started. The upshot is you do a code review on your own code first and fix problems you find. That work doesn’t take long (an hour?), but shaves off hours and days off the code review.
The same technique works for QA: Do your own testing and update the issue/bug/story/card in your work database to make it clear what the change was and how you have already tested it (with proof).
The worst case scenario for a code review and QA are the same: your code has a defect that you should have found. You can do work up-front to make sure this doesn’t happen, and that work is short compared to the wasted time that not doing it will cause.
I assume that you will test your code before you submit it. Hopefully you do that through automated unit-tests, which should include edge cases. You should go beyond that and anticipate what QA will check.
Like with code reviews, this extra work takes a couple of hours and potentially saves days of back-and-forth between your testers and you. If you don’t have any ideas of what to test then check with AI chatbots—they are pretty good at this and can even generate the test.
If you can’t automate the test, then you still need to manually test it when you write it, so it’s a good idea to make some record of this work. For example, for UI code, which is hard to unit test, create a document with before and after screenshots (or make a video showing what you changed).
These ideas also help with another source of QA feedback—that they don’t even understand what the issue/story/bug is. The way I head that off is by attaching a “Test Plan” document with a description of how to see the change in the application and what specifically was changed. A video works here too.
When QA finds a problem that I could not have found, then I am relieved. But, when they kick something back because it wasn’t explained well or I made a stupid mistake I could have easily found, I feel guilty that I wasted their time (and mine). I’ve never regretted taking a little time at the end of a task to help it go smoothly through the rest of the process.
Forget about the 10-X programmer. I think we’re in a time where AI coding assistants can make you much better than that.
Even if you think I’m crazy, I don’t think it’s a stretch that some programmers, particularly less experienced ones, will get a big relative boost compared to themselves without AI. Meaning, they could become 10x better using Cursor than they would be if they didn’t use AI at all.
The norm is less for experienced devs. I think I’m getting about a 2x or 3x improvement for my most AI-amenable tasks. But when I have to do things on projects where I don’t know the language ecosystem as well, it’s much more. So, it’s less about overall skill, and more about familiarity. As long as you know enough to write good prompts, you get more of a multiple the less you know. For example, for my main project, I might save an hour on a 4-hour task, but a junior dev might save days on that same task. Even if I finish it faster this time, they are still going to improve on that same kind of task until we’re about the same.
But, I also think it’s possible to get very high objective, absolute multipliers against all unassisted programmers with projects that are not even worth trying without the AI assistance.
I’ve started calling this Infinity-X programming. I’m talking about projects where it would take weeks for a programmer to complete, but no one is sure that it’s worth the time or cost. Using tools like Cursor and Replit, I’ve seen instances where a person with some programming ability (but not enough to program unassisted) do it on the side, working on it for fun just because they want to. They get somewhere fast, and now we might approve more work because we can see the value and it feels tractable. I’ve seen this happen a few times in my network lately.
It’s not just “non-programmers”. I’m also seeing this among my very experienced programmer colleagues. They are trying very ambitious side-projects that would be way too hard to do alone. They wouldn’t have even tried. But, now, with AI, they can make a lot of progress right away, and that progress spurs them on to do even more.
Without AI, these bigger projects would be too much of a slog, with too many yak-shaving expeditions, and lots of boring boilerplate and bookkeeping tasks. But, with AI, you get to stay in the zone and have fun, making steady progress the whole way. It makes very big things feel like small things. This is what it feels like to approach infinity.
When I prepare code for a pull request, I construct it commit-by-commit in a reading order that convinces you that it is correct. So, when I stage code, I ask myself: “Is the code in this commit obviously correct?” If it’s not, then I probably need to add commits before this one that make the code more clear because I only make explanatory comments on a PR as a last resort.
A PR comment becomes code in a few steps. Step one is that I make comments in the code instead of in the PR. This is better because now anyone reading the code will understand it better. A PR comment isn’t tied to the code unless you think to check the logs and follow that back to the PR.
Step two stems from my belief that a random comment explaining a block of code indicates that that code isn’t clear. This is usually something you can fix with a behavior-preserving refactor. Maybe a variable name is unclear or some code should be extracted into a function. The name of that new function should make the intent of the code inside it easier to see.
But, changing this code might break something, so step three is try to cover this area with unit-tests. When I read a commit with unit tests, I know that all of the cases in the tests are checked, so my job is to think of things that aren’t checked.
It’s tempting to want to fix things in code you are reading, but if they aren’t clarifying the work at hand, that might be a waste of time. By concentrating my efforts on making the PR easier to review, the code will be merged faster if I fix the code.
We use cookies for some of the features of this website. You must accept cookies to continue to use this website.