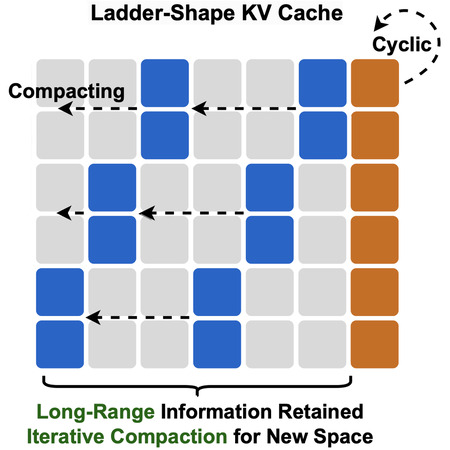
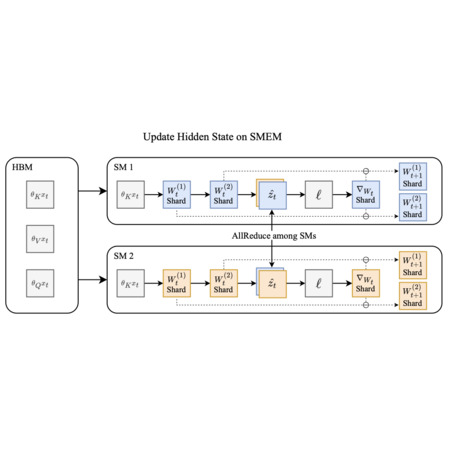
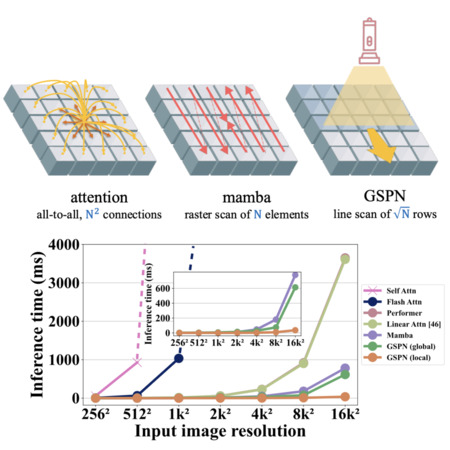
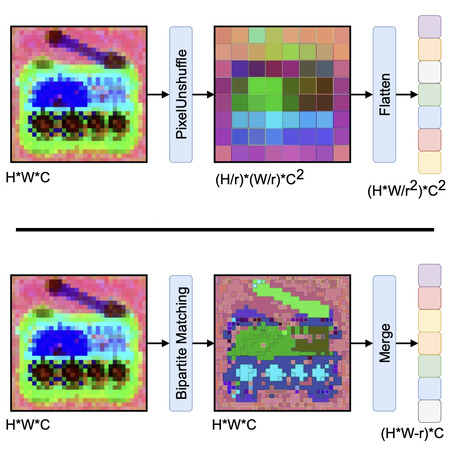
Vice President of Learning and Perception Research @ NVIDIA
I lead the Learning and Perception Research Team at NVIDIA, working predominantly on computer vision problems — from low-level vision (denoising, super-resolution, computational photography) and geometric vision (structure from motion, SLAM, optical flow) to visual perception (detection, recognition, classification), as well as machine learning problems (deep learning, reinforcement learning, generative models).
News
apr
2025
ICLR
We have many papers accepted at ICLR 2025. We hope you can join us!
My team has over 10 papers accepted to CVPR 2023. Come and join us in Vancouver.
may
2023
ICLR
We have 3 papers accepted at ICLR 2023. We hope to see you there!
may
2023
ICRA
My team has 4 papers at ICRA 2023. See you in London!
Research Areas
Efficient AI
We are interested in efficient AI, for both training and inferencing, which includes methods such as pruning, neural architecture search, and so forth.
Visual Perception
Solving perception tasks is an important aspect of our work. In particular, we work on a variety of 2D and 3D perception tasks using deep learning.
Foundation Models
My team is investigating foundation models in the area of computer vision, multi-modal LLMs, as well as embodied AI.
Generative AI
We investigate learning-based methods that can synthesize multi-dimensional data for creative as well as scientific applications.
GR00T Foundation Model
GTC 2025
We released our robotics foundation model, NVIDIA Isaac GR00T N1, at GTC 2025. It is the world's first open foundation model for generalized humanoid robot reasoning and skills. This cross-embodiment model takes multimodal input, including language and images, to perform manipulation tasks in diverse environments. GR00T N1 is trained on an expansive humanoid dataset, consisting of real captured data, synthetic data generated using the components of NVIDIA Isaac GR00T Blueprint, and internet-scale video data. It is adaptable through post-training for specific embodiments, tasks and environments.
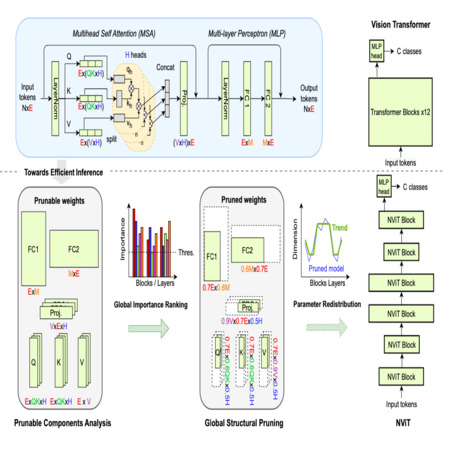
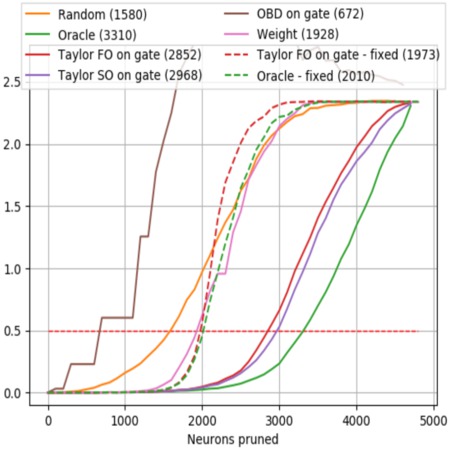
We endeavor to make our computer vision models as efficient as possible. To this end, we have been working on methods for pruning neural networks as well as on methods for architecture search. We have focused on structural pruning of neural network parameters in order to reduce computation, energy, and memory transfer costs during inference. Similarly, we have worked on neural architecture search and distillation methods, for both large vision and large language models.
We have been working on hand and body pose estimation over the past years. Our methods won the HANDS 2015 competition, HANDS 2017 competition (tracking task), as well as the HANDS 2019 competition (task 3). Our methods can handle hands, body pose, body meshes, static and moving cameras, as well as multiple people.
Local Laplacian Filtering
Communications of the ACM 2015, ACM SIGGRAPH 2014
Multi-scale manipulations are central to image editing but they are also prone to halos. Achieving artifact-free results requires sophisticated edge-aware techniques and careful parameter tuning. We address these short comings with the local Laplacian filters, which can achieve a broad range of effects using standard Laplacian pyramids. We show that they are closely related to anisotropic diffusion and to bilateral filtering. Building upon this result, we describe an acceleration scheme for local Laplacian filters on gray-scale images that yields speed-ups on the order of 50×.
Publications
2025
NeurIPS
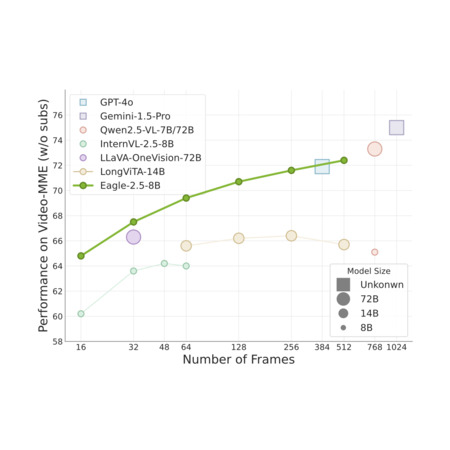
Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
G. Chen, Z. Li, S. Wang, J. Jiang, Y. Liu, L. Lu, D.-A. Huang, W. Byeon, M. Le, T. Rintamaki, T. Poon, M. Ehrlich, T. Lu, L. Wang, B. Catanzaro, J. Kautz, A. Tao, Z. Yu, G. Liu
Advances in Neural Information Processing Systems (NeurIPS)
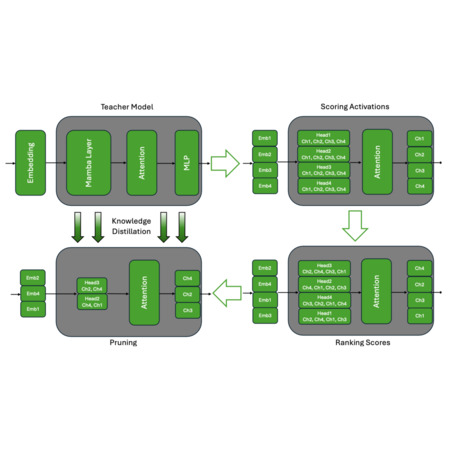
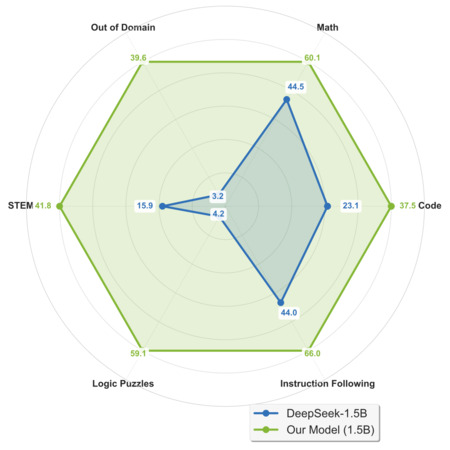
Efficient Hybrid Language Model Compression through Group-Aware SSM Pruning
A. Taghibakhshi, S. T. Sreenivas, S. Muralidharan, M. Chochowski, Y. Karnati, R. B. Joshi, A. S. Mahabaleshwarkar, Z. Chen, Y. Suhara, O. Olabiyi, D. Korzekwa, M. Patwary, M. Shoeybi, J. Kautz, B. Catanzaro
Advances in Neural Information Processing Systems (NeurIPS)
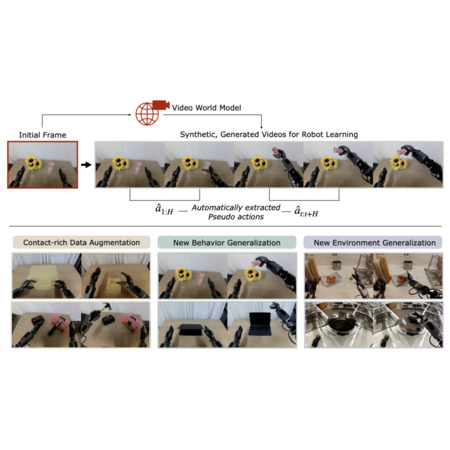
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y. Fang, F. Hu, S. Huang, K. Kundalia, L. Magne, A. Mandlekar, A. Narayan, Y. L. Tan, G. Wang, J. Wang, Q. Wang, Y. Xu, K. Zheng, R. Zheng, L. Zettlemoyer, D. Fox, J. Kautz, S. Reed, Y. Zhu, L. Fan
FLARE: Robot Learning with Implicit World Modeling
R. Zheng, J. Wang, S. Reed, Y. Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, A. Narayan, Y. L. Tan, G. Wang, Q. Wang, J. Xiang, Y. Xu, S. Ye, J. Kautz, F. Huang, Y. Zhu, L. Fan
Wolf: Dense Video Captioning with a World Summarization Framework
B. Li, L. Zhu, R. Tian, S. Tan, Y. Chen, Y. Lu, Y. Cui, S. Veer, M. Ehrlich, J. Philion, X. Weng, F. Xue, L. Fan, Y. Zhu, J. Kautz, A. Tao, M.-Y. Liu, S. Fidler, B. Ivanovic, T. Darrell, J. Malik, S. Han, M. Pavone
Z. Liu, L. Zhu, B. Shi, Z. Zhang, Y. Lou, S. Yang, H. Xi, S. Cao, Y. Gu, D. Li, X. Li, Y. Fang, Y. Chen, C.-Y. Hsieh, D.-A. Huang, A.-C. Cheng, V. Nath, A. Myronenko, J. Hu, S. Liu, R. Krishna, D. Xu, X. Wang, P. Molchanov, J. Kautz, H. Yin, S. Han, a. Y. Lu
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Hymba: A Hybrid-head Architecture for Small Language Models
X. Dong, Y. Fu, S. Diao, W. Byeon, Z. Chen, A. S. Mahabaleshwarkar, S.-Y. Liu, M. V. Keirsbilck, M.-H. Chen, Y. Suhara, Y. C. Lin, J. Kautz, P. Molchanov
International Conference on Learning Representations (ICLR)
Residual corrective diffusion modeling for km-scale atmospheric downscaling
M. Mardani, N. Brenowitz, Y. Cohen, J. Pathak, C.-Y. Chen, C.-C. Liu, A. Vahdat, M. A. Nabian, T. Ge, A. Subramaniam, K. Kashinath, J. Kautz, M. Pritchard
R. Waleffe, W. Byeon, D. Riach, B. Norick, V. Korthikanti, T. Dao, A. Gu, A. Hatamizadeh, S. Singh, D. Narayanan, G. Kulshreshtha, V. Singh, J. Casper, J. Kautz, M. Shoeybi, B. Catanzaro
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
S. Yuan, G. Garcia-Hernando, B. Stenger, G. Moon, J. Y. Chang, K. M. Lee, P. Molchanov, J. Kautz, S. Honari, L. Ge, J. Yuan, X. Chen, G. Wang, F. Yang, K. Akiyama, Y. Wu, Q. Wan, M. Madadi, S. Escalera, S. Li, D. Lee, I. Oikonomidis, A. Argyros, T.-K. Kim
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Binary gradient cameras extract edge and temporal information directly on the sensor, allowing for low-power, low-bandwidth, and high-dynamic-range capabilities — all critical factors for the deployment of embedded computer vision systems. However, these types of images require specialized computer vision algorithms and are not easy to interpret by a human observer. In this paper we propose to recover an intensity image from a single binary spatial gradient image with a deep autoencoder. Extensive experimental results on both simulated and real data show the effectiveness of the proposed approach.
CVPR
Dynamic Facial Analysis: From Bayesian Filtering to Recurrent Neural Network
J. Gu, S. De Mello, X. Yang, J. Kautz
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
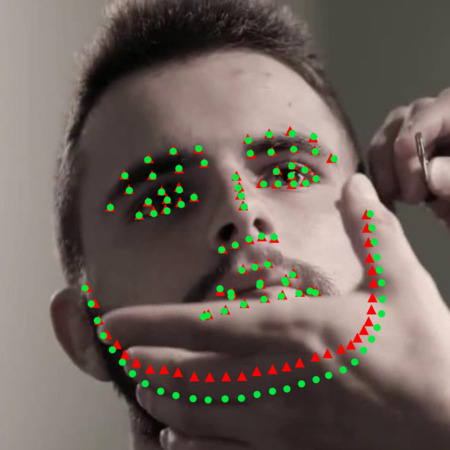
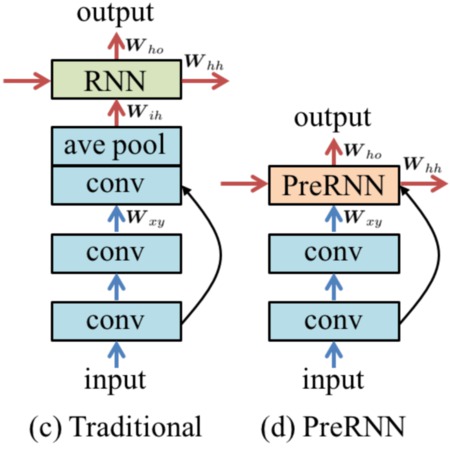
Facial analysis in videos, including head pose estimation and facial landmark localization, is key for many applications such as facial animation capture, human activity recognition, and human-computer interaction. In this paper, we propose to use a recurrent neural network (RNN) for joint estimation and tracking of facial features in videos. We are inspired by the fact that the computation performed in an RNN bears resemblance to Bayesian filters, which have been used for tracking in many previous methods for facial analysis from videos. Bayesian filters used in these methods, however, require complicated, problem-specific design and tuning. In contrast, our proposed RNN-based method avoids such tracker-engineering by learning from training data, similar to how a convolutional neural network (CNN) avoids feature-engineering for image classification. As an end-to-end network, the proposed RNN-based method provides a generic and holistic solution for joint estimation and tracking of various types of facial features from consecutive video frames. Extensive experimental results on head pose estimation and facial landmark localization from videos demonstrate that the proposed RNN-based method outperforms frame-wise models and Bayesian filtering. In addition, we create a large-scale synthetic dataset for head pose estimation, with which we achieve state-of-the-art performance on a benchmark dataset.
CVPR
Polarimetric Multi-View Stereo
Z. Cui, J. Gu, B. Shi, P. Tan, J. Kautz
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Multi-view stereo relies on feature correspondences for 3D reconstruction, and thus is fundamentally flawed in dealing with featureless scenes. In this paper, we propose polarimetric multi-view stereo, which combines per-pixel photometric information from polarization with epipolar constraints from multiple views for 3D reconstruction. Polarization reveals surface normal information, and is thus helpful to propagate depth to featureless regions. Polarimetric multi-view stereo is completely passive and can be applied outdoors in uncontrolled illumination, since the data capture can be done simply with either a polarizer or a polarization camera. Unlike previous work on shape-from-polarization which is limited to either diffuse polarization or specular polarization only, we propose a novel polarization imaging model that can handle real-world objects with mixed polarization. We prove there are exactly two types of ambiguities on estimating surface azimuth angles from polarization, and we resolve them with graph optimization and iso-depth contour tracing. This step significantly improves the initial depth map estimate, which are later fused together for complete 3D reconstruction. Extensive experimental results demonstrate high-quality 3D reconstruction and better performance than state-of-the-art multi-view stereo methods, especially on featureless 3D objects, such as ceramic tiles, office room with white walls, and highly reflective cars in the outdoors.
ICLR
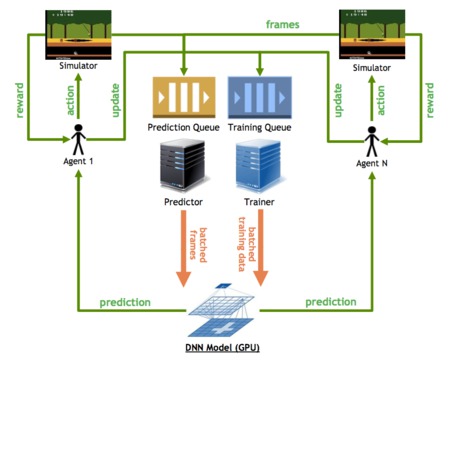
GA3C: GPU-based A3C for Deep Reinforcement Learning
M. Babaeizadeh, I. Frosio, S. Tyree, J. Clemons, J. Kautz
International Conference on Learning Representations
We introduce and analyze the computational aspects of a hybrid CPU/GPU implementation of the Asynchronous Advantage Actor-Critic (A3C) algorithm, currently the state-of-the-art method in reinforcement learning for various gaming tasks. Our analysis concentrates on the critical aspects to leverage the GPU’s computational power, including the introduction of a system of queues and a dynamic scheduling strategy, potentially helpful for other asynchronous algorithms as well. We also show the potential for the use of larger DNN models on a GPU. Our Tensor-Flow implementation achieves a significant speed up compared to our CPU-only implementation, and it will be made publicly available to other researchers.
ICLR
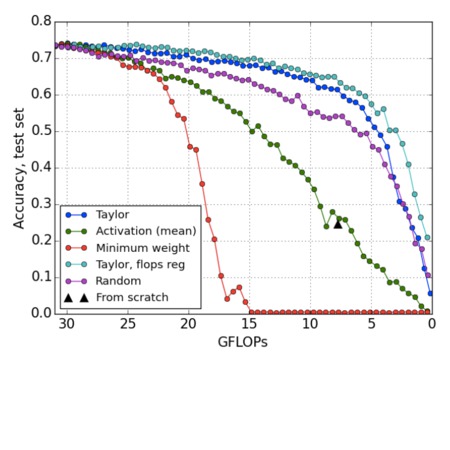
Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning
P. Molchanov, S. Tyree, T. Karras, T. Aila, J. Kautz
International Conference on Learning Representations
We propose a new framework for pruning convolutional kernels in neural networks to enable efficient inference, focusing on transfer learning where large and potentially unwieldy pretrained networks are adapted to specialized tasks. We interleave greedy criteria-based pruning with fine-tuning by backpropagation — a computationally efficient procedure that maintains good generalization in the pruned network. We propose a new criterion based on an efficient first-order Taylor expansion to approximate the absolute change in training cost induced by pruning a network component. After normalization, the proposed criterion scales appropriately across all layers of a deep CNN, eliminating the need for per-layer sensitivity analysis. The proposed criterion demonstrates superior performance compared to other criteria, such as the norm of kernel weights or average feature map activation.
IEEE TCI
Loss Functions for Neural Networks for Image Processing
Neural networks are becoming central in several areas of computer vision and image processing and different architectures have been proposed to solve specific problems. The impact of the loss layer of neural networks, however, has not received much attention in the context of image processing: the default and virtually only choice is L2. In this paper we bring attention to alternative choices. We study the performance of several losses, including perceptually-motivated losses, and propose a novel, differentiable error function. We show that the quality of the results improves significantly with better loss functions, even when the network architecture is left unchanged.
2016
SIGGRAPH ASIA
Computational Bounce Flash for Indoor Portraits
L. Murmann, A. Davis, J. Kautz, F. Durand
ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2016)
Portraits taken with direct flash look harsh and unflattering because the light source comes from a small set of angles very close to the camera. Advanced photographers address this problem by using bounce flash, a technique where the flash is directed towards other surfaces in the room, creating a larger, virtual light source that can be cast from different directions to provide better shading variation for 3D modeling. However, finding the right direction to point a bounce flash requires skill and careful consideration of the available surfaces and subject configuration. Inspired by the impact of automation for exposure, focus and flash metering, we automate control of the flash direction for bounce illumination. We first identify criteria for evaluating flash directions, based on established photography literature, and relate these criteria to the color and geometry of a scene. We augment a camera with servomotors rotate the flash head, and additional sensors (a fisheye and 3D sensors) to gather information about potential bounce surfaces. We present a simple numerical optimization criterion that finds directions for the flash that consistently yield compelling illumination and demonstrate the effectiveness of our various criteria in common photographic configurations.
NIPSW
GA3C: GPU-based A3C for Deep Reinforcement Learning
M. Babaeizadeh, I. Frosio, S. Tyree, J. Clemons, J. Kautz
NIPS Workshop on Efficient Methods for Deep Neural Networks
We introduce and analyze the computational aspects of a hybrid CPU/GPU implementation of the Asynchronous Advantage Actor-Critic (A3C) algorithm, currently the state-of-the-art method in reinforcement learning for various gaming tasks. Our analysis concentrates on the critical aspects to leverage the GPU’s computational power, including the introduction of a system of queues and a dynamic scheduling strategy, potentially helpful for other asynchronous algorithms as well. We also show the potential for the use of larger DNN models on a GPU. Our Tensor-Flow implementation achieves a significant speed up compared to our CPU-only implementation, and it will be made publicly available to other researchers.
NIPSW
Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning
P. Molchanov, S. Tyree, T. Karras, T. Aila, J. Kautz
NIPS Workshop on Efficient Methods for Deep Neural Networks
We propose a new framework for pruning convolutional kernels in neural networks to enable efficient inference, focusing on transfer learning where large and potentially unwieldy pretrained networks are adapted to specialized tasks. We interleave greedy criteria-based pruning with fine-tuning by backpropagation — a computationally efficient procedure that maintains good generalization in the pruned network. We propose a new criterion based on an efficient first-order Taylor expansion to approximate the absolute change in training cost induced by pruning a network component. After normalization, the proposed criterion scales appropriately across all layers of a deep CNN, eliminating the need for per-layer sensitivity analysis. The proposed criterion demonstrates superior performance compared to other criteria, such as the norm of kernel weights or average feature map activation.
ACM MM
Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification
This paper presents a novel framework to combine multiple layers and modalities of deep neural networks for video classification. We first propose a multilayer strategy to simultaneously capture a variety of levels of abstraction and invariance in a network, where the convolutional and fully connected layers are effectively represented by our proposed feature aggregation methods. We further introduce a multimodal scheme that includes four highly complementary modalities to extract diverse static and dynamic cues at multiple temporal scales. In particular, for modeling the long-term temporal information, we propose a new structure, FC-RNN, to effectively transform pre-trained fully connected layers into recurrent layers. A robust boosting model is then introduced to optimize the fusion of multiple layers and modalities in a unified way. In the extensive experiments, we achieve state-of-the-art results on two public benchmark datasets: UCF101 and HMDB51.
CVPR
Accelerated Generative Models for 3D Point Cloud Data
B. Eckart, K. Kim, A. Troccoli, A. Kelly, J. Kautz
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Finding meaningful, structured representations of 3D point cloud data (PCD) has become a core task for spatial perception applications. In this paper we introduce a method for constructing compact generative representations of PCD at multiple levels of detail. As opposed to deterministic structures such as voxel grids or octrees, we propose probabilistic subdivisions of the data through local mixture modeling, and show how these subdivisions can provide a maximum likelihood segmentation of the data. The final representation is hierarchical, compact, parametric, and statistically derived, facilitating run-time occupancy calculations through stochastic sampling. Unlike traditional deterministic spatial subdivision methods, our technique enables dynamic creation of voxel grids according the application's best needs. In contrast to other generative models for PCD, we explicitly enforce sparsity among points and mixtures, a technique which we call expectation sparsification. This leads to a highly parallel hierarchical Expectation Maximization (EM) algorithm well-suited for the GPU and real-time execution. We explore the trade-offs between model fidelity and model size at various levels of detail, our tests showing favorable performance when compared to octree and NDT-based methods.
CVPR
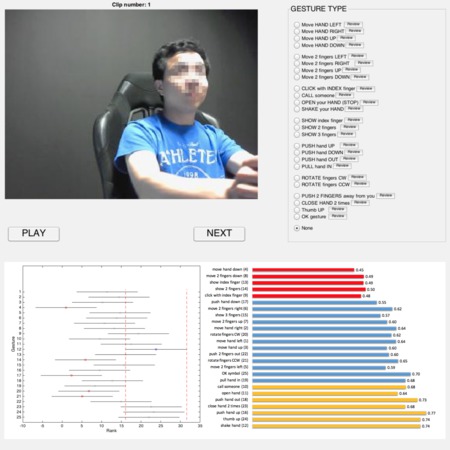
Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks
P. Molchanov, X. Yang, S. Gupta, K. Kim, S. Tyree, J. Kautz
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Automatic detection and classification of dynamic hand gestures in real-world systems intended for human computer interaction is challenging as: 1) there is a large diversity in how people perform gestures, making detection and classification difficult; 2) the system must work online in order to avoid noticeable lag between performing a gesture and its classification; in fact, a negative lag (classification before the gesture is finished) is desirable, as feedback to the user can then be truly instantaneous. In this paper, we address these challenges with a recurrent three-dimensional convolutional neural network that performs simultaneous detection and classification of dynamic hand gestures from multi-modal data. We employ connectionist temporal classification to train the network to predict class labels from in-progress gestures in unsegmented input streams. In order to validate our method, we introduce a new challenging multi-modal dynamic hand gesture dataset captured with depth, color and stereo-IR sensors. On this challenging dataset, our gesture recognition system achieves an accuracy of 83.8%, outperforms competing state-of-the-art algorithms, and approaches human accuracy of 88.4%. Moreover, our method achieves state-of-the-art performance on SKIG and ChaLearn2014 benchmarks.
IEEE IVS
Towards Selecting Robust Hand Gestures for Automotive Interfaces
S. Gupta, P. Molchanov, X. Yang, K. Kim, S. Tyree, J. Kautz
Driver distraction is a serious threat to automotive safety. The visual-manual interfaces in cars are a source of distraction for drivers. Automotive touch-less hand gesture-based user interfaces can help to reduce driver distraction and enhance safety and comfort. The choice of hand gestures in automotive interfaces is central to their success and widespread adoption. In this work we evaluate the recognition accuracy of 25 different gestures for state-of-the-art computer vision-based gesture recognition algorithms and for human observers. We show that some gestures are consistently recognized more accurately than others by both vision-based algorithms and humans. We further identify similarities in the hand gesture recognition abilities of vision-based systems and humans. Lastly, by merging pairs of gestures with high miss-classification rates, we propose ten robust hand gestures for automotive interfaces, which are classified with high and equal accuracy by vision-based algorithms.
2015
ICCV
Robust Model-based 3D Head Pose Estimation
G. P. Meyer, S. Gupta, I. Frosio, D. Reddy, J. Kautz
IEEE International Conference on Computer Vision (ICCV)
We introduce a method for accurate three dimensional head pose estimation using a commodity depth camera. We perform pose estimation by registering a morphable face model to the measured depth data, using a combination of particle swarm optimization (PSO) and the iterative closest point (ICP) algorithm, which minimizes a cost function that includes a 3D registration and a 2D overlap term. The pose is estimated on the fly without requiring an explicit initialization or training phase. Our method handles large pose angles and partial occlusions by dynamically adapting to the reliable visible parts of the face. It is robust and generalizes to different depth sensors without modification. On the Biwi Kinect dataset, we achieve best-in-class performance, with average angular errors of 2.1, 2.1 and 2.4 degrees for yaw, pitch, and roll, respectively, and an average translational error of 5.9 mm, while running at 6 fps on a graphics processing unit.
CGF
Interactive Sketch-Driven Image Synthesis
D. Turmukhambetov, N. Campbell, D. Goldman, J. Kautz
We present an interactive system for composing realistic images of an object under arbitrary pose and appearance specified by sketching. Our system draws inspiration from a traditional illustration workflow: The user first sketches rough ‘masses’ of the object, as ellipses, to define an initial abstract pose that can then be refined with more detailed contours as desired. The system is made robust to partial or inaccurate sketches using a reduced-dimensionality model of pose space learnt from a labelled collection of photos. Throughout the composition process, interactive visual feedback is provided to guide the user. Finally, the user's partial or complete sketch, complemented with appearance requirements, is used to constrain the automatic synthesis of a novel, high-quality, realistic image.
UIST
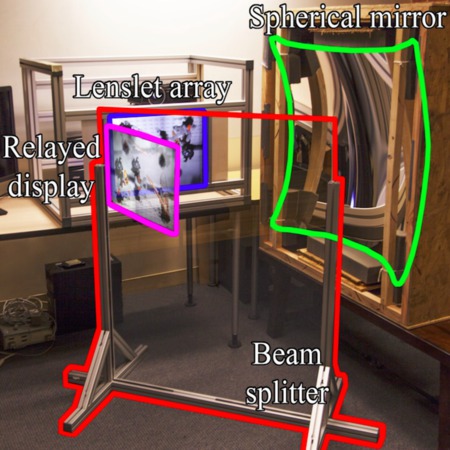
Joint 5D Pen Input for Light Field Displays
J. Tompkin, S. Muff, J. McCann, H. Pfister, J. Kautz, M. Alexa, W. Matusik
Light field displays allow viewers to see view-dependent 3D content as if looking through a window; however, existing work on light field display interaction is limited. Yet, they have the potential to parallel 2D pen and touch screen systems which present a joint input and display surface for natural interaction. We propose a 4D display and interaction space using a dual-purpose lenslet array, which combines light field display and light field pen sensing, and allows us to estimate the 3D position and 2D orientation of the pen. This method is simple and fast (150 Hz), with position accuracy of 2–3 mm and precision of 0.2–0.6 mm from 0–350 mm away from the lenslet array, and orientation accuracy of 2° and precision of 0.2–0.3° within 50°. Further, we 3D print the lenslet array with embedded baffles to reduce out-of-bounds cross-talk, and use an optical relay to allow interaction behind the focal plane. We demonstrate our joint display/sensing system with interactive light field painting.
3DV
MLMD: Maximum Likelihood Mixture Decoupling for Fast and Accurate Point Cloud Registration
B. Eckart, K. Kim, A. Troccoli, A. Kelly, J. Kautz
Registration of Point Cloud Data (PCD) forms a core component of many 3D vision algorithms such as object matching and environment reconstruction. In this paper, we introduce a PCD registration algorithm that utilizes Gaussian Mixture Models (GMM) and a novel dual-mode parameter optimization technique which we call mixture decoupling. We show how this decoupling technique facilitates both faster and more robust registration by first optimizing over the mixture parameters (decoupling the mixture weights, means, and covariances from the points) before optimizing over the 6DOF registration parameters. Furthermore, we frame both the decoupling and registration process inside a unified, dual-mode Expectation Maximization (EM) framework, for which we derive a Maximum Likelihood Estimation (MLE) solution along with a parallel implementation on the GPU. We evaluate our MLE-based mixture decoupling (MLMD) registration method over both synthetic and real data, showing better convergence for a wider range of initial conditions and higher speeds than previous state of the art methods.
HPG
An Adaptive Acceleration Structure for Screen-space Ray Tracing
S. Widmer, D. Pajak, A. Schulz, K. Pulli, J. Kautz, M. Goesele, D. Luebke
We propose an efficient acceleration structure for real-time screen- space ray tracing. The hybrid data structure represents the scene geometry by combining a bounding volume hierarchy with local planar approximations. This enables fast empty space skipping while tracing and yields exact intersection points for the planar approximation. In combination with an occlusion-aware ray traversal our algorithm is capable to quickly trace even multiple depth layers. Compared to prior work, our technique improves the accuracy of the results, is more general, and allows for advanced image trans- formations, as all pixels can cast rays to arbitrary directions. We demonstrate real-time performance for several applications, including depth-of-field rendering, stereo warping, and screen-space ray traced reflections.
EGSR
Filtering Environment Illumination for Interactive Physically-Based Rendering in Mixed Reality
S. Mehta, K. Kim, D. Pajak, K. Pulli, J. Kautz, R. Ramamoorthi
Physically correct rendering of environment illumination has been a long-standing challenge in interactive graphics, since Monte-Carlo ray-tracing requires thousands of rays per pixel. We propose accurate filtering of a noisy Monte-Carlo image using Fourier analysis. Our novel analysis extends previous works by showing that the shape of illumination spectra is not always a line or wedge, as in previous approximations, but rather an ellipsoid. Our primary contribution is an axis-aligned filtering scheme that preserves the frequency content of the illumination. We also propose a novel application of our technique to mixed reality scenes, in which virtual objects are inserted into a real video stream so as to become indistinguishable from the real objects. The virtual objects must be shaded with the real lighting conditions, and the mutual illumination between real and virtual objects must also be determined. For this, we demonstrate a novel two-mode path tracing approach that allows ray-tracing a scene with image-based real geometry and mesh-based virtual geometry. Finally, we are able to de-noise a sparsely sampled image and render physically correct mixed reality scenes at over 5 fps on the GPU.
CVPR
Modeling Object Appearance using Context-Conditioned Component Analysis
D. Turmukhambetov, N. Campbell, S. Prince, J. Kautz
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Subspace models have been very successful at modeling the appearance of structured image datasets when the visual objects have been aligned in the images, for example faces. Even with extensions that allow for global transformations or dense warps of the image, the set of visual objects whose appearance may be modeled by such methods is limited. They are unable to account for visual objects where occlusion leads to changing visibility of different parts of the object (without a strict layered structure) and where a one-to-one mapping between parts is not preserved, for example bunches of bananas contain different numbers of bananas but each individual banana shares an appearance subspace. In this work we remove the image space alignment limitations of existing subspace models by conditioning the models on a shape dependent context that allows for complex, non-linear structure within the appearance of the visual object to be captured and shared. This allows us to exploit the advantages of subspace appearance models with non-rigid, deformable objects whilst also dealing with complex occlusions and varying numbers of parts. We demonstrate the effectiveness of our new model with examples of structured in-painting and appearance transfer.
CVPRW
Hand Gesture Recognition with 3D Convolutional Neural Networks
P. Molchanov, S. Gupta, K. Kim, J. Kautz
IEEE CVPR Workshop on Observing and Understanding Hands in Action
Touchless hand gesture recognition systems are becoming important in automotive user interfaces as they improve safety and comfort. Various computer vision algorithms have employed color and depth cameras for hand gesture recognition, but robust classification of gestures from different subjects performed under widely varying lighting conditions is still challenging. We propose an algorithm for drivers’ hand gesture recognition from challenging depth and intensity data using 3D convolutional neural networks. Our solution combines information from multiple spatial scales for the final prediction. It also employs spatio-temporal data augmentation for more effective training and to reduce potential overfitting. Our method achieves a correct classification rate of 77.5% on the VIVA challenge dataset.
CVPRW
Locally Non-rigid Registration for Mobile HDR Photography
Image registration for stack-based HDR photography is challenging. If not properly accounted for, camera motion and scene changes result in artifacts in the composite image. Unfortunately, existing methods to address this problem are either accurate, but too slow for mobile devices, or fast, but prone to failing. We propose a method that fills this void: our approach is extremely fast—under 700ms on a commercial tablet for a pair of 5MP images—and prevents the artifacts that arise from insufficient registration quality.
APP. OPTICS
Slim Near Eye Display Using Pinhole Aperture Arrays
We report a new technique for building a wide-angle, lightweight, thin form factor, cost effective, easy to manufacture near-eye Head-Mounted Display (HMD) for virtual reality applications. Our approach adopts an aperture mask containing an array of pinholes and a screen as a source of imagery. We demonstrate a proof-of-concept HMD prototype with a binocular field of view (FOV) of 70° × 45°, or total diagonal FOV of 83°. This FOV should increase with the increasing display panel size. The optical angular resolution supported in our prototype can go down to 1.4 - 2.1 arcmin by adopting a display with 20 - 30 µm pixel pitch.
CACM
Local Laplacian Filters: Edge-aware Image Processing with a Laplacian Pyramid
The Laplacian pyramid is ubiquitous for decomposing images into multiple scales and is widely used for image analysis. However, because it is constructed with spatially invariant Gaussian kernels, the Laplacian pyramid is widely believed as being unable to represent edges well and as being ill-suited for edge-aware operations such as edge-preserving smoothing and tone mapping. To tackle these tasks, a wealth of alternative techniques and representations have been proposed, e.g., anisotropic diffusion, neighborhood filtering, and specialized wavelet bases. While these methods have demonstrated successful results, they come at the price of additional complexity, often accompanied by higher computational cost or the need to post-process the generated results. In this paper, we show state-of-the-art edge-aware processing using standard Laplacian pyramids. We characterize edges with a simple threshold on pixel values that allows us to differentiate large-scale edges from small-scale details. Building upon this result, we propose a set of image filters to achieve edge-preserving smoothing, detail enhancement, tone mapping, and inverse tone mapping. The advantage of our approach is its simplicity and flexibility, relying only on simple point-wise nonlinearities and small Gaussian convolutions; no optimization or post-processing is required. As we demonstrate, our method produces consistently high-quality results, without degrading edges or introducing halos.
ACM MM
Speaker-Following Video Subtitles
Y. Hu, J. Kautz, Y. Yu, and W. Wang
ACM Transactions on Multimedia Computing, Communications, and Applications
We propose a new method for improving the presentation of subtitles in video (e.g., TV and movies). With conventional subtitles, the viewer has to constantly look away from the main viewing area to read the subtitles at the bottom of the screen, which disrupts the viewing experience and causes unnecessary eyestrain. Our method places on-screen subtitles next to the respective speakers to allow the viewer to follow the visual content while simultaneously reading the subtitles. We use novel identification algorithms to detect the speakers based on audio and visual information. Then the placement of the subtitles is determined using global optimization. A comprehensive usability study indicated that our subtitle placement method outperformed both conventional fixed-position subtitling and another previous dynamic subtitling method in terms of enhancing the overall viewing experience and reducing eyestrain.
2014
SIGGRAPH ASIA
FlexISP: A Flexible Camera Image Processing Framework
F. Heide, M. Steinberger, Y.-T. Tsai, N. Rouf, D. Pajak, D. Reddy, O. Gallo, J. Liu, W. Heidrich, K. Egiazarian, J. Kautz, K. Pulli
ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2014)
Conventional pipelines for capturing, displaying, and storing images are usually defined as a series of cascaded modules, each responsible for addressing a particular problem. While this divide-and-conquer approach offers many benefits, it also introduces a cumulative error, as each step in the pipeline only considers the output of the previous step, not the original sensor data. We propose an end-to-end system that is aware of the camera and image model, enforces natural-image priors, while jointly accounting for common image processing steps like demosaicking, denoising, deconvolution, and so forth, all directly in a given output representation (e.g., YUV, DCT). Our system is flexible and we demonstrate it on regular Bayer images as well as images from custom sensors. In all cases, we achieve large improvements in image quality and signal reconstruction compared to state-of-the-art techniques. Finally, we show that our approach is capable of very efficiently handling high-resolution images, making even mobile implementations feasible.
CVMP
Device Effect on Panoramic Video+Context Tasks
F. Pece, J. Tompkin, H. Pfister, J. Kautz, C. Theobalt,
Panoramic imagery is viewed daily by thousands of people, and panoramic video imagery is becoming more common. This imagery is viewed on many different devices with different properties, and the effect of these differences on spatio-temporal task performance is yet untested on these imagery. We adapt a novel panoramic video interface and conduct a user study to discover whether display type affects spatio-temporal reasoning task performance across desktop monitor, tablet, and head-mounted displays. We discover that, in our complex reasoning task, HMDs are as effective as desktop displays even if participants felt less capable, but tablets were less effective than desktop displays even though participants felt just as capable. Our results impact virtual tourism, telepresence, and surveillance applications, and so we state the design implications of our results for panoramic imagery systems.
ACCVW
User Directed Multi-View-Stereo
Y. Doron, N. Campbell, J. Starck, J. Kautz
Workshop on User-Centred Computer Vision (at ACCV)
Depth reconstruction from video footage and image collections is a fundamental part of many modelling and image-based rendering applications. However real-world scenes often contain limited texture information, repeated elements and other ambiguities which remain challenging for fully automatic algorithms. This paper presents a technique that combines intuitive user constraints with dense multi-view stereo reconstruction. By providing annotations in the form of simple paint strokes, a user can guide a multi-view stereo algorithm and avoid common failure cases. We show how smoothness, discontinuity and depth ordering constraints can be incorporated directly into a variational optimization framework for multi-view stereo. Our method avoids the need for heuristic approaches that edit a depth-map in a sequential process, and avoids requiring the user to accurately segment object boundaries or to directly model geometry. We show how with a small amount of intuitive input, a user may create improved depth maps in challenging cases for multi-view-stereo.
IJCV
PMBP: PatchMatch Belief Propagation for Correspondence Field Estimation
PatchMatch (PM) is a simple, yet very powerful and successful method for optimizing continuous labelling problems. The algorithm has two main ingredients: the update of the solution space by sampling and the use of the spatial neighbourhood to propagate samples. We show how these ingredients are related to steps in a specific form of belief propagation (BP) in the continuous space, called max-product particle BP (MP-PBP). However, MP-PBP has thus far been too slow to allow complex state spaces. In the case where all nodes share a common state space and the smoothness prior favours equal values, we show that unifying the two approaches yields a new algorithm, PMBP, which is more accurate than PM and orders of magnitude faster than MP-PBP. To illustrate the benefits of our PMBP method we have built a new stereo matching algorithm with unary terms which are borrowed from the recent PM Stereo work and novel realistic pairwise terms that provide smoothness. We have experimentally verified that our method is an improvement over state-of-the-art techniques at sub-pixel accuracy level.
ECCV
Highly Overparameterized Optical Flow Using PatchMatch Belief Propagation
M. Hornacek, F. Besse, J. Kautz, A. Fitzgibbon, C. Rother
European Conference on Computer Vision (ECCV) 2014
Motion in the image plane is ultimately a function of 3D motion in space. We propose to compute optical flow using what is ostensibly an extreme overparameterization: depth, surface normal, and frame-to-frame 3D rigid body motion at every pixel, giving a total of 9 DoF. The advantages of such an overparameterization are twofold: first, geometrically meaningful reasoning can be called upon in the optimization, reflecting possible 3D motion in the underlying scene; second, the 'fronto-parallel' assumption implicit in the use of traditional matching pixel windows is ameliorated because the parameterization determines a plane-induced homography at every pixel. We show that optimization over this high-dimensional, continuous state space can be carried out using an adaptation of the recently introduced PatchMatch Belief Propagation (PMBP) energy minimization algorithm, and that the resulting flow fields compare favorably to the state of the art on a number of small- and large-displacement datasets.
SIGGRAPH
Fast Local Laplacian Filters: Theory and Applications
M. Aubry, S. Paris, S. Hasinoff, J. Kautz, F. Durand
ACM Transactions on Graphics (Presented at SIGGRAPH 2014)
Multi-scale manipulations are central to image editing but they are also prone to halos. Achieving artifact-free results requires sophisticated edge- aware techniques and careful parameter tuning. These shortcomings were recently addressed by the local Laplacian filters, which can achieve a broad range of effects using standard Laplacian pyramids. However, these filters are slow to evaluate and their relationship to other approaches is unclear. In this paper, we show that they are closely related to anisotropic diffusion and to bilateral filtering. Our study also leads to a variant of the bilateral filter that produces cleaner edges while retaining its speed. Building upon this result, we describe an acceleration scheme for local Laplacian filters on gray-scale images that yields speed-ups on the order of 50x. Finally, we demonstrate how to use local Laplacian filters to alter the distribution of gradients in an image. We illustrate this property with a robust algorithm for photographic style transfer.
SIGGRAPH
Learning a Manifold of Fonts
N. Campbell, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH 2014)
The design and manipulation of typefaces and fonts is an area requiring substantial expertise; it can take many years of study to become a proficient typographer. At the same time, the use of typefaces is ubiquitous; there are many users who, while not experts, would like to be more involved in tweaking or changing existing fonts without suffering the learning curve of professional typography packages. Given the wealth of fonts that are available today, we would like to exploit the expertise used to produce these fonts, and to enable everyday users to create, explore, and edit fonts. To this end, we build a generative manifold of standard fonts. Every location on the manifold corresponds to a unique and novel typeface, and is obtained by learning a non-linear mapping that intelligently interpolates and extrapolates existing fonts. Using the manifold, we can smoothly interpolate and move between existing fonts. We can also use the manifold as a constraint that makes a variety of new applications possible. For instance, when editing a single character, we can update all the other glyphs in a font simultaneously to keep them compatible with our changes.
SIGGRAPH
Cascaded Displays: Spatiotemporal Superresolution using Offset Pixel Layers
F. Heide, D. Lanman, D. Reddy, J. Kautz, K. Pulli, D. Luebke
ACM Transactions on Graphics (Proceedings SIGGRAPH 2014)
We demonstrate that layered spatial light modulators (SLMs), subject to fixed lateral displacements and refreshed at staggered intervals, can synthesize images with greater spatiotemporal resolution than that afforded by any single SLM used in their construction. Dubbed cascaded displays, such architectures enable superresolution flat panel displays (e.g., using thin stacks of liquid crystal displays (LCDs)) and digital projectors (e.g., relaying the image of one SLM onto another). We introduce a comprehensive optimization framework, leveraging non-negative matrix and tensor factorization, that decomposes target images and videos into multi-layered, time-multiplexed attenuation patterns—offering a flexible trade-off between apparent image brightness, spatial resolution, and refresh rate. Through this analysis, we develop a real-time dual-layer factorization method that quadruples spatial resolution and doubles refresh rate. Compared to prior superresolution displays, cascaded displays place fewer restrictions on the hardware, offering thin designs without moving parts or the necessity of temporal multiplexing. Furthermore, cascaded displays are the first use of multi-layer displays to increase apparent temporal resolution. We validate these concepts using two custom-built prototypes: a dual-layer LCD and a dual-modulation liquid crystal on silicon (LCoS) projector, with the former emphasizing head-mounted display (HMD) applications.
EGSR
Error Analysis of Estimators that Use Combinations of Stochastic Sampling Strategies for Direct Illumination
K. Subr, D. Nowrouzezahrai, W. Jarosz, J. Kautz, K. Mitchell
We present a theoretical analysis of error of combinations of Monte Carlo estimators used in image synthesis. Importance sampling and multiple importance sampling are popular variance-reduction strategies. Unfortunately, neither strategy improves the rate of convergence of Monte Carlo integration. Jittered sampling (a type of stratified sampling), on the other hand is known to improve the convergence rate. Most rendering software optimistically combine importance sampling with jittered sampling, hoping to achieve both. We derive the exact error of the combination of multiple importance sampling with jittered sampling. In addition, we demonstrate a further benefit of introducing negative correlations (antithetic sampling) between estimates to the convergence rate. As with importance sampling, antithetic sampling is known to reduce error for certain classes of integrands without affecting the convergence rate. In this paper, our analysis and experiments reveal that importance and antithetic sampling, if used judiciously and in conjunction with jittered sampling, may improve convergence rates. We show the impact of such combinations of strategies on the convergence rate of estimators for direct illumination.
CVPR
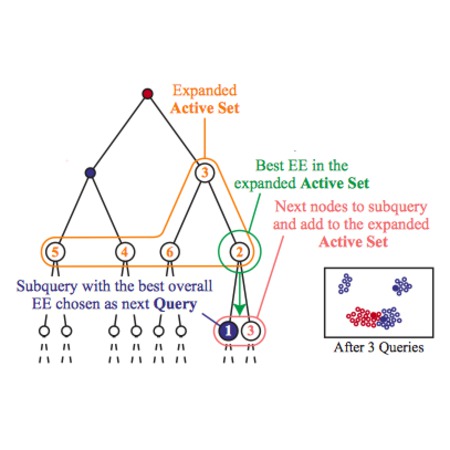
Hierarchical Subquery Evaluation for Active Learning on a Graph
O. Mac Aodha, N. Campbell, J. Kautz, G. Brostow,
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
To train good supervised and semi-supervised object classifiers, it is critical that we not waste the time of the human experts who are providing the training labels. Existing active learning strategies can have uneven performance, being efficient on some datasets but wasteful on others, or inconsistent just between runs on the same dataset. We propose perplexity based graph construction and a new hierarchical subquery evaluation algorithm to combat this variability, and to release the potential of Expected Error Reduction. Under some specific circumstances, Expected Error Reduction has been one of the strongest-performing informativeness criteria for active learning. Until now, it has also been prohibitively costly to compute for sizeable datasets. We demonstrate our highly practical algorithm, comparing it to other active learning measures on classification datasets that vary in sparsity, dimensionality, and size. Our algorithm is consistent over multiple runs and achieves high accuracy, while querying the human expert for labels at a frequency that matches their desired time budget.
CGF
Low-Cost Subpixel Rendering for Diverse Displays
T. Engelhardt, T.-W. Schmidt, J. Kautz, C. Dachsbacher
Subpixel rendering increases the apparent display resolution by taking into account the subpixel structure of a given display. In essence, each subpixel is addressed individually, allowing the underlying signal to be sampled more densely. Unfortunately, naïve subpixel sampling introduces color aliasing, as each subpixel only displays a specific color (usually R, G, and B subpixels are used). As previous work has shown, chromatic aliasing can be reduced significantly by taking the sensitivity of the human visual system into account. In this work, we find optimal filters for subpixel rendering for a diverse set of 1D and 2D subpixel layout patterns. We demonstrate that these optimal filters can be approximated well with analytical functions. We incorporate our filters into GPU-based multisample antialiasing to yield subpixel rendering at a very low cost (1-2ms filtering time at HD resolution). We also show that texture filtering can be adapted to perform efficient subpixel rendering. Finally, we analyze the findings of a user study we performed, which underpins the increased visual fidelity that can be achieved for diverse display layouts, by using our optimal filters.
2013
JVRB
Bitmap Movement Detection: HDR for Dynamic Scenes
F. Pece, J. Kautz
Journal of Virtual Reality and Broadcasting
10(2), December 2013, pages 1-13 (extended CVMP 2010 paper)
Exposure Fusion and other HDR techniques generate well-exposed images from a bracketed image sequence while reproducing a large dynamic range that far exceeds the dynamic range of a single exposure. Common to all these techniques is the problem that the smallest movements in the captured images generate artefacts (ghosting) that dramatically affect the quality of the final images. This limits the use of HDR and Exposure Fusion techniques because common scenes of interest are usually dynamic. We present a method that adapts Exposure Fusion, as well as standard HDR techniques, to allow for dynamic scene without introducing artefacts. Our method detects clusters of moving pixels within a bracketed exposure sequence with simple binary operations. We show that the proposed technique is able to deal with a large amount of movement in the scene and different movement configurations. The result is a ghost-free and highly detailed exposure fused image at a low computational cost.
CG&A
3D-Printing Spatially Varying BRDFs
O. Roullier, B. Bickel, J. Kautz, W. Matusik, M. Alexa
A new method fabricates custom surface reflectance and spatially varying bidirectional reflectance distribution functions (svBRDFs). Researchers optimize a microgeometry for a range of normal distribution functions and simulate the resulting surface's effective reflectance. Using the simulation's results, they reproduce an input svBRDF's appearance by distributing the microgeometry on the printed material's surface. This method lets people print svBRDFs on planar samples with current 3D printing technology, even with a limited set of printing materials. It extends naturally to printing svBRDFs on arbitrary shapes.
SIGGRAPH ASIA
The Shading Probe: Fast Appearance Acquisition for Mobile AR
D. A. Calian, K. Mitchell, D. Nowrouzezahrai, J. Kautz
The ubiquity of mobile devices with powerful processors and integrated video cameras is re-opening the discussion on practical augmented reality (AR). Despite this technological convergence, several issues prevent reliable and immersive AR on these platforms. We address one such problem, the shading of virtual objects and determination of lighting that remains consistent with the surrounding environment. We design a novel light probe and exploit its structure to permit an efficient reformulation of the rendering equation that is suitable for fast shading on mobile devices. Unlike prior approaches, our shading probe directly captures the shading, and not the incident light, in a scene. As such, we avoid costly and unreliable radiometric calibration as well as side-stepping the need for complex shading algorithms. Moreover, we can tailor the shading probe’s structure to better handle common lighting scenarios, such as outdoor settings. We achieve high-performance shading of virtual objects in an AR context, incorporating plausible local globalillumination effects, on mobile platforms.
UIST
Video Collections in Panoramic Contexts
J. Tompkin, F. Pece, R. Shah, S. Izadi, J. Kautz, C. Theobalt
ACM Symposium on User Interface Software and Technology (UIST) 2013
Video collections of places show contrasts and changes in our world, but current interfaces to video collections make it hard for users to explore these changes. Recent state-of-the-art interfaces attempt to solve this problem for 'outside➞in' collections, but cannot connect 'inside➞out' collections of the same place which do not visually overlap. We extend the focus+context paradigm to create a video-collections+context interface by embedding videos into a panorama. We build a spatio-temporal index and tools for fast exploration of the space and time of the video collection. We demonstrate the flexibility of our representation with interfaces for desktop and mobile flat displays, and for a spherical display with joypad and tablet controllers. We study with users the effect of our video-collection+context system to spatio-temporal localization tasks, and find significant improvements to accuracy and completion time in visual search tasks compared to existing systems. We measure the usability of our interface with System Usability Scale (SUS) and task-specific questionnaires, and find our system scores higher.
Traditionally, computer graphics has been concerned with producing imagery that is as physically accurate as possible. But accurate physical simulation of geometry, lighting, and material properties of a visual scene can be cumbersome and time consuming. At the same time, human vision is far from accurate, which offers an enormous opportunity to create imagery at a reduced computational cost as well as with less reliance on human modelers. As a result, a recent trend is toward accepting perceptual plausibility instead of physical accuracy as a guiding principle in the design of modeling and rendering systems. This requires us to understand visual realism, which involves both learning statistical regularities of the world, for instance, by employing huge amounts of data, as well as human's visual perception of it. This paper addresses issues related to understanding realism, presents several applications, and discusses what this interesting approach may lead to in the future.
ACM TAP
Preference and Artifact Analysis for Video Collections of Places
J. Tompkin, M. H. Kim, K. I. Kim, J. Kautz, C. Theobalt
ACM Transactions on Applied Perception (Presented at ACM SAP)
Emerging interfaces for video collections of places attempt to link similar content with seamless transitions. However, the automatic computer vision techniques that enable these transitions have many failure cases which lead to artifacts in the final rendered transition. Under these conditions, which transitions are preferred by participants and which artifacts are most objectionable? We perform an experiment with participants comparing seven transition types, from movie cuts and dissolves to image-based warps and virtual camera transitions, across five scenes in a city. This document describes how we condition this experiment on slight and considerable view change cases, and how we analyze the feedback from participants to find their preference for transition types and artifacts. We discover that transition preference varies with view change, that automatic rendered transitions are significantly preferred even with some artifacts, and that dissolve transitions are comparable to less-sophisticated rendered transitions. This leads to insights into what visual features are important to maintain in a rendered transition, and to an artifact ordering within our transitions.
SIGGRAPH
Fourier Analysis of Stochastic Sampling Strategies for Assessing Bias and Variance in Integration
K. Subr, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH 2013)
Each pixel in a photorealistic, computer generated picture is calculated by approximately integrating all the light arriving at the pixel, from the virtual scene. A common strategy to calculate these high-dimensional integrals is to average the estimates at stochastically sampled locations. The strategy with which the sampled locations are chosen is of utmost importance in deciding the quality of the approximation, and hence rendered image. We derive connections between the spectral properties of stochastic sampling patterns and the first and second order statistics of estimates of integration using the samples. Our equations provide insight into the assessment of stochastic sampling strategies for integration. We show that the amplitude of the expected Fourier spectrum of sampling patterns is a useful indicator of the bias when used in numerical integration. We deduce that estimator variance is directly dependent on the variance of the sampling spectrum over multiple realizations of the sampling pattern. We then analyse Gaussian jittered sampling, a simple variant of jittered sampling, that allows a smooth trade-off of bias for variance in uniform (regular grid) sampling. We verify our predictions using spectral measurement, quantitative integration experiments and qualitative comparisons of rendered images.
SIGGRAPH
Content-adaptive Lenticular Prints
J. Tompkin, S. Heinzle, J. Kautz, W. Matusik
ACM Transactions on Graphics (Proceedings SIGGRAPH 2013)
Lenticular prints are a popular medium for producing automultiscopic glasses-free 3D images. Traditionally, the light field emitted by such prints has a fixed spatial and angular resolution, a trade-off which is defined by the width of the individual lenslets as well as the number of pixels underneath each of those lenslets. We increase both perceived angular and spatial resolution by modifying the lenslet array to better match the content of a given light field. Our optimization algorithm analyzes the input light field and computes an optimal lenslet size, shape, and arrangement that best matches the input light field given a set of output parameters. The resulting lenticular print shows higher detail and smoother motion parallax compared to fixed-size lens arrays. We demonstrate our technique using rendered simulations and by 3D printing lens arrays, and we validate our approach in simulation with a user study.
CVPR
Fully-Connected CRFs with Non-Parametric Pairwise Potentials
N. Campbell, K. Subr, J. Kautz
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2013
Conditional Random Fields (CRFs) are used for diverse tasks, ranging from image denoising to object recognition. For images, they are commonly defined as a graph with nodes corresponding to individual pixels and pairwise links that connect nodes to their immediate neighbors. Recent work has shown that fully-connected CRFs, where each node is connected to every other node, can be solved efficiently under the restriction that the pairwise term is a Gaussian kernel over a Euclidean feature space. In this paper, we generalize the pairwise terms to a non-linear dissimilarity measure that is not required to be a distance metric. To this end, we use an efficient embedding technique to estimate an approximate Euclidean feature space, in which the pairwise term can still be expressed as a Gaussian kernel. We demonstrate that the use of non-parametric models for the pairwise interactions, conditioned on the input data, greatly increases expressive power whilst maintaining efficient inference.
EUROGRAPHICS
Accurate Binary Image Selection from Inaccurate User Input
K. Subr, S. Paris, C. Soler, J. Kautz
Computer Graphics Forum (Proceedings Eurographics 2013)
Selections are central to image editing, e.g., they are the starting point of common operations such as copy-pasting and local edits. Creating them by hand is particularly tedious and scribble-based techniques have been introduced to assist the process. By interpolating a few strokes specified by users, these methods generate precise selections. However, most of the algorithms assume a 100% accurate input, and even small inaccuracies in the scribbles often degrade the selection quality, which imposes an additional burden on users. In this paper, we propose a selection technique tolerant to input inaccuracies. We use a dense conditional random field (CRF) to robustly infer a selection from possibly inaccurate input. Further, we show that patch-based pixel similarity functions yield more precise selection than simple point-wise metrics. However, efficiently solving a dense CRF is only possible in low-dimensional Euclidean spaces, and the metrics that we use are high-dimensional and often non-Euclidean. We address this challenge by embedding pixels in a low-dimensional Euclidean space with a metric that approximates the desired similarity function. The results show that our approach performs better than previous techniques and that two options are sufficient to cover a variety of images depending on whether the objects are textured.
CHI
PanoInserts: Practical Spatial Teleconferencing
F. Pece, W. Steptoe, F. Wanner, S. Julier, T. Weyrich, J. Kautz, A. Steed
ACM Conference on Human Factors in Computing Systems (CHI) 2013
April 2013, pages 1319-1328 (Best Paper Honorable Mention Award)
We present PanoInserts: a teleconferencing system that uses smartphone cameras to create a surround plus video representation of meeting places. We take a static panoramic image of a location and insert live video windows from smart- phones. We use a combination of marker- and image-based tracking to position the video inserts within the panorama, and transmit this representation to a remote viewer. We re- port findings from a user study comparing our system against fully panoramic video and conventional webcam video conferencing for two tasks: 1) determining where objects are positioned at a remote location, and 2) instructing a confederate to place objects in the remote location. Results indicate that our system performs comparably to full panoramic video systems and significantly better than standard video conferencing in tasks that require accurate surround representation of a remote space. We discuss the representational properties and usability of the system for video communication applications.
We propose an approach to interactively explore video textures from different viewpoints. Scenes can be played back continuously and in a temporally coherent fashion from any camera location along a path. Our algorithm takes as input short videos from a set of discrete camera locations, and does not require contemporaneous capture — data is acquired by moving a single camera. We analyze this data to find optimal transitions within each video (equivalent to video textures) and to find good transition points between spatially distinct videos. We propose a spatio-temporal view synthesis approach that dynamically creates intermediate frames to maintain temporal coherence. We demonstrate our approach on a variety of scenes with stochastic or repetitive motions, and we analyze the limits of our approach and failure-case artifacts.
CVMP
Two-frame Stereo Photography in Low-light Settings: A Preliminary Study
Image-pairs captured using binocular stereo-vision cameras are increasingly used to reconstruct partial 3D information. Matching corresponding points in a left-right image pair is a crucial step in this reconstruction, and one that is both slow and surprisingly fragile. The reconstruction problem is exacerbated by noise or blur in the input images because of the potential ambiguities they introduce in the matching process. For scenes that are poorly illuminated, it is necessary to make a combination of three adjustments: To increase the size of the aperture to allow more light; to increase the duration of exposure; and to increase the sensor-gain (ISO). These adjustements potentially introduce defocus, motion blur and noise — all of which adversely affect reconstruction. We present an exploratory study of how they relatively affect reconstruction by comparing the performances of a few reconstruction algorithms over the space of exposures.
CG&A
Beaming: An Asymmetric Telepresence System
A. Steed, W. Steptoe, W. Oyekoya, F. Pece, T. Weyrich, J. Kautz, D. Friedman, A. Peer, M. Solazzi, F. Tecchia, M. Bergamasco, M. Slater
The Beaming project recreates, virtually, a real environment; using immersive VR, remote participants can visit the virtual model and interact with the people in the real environment. The real environment doesn't need extensive equipment and can be a space such as an office or meeting room, domestic environment, or social space.
SIGGRAPH ASIA
3D-Printing of Non-Assembly, Articulated Models
J. Calì, D. A. Calian, C. Amati, R. Kleinberger, A. Steed, J. Kautz, T. Weyrich
ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2012)
Additive manufacturing (3D printing) is commonly used to produce physical models for a wide variety of applications, from archaeology to design. While static models are directly supported, it is desirable to also be able to print models with functional articulations, such as a hand with joints and knuckles, without the need for manual assembly of joint components. Apart from having to address limitations inherent to the printing process, this poses a particular challenge for articulated models that should be posable: to allow the model to hold a pose, joints need to exhibit internal friction to withstand gravity, without their parts fusing during 3D printing. This has not been possible with previous printable joint designs. In this paper, we propose a method for converting 3D models into printable, functional, non-assembly models with internal friction. To this end, we have designed an intuitive work- flow that takes an appropriately rigged 3D model, automatically fits novel 3D-printable and posable joints, and provides an interface for specifying rotational constraints. We show a number of results for different articulated models, demonstrating the effectiveness of our method.
PRESENCE
Acting Rehearsal in Collaborative Multimodal Mixed Reality Environments
W. Steptoe, J.-M. Normand, O. Oyekoya, F. Pece, E. Giannopoulos, F. Tecchia, A. Steed, T. Weyrich, J. Kautz, M. Slater
This paper presents experience of using our multimodal mixed reality telecommunication system to support remote acting rehearsal. The rehearsals involved two actors located in London and Barcelona, and a director in another location in London. This triadic audiovisual telecommunication was performed in a spatial and multimodal collaborative mixed reality environment based on the “destination-visitor” paradigm, which we define and motivate. We detail our heterogeneous system architecture, which spans over the three distributed and technologically-asymmetric sites, and features a range of capture, display, and transmission technologies. The actors’ and director’s experience of rehearsing a scene via the system are then discussed, exploring successes and failures of this heterogeneous form of telecollaboration. Overall, the common spatial frame of reference presented by the system to all parties was highly conducive to theatrical acting and directing, allowing blocking, gross gesture, and unambiguous instruction to be issued. The relative inexpressivity of the actors’ embodiments was identified as the central limitation of the telecommunication, meaning that moments relying on performing and reacting to consequential facial expression and subtle gesture were less successful.
ECCV
Background Inpainting for Videos with Dynamic Objects and a Free-moving Camera
M. Granados, K. I. Kim, J. Tompkin, J. Kautz, C. Theobalt
European Conference on Computer Vision (ECCV) 2012
We propose a method for removing marked dynamic objects from videos captured with a free-moving camera, so long as the objects occlude parts of the scene with a static background. Our approach takes as input a video, a mask marking the object to be removed, and a mask marking the dynamic objects to remain in the scene. To inpaint a frame, we align other candidate frames in which parts of the missing region are visible. Among these candidates, a single source is chosen to fill each pixel so that the final arrangement is color-consistent. In a final step, intensity differences between sources are smoothed using gradient domain fusion. Our frame alignment process assumes that the scene can be approximated using piecewise planar geometry: A set of homographies is estimated for each frame pair, and one each is selected for aligning pixels such that the color-discrepancy is minimized and the epipolar constraints are maintained. We provide experimental validation with several real-world video sequences to demonstrate that, unlike in previous work, inpainting videos shot with free-moving cameras does not necessarily require estimation of absolute camera positions and per-frame per-pixel depth maps.
ECCV
Match Graph Construction for Large Image Databases
K. I. Kim, J. Tompkin, M. Theobald, J. Kautz, C. Theobalt
European Conference on Computer Vision (ECCV) 2012
How best to efficiently establish correspondence among a large set of images or video frames is an interesting unanswered question. For large databases, the high computational cost of performing pair-wise image matching is a major problem. However, for many applications, images are inherently sparsely connected, and so current techniques try to correctly estimate small potentially matching subsets of databases upon which to perform expensive pair-wise matching. Our contribution is to pose the identification of potential matches as a link prediction problem in an image correspondence graph, and to propose an effective algorithm to solve this problem. Our algorithm facilitates incremental image matching: initially, the match graph is very sparse, but it becomes dense as we alternate between link prediction and verification. We demonstrate the effectiveness of our algorithm by comparing it with several existing alternatives on large-scale databases. Our resulting match graph is useful for many different applications. As an example, we show the benefits of our graph construction method to a label propagation application which propagates user-provided sparse object labels to other instances of that object in large image collections.
BMVC
PMBP: PatchMatch Belief Propagation for Correspondence Field Estimation
PatchMatch is a simple, yet very powerful and successful method for optimizing continuous labelling problems. The algorithm has two main ingredients: the update of the solution space by sampling and the use of the spatial neighbourhood to propagate samples. We show how these ingredients are related to steps in a specific form of belief propagation in the continuous space, called Particle Belief Propagation (PBP). However, PBP has thus far been too slow to allow complex state spaces. We show that unifying the two approaches yields a new algorithm, PMBP, which is more accurate than PatchMatch and orders of magnitude faster than PBP. To illustrate the benefits of our PMBP method we have built a new stereo matching algorithm with unary terms which are borrowed from the recent PatchMatch Stereo work and novel realistic pairwise terms that provide smoothness. We have experimentally verified that our method is an improvement over state-of-the-art techniques at sub-pixel accuracy level.
SIGGRAPH
Videoscapes: Exploring Sparse, Unstructured Video Collections
J. Tompkin, K. I. Kim, J. Kautz, C. Theobalt
ACM Transactions on Graphics (Proceedings SIGGRAPH 2012)
The abundance of mobile devices and digital cameras with video capture makes it easy to obtain large collections of video clips that contain the same location, environment, or event. However, such an unstructured collection is difficult to comprehend and explore. We propose a system that analyzes collections of unstructured but related video data to create a Videoscape: a data structure that enables interactive exploration of video collections by visually navigating - spatially and/or temporally - between different clips. We automatically identify transition opportunities, or portals. From these portals, we construct the Videoscape, a graph whose edges are video clips and whose nodes are portals between clips. Now structured, the videos can be interactively explored by walking the graph or by geographic map. Given this system, we gauge preference for different video transition styles in a user study, and generate heuristics that automatically choose an appropriate transition style. We evaluate our system using three further user studies, which allows us to conclude that Videoscapes provides significant benefits over related methods. Our system leads to previously unseen ways of interactive spatio-temporal exploration of casually captured videos, and we demonstrate this on several video collections.
SIGGRAPH ET
Interactive Light-Field Painting
J. Tompkin, S. Muff, S. Jakuschevskij, J. McCann, J. Kautz, M. Alexa, W. Matusik
Since Sutherland's seminal SketchPad work in 1964, direct interaction with computers has been compelling: we can directly touch, move, and change what we see. Direct interaction is a major contribution to the success of smartphones and tablets, but the world is not flat. While existing technologies can display realistic multi-view stereoscopic 3D content reasonably well, interaction within the same 3D space often requires extensive additional hardware. This project presents a cheap and easy system that uses the same lenslet array for both multi-view autostereoscopic display and 3D light-pen position sensing. The display provides multi-user, glasses-free autostereoscopic viewing with motion parallax. A single near-infrared camera located behind the lenslet array is used to track a light pen held by the user. Full 3D position tracking is accomplished by analysing the pattern produced when light from the pen shines through the lenselet array. This light pen can be used to directly draw into a displayed light field, or as input for object manipulation or defining parametric lines. The system has a number of advantages. First, it inexpensively provides both multi-view autostereoscopic display and 3D sensing with 1:1 mapping. A review of the literature indicates that this has not been offered in previous interactive content-creation systems. Second, because the same lenslet array provides both 3D display and 3D sensing, the system design is extremely simple, inexpensive, and easy to build and calibrate. The demo at SIGGRAPH 2012 shows a variety of interesting interaction styles with a prototype implementation: freehand drawing, polygonal and parametric line drawing, model manipulation, and model editing.
EUROGRAPHICS
Interactive Multi-perspective Imagery from Photos and Videos
H. Lieng, J. Tompkin, J. Kautz
Computer Graphics Forum (Proceedings Eurographics 2012)
Photographs usually show a scene from a single perspective. However, as commonly seen in art, scenes and objects can be visualized from multiple perspectives. Making such images manually is time consuming and tedious. We propose a novel system for designing multi-perspective images and videos. First, the images in the input sequence are aligned using structure from motion. This enables us to track feature points across the sequence. Second, the user chooses portal polygons in a target image into which different perspectives are to be embedded. The corresponding image regions from the other images are then copied into these portals. Due to the tracking feature and automatic warping, this approach is considerably faster than current tools. We explore a wide range of artistic applications using our system with image and video data, such as looking around corners and up and down stair cases, recursive multi-perspective imaging, cubism and panoramas.
EUROGRAPHICS
How Not to Be Seen — Object Removal from Videos of Crowded Scenes
M. Granados, J. Tompkin, K. Kim, O. Grau, J. Kautz, C. Theobalt
Computer Graphics Forum (Proceedings Eurographics 2012)
Removing dynamic objects from videos is an extremely challenging problem that even visual effects professionals often solve with time-consuming manual frame-by-frame editing. We propose a new approach to video completion that can deal with complex scenes containing dynamic background and non-periodical moving objects. We build upon the idea that the spatio-temporal hole left by a removed object can be filled with data available on other regions of the video where the occluded objects were visible. Video completion is performed by solving a large combinatorial problem that searches for an optimal pattern of pixel offsets from occluded to unoccluded regions. Our contribution includes an energy functional that generalizes well over different scenes with stable parameters, and that has the desirable convergence properties for a graph-cut-based optimization. We provide an interface to guide the completion process that both reduces computation time and allows for efficient correction of small errors in the result. We demonstrate that our approach can effectively complete complex, high-resolution occlusions that are greater in difficulty than what existing methods have shown.
CGF
State of the Art in Interactive Global Illumination
The interaction of light and matter in the world surrounding us is of striking complexity and beauty. Since the very beginning of computer graphics, adequate modeling of these processes and efficient computation is an intensively studied research topic and still not a solved problem. The inherent complexity stems from the underlying physical processes as well as the global nature of the interactions that let light travel within a scene. This article reviews the state of the art in \emph{interactive global illumination} computation, that is, methods that generate an image of a virtual scene in less than one second with an as exact as possible, or plausible, solution to the light transport. Additionally, the theoretical background and attempts to classify the broad field of methods are described. The strengths and weaknesses of different approaches, when applied to the different visual phenomena, arising from light interaction are compared and discussed. Finally, the article concludes by highlighting design patterns for interactive global illumination and a list of open problems.
The imagination of the online photographic community has recently been sparked by so-called cinemagraphs: short, seamlessly looping animated GIF images created from video in which only parts of the image move. These cinemagraphs capture the dynamics of one particular region in an image for dramatic effect, and provide the creator with control over what part of a moment to capture. We create a cinemagraphs authoring tool combining video motion stabilisation, segmentation, interactive motion selection, motion loop detection and selection, and cinemagraph rendering. Our work pushes toward the easy and versatile creation of moments that cannot be represented with still imagery.
JVRC
Adapting Standard Video Codecs for Depth Streaming
Cameras that can acquire a continuous stream of depth images are now commonly available, for instance the Microsoft Kinect. It may seem that one should be able to stream these depth videos using standard video codecs, such as VP8 or H.264. However, the quality degrades considerably as the compression algorithms are geared towards standard three-channel (8-bit) colour video, whereas depth videos are single-channel but have a higher bit depth. We present a novel encoding scheme that efficiently converts the single-channel depth images to standard 8-bit three-channel images, which can then be streamed using standard codecs. Our encoding scheme ensures that the compression affects the depth values as little as possible. We show results obtained using two common video encoders (VP8 and H.264) as well as the results obtained when using JPEG compression. The results indicate that our encoding scheme performs much better than simpler methods.
SIGGRAPH
Local Laplacian Filters: Edge-aware Image Processing with a Laplacian Pyramid
S. Paris, S. Hasinoff, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH 2011)
The Laplacian pyramid is ubiquitous for decomposing images into multiple scales and is widely used for image analysis. However, because it is constructed with spatially invariant Gaussian kernels, the Laplacian pyramid is widely believed as being unable to represent edges well and as being ill-suited for edge-aware operations such as edge-preserving smoothing and tone mapping. To tackle these tasks, a wealth of alternative techniques and representations have been proposed, e.g., anisotropic diffusion, neighborhood filtering, and specialized wavelet bases. While these methods have demonstrated successful results, they come at the price of additional complexity, often accompanied by higher computational cost or the need to post-process the generated results. In this paper, we show state-of-the-art edge-aware processing using standard Laplacian pyramids. We characterize edges with a simple threshold on pixel values that allows us to differentiate large-scale edges from small-scale details. Building upon this result, we propose a set of image filters to achieve edge-preserving smoothing, detail enhancement, tone mapping, and inverse tone mapping. The advantage of our approach is its simplicity and flexibility, relying only on simple point-wise nonlinearities and small Gaussian convolutions; no optimization or post-processing is required. As we demonstrate, our method produces consistently high-quality results, without degrading edges or introducing halos.
SIGGRAPH
Video-based Characters – Creating New Human Performances from a Multi-view Video Database
F. Xu, Y. Liu, C. Stoll, J. Tompkin, G. Bharaj, Q. Dai, H.-P. Seidel, J. Kautz, C. Theobalt
ACM Transactions on Graphics (Proceedings SIGGRAPH 2011)
We present a method to synthesize plausible video sequences of humans according to user-defined body motions and viewpoints. We first capture a small database of multi-view video sequences of an actor performing various basic motions. This database needs to be captured only once and serves as the input to our synthesis algorithm. We then apply a marker-less model-based performance capture approach to the entire database to obtain pose and geometry of the actor in each database frame. To create novel video sequences of the actor from the database, a user animates a 3D human skeleton with novel motion and viewpoints. Our technique then synthesizes a realistic video sequence of the actor performing the specified motion based only on the initial database. The first key component of our approach is a new efficient retrieval strategy to find appropriate spatio-temporally coherent database frames from which to synthesize target video frames. The second key component is a warping-based texture synthesis approach that uses the retrieved most-similar database frames to synthesize spatio-temporally coherent target video frames. For instance, this enables us to easily create video sequences of actors performing dangerous stunts without them being placed in harm's way. We show through a variety of result videos and a user study that we can synthesize realistic videos of people, even if the target motions and camera views are different from the database content.
ACM TOG
Edge-Aware Color Appearance
M. H. Kim, T. Ritschel, J. Kautz
ACM Transactions on Graphics (Presented at ACM SIGGRAPH 2011)
Color perception is recognized to vary with surrounding spatial structure, but the impact of edge smoothness on color has not been studied in color appearance modeling. In this work, we study the appearance of color under different degrees of edge smoothness. A psychophysical experiment was conducted to quantify the change in perceived lightness, colorfulness and hue with respect to edge smoothness. We confirm that color appearance, in particular lightness, changes noticeably with increased smoothness. Based on our experimental data, we have developed a computational model that predicts this appearance change. The model can be integrated into existing color appearance models. We demonstrate the applicability of our model on a number of examples.
ICCP
Display-aware Image Editing
W.-K. Jeong, K. Johnson, I. Yu, J. Kautz, H. Pfister, S. Paris,
IEEE International Conference on Computational Photography (ICCP) 2011
We describe a set of image editing and viewing tools that explicitly take into account the resolution of the display on which the image is viewed. Our approach is twofolds. First, we design editing tools that process only the visible data, which is particularly useful for images that are large compared to the display. This encompasses a variety of cases such as multi-image panoramas and high-resolution medical data. While existing techniques cannot run at interactive rate when image size approaches or exceeds the gigapixel, our algorithms address this challenge by processing only the visible data and being highly data-parallel. Second, we propose an adaptive way to set viewing parameters such brightness and contrast. We let the users set different parameter values for different locations and scales, thereby enabling the exploration of rendition of various subsets of these large images. We demonstrate the efficiency of our approach on different display and image sizes. Since the computational complexity to render a view depends on the display resolution and not the actual input image resolution, we achieve interactive image editing even on a 16 gigapixel image.
Exposure Fusion and other HDR techniques generate well-exposed images from a bracketed image sequence while reproducing a large dynamic range that far exceeds the dynamic range of a single exposure. Common to all these techniques is the problem that the smallest movements in the captured images generate artefacts (ghosting) that dramatically affect the quality of the final images. This limits the use of HDR and Exposure Fusion techniques because common scenes of interest are usually dynamic. We present a method that adapts Exposure Fusion, as well as standard HDR techniques, to allow for dynamic scene without introducing artefacts. Our method detects clusters of moving pixels within a bracketed exposure sequence with simple binary operations. We show that the proposed technique is able to deal with a large amount of movement in the scene and different movement configurations. The result is a ghost-free and highly detailed exposure fused image at a low computational cost.
PACIFIC GRAPHICS
Variance Soft Shadow Mapping
B. Yang, Z. Dong, J. Feng, H.-P. Seidel, J. Kautz
Computer Graphics Forum (Proceedings Pacific Graphics 2010)
We present variance soft shadow mapping (VSSM) for rendering plausible soft shadow in real-time. VSSM is based on the theoretical framework of percentage-closer soft shadows (PCSS) and exploits recent advances in variance shadow mapping (VSM). Our new formulation allows for the efficient computation of (average) blocker distances, a common bottleneck in PCSS-based methods. Furthermore, we avoid incorrectly lit pixels commonly encountered in VSM-based methods by appropriately subdividing the filter kernel. We demonstrate that VSSM renders high-quality soft shadows efficiently (usually over 100 fps) for complex scene settings. Its speed is at least one order of magnitude faster than PCSS for large penumbra.
SIGGRAPH
Interactive On-Surface Signal Deformation
T. Ritschel, T. Thormaehlen, C. Dachsbacher, J. Kautz, H.-P. Seidel
ACM Transactions on Graphics (Proceedings SIGGRAPH 2010)
We present an interactive system for the artistic control of visual phenomena visible on surfaces. Our method allows the user to intuitively reposition shadows, caustics, and indirect illumination using a simple click-and-drag user interface working directly on surfaces. In contrast to previous approaches, the positions of the lights or objects in the scene remain unchanged, enabling localized edits of individual shading components. Our method facilitates the editing by computing a mapping from one surface location to another. Based on this mapping, we can not only edit shadows, caustics, and indirect illumination but also other surface properties, such as color or texture, in a unified way. This is achieved using an intuitive user-interface that allows the user to specify position constraints with drag-and-drop or sketching operations directly on the surface. Our approach requires no explicit surface parametrization and handles scenes with arbitrary topology. We demonstrate the applicability of the approach to interactive editing of shadows, reflections, refractions, textures, caustics, and diffuse indirect light. The effectiveness of the system to achieve an artistic goal is evaluated by a user study.
SIGGRAPH
Acquisition and Analysis of Bispectral Bidirectional Reflectance and Reradiation Distribution Functions
M. Hullin, J. Hanika, B. Ajdin, J. Kautz, H.-P. Seidel, H. Lensch
ACM Transactions on Graphics (Proceedings SIGGRAPH 2010)
In fluorescent materials, light from a certain band of incident wavelengths is reradiated at longer wavelengths, i.e., with a reduced per-photon energy. While fluorescent materials are common in everyday life, they have received little attention in computer graphics. Especially, no bidirectional reradiation measurements of fluorescent materials have been available so far. In this paper, we extend the well-known concept of the bidirectional reflectance distribution function (BRDF) to account for energy transfer between wavelengths, resulting in a Bispectral Bidirectional Reflectance and Reradiation Distribution Function (bispectral BRRDF). Using a bidirectional and bispectral measurement setup, we acquire reflectance and reradiation data of a variety of fluorescent materials, including vehicle paints, paper and fabric, and compare their renderings with RGB, RGB$\times$RGB, and spectral BRDFs. Our acquisition is guided by a principal component analysis on complete bispectral data taken under a sparse set of angles. We show that in order to faithfully reproduce the full bispectral information for all other angles, only a very small number of wavelength pairs needs to be measured at a high angular resolution.
2009
SIGGRAPH ASIA
Micro-Rendering for Scalable, Parallel Final Gathering
T. Ritschel, T. Engelhardt, T. Grosch, H.-P. Seidel, J. Kautz, C. Dachsbacher
ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2009)
Recent approaches to global illumination for dynamic scenes achieve interactive frame rates by using coarse approximations to geometry, lighting, or both, which limits scene complexity and rendering quality. High-quality global illumination renderings of complex scenes are still limited to methods based on ray tracing. While conceptually simple, these techniques are computationally expensive. We present an efficient and scalable method to compute global illumination solutions at interactive rates for complex and dynamic scenes. Our method is based on parallel final gathering running entirely on the GPU. At each final gathering location we perform micro-rendering: we traverse and rasterize a hierarchical point-based scene representation into an importance-warped micro-buffer, which allows for BRDF importance sampling. The final reflected radiance is computed at each gathering location using the micro-buffers and is then stored in image-space. We can trade quality for speed by reducing the sampling rate of the gathering locations in conjunction with bilateral upsampling. We demonstrate the applicability of our method to interactive global illumination, the simulation of multiple indirect bounces, and to final gathering from photon maps.
VMV
Real-time Indirect Illumination with Clustered Visibility
Z. Dong, T. Grosch, T. Ritschel, J. Kautz, H.-P. Seidel
Vision, Modeling, and Visualization Workshop (VMV) 2009
Visibility computation is often the bottleneck when rendering indirect illumination. However, recent methods based on instant radiosity have demonstrated that accurate visibility is not required for indirect illumination. To exploit this insight, we cluster a large number of virtual point lights -- which represent the indirect illumination when using instant radiosity -- into a small number of virtual area lights. This allows us to compute visibility using recent real-time soft shadow algorithms. Such approximate and fractional from-area visibility is faster to compute and avoids banding when compared to exact binary from-point visibility. Our results show, that the perceptual error of this approximation is negligible and that we achieve real-time frame-rates for large and dynamic scenes.
ACM TAP
Perceptual Influence of Approximate Visibility in Indirect Illumination
I. Yu, A. Cox, M. H. Kim, T. Ritschel, T. Grosch, C. Dachsbacher, J. Kautz
ACM Transactions on Applied Perception (Presented at APGV 2009)
In this paper we evaluate the use of approximate visibility for efficient global illumination. Traditionally, accurate visibility is used in light transport. However, the indirect illumination we perceive on a daily basis is rarely of high frequency nature, as the most significant aspect of light transport in real-world scenes is diffuse, and thus displays a smooth gradation. This raises the question of whether accurate visibility is perceptually necessary in this case. To answer this question, we conduct a psychophysical study on the perceptual influence of approximate visibility on indirect illumination. This study reveals that accurate visibility is not required and that certain approximations may be introduced.
Global illumination is an important factor in creating realistic scenes and provides visual cues for understanding scene geometry. However, global illumination is very costly and only recently has it become viable to render scenes with global illumination effects at interactive frame rates by exploiting the parallelism and programmability of modern GPUs. These recent GPU-based algorithms enable the computation of global illumination solutions for fully dynamic scenes and are of interest to both the academic research community and practitioners of interactive computer graphics. In this course, we will give a concise overview of recent GPU-based global illumination techniques that support fully dynamic scenes, compare them and discuss their various strengths and weaknesses. After introducing the necessary foundation (rendering equation, direct vs. indirect illumination, etc.), we cover the three main streams of real-time global illumination techniques: virtual point lights, screen-space techniques, and hierarchical finite elements. For each sub-topic, we first give a brief overview of the basic idea and continue with recent GPU-based methods sharing the same basic idea.
SIGGRAPH
Modeling Human Color Perception under Extended Luminance Levels
M. H. Kim, T. Weyrich, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH 2009)
Display technology is advancing quickly with peak luminance increasing significantly, enabling high-dynamic-range displays. However, perceptual color appearance under extended luminance levels has not been studied, mainly due to the unavailability of psychophysical data. Therefore, we conduct a psychophysical study in order to acquire appearance data for many different luminance levels (up to 16,860cd/m2) covering most of the dynamic range of the human visual system. These experimental data allow us to quantify human color perception under extended luminance levels, yielding a generalized color appearance model. Our proposed appearance model is efficient, accurate and invertible. It can be used to adapt the tone and color of images to different dynamic ranges for cross-media reproduction while maintaining appearance that is close to human perception.
SIGGRAPH
Visio-lization: Generating Novel Facial Images
U. Mohammed, S. J. D. Prince, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH 2009)
Our goal is to generate novel realistic images of faces using a model trained from real examples. This model consists of two components: First we consider face images as samples from a texture with spatially varying statistics and describe this texture with a local non-parametric model. Second, we learn a parametric global model of all of the pixel values. To generate realistic faces, we combine the strengths of both approaches and condition the local non-parametric model on the global parametric model. We demonstrate that with appropriate choice of local and global models it is possible to reliably generate new realistic face images that do not correspond to any individual in the training data. We extend the model to cope with considerable intra-class variation (pose and illumination). Finally, we apply our model to editing real facial images: we demonstrate image in-painting, interactive techniques for improving synthesized images and modifying facial expressions.
CVPR
Capturing Multiple Illuminations using Time and Color Multiplexing
B. De Decker, J. Kautz, T. Mertens, P. Bekaert
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2009
Many vision and graphics problems such as relighting, structured light scanning and photometric stereo, need images of a scene under a number of different illumination conditions. It is typically assumed that the scene is static. To extend such methods to dynamic scenes, dense optical flow can be used to register adjacent frames. This registration becomes inaccurate if the frame rate is too low with respect to the degree of movement in the scenes. We present a general method that extends time multiplexing with color multiplexing in order to better handle dynamic scenes. Our method allows for packing more illumination information into a single frame, thereby reducing the number of required frames over which optical flow must be computed. Moreover, color-multiplexed frames lend themselves better to reliably computing optical flow. We show that our method produces better results compared to time-multiplexing alone. We demonstrate its application to relighting, structured light scanning and photometric stereo in dynamic scenes.
CAe
Consistent Scene Illumination using a Chromatic Flash
M. H. Kim, J. Kautz
Computational Aesthetics in Graphics, Visualization, and Imaging (CAe) 2009
Flash photography is commonly used in low-light conditions to prevent noise and blurring artifacts. However, flash photography commonly leads to a mismatch between scene illumination and flash illumination, due to the bluish light that flashes emit. Not only does this change the atmosphere of the original scene illumination, it also makes it difficult to perform white balancing because of the illumination differences. Professional photographers sometimes apply colored gel filters to the flashes in order to match the color temperature. While effective, this is impractical for the casual photographer. We propose a simple but powerful method to automatically match the correlated color temperature of the auxiliary flash light with that of scene illuminations allowing for well-lit photographs while maintaining the atmosphere of the scene. Our technique consists of two main components. We first estimate the correlated color temperature of the scene, e.g., during image preview. We then adjust the color temperature of the flash to the scene's correlated color temperature, which we achieve by placing a small trichromatic LCD in front of the flash. We demonstrate the effectiveness of this approach with a variety of examples.
CGF
Exposure Fusion: A Simple and Practical Alternative to High Dynamic Range Photography
T. Mertens, J. Kautz, F. Van Reeth
Computer Graphics Forum
28(1), March 2009, pages 161-171 (extended version of PG'07)
We propose a technique for fusing a bracketed exposure sequence into a high quality image, without converting to HDR first. Skipping the physically-based HDR assembly step simplifies the acquisition pipeline. This avoids camera response curve calibration and is computationally efficient. It also allows for including flash images in the sequence. Our technique blends multiple exposures, guided by simple quality measures like saturation and contrast. This is done in a multi-resolution fashion to account for the brightness variation in the sequence. The resulting image quality is comparable to existing tone mapping operators.
2008
SIGGRAPH ASIA
Imperfect Shadow Maps for Efficient Computation of Indirect Illumination
T. Ritschel, T. Grosch, M. Kim, H.-P. Seidel, C. Dachsbacher, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2008)
We present a method for interactive computation of indirect illumination in large and fully dynamic scenes based on approximate visibility queries. While the high-frequency nature of direct lighting requires accurate visibility, indirect illumination mostly consists of smooth gradations, which tend to mask errors due to incorrect visibility. We exploit this by approximating visibility for indirect illumination with imperfect shadow maps—low-resolution shadow maps rendered from a crude point-based representation of the scene. These are used in conjunction with a global illumination algorithm based on virtual point lights enabling indirect illumination of dynamic scenes at real-time frame rates. We demonstrate that imperfect shadow maps are a valid approximation to visibility, which makes the simulation of global illumination an order of magnitude faster than using accurate visibility.
SIGGRAPH
Real-Time, All-Frequency Shadows in Dynamic Scenes
T. Annen, Z. Dong, T. Mertens, P. Bekaert, H.-P. Seidel, J. Kautz
ACM Transactions on Graphics (Proceedings SIGGRAPH 2008)
Shadow computation in dynamic scenes under complex illumination is a challenging problem. Methods based on precomputation provide accurate, real-time solutions, but are hard to extend to dynamic scenes. Specialized approaches for soft shadows can deal with dynamic objects but are not fast enough to handle more than one light source. In this paper, we present a technique for rendering dynamic objects under arbitrary environment illumination, which does not require any precomputation. The key ingredient is a fast, approximate technique for computing soft shadows, which achieves several hundred frames per second for a single light source. This allows for approximating environment illumination with a sparse collection of area light sources and yields real-time frame rates.
GRAPHICS INTERFACE
Exponential Shadow Maps
T. Annen, T. Mertens, H.-P. Seidel, E. Flerackers, J. Kautz
Rendering high-quality shadows in real-time is a challenging problem. Shadow mapping has proved to be an efficient solution, as it scales well for complex scenes. However, it suffers from aliasing problems. Filtering the shadow map alleviates aliasing, but unfortunately, native hardware-accelerated filtering cannot be applied, as the shadow test has to take place beforehand. We introduce a simple approach to shadow map filtering, by approximating the shadow test using an exponential function. This enables us to pre-filter the shadow map, which in turn allows for high quality hardware-accelerated filtering. Compared to previous filtering techniques, our technique is faster, consumes less memory and produces less artifacts.
GRAPHICS INTERFACE
Interactive Global Illumination Based on Coherent Surface Shadow Maps
Interactive rendering of global illumination effects is a challenging problem. While precomputed radiance transfer (PRT) is able to render such effects in real time the geometry is generally assumed static. This work proposes to replace the precomputed lighting response used in PRT by precomputed depth. Precomputing depth has the same cost as precomputing visibility, but allows visibility tests for moving objects at runtime using simple shadow mapping. For this purpose, a compression scheme for a high number of coherent surface shadow maps (CSSMs) covering the entire scene surface is developed. CSSMs allow visibility tests between all surface points against all points in the scene. We demonstrate the effectiveness of CSSM-based visibility using a novel combination of the lightcuts algorithm and hierarchical radiosity, which can be efficiently implemented on the GPU. We demonstrate interactive n-bounce diffuse global illumination, with a final glossy bounce and many high frequency effects: general BRDFs, texture and normal maps, and local or distant lighting of arbitrary shape and distribution -- all evaluated per-pixel. Furthermore, all parameters can vary freely over time -- the only requirement is rigid geometry.
In this paper we present a new practical camera characterization technique to improve color accuracy in high dynamic range (HDR) imaging. Camera characterization refers to the process of mapping device-dependent signals, such as digital camera RAW images, into a well-defined color space. This is a well-understood process for low dynamic range (LDR) imaging and is part of most digital cameras --- usually mapping from the raw camera signal to the sRGB or Adobe RGB color space. This paper presents an efficient and accurate characterization method for high dynamic range imaging that extends previous methods originally designed for LDR imaging. We demonstrate that our characterization method is very accurate even in unknown illumination conditions, effectively turning a digital camera into a measurement device that measures physically accurate radiance values --- both in terms of luminance and color --- rivaling more expensive measurement instruments.
We propose a technique for fusing a bracketed exposure sequence into a high quality image, without converting to HDR first. Skipping the physically-based HDR assembly step simplifies the acquisition pipeline. This avoids camera response curve calibration and is computationally efficient. It also allows for including flash images in the sequence. Our technique blends multiple exposures, guided by simple quality measures like saturation and contrast. This is done in a multi-resolution fashion to account for the brightness variation in the sequence. The resulting image quality is comparable to existing tone mapping operators.
PACIFIC GRAPHICS
Interactive Global Illumination Using Implicit Visibility
Rendering global illumination effects for dynamic scenes at interactive frame rates is a computationally challenging task. Much of the computation time needed is spent during visibility queries between individual scene elements, and it is almost illusive to update this information at real-time even for moderately complex scenes. In this paper, we propose a global illumination approach for dynamic scenes that runs at near-real-time frame rates on a single PC. Our method is inspired by the principles of hierarchical radiosity and tackles the visibility problem by implicitly evaluating mutual visibility while constructing a hierarchical link structure between scene elements. By means of the same efficient and easy-to-implement framework, we are able to reproduce a large variety of complex lighting effects for moderately sized scenes, such as interreflections, environment map lighting as well as area light sources.
EUROGRAPHICS
Efficient Reflectance and Visibility Approximations for Environment Map Rendering
We present a technique for approximating isotropic BRDFs and precomputed self-occlusion that enables accurate and efficient prefiltered environment map rendering. Our approach uses a nonlinear approximation of the BRDF as a weighted sum of isotropic Gaussian functions. Our representation requires a minimal amount of storage, can accurately represent BRDFs of arbitrary sharpness, and is above all efficient to render. We precompute visibility due to self-occlusion and store a low-frequency approximation suitable for glossy reflections. We demonstrate our method by fitting our representation to measured BRDF data, yielding high visual quality at real-time frame rates.
SIGGRAPH
Interactive Editing and Modeling of Bidirectional Texture Functions
J. Kautz, S. Boulos, F. Durand
ACM Transactions on Graphics (Proceedings SIGGRAPH 2007)
While measured Bidirectional Texture Functions (BTF) enable impressive realism in material appearance, they offer little control, which limits their use for content creation. In this work, we interactively manipulate BTFs and create new BTFs from flat textures. We present an out-of-core approach to manage the size of BTFs and introduce new editing operations that modify the appearance of a material. These tools achieve their full potential when selectively applied to subsets of the BTF through the use of new selection operators. We further analyze the use of our editing operators for the modification of important visual characteristics such as highlights, roughness, and fuzziness. Results compare favorably to the direct alteration of micro-geometry and reflectances of ground-truth synthetic data.
APGV
Is Accurate Occlusion of Glossy Reflections Necessary?
O. Kozlowski, J. Kautz
Symposium on Applied Perception in Graphics and Visualization 2007
Much research in recent times has been conducted towards realtime rendering of accurate glossy reflections under direct, natural illumination including correct occlusions. The view dependent nature of these reflections will always cause this computation to be expensive unless heavily approximated. There also remains a question as to whether humans are even capable of noticing the difference in accuracy or whether our perception of the realism of the scene remains unchanged and thus the extra effort expended in rendering accurate reflections is effectively wasted. We conduct a user study to analyse any decline in perceived realism of glossy scenes rendered with a variety of specular occlusion approximations under a multitude of BRDFs, lighting environments and camera orientations. We demonstrate that although no one approximation is always suitable, it is rare to have a scene whose computational complexity cannot be decreased to some degree.
EGSR
Convolution Shadow Maps
T. Annen, T. Mertens, P. Bekaert, H.-P. Seidel, J. Kautz
We present Convolution Shadow Maps, a novel shadow representation that affords efficient arbitrary linear filtering of shadows. Traditional shadow mapping is inherently non-linear w.r.t. the stored depth values, due to the binary shadow test. We linearize the problem by approximating shadow test as a weighted summation of basis terms. We demonstrate the usefulness of this representation, and show that hardware-accelerated anti-aliasing techniques, such as tri-linear filtering, can be applied naturally to Convolution Shadow Maps. Our approach can be implemented very efficiently in current generation graphics hardware, and offers real-time frame rates.
EGSR
Interactive Illumination with Coherent Shadow Maps
We present a new method for interactive illumination computations based on precomputed visibility using coherent shadow maps (CSMs). It is well-known that visibility queries dominate the cost of physically based rendering. Precomputing all visibility events, for instance in the form of many shadow maps, enables fast queries and allows for real-time computation of illumination but requires prohibitive amounts of storage. We propose a lossless compression scheme for visibility information based on shadow maps that efficiently exploits coherence. We demonstrate a Monte Carlo renderer for direct lighting using CSMs that runs entirely on graphics hardware. We support spatially varying BRDFs, normal maps, and environment maps all with high frequencies, spatial as well as angular. Multiple dynamic rigid objects can be combined in a scene. As opposed to precomputed radiance transfer techniques, that assume distant lighting, our method includes distant lighting as well as local area lights of arbitrary shape, varying intensity, or anisotropic light distribution that can freely vary over time.
GRAPHICS INTERFACE
Packet-Based Whitted and Distribution Ray Tracing
S. Boulos, D. Edwards, J. Lacewell, J. Kniss, J. Kautz, I. Wald, P. Shirley
Much progress has been made toward interactive ray tracing, but most research has focused specifically on ray casting. A common approach is to use "packets" of rays to amortize cost across sets of rays. Whether "packets" can be used to speed up the cost of reflection and refraction rays is unclear. The issue is complicated since such rays do not share common origins and often have less directional coherence than viewing and shadow rays. Since the primary advantage of ray tracing over rasterization is the computation of global effects, such as accurate reflection and refraction, this lack of knowledge should be corrected. We are also interested in exploring whether distribution ray tracing, due to its stochastic properties, further erodes the effectiveness of techniques used to accelerate ray casting. This paper addresses the question of whether packet-based ray algorithms can be effectively used for more than visibility computation. We show that by choosing an appropriate data structure and a suitable packet assembly algorithm we can extend the idea of "packets" from ray casting to Whitted-style and distribution ray tracing, while maintaining efficiency.
This course discusses the practical implementation of physically-principled reflectance models in interactive graphics and video games, in current practice as well as upcoming technologies. The course begins with the visual phenomena important to the perception of reflectance in real-world materials, which it uses as background for the underlying theory and derivation of common reflectance models. After introducing the current game development pipeline, from content creation to rendering, the course then discusses rendering techniques for implementing reflectance models in games --- with emphasis on real-world trade offs such as shader performance, content creation efficiency, resource size considerations, and overall rendering quality. The course will help a researcher understand constraints in the game development pipeline and it will help a game developer understand the physical phenomena underlying reflectance models.
EGSR
Texture Transfer Using Geometry Correlation
T. Mertens, J. Kautz, J. Chen, P. Bekaert, F. Durand
Texture variation on real-world objects often correlates with underlying geometric characteristics and creates a visually rich appearance. We present a technique to transfer such geometry-dependent texture variation from an example textured model to new geometry in a visually consistent way. It captures the correlation between a set of geometric features, such as curvature, and the observed diffuse texture. We perform dimensionality reduction on the overcomplete feature set which yields a compact guidance field that is used to drive a spatially varying texture synthesis model. In addition, we introduce a method to enrich the guidance field when the target geometry strongly differs from the example. Our method transfers elaborate texture variation that follows geometric features, which gives 3D models a compelling photorealistic appearance.
I3D
View-Dependent Precomputed Light Transport Using Nonlinear Gaussian Function Approximations
P. Green, J. Kautz, W. Matusik, F. Durand
ACM Symposium in Interactive 3D Graphics and Games (I3D) 2006
We propose a real-time method for rendering rigid objects with complex view-dependent effects under distant all-frequency lighting. Existing precomputed light transport approaches can render rich global illumination effects, but high-frequency view-dependent effects such as sharp highlights remain a challenge. We introduce a new representation of the light transport operator based on sums of Gaussians. The nonlinear parameters of our representation enable 1) arbitrary bandwidth because scale is encoded as a direct parameter, and 2) high-quality interpolation across view and mesh triangles because we interpolate the mean direction of the Gaussians, thereby preventing linear cross-fading artifacts. However, fitting the precomputed light transport data to this new representation requires solving a nonlinear regression problem that is more involved than traditional linear and nonlinear (truncation) approximation techniques. We present a new data fitting method based on optimization that includes energy terms aimed at enforcing artifactfree interpolation. We demonstrate that our method achieves high visual quality with a small storage cost and an efficient rendering algorithm.
2005
SIGGRAPH
Precomputed Radiance Transfer: Theory and Practice
Interactive rendering of realistic objects under general lighting models poses three principal challenges. Handling complex light transport phenomena like shadows, inter-reflections, caustics and sub-surface scattering is difficult to do in real time. Integrating these effects over large area light sources compounds the difficulty, and finally real objects have complex spatially-varying BRDF's. Precomputed Radiance Transfer (PRT) encapsulates a family of techniques that partially addresses these challenges. PRT is an active of area of research that has relevance to both the academic research community and practitioners of interactive computer graphics. This technique and its variants are being actively investigated in the game development community and there is quite a lot of interest due to the recent appearance of PRT techniques in games such as "Halo 2". This course covers these techniques, compares them and discusses their various strengths and weaknesses.
CGF
Efficient Rendering of Local Subsurface Scattering
Tom Mertens, Jan Kautz, Philippe Bekaert, Frank Van Reeth, Hans-Peter Seidel
A novel approach is presented to efficiently render local subsurface scattering effects. We introduce an importance sampling scheme for a practical subsurface scattering model. It leads to a simple and efficient rendering algorithm, which operates in image- or texture-space, and which is even amenable for implementation on graphics hardware. We demonstrate the applicability of our technique to the problem of skin rendering, for which the subsurface transport of light typically remains local. Our implementation shows that plausible images can be rendered interactively using hardware acceleration.
2004
SIGGRAPH
Real-Time Shadowing Techniques
J. Kautz, M. Stamminger, T. Akenine-Moeller, E. Chan, W. Heidrich, M. Kilgard
Shadows heighten realism and provide important visual cues about the spatial relationships between objects. But integration of robust shadow shadowing techniques in real-time rendering is not an easy task. In this course on how shadows are incorporated in real-time rendering, attendees learn basic shadowing techniques and more advanced techniques that exploit new features of graphics hardware. The course begins with shadowing techniques using shadow maps. After an introduction to shadow maps and general improvements of this technique (filtering, depth bias, omnidirectional lights, etc.), the first section describes two methods for reducing sampling artifacts: perspective shadow maps and silhouette maps. Both techniques can significantly improve shadow quality, but they require careful implementation. The course continues with extensions of the shadow mapping method that allow soft shadows from linear and area light sources. The second part of the course discusses recent advances in efficient and robust implementation of shadow volumes on graphics hardware and then shows how shadow volumes can be extended to generate accurate soft shadows from area lights. Finally, the course summarizes real-time shadowing from full lighting environments using the technique of precomputed radiance transfer. The course explains the differences among these algorithms and their strengths and weaknesses. Implementation details, often omitted in technical papers, are provided. And throughout the course, the tradeoffs between quality and performance are illustrated for the different techniques.
EGSR
Hemispherical Rasterization for Self-Shadowing of Dynamic Objects
We present a method for interactive rendering of dynamic models with self-shadows due to time-varying, low-frequency lighting environments. In contrast to previous techniques, the method is not limited to static or pre-animated models. Our main contribution is a hemispherical rasterizer, which rapidly computes visibility by rendering blocker geometry into a 2D occlusion mask with correct occluder fusion. The response of an object to the lighting is found by integrating the visibility function at each of the vertices against the spherical harmonic functions and the BRDF. This yields transfer coefficients that are then multiplied by the lighting coefficients to obtain the final, shadowed exitant radiance. No precomputation is necessary and memory requirements are modest. The method supports both diffuse and glossy BRDFs.
EGSR
A Self-Shadow Algorithm for Dynamic Hair using Clustered Densities
Self-shadowing is an important factor in the appearance of hair and fur. In this paper we present a new rendering algorithm to accurately compute shadowed hair at interactive rates using graphics hardware. No constraint is imposed on the hair style, and its geometry can be dynamic. Similar to previously presented methods, a 1D visibility function is constructed for each line of sight of the light source view. Our approach differs from other work by treating the hair geometry as a 3D density field, which is sampled on the fly using simple rasterization. The rasterized fragments are clustered, effectively estimating the density of hair along a ray. Based hereon, the visibility function is constructed. We show that realistic self-shadowing of thousands of individual dynamic hair strands can be rendered at interactive rates using consumer graphics hardware.
EGSR
Spherical Harmonic Gradients for Mid-Range Illumination
Spherical harmonics are often used for compact description of incident radiance in low-frequency but distant lighting environments. For interaction with nearby emitters, computing the incident radiance at the center of an object only is not sufficient. Previous techniques then require expensive sampling of the incident radiance field at many points distributed over the object. Our technique alleviates this costly requirement using a first-order Taylor expansion of the spherical-harmonic lighting coefficients around a point. We propose an interpolation scheme based on these gradients requiring far fewer samples (one is often sufficient). We show that the gradient of the incident-radiance spherical harmonics can be computed for little additional cost compared to the coefficients alone. We introduce a semi-analytical formula to calculate this gradient at run-time and describe how a simple vertex shader can interpolate the shading. The interpolated representation of the incident radiance can be used with any low-frequency light-transfer technique.
GRAPHICS INTERFACE
Decoupling BRDFs from Surface Mesostructures
J. Kautz, M. Sattler, R. Sarlette, R. Klein, H.-P. Seidel
We present a technique for the easy acquisition of realistic materials and mesostructures, without acquiring the actual BRDF. The method uses the observation that under certain circumstances the mesostructure of a surface can be acquired independently of the underlying BRDF. The acquired data can be used directly for rendering with little preprocessing. Rendering is possible using an offline renderer but also using graphics hardware, where it achieves real-time frame rates. Compelling results are achieved for a wide variety of materials.
Traditionally, hardware rasterizers only support the Phong lighting model in combination with Gouraud shading using point light sources. However, the Phong lighting model is strictly empirical and physically implausible. Gouraud shading also tends to undersample the highlight unless a highly tesselated surface is used. Hence, higherquality hardware accelerated lighting and shading has gained much interest in the recent five years. The research on hardware lighting and shading is two-fold. On the one hand, better lighting models for local illumination (assuming point light sources but evaluated per pixel) were demonstrated to be amenable to hardware implementation. On the other hand, recent research has demonstrated that even area lights, represented as environment maps, can be combined with complex lighting models. In both areas, many articles have been published, making it hard to decide which algorithm is well-suited for which application. This state-of-the-art report will review all relevent articles in both areas, and list advantages and disadvantages of each algorithm.
In this paper, we propose a simple approach for rendering diffuse and glossy reflections using environment maps. This approach is geared towards VR applications, where realism and fast rendering is important. We exploit certain properties of diffuse reflections and certain features of graphics hardware for glossy reflections. This results in a very fast, single-pass rendering algorithm, which even allows to dynamically vary the incident lighting.
2003
PACIFIC GRAPHICS
Efficient Rendering of Local Subsurface Scattering
T. Mertens, J. Kautz, P. Bekaert, H.-P. Seidel, F. Van Reeth
A novel approach is presented to efficiently render local subsurface scattering effects. We introduce an importance sampling scheme for a practical subsurface scattering model. It leads to a simple and efficient rendering algorithm, which operates in image-space, and which is even amenable for implementation on graphics hardware. We demonstrate the applicability of our technique to the problem of skin rendering, for which the subsurface transport of light typically remains local. Our implementation shows that plausible images can be rendered interactively using hardware acceleration.
CGF
Interactive Rendering of Translucent Objects
H. Lensch, M.Goesele, P. Bekaert, J. Kautz, M. Magnor, J. Lang, H.-P. Seidel
This paper presents a rendering method for translucent objects, in which view point and illumination can be modi- fied at interactive rates. In a preprocessing step the impulse response to incoming light impinging at each surface point is computed and stored in two different ways: The local effect on close-by surface points is modeled as a per-texel filter kernel that is applied to a texture map representing the incident illumination. The global response (i.e. light shining through the object) is stored as vertex-to-vertex throughput factors for the triangle mesh of the object. During rendering, the illumination map for the object is computed according to the current lighting situation and then filtered by the precomputed kernels. The illumination map is also used to derive the incident illumination on the vertices which is distributed via the vertex-to-vertex throughput factors to the other vertices. The final image is obtained by combining the local and global response. We demonstrate the performance of our method for several models.
EGSR
Interactive Rendering of Translucent Deformable Objects
T. Mertens, J. Kautz, P. Bekaert, H.-P. Seidel, F. Van Reeth
Realistic rendering of materials such as milk, fruits, wax, marble, and so on, requires the simulation of subsurface scattering of light. This paper presents an algorithm for plausible reproduction of subsurface scattering effects. Unlike previously proposed work, our algorithm allows to interactively change lighting, viewpoint, subsurface scattering properties, as well as object geometry. The key idea of our approach is to use a hierarchical boundary element method to solve the integral describing subsurface scattering when using a recently proposed analytical BSSRDF model. Our approach is inspired by hierarchical radiosity with clustering. The success of our approach is in part due to a semi-analytical integration method that allows to compute needed point-to-patch form-factor like transport coefficients efficiently and accurately where other methods fail. Our experiments show that high-quality renderings of translucent objects consisting of tens of thousands of polygons can be obtained from scratch in fractions of a second. An incremental update algorithm further speeds up rendering after material or geometry changes.
CG&A
Efficient Light Transport Using Precomputed Visibility
K. Daubert, W. Heidrich, J. Kautz, J.-M. Dischler, H.-P. Seidel
Global illumination algorithms usually spend the majority of time on visibility computations. It therefore seems natural to reuse visibility information acquired at one point for different computations. For example, once we've established the visibility between two points in a scene, we can use this information for multiple light paths in which different amounts of energy are transported between the points. This is particularly advantageous in cases where we need to compute multiple images with varying illumination or camera settings. Researchers have developed several approaches where illumination information computed for one point in the scene is reused for nearby points. Because these methods store illumination information (irradiance or incident radiance) at discrete points, it isn't possible to reuse the information for light source changes. In addition, finding the desired information for one point in space requires a search through the data structure. Although we can perform this search in logarithmic expected time, the resulting memory access patterns are irregular and can significantly affect performance. We take a different approach. Instead of storing and reusing illumination information, we directly reuse visibility information stored in a regular fashion that allows for constant time lookups. Our method is a generalization of Heidrich et al.'s method for height fields to different geometries such as general parametric surfaces, triangle meshes without a global parameterization, and volumes. For each case we propose efficient algorithms for computing direct and indirect illumination, which also account for shadows. Using the method of dependent tests - a variant of Monte Carlo integration - we can access the visibility in a structured fashion. This allows for efficient memory access patterns in software implementations and lets us use graphics hardware for the light transport.
Precomputed Radiance Transfer allows interactive rendering of objects illuminated by low-frequency environment maps, including self-shadowing and interreflections. The expensive integration of incident lighting is partially precomputed and stored as matrices. Incorporating anisotropic, glossy BRDFs into precomputed radiance transfer has been previously shown to be possible, but none of the previous methods offer real-time performance. We propose a new method, matrix radiance transfer, which significantly speeds up exit radiance computation and allows anisotropic BRDFs. We generalize the previous radiance transfer methods to work with a matrix representation of the BRDF and optimize exit radiance computation by expressing the exit radiance in a new, directionally locally supported basis set instead of the spherical harmonics. To determine exit radiance, our method performs four dot products per vertex in contrast to previous methods, where a full matrix-vector multiply is required. Image quality can be controlled by adapting the number of basis functions. We compress our radiance transfer matrices through principal component analysis (PCA). We show that it is possible to render directly from the PCA representation, which also enables the user to trade interactively between quality and speed.
ACM TOG
Image-Based Reconstruction of Spatial Appearance and Geometric Detail
H. Lensch, J. Kautz, M. Goesele, W. Heidrich, H.-P. Seidel
Real-world objects are usually composed of a number of different materials that often show subtle changes even within a single material. Photorealistic rendering of such objects requires accurate measurements of the reflection properties of each material, as well as the spatially varying effects. We present an image-based measuring method that robustly detects the different materials of real objects and fits an average bidirectional reflectance distribution function (BRDF) to each of them. In order to model local changes as well, we project the measured data for each surface point into a basis formed by the recovered BRDFs leading to a truly spatially varying BRDF representation. Real-world objects often also have fine geometric detail that is not represented in an acquired mesh. To increase the detail, we derive normal maps even for non-Lambertian surfaces using our measured BRDFs. A high quality model of a real object can be generated with relatively little input data. The generated model allows for rendering under arbitrary viewing and lighting conditions and realistically reproduces the appearance of the original object.
2002
PACIFIC GRAPHICS
Interactive Rendering of Translucent Objects
H. Lensch, M.Goesele, P. Bekaert, J. Kautz, M. Magnor, J. Lang, H.-P. Seidel
This paper presents a rendering method for translucent objects, in which view point and illumination can be modi- fied at interactive rates. In a preprocessing step the impulse response to incoming light impinging at each surface point is computed and stored in two different ways: The local effect on close-by surface points is modeled as a per-texel filter kernel that is applied to a texture map representing the incident illumination. The global response (i.e. light shining through the object) is stored as vertex-to-vertex throughput factors for the triangle mesh of the object. During rendering, the illumination map for the object is computed according to the current lighting situation and then filtered by the precomputed kernels. The illumination map is also used to derive the incident illumination on the vertices which is distributed via the vertex-to-vertex throughput factors to the other vertices. The final image is obtained by combining the local and global response. We demonstrate the performance of our method for several models.
We present a real-time hardware accelerated method for rendering objects using halftoning. It is solely based on texture mapping and creates the impression of a printed image, although the lighting and the objects can be changed and manipulated on-the-fly.
Quite a few techniques have been proposed on how to implement more complex and realistic shading models with graphics hardware, making them useful for games. Still, these techniques are rarely used probably due to two reasons: complex implementation issues and unintuitive parameters for the used shading models. We propose to use a simple technique called "NDF shading". It allows an artist to handcraft shading models; shape and color of highlights are simply stored in a bitmap. The technique uses per-pixel shading, and can also be used in conjunction with bump mapping; anisotropic shading models can also be created.
SIGGRAPH
Precomputed Radiance Transfer for Real-Time Rendering in Dynamic, Low-Frequency Lighting Environments
P.-P. Sloan, J. Kautz, J. Snyder
ACM Transactions on Graphics (Proceedings SIGGRAPH 2002)
We present a new, real-time method for rendering diffuse and glossy objects in low-frequency lighting environments that captures soft shadows, interreflections, and caustics. As a preprocess, a novel global transport simulator creates functions over the object's surface representing transfer of arbitrary, low-frequency incident lighting into transferred radiance which includes global effects like shadows and interreflections from the object onto itself. At run-time, these transfer functions are applied to actual incident lighting. Dynamic, local lighting is handled by sampling it close to the object every frame; the object can also be rigidly rotated with respect to the lighting and vice versa. Lighting and transfer functions are represented using low-order spherical harmonics. This avoids aliasing and evaluates efficiently on graphics hardware by reducing the shading integral to a dot product of 9 to 25 element vectors for diffuse receivers. Glossy objects are handled using matrices rather than vectors. We further introduce functions for radiance transfer from a dynamic lighting environment through a preprocessed object to neighboring points in space. These allow soft shadows and caustics from rigidly moving objects to be cast onto arbitrary, dynamic receivers. We demonstrate real-time global lighting effects with this approach.
EGWR
Fast, Arbitrary BRDF Shading for Low-Frequency Lighting Using Spherical Harmonics
Real-time shading using general (e.g., anisotropic) BRDFs has so far been limited to a few point or directional light sources. We extend such shading to smooth, area lighting using a low-order spherical harmonic basis for the lighting environment. We represent the 4D product function of BRDF times the cosine factor (dot product of the incident lighting and surface normal vectors) as a 2D table of spherical harmonic coefficients. Each table entry represents, for a single view direction, the integral of this product function times lighting on the hemisphere expressed in spherical harmonics. This reduces the shading integral to a simple dot product of 25 component vectors, easily evaluatable on PC graphics hardware. Non-trivial BRDF models require rotating the lighting coefficients to a local frame at each point on an object, currently forming the computational bottleneck. Real-time results can be achieved by fixing the view to allow dynamic lighting or vice versa. We also generalize a previous method for precomputed radiance transfer to handle general BRDF shading. This provides shadows and interreflections that respond in real-time to lighting changes on a preprocessed object of arbitrary material (BRDF) type.
2001
GRAPHICS HARDWARE
Real-Time Bump Map Synthesis
J. Kautz, W. Heidrich, H.-P. Seidel
Eurographics/SIGGRAPH Workshop on Graphics Hardware 2001
In this paper we present a method that automatically synthesizes bump maps at arbitrary levels of detail in real-time. The only input data we require is a normal density function; the bump map is generated according to that function. It is also used to shade the generated bump map. The technique allows to infinitely zoom into the surface, because more (consistent) detail can be created on the fly. The shading of such a surface is consistent when displayed at different distances to the viewer (assuming that the surface structure is self-similar). The bump map generation and the shading algorithm can also be used separately.
EGWR
Image-Based Reconstruction of Spatially Varying Materials
H. Lensch, J. Kautz, M. Goesele, W. Heidrich, H.-P. Seidel
The measurement of accurate material properties is an important step towards photorealistic rendering. Many real-world objects are composed of a number of materials that often show subtle changes even within a single material. Thus, for photorealistic rendering both the general surface properties as well as the spatially varying effects of the object are needed. We present an image-based measuring method that robustly detects the different materials of real objects and fits an average bidirectional reflectance distribution function (BRDF) to each of them. In order to model the local changes as well, we project the measured data for each surface point into a basis formed by the recovered BRDFs leading to a truly spatially varying BRDF representation. A high quality model of a real object can be generated with relatively few input data. The generated model allows for rendering under arbitrary viewing and lighting conditions and realistically reproduces the appearance of the original object.
GRAPHICS INTERFACE
Hardware Accelerated Displacement Mapping for Image Based Rendering
In this paper, we present a technique for rendering displacement mapped geometry using current graphics hardware. Our method renders a displacement by slicing through the enclosing volume. The alpha-test is used to render only the appropriate parts of every slice. The slices need not to be aligned with the base surface, e.g. it is possible to do screen-space aligned slicing. We then extend the method to be able to render the intersection between several displacement mapped polygons. This is used to render a new kind of image-based objects based on images with depth, which we call image based depth objects. This technique can also directly be used to accelerate the rendering of objects using the image-based visual hull. Other warping based IBR techniques can be accelerated in a similar manner.
GDM
Achieving Real-Time Realistic Reflectances
J. Kautz, J. Blow, C. Blasband, A. Ahmad, M. McCool
Within the game development community, several current approaches address the illumination problem. Point lights (with optional fog, distance, or shadow attenuation) are often used to determine the amount of light that arrives at a surface. Directional light sources and light maps effectively serve this purpose as well. Unfortunately, sophisticated models of reflectance have not really made an appearance in games. In terms of reflectance, most games to date use the Phong reflectance model or rely on strict intensity modulation to determine how surfaces reflect the light that strikes them. While this is not a bad thing, Phong reflectance and intensity modulation are limited in the type of lighting phenomena they are capable of simulating. Consequently, they are unable to reproduce the appearance that we observe of many real-world materials. This two-part series of articles focuses on the reflectance aspect of lighting. We will discuss a technique that implements more general reflectance models for a wide variety of surface materials, for example velvet, copper, and others. This is called separable decomposition and is an effective and efficient way to incorporate physically accurate reflection models and ultimately increase the level of realism in a game. The technique can be used in conjunction with point light sources, directional light sources, light maps, shadows, and fog, since each of these influences only the illumination component of lighting and does not affect the reflectance model.
2000
GRAPHICS HARDWARE
Towards Interactive Bump Mapping with Anisotropic Shift-Variant BRDFs
J. Kautz, H.-P. Seidel
Eurographics/SIGGRAPH Workshop on Graphics Hardware 2000
August 2000, pages 51-58 (Best Paper Award - 2nd Place)
In this paper a technique is presented that combines interactive hardware accelerated bump mapping with shift-variant anisotropic reflectance models. An evolutionary path is shown how some simpler reflectance models can be rendered at interactive rates on current low-end graphics hardware, and how features from future graphics hardware can be exploited for more complex models. We show how our method can be applied to some well known reflectance models, namely the Banks model, Ward's model, and an anisotropic version of the Blinn-Phong model, but it is not limited to these models. Furthermore, we take a close look at the necessary capabilities of the graphics hardware, identify problems with current hardware, and discuss possible enhancements.
SIGGRAPH
Illuminating Micro Geometry Based on Precomputed Visibility
Many researchers have been arguing that geometry, bump maps, and BRDFs present a hierarchy of detail that should be exploited for efficient rendering purposes. In practice however, this is often not possible due to inconsistencies in the illumination for these different levels of detail. For example, while bump map rendering often only considers direct illumination and no shadows, geometry-based rendering and BRDFs will mostly also respect shadowing effects, and in many cases even indirect illumination caused by scattered light. In this paper, we present an approach for overcoming these inconsistencies. We introduce an inexpensive method for consistently illuminating height fields and bump maps, as well as simulating BRDFs based on precomputed visibility information. With this information we can achieve a consistent illumination across the levels of detail. The method we propose offers significant performance benefits over existing algorithms for computing the light scattering in height fields and for computing a sampled BRDF representation using a virtual gonioreflectometer. The performance can be further improved by utilizing graphics hardware, which then also allows for interactive display. Finally, our method also approximates the changes in illumination when the height field, bump map, or BRDF is applied to a surface with a different curvature.
EGWR
A Unified Approach to Prefiltered Environment Maps
J. Kautz, P.-P. Vázquez, W. Heidrich, H.-P. Seidel
Different methods for prefiltered environment maps have been proposed, each of which has different advantages and disadvantages. We present a general notation for prefiltered environment maps, which will be used to classify and compare the existing methods. Based on that knowledge we develop three new algorithms: 1. A fast hierarchical prefiltering method that can be utilized for all previously proposed prefiltered environment maps. 2. A technique for hardware-accelerated prefiltering of environment maps that achieves interactive rates even on low-end workstations. 3. Anisotropic environment maps using the Banks model.
GRAPHICS INTERFACE
Approximation of Glossy Reflection with Prefiltered Environment Maps
A method is presented that can render glossy reflections with arbitrary isotropic bidirectional reflectance distribution functions (BRDFs) at interactive rates using texture mapping. This method is based on the well-known environment map technique for specular reflections. Our approach uses a single- or multilobe representation of bidirectional reflectance distribution functions, where the shape of each radially symmetric lobe is also a function of view elevation. This approximate representation can be computed efficiently using local greedy fitting techniques. Each lobe is used to filter specular environment maps during a preprocessing step, resulting in a three-dimensional environment map. For many BRDFs, simplifications using lower-dimensional approximations, coarse sampling with respect to view elevation, and small numbers of lobes can still result in a convincing approximation to the true surface reflectance.
1999
EGWR
Interactive Rendering with Arbitrary BRDFs using Separable Approximations
A separable decomposition of bidirectional reflectance distributions (BRDFs) is used to implement arbitrary reflectances from point sources on existing graphics hardware. Two-dimensional texture mapping and compositing operations are used to reconstruct samples of the BRDF at every pixel at interactive rates. A change of variables, the Gram-Schmidt halfangle/difference vector parameterization, improves separability. Two decomposition algorithms are also presented. The singular value decomposition (SVD) minimizes RMS error. The normalized decomposition is fast and simple, using no more space than what is required for the final representation.
Complex luminaries and lamp geometries can greatly increase the realism of synthetic images. Unfortunately, the correct rendering of illumination from complex lamps requires costly global illumination algorithms to simulate the indirect illumination re- flected or refracted by parts of the lamp. Currently, this simulation has to be repeated for every scene in which a lamp is to be used, and even for multiple instances of a lamp within a single scene. In this paper, we separate the global illumination simulation of the interior lamp geometry from the actual scene rendering. The lightfield produced by a given lamp is computed using any of the known global illumination algorithms. Afterwards, a discretized version of this lightfield is stored away for later use as a lightsource. We describe how this data can be efficiently utilized to illuminate a given scene using a number of different rendering algorithms, such as ray-tracing and hardware-based rendering.
CV
oct 2018
Vice President of Learning and Perception Research, NVIDIA, USA
Head of the learning and perception research group at NVIDIA.
apr 2017
Senior Director of Visual Computing and Machine Learning Research, NVIDIA, USA
oct 2015
Director of Visual Computing Research, NVIDIA, USA
oct 2014
Senior Research Manager, NVIDIA, USA
Head of the visual computing research group at NVIDIA.
sep 2013
Senior Research Scientist, NVIDIA, USA
Research in comp. photography and computer vision.
oct 2012
Professor of Visual Computing, University College London, UK
oct 2011
Associate Professor (Reader), University College London, UK
oct 2009
Associate Professor (Senior Lecturer), University College London, UK
mar 2006
Assistant Professor (Lecturer), University College London, UK
Research in visual computing, teaching and supervision of students (BSc, MSc, PhD).
jul 2003
Post-Doctoral Researcher, Massachusetts Institute of Technology, USA
Working on appearance editing and realistic, real-time rendering.