In this Lucene tutorial, we will learn to use RAMDirectory to run quick examples of POCs because it is not intended to work with huge indexes. Please note that it also has bad concurrent behavior in multi-threaded environments.
The RAMDirectory was deprecated in 8.2.0 (in favor of ByteBuffersDirectory) and later removed from Lucene 9.0.0.
1. Maven
Start with adding these Lucene dependencies. We are using Lucene 9.10.0 and Java 21.
<properties> <maven.compiler.source>21</maven.compiler.source> <maven.compiler.target>21</maven.compiler.target> <lucene.version>9.10.0</lucene.version> </properties> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analysis-common</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>${lucene.version}</version> </dependency>2. Writing Indexes in RAMDirectory
When compared to the Lucene example, most of the things will remain the same when we want to index the documents in RAM (in place of the directory location). We only need to change from FSDirectory to RAMDirectory.
//Create RAMDirectory instance RAMDirectory ramDir = new RAMDirectory(); //Builds an analyzer with the default stop words Analyzer analyzer = new StandardAnalyzer(); try { // IndexWriter Configuration IndexWriterConfig iwc = new IndexWriterConfig(analyzer); iwc.setOpenMode(OpenMode.CREATE); //IndexWriter writes new index files to the directory IndexWriter writer = new IndexWriter(ramDir, iwc); //Create some docs with name and content indexDoc(writer, "document-1", "hello world"); indexDoc(writer, "document-2", "hello happy world"); indexDoc(writer, "document-3", "hello happy world"); indexDoc(writer, "document-4", "hello hello world"); //don't forget to close the writer writer.close(); } catch (IOException e) { //Any error goes here e.printStackTrace(); } static void indexDoc(IndexWriter writer, String name, String content) throws IOException { Document doc = new Document(); doc.add(new TextField("name", name, Store.YES)); doc.add(new TextField("content", content, Store.YES)); writer.addDocument(doc); }3. Searching Indexes in RAMDirectory
To search index from RAM:
- Create IndexReader using DirectoryReader.open(RAMDirectory).
- Use the reader to create an IndexSearcher instance.
- Use ‘searcher.search(query, int)‘ to search indexed docs.
//Create RAMDirectory instance RAMDirectory ramDir = new RAMDirectory(); //Builds an analyzer with the default stop words Analyzer analyzer = new StandardAnalyzer(); IndexReader reader = null; try { //Create Reader reader = DirectoryReader.open(ramDir); //Create index searcher IndexSearcher searcher = new IndexSearcher(reader); //Build query QueryParser qp = new QueryParser("content", analyzer); Query query = qp.parse("happy"); //Search the index TopDocs foundDocs = searcher.search(query, 10); // Total found documents System.out.println("Total Results :: " + foundDocs.totalHits); //Let's print found doc names and their content along with score for (ScoreDoc sd : foundDocs.scoreDocs) { Document d = searcher.doc(sd.doc); System.out.println("Document Name : " + d.get("name") + " :: Content : " + d.get("content") + " :: Score : " + sd.score); } //don't forget to close the reader reader.close(); } catch (IOException | ParseException e) { //Any error goes here e.printStackTrace(); }4. Complete Example
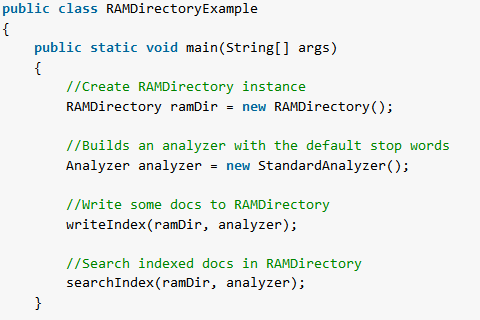
This is the complete source code of RAMDirectoryan example which first – index 4 docs with some content, second – search docs based on query.
package com.howtodoinjava.demo.lucene.misc; import java.io.IOException; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexWriterConfig.OpenMode; import org.apache.lucene.queryparser.classic.ParseException; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.RAMDirectory; public class RAMDirectoryExample { public static void main(String[] args) { //Create RAMDirectory instance RAMDirectory ramDir = new RAMDirectory(); //Builds an analyzer with the default stop words Analyzer analyzer = new StandardAnalyzer(); //Write some docs to RAMDirectory writeIndex(ramDir, analyzer); //Search indexed docs in RAMDirectory searchIndex(ramDir, analyzer); } static void writeIndex(RAMDirectory ramDir, Analyzer analyzer) { try { // IndexWriter Configuration IndexWriterConfig iwc = new IndexWriterConfig(analyzer); iwc.setOpenMode(OpenMode.CREATE); //IndexWriter writes new index files to the directory IndexWriter writer = new IndexWriter(ramDir, iwc); //Create some docs with name and content indexDoc(writer, "document-1", "hello world"); indexDoc(writer, "document-2", "hello happy world"); indexDoc(writer, "document-3", "hello happy world"); indexDoc(writer, "document-4", "hello hello world"); //don't forget to close the writer writer.close(); } catch (IOException e) { //Any error goes here e.printStackTrace(); } } static void indexDoc(IndexWriter writer, String name, String content) throws IOException { Document doc = new Document(); doc.add(new TextField("name", name, Store.YES)); doc.add(new TextField("content", content, Store.YES)); writer.addDocument(doc); } static void searchIndex(RAMDirectory ramDir, Analyzer analyzer) { IndexReader reader = null; try { //Create Reader reader = DirectoryReader.open(ramDir); //Create index searcher IndexSearcher searcher = new IndexSearcher(reader); //Build query QueryParser qp = new QueryParser("content", analyzer); Query query = qp.parse("happy"); //Search the index TopDocs foundDocs = searcher.search(query, 10); // Total found documents System.out.println("Total Results :: " + foundDocs.totalHits); //Let's print found doc names and their content along with score for (ScoreDoc sd : foundDocs.scoreDocs) { Document d = searcher.doc(sd.doc); System.out.println("Document Name : " + d.get("name") + " :: Content : " + d.get("content") + " :: Score : " + sd.score); } //don't forget to close the reader reader.close(); } catch (IOException | ParseException e) { //Any error goes here e.printStackTrace(); } } }Output:
Total Results :: 2 Document Name : document-2 :: Content : hello happy world :: Score : 0.58446556 Document Name : document-3 :: Content : hello happy world :: Score : 0.58446556Drop me your questions in the comments section.
Happy Learning !!
Comments