
data-diff is a free, open-source tool that enables data professionals to detect differences in values between any two tables. It's fast, easy to use, and reliable. Even at massive scale.


pip install data-diff -
pip install 'data-diff[mysql]' -
pip install 'data-diff[postgresql]' -
pip install 'data-diff[snowflake]' -
pip install 'data-diff[presto]' -
pip install 'data-diff[oracle]' -
pip install 'data-diff[trino]' -
pip install 'data-diff[clickhouse]' -
pip install 'data-diff[vertica]' -
For BigQuery, see: https://pypi.org/project/google-cloud-bigquery/
Some drivers have dependencies that cannot be installed using pip and still need to be installed manually.
Once you've installed data-diff, you can run it from the command line.
data-diff DB1_URI TABLE1_NAME DB2_URI TABLE2_NAME [OPTIONS] Be sure to read the How to Use section below which gets into specific details about how to build one of these commands depending on your database setup.
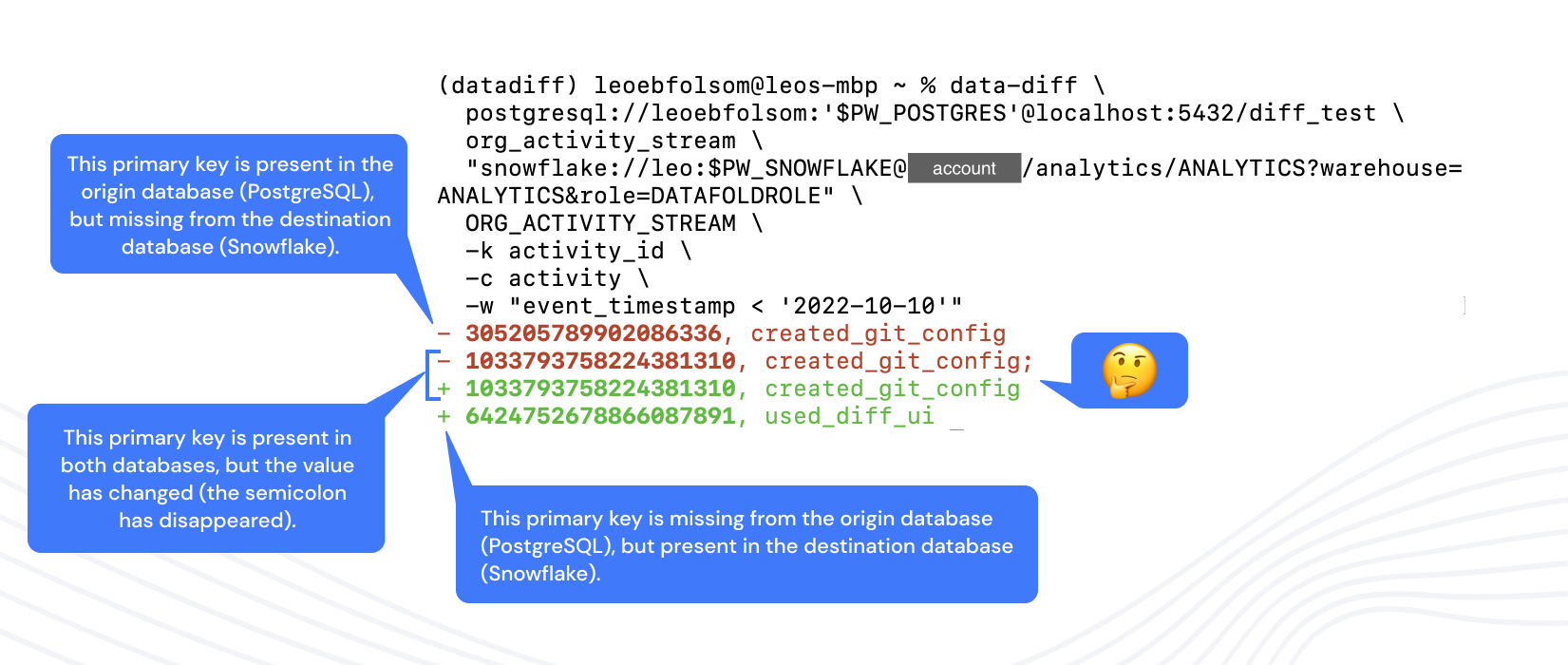
Here's an example command for your copy/pasting, taken from the screenshot above when we diffed data between Snowflake and Postgres.
data-diff \ postgresql://<username>:'<password>'@localhost:5432/<database> \ <table> \ "snowflake://<username>:<password>@<password>/<DATABASE>/<SCHEMA>?warehouse=<WAREHOUSE>&role=<ROLE>" \ <TABLE> \ -k activity_id \ -c activity \ -w "event_timestamp < '2022-10-10'" And here's a code example from the video, where we compare data between two Snowflake tables within one database.
data-diff \ "snowflake://<username>:<password>@<password>/<DATABASE>/<SCHEMA_1>?warehouse=<WAREHOUSE>&role=<ROLE>" <TABLE_1> \ <SCHEMA_2>.<TABLE_2> \ -k org_id \ -c created_at -c is_internal \ -w "org_id != 1 and org_id < 2000" \ -m test_results_%t \ --materialize-all-rows \ --table-write-limit 10000 In both code examples, I've used <> carrots to represent values that should be replaced with your values in the database connection strings. For the flags (-k, -c, etc.), I opted for "real" values (org_id, is_internal) to give you a more realistic view of what your command will look like.
We know, that data-diff DB1_URI TABLE1_NAME DB2_URI TABLE2_NAME [OPTIONS] command can become long and dense. And maybe you're new to the command line.
We're here to help on slack if you have ANY questions as you use data-diff in your workflow.
To run data-diff from the command line, run this command:
data-diff DB1_URI TABLE1_NAME DB2_URI TABLE2_NAME [OPTIONS]
Let's break this down. Assume there are two tables stored in two databases, and you want to know the differences between those tables.
DB1_URIwill be a string thatdata-diffuses to connect to the database where the first table is stored.TABLE1_NAMEis the name of the table in theDB1_URIdatabase.DB2_URIwill be a string thatdata-diffuses to connect to the database where the second table is stored.TABLE2_NAMEis the name of the second table in theDB2_URIdatabase.[OPTIONS]can be replaced with a variety of additional commands, detailed here.
| Database | Connection string | Status |
|---|---|---|
| PostgreSQL >=10 | postgresql://<user>:'<password>'@<host>:5432/<database> | 💚 |
| MySQL | mysql://<user>:<password>@<hostname>:5432/<database> | 💚 |
| Snowflake | With password:"snowflake://<USER>:<password>@<ACCOUNT>/<DATABASE>/<SCHEMA>?warehouse=<WAREHOUSE>&role=<ROLE>"With SSO: "snowflake://<USER>@<ACCOUNT>/<DATABASE>/<SCHEMA>?warehouse=<WAREHOUSE>&role=<ROLE>&authenticator=externalbrowser"Note: Unless something is explicitly case sensitive (like your password) use all caps. | 💚 |
| BigQuery | bigquery://<project>/<dataset> | 💚 |
| Redshift | redshift://<username>:<password>@<hostname>:5439/<database> | 💚 |
| Oracle | oracle://<username>:<password>@<hostname>/database | 💛 |
| Presto | presto://<username>:<password>@<hostname>:8080/<database> | 💛 |
| Databricks | databricks://<http_path>:<access_token>@<server_hostname>/<catalog>/<schema> | 💛 |
| Trino | trino://<username>:<password>@<hostname>:8080/<database> | 💛 |
| Clickhouse | clickhouse://<username>:<password>@<hostname>:9000/<database> | 💛 |
| Vertica | vertica://<username>:<password>@<hostname>:5433/<database> | 💛 |
| ElasticSearch | 📝 | |
| Planetscale | 📝 | |
| Pinot | 📝 | |
| Druid | 📝 | |
| Kafka | 📝 | |
| DuckDB | 📝 | |
| SQLite | 📝 |
- 💚: Implemented and thoroughly tested.
- 💛: Implemented, but not thoroughly tested yet.
- ⏳: Implementation in progress.
- 📝: Implementation planned. Contributions welcome.
If a database is not on the list, we'd still love to support it. Open an issue to discuss it.
Note: Because URLs allow many special characters, and may collide with the syntax of your command-line, it's recommended to surround them with quotes. Alternatively, you may provide them in a TOML file via the --config option.
--help- Show help message and exit.-kor--key-columns- Name of the primary key column. If none provided, default is 'id'.-tor--update-column- Name of updated_at/last_updated column-cor--columns- Names of extra columns to compare. Can be used more than once in the same command. Accepts a name or a pattern like in SQL. Example:-c col% -c another_col -c %foorb.r%-lor--limit- Maximum number of differences to find (limits maximum bandwidth and runtime)-sor--stats- Print stats instead of a detailed diff-dor--debug- Print debug info-vor--verbose- Print extra info-ior--interactive- Confirm queries, implies--debug--json- Print JSONL output for machine readability--min-age- Considers only rows older than specified. Useful for specifying replication lag. Example:--min-age=5minignores rows from the last 5 minutes. Valid units:d, days, h, hours, min, minutes, mon, months, s, seconds, w, weeks, y, years--max-age- Considers only rows younger than specified. See--min-age.-jor--threads- Number of worker threads to use per database. Default=1.-w,--where- An additional 'where' expression to restrict the search space.--conf,--run- Specify the run and configuration from a TOML file. (see below)--no-tracking- data-diff sends home anonymous usage data. Use this to disable it.
The following two options are not available when using the beta release In-DB feature:
--bisection-threshold- Minimal size of segment to be split. Smaller segments will be downloaded and compared locally.--bisection-factor- Segments per iteration. When set to 2, it performs binary search.
In-DB commands, available in beta release only:
-m,--materialize- Materialize the diff results into a new table in the database. If a table exists by that name, it will be replaced. Use%tin the name to place a timestamp. Example:-m test_mat_%t--assume-unique-key- Skip validating the uniqueness of the key column during joindiff, which is costly in non-cloud dbs.--sample-exclusive-rows- Sample several rows that only appear in one of the tables, but not the other. Use with-s.--materialize-all-rows- Materialize every row, even if they are the same, instead of just the differing rows.--table-write-limit- Maximum number of rows to write when creating materialized or sample tables, per thread. Default=1000.-a,--algorithm[auto|joindiff|hashdiff]- Force algorithm choice
Data-diff lets you load the configuration for a run from a TOML file.
Reasons to use a configuration file:
-
Convenience: Set-up the parameters for diffs that need to run often
-
Easier and more readable: You can define the database connection settings as config values, instead of in a URI.
-
Gives you fine-grained control over the settings switches, without requiring any Python code.
Use --conf to specify that path to the configuration file. data-diff will load the settings from run.default, if it's defined.
Then you can, optionally, use --run to choose to load the settings of a specific run, and override the settings run.default. (all runs extend run.default, like inheritance).
Finally, CLI switches have the final say, and will override the settings defined by the configuration file, and the current run.
Example TOML file:
# Specify the connection params to the test database. [database.test_postgresql] driver = "postgresql" user = "postgres" password = "Password1" # Specify the default run params [run.default] update_column = "timestamp" verbose = true # Specify params for a run 'test_diff'. [run.test_diff] verbose = false # Source 1 ("left") 1.database = "test_postgresql" # Use options from database.test_postgresql 1.table = "rating" # Source 2 ("right") 2.database = "postgresql://postgres:Password1@/" # Use URI like in the CLI 2.table = "rating_del1"In this example, running data-diff --conf myconfig.toml --run test_diff will compare between rating and rating_del1. It will use the timestamp column as the update column, as specified in run.default. However, it won't be verbose, since that flag is overwritten to false.
Running it with data-diff --conf myconfig.toml --run test_diff -v will set verbose back to true.
API reference: https://data-diff.readthedocs.io/en/latest/
Example:
# Optional: Set logging to display the progress of the diff import logging logging.basicConfig(level=logging.INFO) from data_diff import connect_to_table, diff_tables table1 = connect_to_table("postgresql:///", "table_name", "id") table2 = connect_to_table("mysql:///", "table_name", "id") for different_row in diff_tables(table1, table2): plus_or_minus, columns = different_row print(plus_or_minus, columns)Run help(diff_tables) or read the docs to learn about the different options.
- Open an issue or chat with us on slack.
- Interested in contributing to this open source project? Please see our Contributing Guideline!
- Did we mention we're hiring?
data-diff collects anonymous usage data to help our team improve the tool and to apply development efforts to where our users need them most.
We capture two events: one when the data-diff run starts, and one when it is finished. No user data or potentially sensitive information is or ever will be collected. The captured data is limited to:
- Operating System and Python version
- Types of databases used (postgresql, mysql, etc.)
- Sizes of tables diffed, run time, and diff row count (numbers only)
- Error message, if any, truncated to the first 20 characters.
- A persistent UUID to indentify the session, stored in
~/.datadiff.toml
If you do not wish to participate, the tracking can be easily disabled with one of the following methods:
- In the CLI, use the
--no-trackingflag. - In the config file, set
no_tracking = true(for example, under[run.default]) - If you're using the Python API:
import data_diff data_diff.disable_tracking() # Call this first, before making any API calls # Connect and diff your tables without any trackingThis project is licensed under the terms of the MIT License.