|
| 1 | +# 01-B 站评论系统架构设计难点 |
| 2 | + |
| 3 | +原文链接:https://mp.weixin.qq.com/s/s99ZWuSi0Lu6ivfpBHvLWQ |
| 4 | + |
| 5 | +这里整理一下在哔哩哔哩技术公众号看到的 B 站评论系统的架构设计文章,自己在学习过程中,对其中感觉比较有帮助的点做一下整理,方便以后查阅,详细版可以点击上方原文链接查看(文中图片均来源于原文) |
| 6 | + |
| 7 | + |
| 8 | + |
| 9 | +## 架构设计 |
| 10 | + |
| 11 | +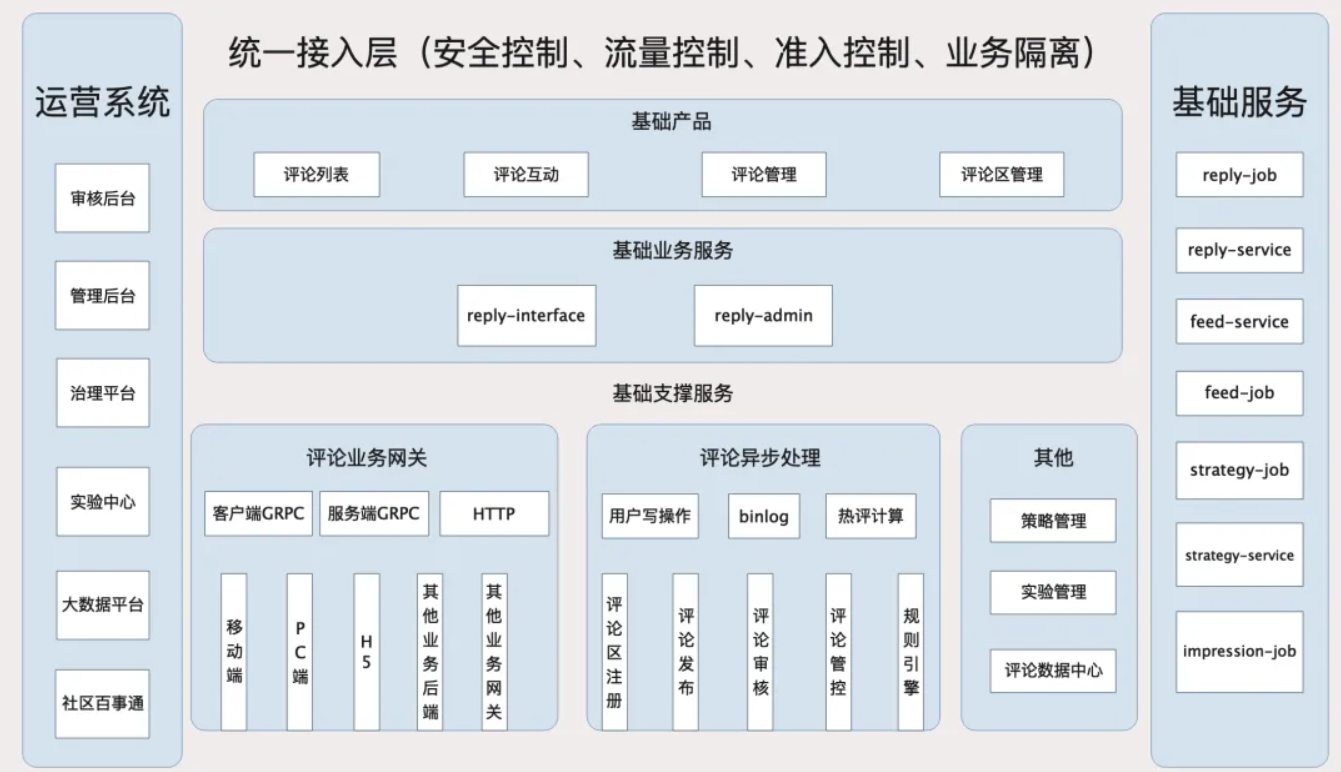 |
| 12 | + |
| 13 | + |
| 14 | + |
| 15 | +在评论业务中,最为核心的功能是 **发布类接口** 和 **列表类接口** ,数据字段多、依赖服务多、调用关系复杂,因此容易造成系统腐化 |
| 16 | + |
| 17 | + |
| 18 | + |
| 19 | +### 接口解耦 |
| 20 | + |
| 21 | +这里在设计的时候,将整个业务数据的查询分为了两个步骤:服务编排、数据组装 |
| 22 | + |
| 23 | +举个例子:在批量查询评论发布人的粉丝勋章数据之后,将其转换、组装到各个评论卡片中 |
| 24 | + |
| 25 | +如果不采用这样的方式,而是在查询评论卡片时,再去查询该评论发布人的粉丝勋章数据,那么会导致【查询评论】和【查询发布人粉丝勋章数据】这两个接口耦合度过高的情况,一旦【查询粉丝勋章数据】接口出现了不可用,会导致【查询评论】功能也会不可用 |
| 26 | + |
| 27 | +因此先【查询粉丝勋章数据】,再将数据拼接到评论卡片中,降低两个接口的耦合度,将两个接口之间的强依赖关系变为弱依赖关系,并且可以针对两个接口做 **不同的降级、限流、超时控制** |
| 28 | + |
| 29 | + |
| 30 | + |
| 31 | +### 基础服务 reply-service |
| 32 | + |
| 33 | +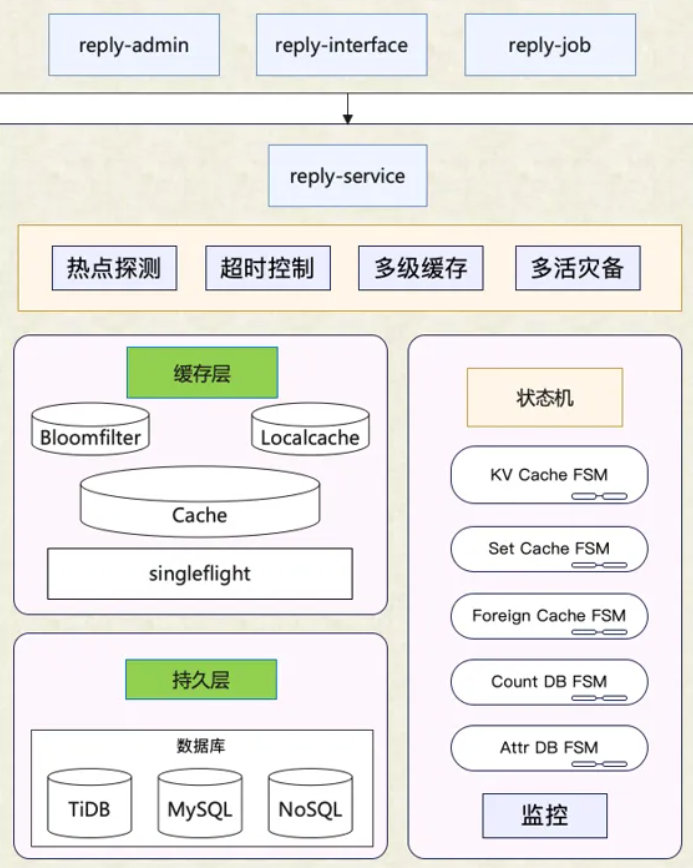 |
| 34 | + |
| 35 | +评论基础服务层(reply-service)专注于评论功能的原子化实现,也是最小粒度的功能,如查询评论、删除评论等功能 |
| 36 | + |
| 37 | +该层的接口是需要被其他业务层进行大量调用与业务逻辑组合,因此该层的接口需要保证较高的 **可用性和性能** |
| 38 | + |
| 39 | +因此会集成 **多级缓存、热点探测、布隆过滤器** 等性能优化手段 |
| 40 | + |
| 41 | + |
| 42 | + |
| 43 | +### 异步处理 reply-job |
| 44 | + |
| 45 | +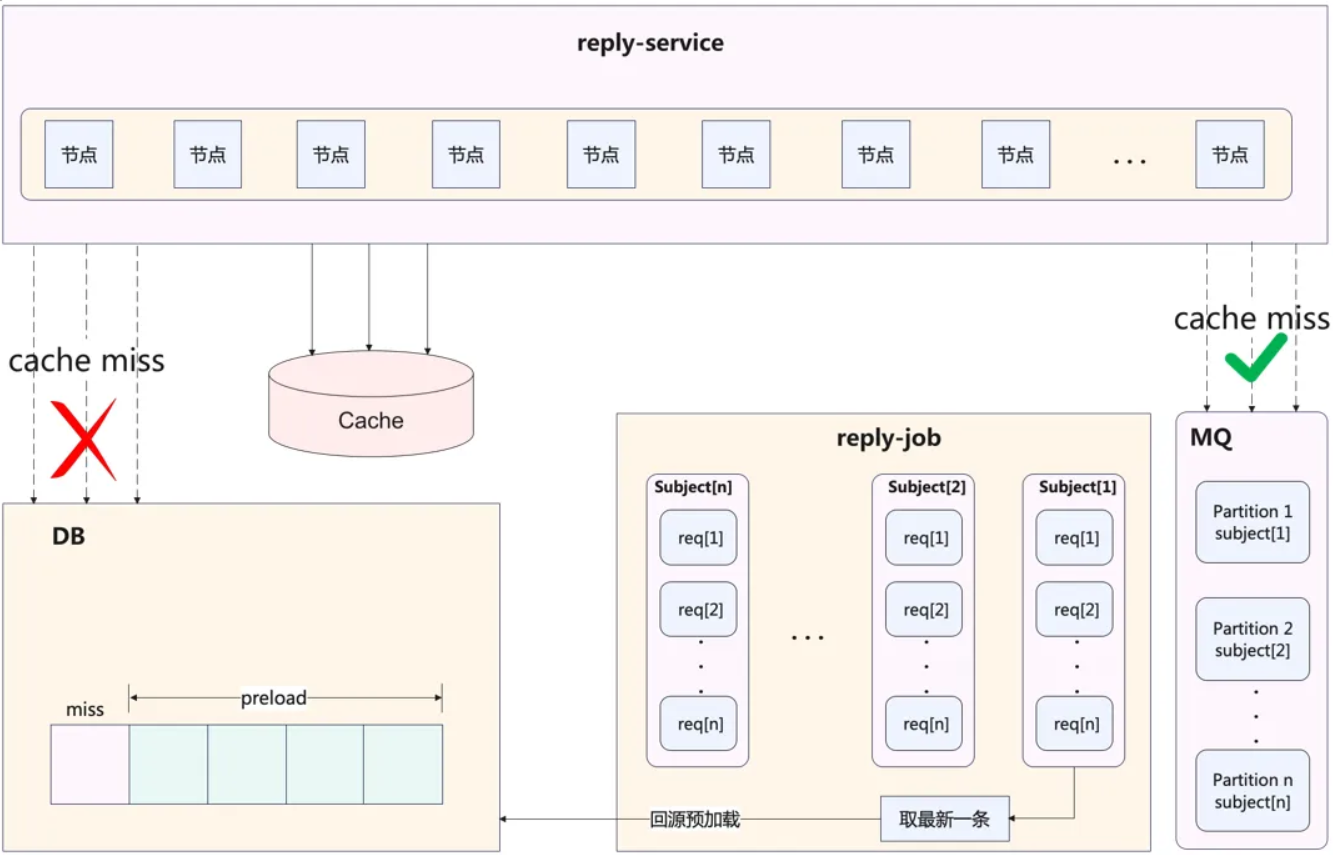 |
| 46 | + |
| 47 | +异步处理层 reply-job 主要作用就是为评论基础功能做一些架构上的补充 |
| 48 | + |
| 49 | +#### 缓存更新 |
| 50 | + |
| 51 | +缓存更新经常采用的 **缓存旁路模式(Cache Aside)** ,即先读缓存,再读 DB,之后进行缓存的重建 |
| 52 | + |
| 53 | +**存在的问题:** 部分缓存数据重建代价较高,比如评论列表(评论列表是分页的,重建时会预加载,加载多页的数据),那么如果短时间内大量请求未命中,就会导致 DB 瞬时压力过大,造成 DB 抖动 |
| 54 | + |
| 55 | +**解决方案:** 采用消息队列,保证对单个评论列表,只重建一次缓存 |
| 56 | + |
| 57 | +reply-job 的另外一个作用:作为数据库 bin log 的消费者,执行缓存的更新操作 |
| 58 | + |
| 59 | + |
| 60 | + |
| 61 | +#### 削峰/异步化处理 |
| 62 | + |
| 63 | +reply-job 还负责与 reply-interface 协同,为一些长耗时/高吞吐的调用进行 **异步化/削峰** 处理 |
| 64 | + |
| 65 | +比如:**评论发布功能** ,在发布之前,基于安全/策略考量,会有很多前置调用逻辑,导致耗时很长 |
| 66 | + |
| 67 | +因此 reply-interface 在处理完一些必要校验逻辑之后,再通过 **消息队列** 送至 reply-job 进行异步处理,包括送审、写 DB、发通知等 |
| 68 | + |
| 69 | +这里需要保证单个评论区内的发布评论 **串行** 处理,如果并行处理可能会出现一些数据错乱的风险,因此为了保证串行处理就利用到了 **消息队列的有序性** |
| 70 | + |
| 71 | + |
| 72 | + |
| 73 | +## 存储设计 |
| 74 | + |
| 75 | +### 数据库设计 |
| 76 | + |
| 77 | +评论功能主要是三张表:评论表+评论区表+评论内容表 |
| 78 | + |
| 79 | +因为评论内容的大字段,相对独立,很少修改,因此独立设计成一张表(评论内容表) |
| 80 | + |
| 81 | +**数据库选型:** |
| 82 | + |
| 83 | +刚开始使用 MySQL 分表来实现评论功能,但是很快达到存储瓶颈,从 2020 年起,逐步迁移到 TiDB,从而具备了水平扩容能力 |
| 84 | + |
| 85 | + |
| 86 | + |
| 87 | + |
| 88 | + |
| 89 | +### 缓存设计 |
| 90 | + |
| 91 | +缓存选用 **Redis** ,主要缓存的信息: |
| 92 | + |
| 93 | +1、评论区的基础信息(redis string 类型,value 使用 JSON 序列化存入) |
| 94 | + |
| 95 | +2、查询 xxx 的评论列表(redis sorted set 类型,member 为评论 id,score 对应 order by 字段) |
| 96 | + |
| 97 | +3、查询 xxx 的评论基础信息(redis) |
| 98 | + |
| 99 | + |
| 100 | + |
| 101 | +缓存的一致性依赖于 binlog 刷新,有以下几处关键细节: |
| 102 | + |
| 103 | +1、binlog 投递到消息队列,需要保证单个评论区以及单个评论更新的 **串行化** (分片 key 选择评论区) |
| 104 | + |
| 105 | +2、数据库更新后,采用删除缓存而非直接更新的方式,避免并发写时的数据错乱 |
| 106 | + |
| 107 | +此时会存在大量写操作后, **读操作缓存命中率低的问题** ,利用 singleflight 进行控制,防止 **缓存击穿** |
| 108 | + |
| 109 | +(singleflight 是一种编程模式,用来防止在高并发环境下对于同一资源的重复请求,尤其适用于处理缓存击穿问题。缓存击穿指的是当缓存失效的瞬间,由于并发请求同一数据,导致大量请求直接落到数据库上,从而可能引起数据库的性能问题) |
| 110 | + |
| 111 | + |
| 112 | + |
| 113 | +## 可用性设计 |
| 114 | + |
| 115 | +### 写热点和读热点 |
| 116 | + |
| 117 | +上边有大量的评论区维度的串行操作,导致 **发布评论** 吞吐量较低,出现热点文章下发布大量评论,就会出现严重延迟 |
| 118 | + |
| 119 | +针对吞吐量低的问题,做出如下优化: |
| 120 | + |
| 121 | +1、评论区评论计数的更新:在内存中先合并再更新,减少热点场景下的 SQL 执行次数,评论表的插入也改为批量插入 **(合并是很常见的优化,对于一些实时性要求不强的场景,会将多条数据合并,比如达到几秒合并一次,或者达到多少条数据合并一次,之后通过一次 SQL 完成插入)** |
| 122 | + |
| 123 | +2、非数据库写操作的其他业务逻辑,将这些逻辑从【数据写入主线程】中剥离,交给其他线程并发执行 |
| 124 | + |
| 125 | +经过上述优化,热点评论区发布评论 TPS 提升了 10 倍以上 |
| 126 | + |
| 127 | +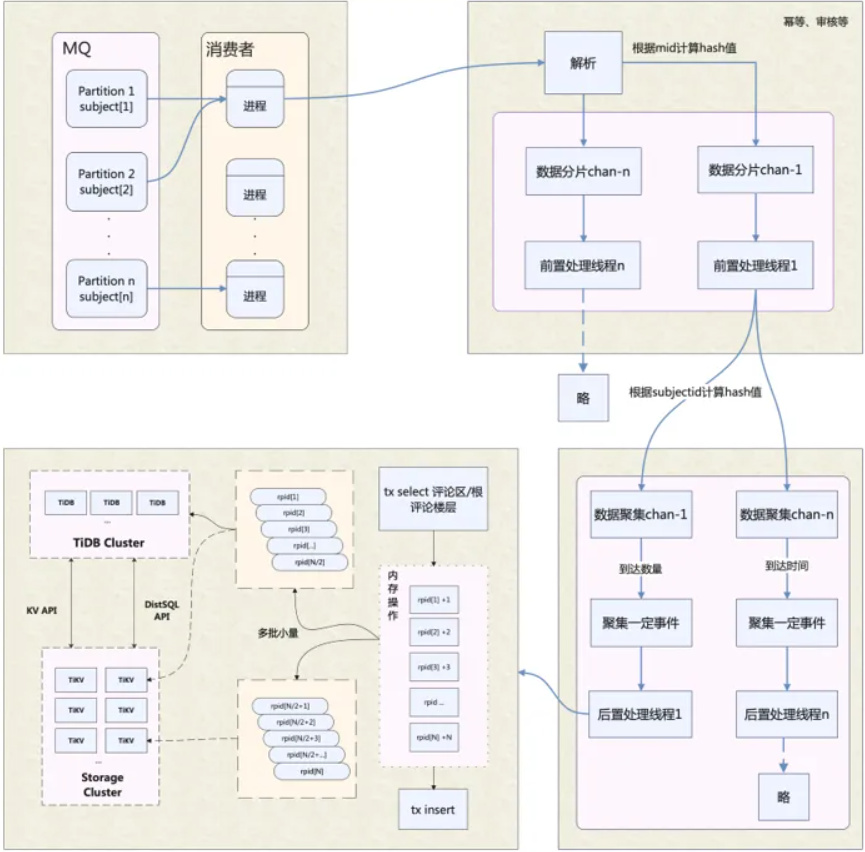 |
| 128 | + |
| 129 | + |
| 130 | + |
| 131 | +接下来说一下 **读热点问题** 中的典型特征: |
| 132 | + |
| 133 | +1、由于大量接口都需要读取评论区基础信息,存在读放大(在读取数据时,需要关联的读取其他大量数据即为读放大),因此该操作是最先感知到读热点存在的 |
| 134 | + |
| 135 | +2、评论业务下游依赖较多,因此对下游来说也是读放大,很多下游依赖是体量相对小的业务单元,难以承载大流量 |
| 136 | + |
| 137 | +3、读热点集中在评论列表的第一页,以及热评 |
| 138 | + |
| 139 | +4、评论列表的业务数据模型也包含部分个性化信息 |
| 140 | + |
| 141 | +基于以上特征, **读热点探测** 放在【读取评论区基础信息】阶段进行,探测到热点之后,在本地缓存中进行热点数据的读取 |
| 142 | + |
| 143 | +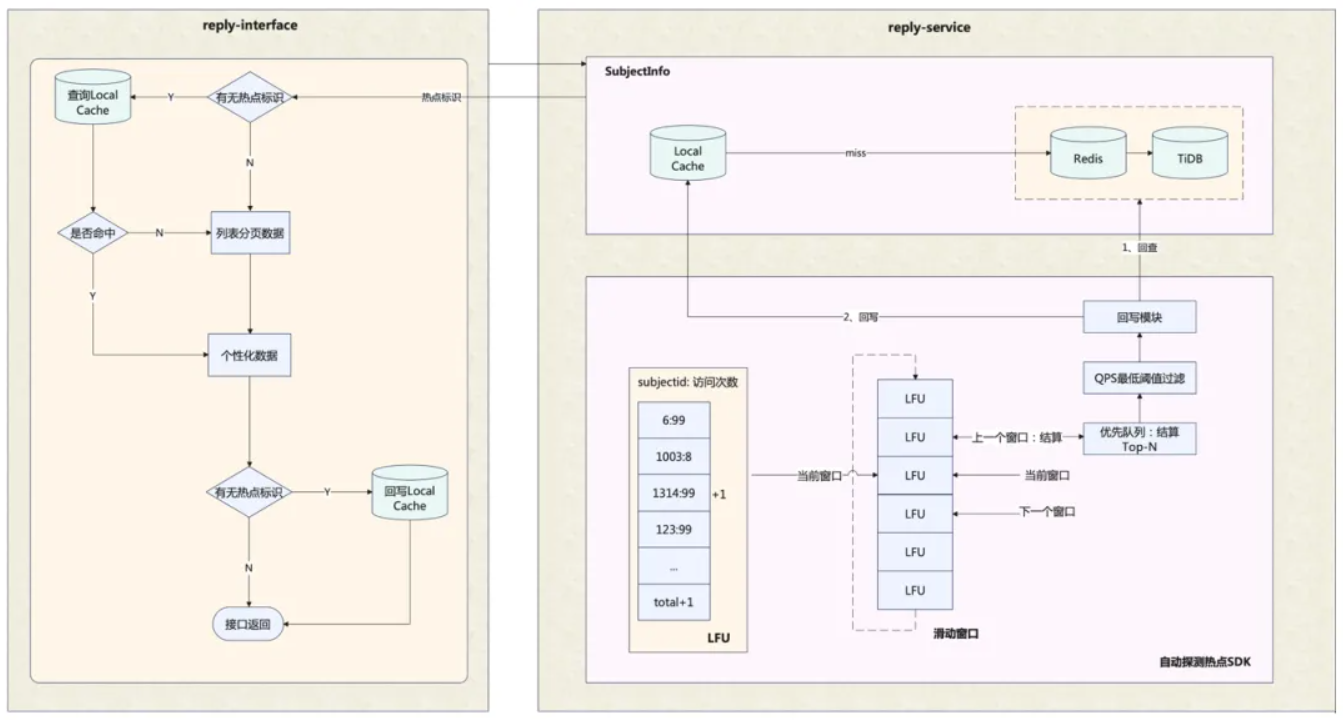 |
| 144 | + |
| 145 | + |
| 146 | + |
| 147 | +**热点探测** 的实现基于单机的滑动窗口+LFU,那么如何定义、计算相应的热点条件阈值呢? |
| 148 | + |
| 149 | +首先,我们进行系统容量设计,列出容量计算的数学公式,主要包括各接口QPS的关系、服务集群总QPS与节点数的关系、接口QPS与CPU/网络吞吐的关系等;然后,收集系统内部以及相应依赖方的一些的热点相关统计信息,通过前面列出的公式,计算出探测数据项的单机QPS热点阈值。最后通过热点压测,来验证相应的热点配置与代码实现是符合预期的。 |
| 150 | + |
| 151 | +> 扩展:LFU 和 LRU(Least Recently Used) 的区别: |
| 152 | +
|
| 153 | +**LRU** :LRU是另一种流行的缓存替换策略,它基于数据项的最近访问时间进行缓存管理,最近最少访问的数据项将被首先替换。这种策略假设最近使用过的数据将来很可能再次被使用。 |
| 154 | + |
| 155 | +**LFU** :与LRU基于时间的策略不同,LFU更关注数据项的访问频率。理论上,LFU能更好地识别并保留那些即使不是最近使用但访问频率高的长期热点数据。 |
| 156 | + |
| 157 | + |
| 158 | + |
| 159 | +### 冗余与降级 |
| 160 | + |
| 161 | +**冗余与降级是保证可用性必不可少的手段** |
| 162 | + |
| 163 | +上边的评论基础服务集成了 **多级缓存** ,那么在上一级缓存不可用时,要求可以降级至下一级缓存,保证功能的可用性 |
| 164 | + |
| 165 | +评论系统架构为同城读双活,数据库与缓存均是双机房独立部署的,均支持多副本,具备水平扩容的弹性。针对双机房架构下特有的副机房数据延迟故障,支持入口层切流/跨机房重试/应用层补偿,尽可能保证极端情况下用户无感。 |
| 166 | + |
| 167 | +在功能层面,我们做了重要级别划分,把相应的依赖划分为强依赖(如审核)、弱依赖(如粉丝勋章)。对于弱依赖,我们一方面在异常情况下坚决限流熔断,另一方面也通过超时控制、请求预过滤、优化调用编排甚至技术方案重构等方式持续优化提升非核心功能的可用性,为业务在评论区获得更好的曝光展现。 |
| 168 | + |
| 169 | + |
| 170 | + |
| 171 | +原文中还有一部分是关于 **热评的设计** ,即对于热评的存储、热评的查询、热评的排序如何进行设计,这一部分较为复杂,如果感兴趣可以查看原文第 7 部分:热评设计 |
| 172 | + |
0 commit comments