|
| 1 | +# ES深分页问题解决方案 |
| 2 | + |
| 3 | +## 1 背景 |
| 4 | + |
| 5 | +某日,在工位摸鱼时,突然收到生产的方法性能监控报警: |
| 6 | + |
| 7 | + |
| 8 | + |
| 9 | +立马查看报警接口的线上监控: |
| 10 | + |
| 11 | +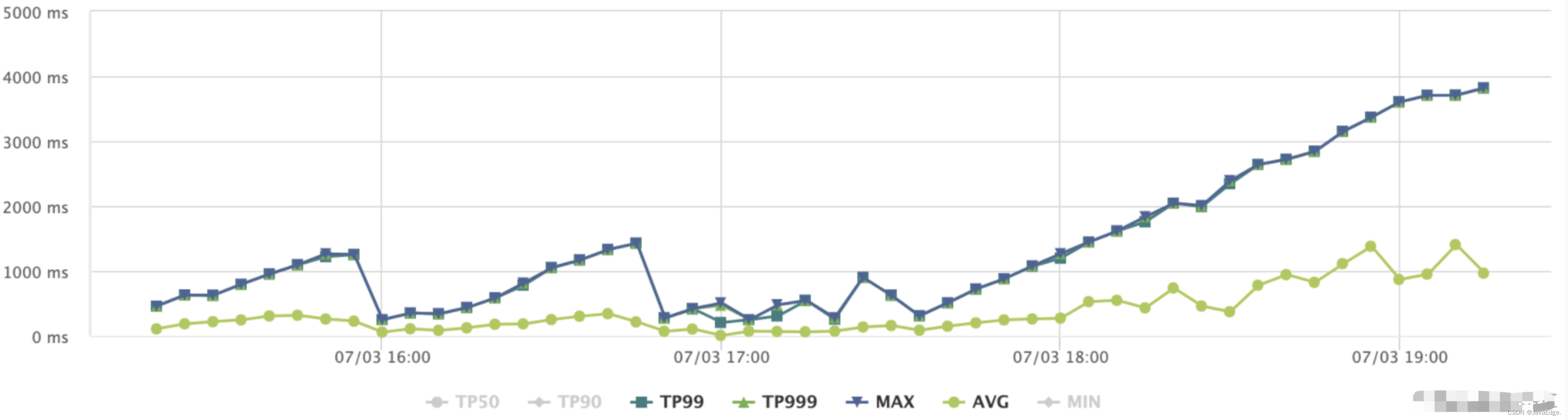 |
| 12 | + |
| 13 | +可观察到:接口几乎不可用,继续查看接口内部方法的监控,包括 HBASE、ES 等相关内部调用方法的监控,定位造成接口性能异常的具体方法。发现除 ES 方法性能异常外,其他方法的监控性能都正常。 |
| 14 | + |
| 15 | +继续查看ES监控: |
| 16 | + |
| 17 | +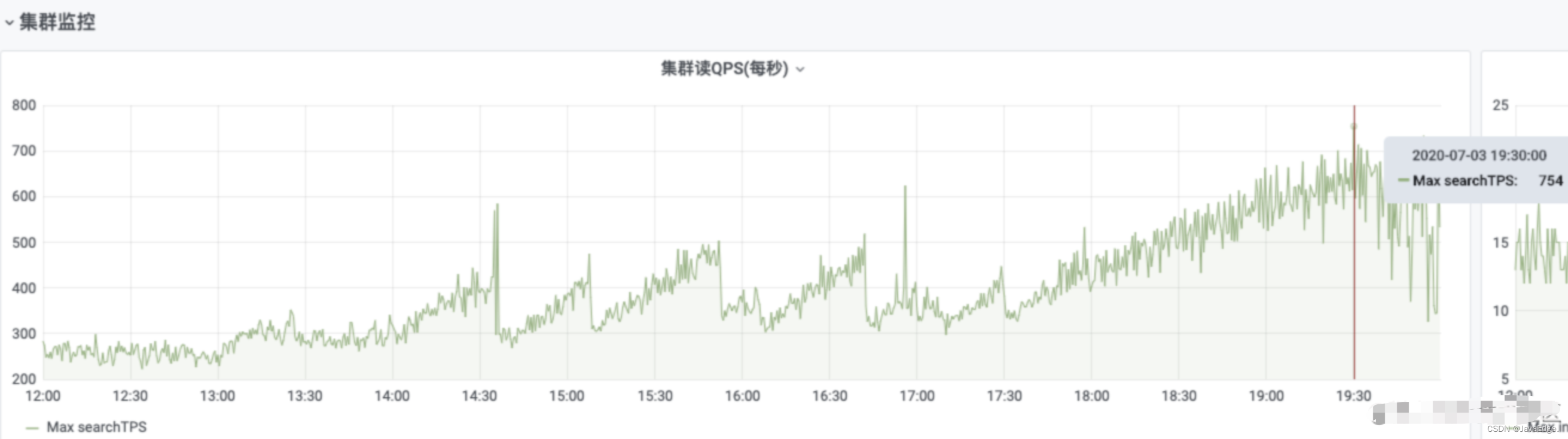 |
| 18 | + |
| 19 | +- ES监控(QPS、CPU、内存等指数异常升高几倍) |
| 20 | +- 初步定位ES异常,ES相关方法代码主要在做分页检索,猜测存在深分页问题,继续排查日志 |
| 21 | +- 日志情况(被刷到 1000 多页),通过日志最终定位到异常原因:有人在不停发起翻页请求,但接口未做保护限制,导致线上接口性能超时严重 |
| 22 | + |
| 23 | +## 2 ES深分页解决方案 |
| 24 | + |
| 25 | +### 2.1 业务限制 |
| 26 | + |
| 27 | +`限制翻页数(page)为 100 页,后续不再提供检索`,这是业内最常用方法,简单有效。 |
| 28 | + |
| 29 | +- 通常认为 100 页后的检索内容对检索者参考意义不大 |
| 30 | +- 考虑到除了恶意请求,应该不会有翻到 100 页没有找到检索内容还依然要检索的 |
| 31 | + |
| 32 | +### 2.2 ES自身方案 |
| 33 | + |
| 34 | +## 3 ES查询的方式 |
| 35 | + |
| 36 | +### 3.1 from + size **方式** |
| 37 | + |
| 38 | +一个最基本的 ES 查询语句: |
| 39 | + |
| 40 | +```bash |
| 41 | +POST /my_index/my_type/_search |
| 42 | +{ |
| 43 | + "query": { "match_all": {}}, |
| 44 | + "from": 100, |
| 45 | + "size": 10 |
| 46 | +} |
| 47 | +复制代码 |
| 48 | +``` |
| 49 | +
|
| 50 | +从搜索结果中取第 100 条开始的 10 条数据,该查询语句在 ES 集群内部如何执行?ES中搜索一般包括两阶段,**`query`** 、 **`fetch`**,query 阶段确定要取哪些 doc(ids),fetch 阶段取出具体的 doc。 |
| 51 | +
|
| 52 | +#### Query 阶段 |
| 53 | +
|
| 54 | +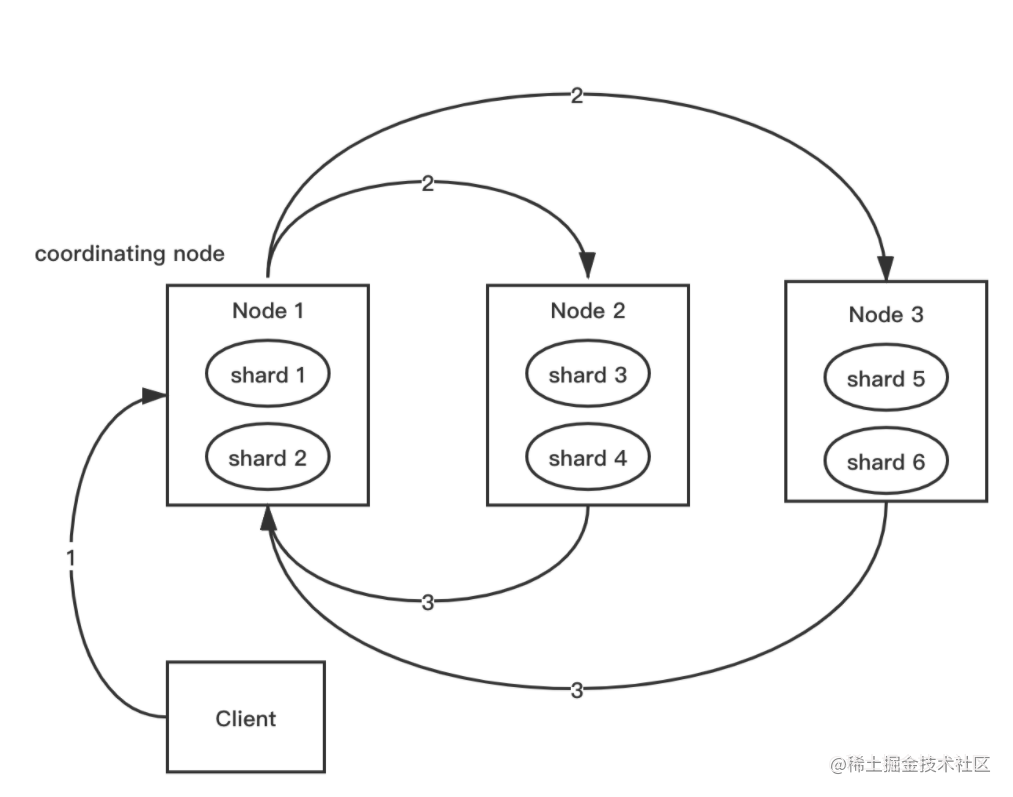 |
| 55 | +
|
| 56 | +该图描述了一次搜索请求的 query 阶段: |
| 57 | +
|
| 58 | +- Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为 from + size 的优先级队列存结果,管 node1 叫 **`coordinating node`** |
| 59 | +- coordinating node 将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为 from + size 的优先级队列 |
| 60 | +- 每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各shards 返回的结果后对结果进行合并,产生一个全局的优先级队列,存到自身的优先级队列里 |
| 61 | +- 案例中coordinating node 拿到 (from + size) * 6 条数据,然后合并并排序后选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。各分片返给 coordinating node 的数据用于选出前 from + size 条数据,所以,只需返回 **`唯一标记 doc 的 _id`** 以及 **`用于排序的 _score`** ,保证返回的数据量足够小 |
| 62 | +- coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段 |
| 63 | +
|
| 64 | +#### Fetch 阶段 |
| 65 | +
|
| 66 | +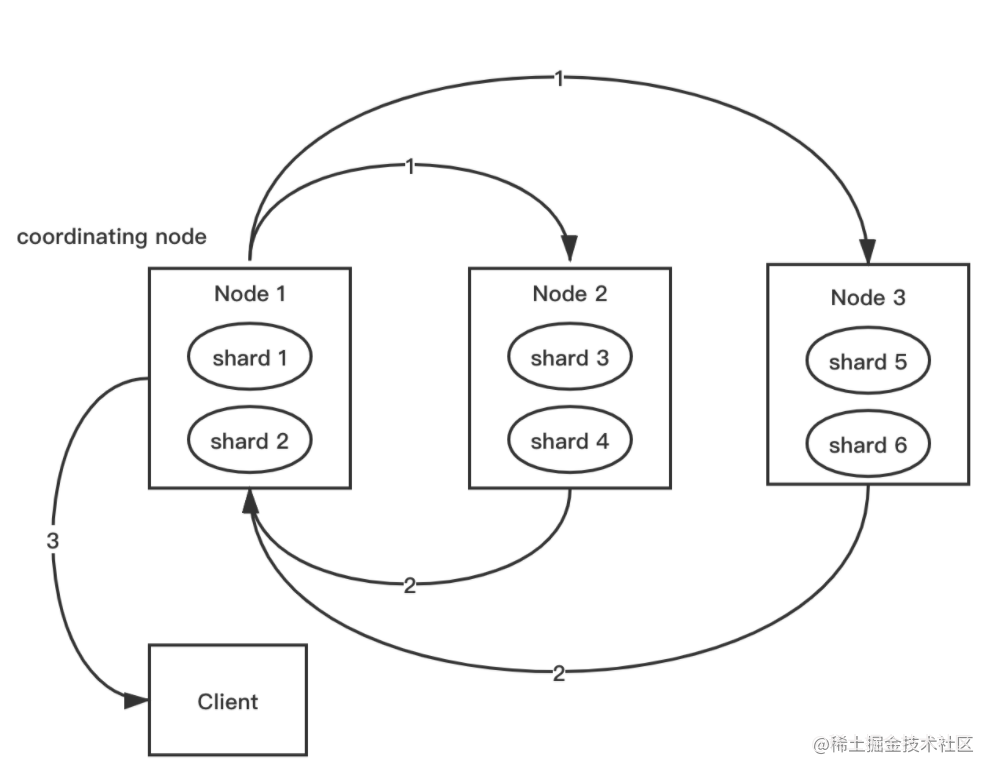 |
| 67 | +
|
| 68 | +该图展示 fetch 过程: |
| 69 | +
|
| 70 | +- coordinating node 发送 GET 请求到相关 shards |
| 71 | +- shard 根据 doc 的 _id 取到数据详情,然后返给 coordinating node |
| 72 | +- coordinating node 返回数据给 Client |
| 73 | +- coordinating node 的优先级队列有 from + size 个 _doc _id,但fetch 阶段**`并不需要取回所有数据`**,案例的前100条数据不需要取,只需取优先级队列里的第101到110条数据 |
| 74 | +- 要取的数据可能在不同分片,也可能同一分片,coordinating node 使用 **`multi-get`** 避免多次去同一分片取数据 |
| 75 | +
|
| 76 | +#### 限制 |
| 77 | +
|
| 78 | +一个索引,有 1 亿数据,分 10 个 shards,然后,一个搜索请求,from=1,000,000,size=100,会带来严重性能问题: |
| 79 | +
|
| 80 | +- query阶段,每个 shard 需返回 1,000,100 条数据给 coordinating node,而 coordinating node 需接收 10 * 1,000,100 条数据,即使每条数据只有 _id 和 _score,这数据量也很大,而且,这才一个查询请求 |
| 81 | +- 这种深分页请求并不合理,很少人为看很后面的请求,很多业务场景直接限制分页,如只能看前100页 |
| 82 | +- 但这种深度分页确实存在,如被爬虫了,这时直接干掉深度分页就好;又或业务上有遍历数据的需要,就得取所有符合条件数据,易想到利用 from + size 实现,不过,这显然不现实,这时,可采用 ES 提供的 **`scroll`** 方式遍历 |
| 83 | +
|
| 84 | +### 3.2 scroll方式 |
| 85 | +
|
| 86 | +scroll 查询可用来对 ES **`有效执行大批量文档查询`**,而又不用付出深分页的代价。 |
| 87 | +
|
| 88 | +- 游标查询允许我们 **`先做查询初始化`**,再批量拉取结果。像传统数据库中的 **`cursor`** |
| 89 | +- 游标查询会 **`取某时间点的快照数据`**。查询初始化之后索引上的任何变化会被它忽略。通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引视图 |
| 90 | +- 深分页的代价根源是 **`结果集全局排序`**,若去掉全局排序的特性,查询结果成本就很低。游标查询用字段 _doc 排序。这指令让 Elasticsearch 仅从还有结果的分片返回下一批结果。 |
| 91 | +
|
| 92 | +
|
| 93 | +
|
| 94 | +Scroll **`为检索大量结果而设计`**。如查询 1~100 页的数据,每页 100 条数据: |
| 95 | +
|
| 96 | +- from + size(Search)查询:每次都要在每个分片上查询得分最高的 from + 100 条数据,然后协同节点把收集到的 n × (from + 100) 条数据聚合起来再进行一次排序(Query 阶段) |
| 97 | +
|
| 98 | +- 每次返回 from + 1 开始的 100 条数据(Fetch 阶段),并且要重复执行 100 次 Search 查询过程(Query + Fetch),才能获取全部 100 页数据 |
| 99 | +
|
| 100 | +而Scroll查询: |
| 101 | +
|
| 102 | + - 只需在各分片上查询 10000 条数据,协同节点聚合 n × 10000 条数据进行合并、排序(Query 阶段),并取出前 10000 的结果(Fetch 阶段)快照起来,后续滚动查询时,只需根据设置的 size,直接 **`在生成的快照里面以游标形式`**,取回这个 size 数量的文档。 **`减少查询和排序次数`**。 |
| 103 | + - 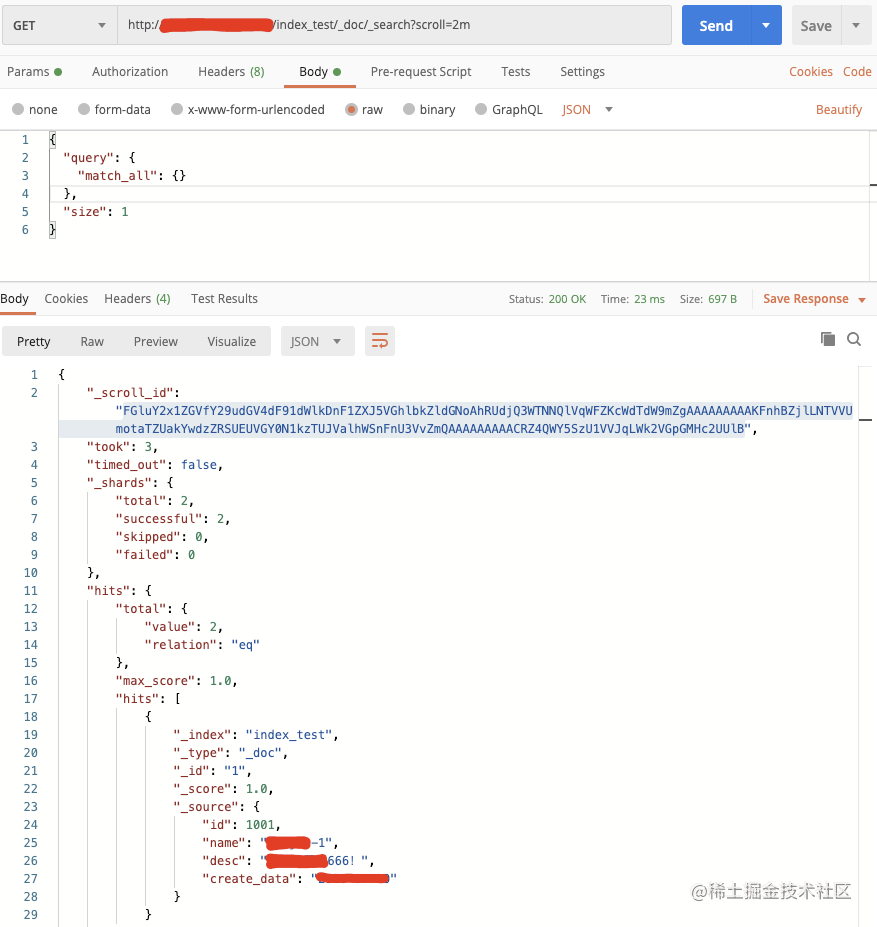 |
| 104 | + - 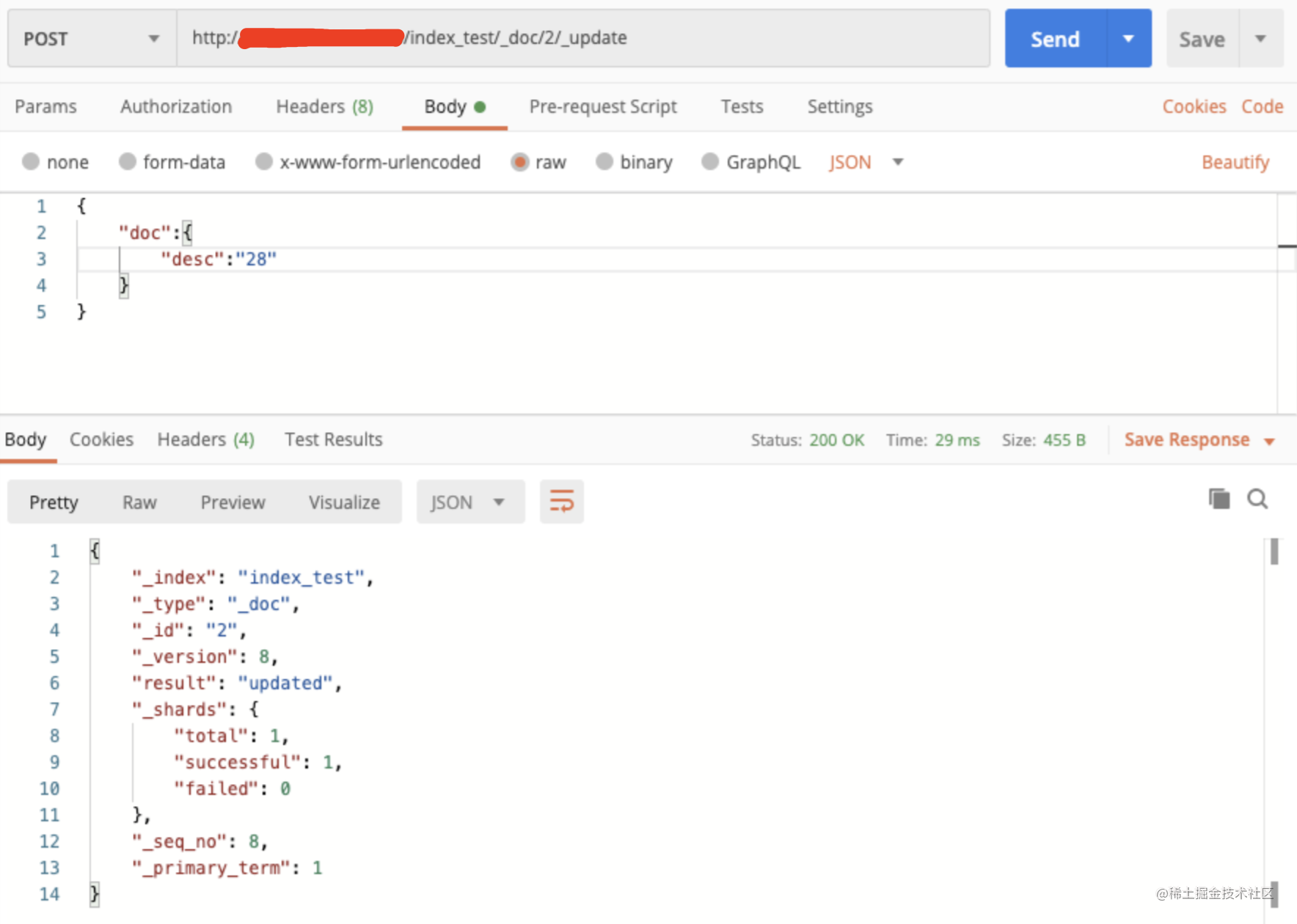 |
| 105 | + - 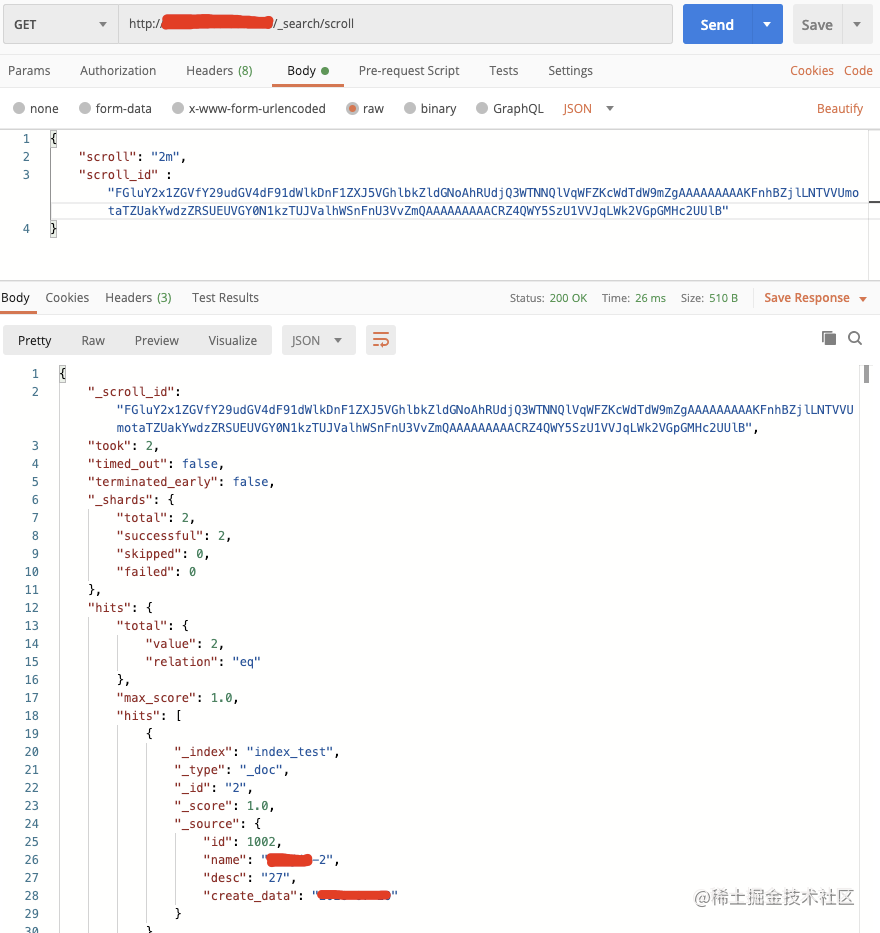 |
| 106 | + - 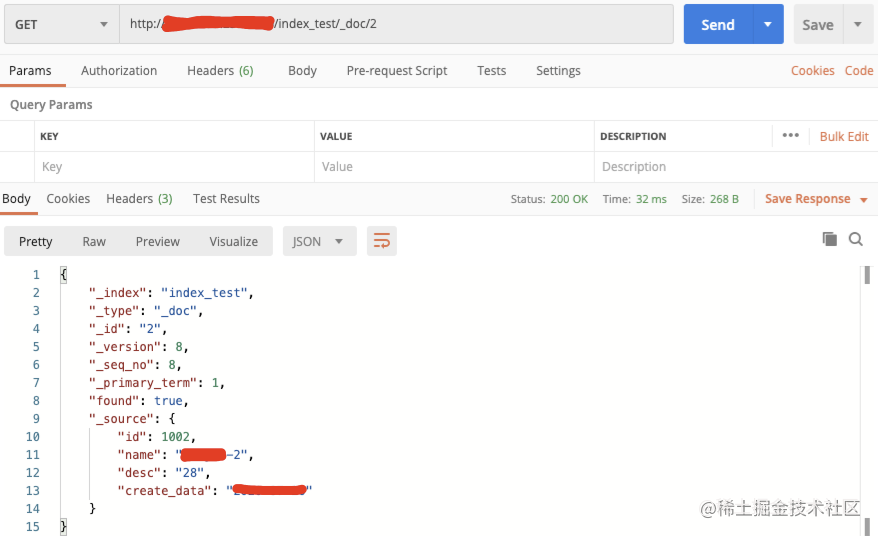 |
| 107 | +
|
| 108 | +### 3.3 search_after |
| 109 | +
|
| 110 | +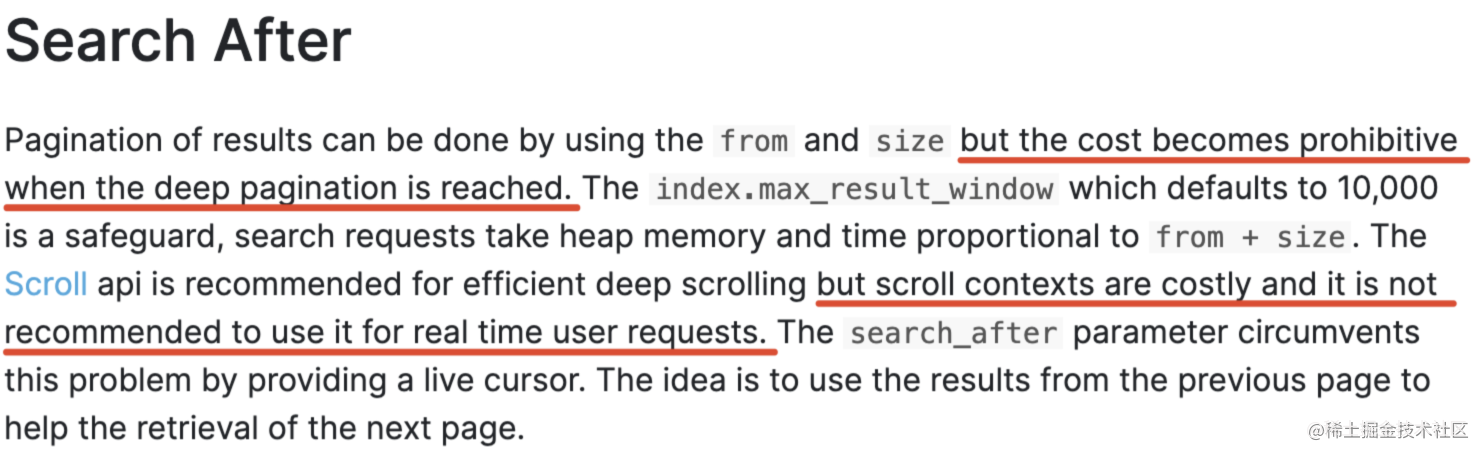 |
| 111 | +
|
| 112 | +ES 5引入的一种分页查询机制, `原理几乎就是和 scroll 一样`: |
| 113 | +
|
| 114 | +- 须先`指定排序` |
| 115 | +- 须`从第一页开始` |
| 116 | +- 从第一页开始以后,每次带上 **`search_after=lastEmittedDocFieldValue`** 为无状态实现一个状态,即把每次固定的 from + size 偏移变成一个确定值 lastEmittedDocFieldValue,而查询则从这个偏移量开始获取 size 个 _doc(每个 shard 获取 size 个,coordinate node 最后汇总 shards * size 个)。 |
| 117 | +
|
| 118 | +无论去到多少页,coordinate node 向其它 node 发送的请求始终就是请求 size 个 docs,是 **`常量`**,而不再是 from + size 那样,越往后,要请求的 docs 就越多,而要丢弃的垃圾结果也越多。即若要做非常多页查询, search_after 是 **`常量查询延迟和开销`**。 |
| 119 | +
|
| 120 | +为啥每次提供一个 search_after 值就能找到确定的那一页的内容呢,ES不是分布式的吗,每个 shard 只维护一部分的离散的文档,那 ES 是怎么做的? |
| 121 | +
|
| 122 | +#### 实现原理 |
| 123 | +
|
| 124 | +- 第一次只能够查第一页,每个 shard 返回一页数据 |
| 125 | +
|
| 126 | +- 服务层得到 2 页数据,内存排序,取出前 100 条数据,作为最终的第一页数据,这个全局的第一页数据,一般来说 **`每个 shard 都包含一部分数据`**(如 shard1 包含 20 条,shard2 包含 80 条) |
| 127 | +
|
| 128 | +- 这方案也要服务器内存排序,岂不是和 scroll 一样?第一页数据的拉取确实一样,但每一次“下一页”拉取的方案就不一样 |
| 129 | +
|
| 130 | +点击“下一页”时,需拉取第二页数据,在第一页数据的基础上,能 **`找到第一页数据被拉取的最大值`**,这个上一页记录的 max,会作为第二页数据拉取的查询条件。 |
| 131 | +
|
| 132 | +就无需像 scroll 那样返回 2 页数据,每个 shard 还是只返回一页数据,只不过是 **`从 max 开始的一页长度的数据`**。 |
| 133 | +
|
| 134 | +服务层得到 2 页数据,内存排序,取出前 100 条数据,作为最终的第 2 页数据,这全局的第 2 页数据,一般也是每个 shard 都包含一部分数据。 |
| 135 | +
|
| 136 | +同理,查询第 100 页数据,不是返回 100 页数据,仍返回一页数据,保证了数据传输量和排序数据量 **`不随不断翻页而导致性能下降`**。 |
0 commit comments