Testing in the world of AI & ML
Exploring the key differences between traditional software testing approaches and testing an AI product, and highlight critical areas all software engineers need to be aware of as they develop these systems.

As Artificial Intelligence (AI) and Machine Learning (ML) become an ever growing part of our world, how does that change our approach to quality & software testing?
Testing is an essential part of any software product, and that doesn't change with AI, but the rules are changing.
So how can we ensure that the end users trust our product? In this post we’ll explore the key differences between traditional software testing approaches and testing an AI product, and highlight critical areas all software engineers need to be aware of as they develop these systems.
Key differences between traditional software and AI/ML - what does it mean for testing?
1. Logic is defined & controlled vs Logic is learnt & evolving
Traditionally: Human developers define the logic in the code, they have full control of any changes.
ML: The logic is defined based on the training data provided, as it learns from more data, that logic may change.
What does it mean for testing? The testing must be continuous, creative and exploratory - we don't necessarily know how the output has been determined and whether that will change. The training data is the only known so it must be complete and, critically, this must be separate from the test data we use.
2. Deterministic vs Probabilistic behaviour
Traditionally: We pass an input, we get a predictable output.
ML: We pass an input, we get the most probable correct output.
What does it mean for testing? Traditionally testing focuses on capturing all the possible inputs, and verifying the outputs. For AI models this becomes more complicated, even with the same input we can get a slightly different output meaning validation of the output is tricky, and often it is not strictly right or wrong, so how do we test for correctness? We also need to know why the output is what it is. The more complex the model, the more complex the problem becomes as well.
What to test in AI / ML systems
Measuring and ensuring quality is a subjective measure, that is true for any product. But this becomes even more so when it comes to AI and ML. We have to take into account accuracy, context, consistency and hallucinations. Even in traditional software, it's not feasible to test everything, so where do we focus our efforts? The following are some of the key areas to focus on:
1. Functional performance
Note: In an ML context, accuracy, recall and precision are mathematical definitions that differ from their more common, everyday use.
Testing a model's performance isn't as simple as checking how often it is correct. How often a model makes a correct prediction is a model's accuracy, it's an intuitive test metric, but it has limitations because it is tied so closely to the dataset. It should definitely be measured but we need to avoid using this as the sole metric.
Precision, recall and F1 score allow us to understand the model in more detail.
- Precision: Of all predicted positives, how many were correct?
- Recall (or true positive rate): Of all actual positives, how many did we catch?
- F1 score: the harmonic mean of these 2 metrics.
In other words,

F1 score is on a value of 0 to 1, where 1 is perfect precision and recall.
A higher F1 score is therefore better in general, but unless your model is perfect then there are other considerations to make other than “the higher the better”. There are different use cases that call for a higher focus on precision rather than recall. For example, false positives are costly in a spam filter, so you want to prioritise a high level or precision. In a fire detection system, a false alarm is better than a missed true case, so a high level of recall is more important.
To visualise this, consider again a spam filter model that scores each input on a scale of 0 to 1, if the result is under 0.5 it is classified as negative (i.e not spam), if the result is over 0.5, it is classified as positive (i.e spam).
For simplicity, our example gets exactly half its predictions right in each classification. So we can see the model has an accuracy, precision, recall and F1 of 0.5 - not ideal for a spam filter as 10 valid emails were sent to spam!
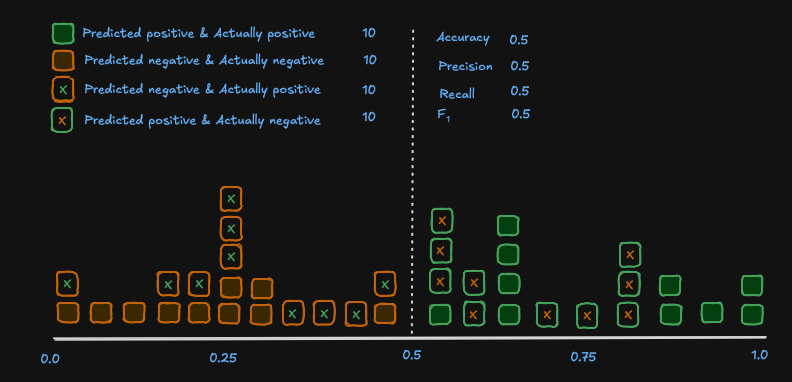
If we were to change the threshold for classification however, we can see how the metrics change:
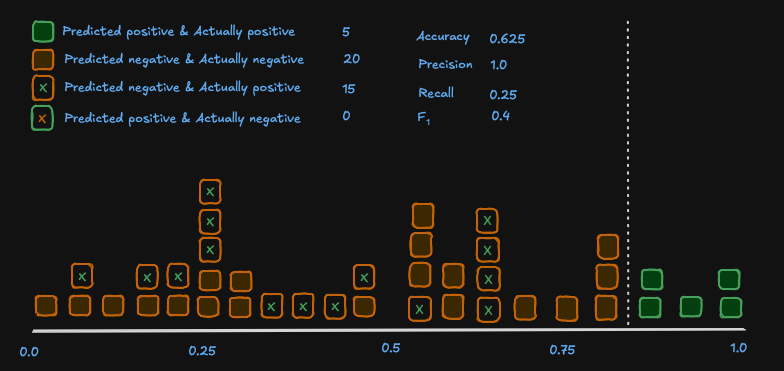
Now we have a model where 0 valid emails were sent to spam, which is a better result for this use case despite the lower F1 score. Your inbox would still have a lot of spam emails though, so the model needs some work!
When considering where to prioritise, a measurement of false positives can also be useful. That is incorrectly classified negatives dived by all actual negatives.
To dive even deeper, it may be useful to measure how confident your model is in its predictions. This is especially useful in probabilistic models such as spam filters. For every input your model will return a confidence level, e.g this email is 91% likely to be spam. In these models a decision threshold will be set, e.g 80%, that eventually determines whether the output is spam or not spam.
When testing these models, there is a lot more value to engineers in mapping the confidence levels than the eventual outputs.
2. Data Quality
Data is the foundation of AI and ML, so it's imperative that we have good understanding of the data being used. Poor data leads to poor models. Testing should cover:
-
Completeness & Anomalies Completeness and anomalies ensure that the model is training on enough data to be able to handle anything thrown at it in production, this is also important in traditional software systems, albeit to a lesser extent. The key is to understand the product and how it will be used. There are also automated tools that can help with this such as TensorFlow Data Validation, and Great Expectations.
-
Bias & Fairness
- Fairness means that the model under test does not systematically disadvantage or advantage certain individuals or groups based on attributes such as race, gender, age, disability or socioeconomic status.
- Bias refers to a model that favours certain outcomes due to skewed training data, biased labels, model design or historical societal inequalities.
Bias & Fairness can be a trickier one to test but it can be critical, especially in sensitive domains such as healthcare, finance and hiring. There are tools which can help with this, such as Tensorflow’s fairness indicators and Microsoft’s Fairlearn, however we can also account for this through visual audits. This is where a test engineers creativeness & exploratory skills are key. For example, consider you are testing a model designed around hiring:
- If you evaluate the model by subgroups “Male” and “Female”, how does the model perform? Is it consistent?
- Are there any use cases where changing only the “Age” attribute causes your model to produce a different result?
- Are you including diverse stakeholders? There may be unconscious bias’ that are not picked up on during development.
-
Leakage between training & test data
This point is of much higher importance when compared with traditional systems. It is common in traditional testing setups to try and replicate production data as closely as possible during development and testing phases. However, if there is an overlap between training and test data in ML systems, or if the data is too similar, then the value of the tests reduces drastically.
Put simply, if a model has learnt on the test data, it should always get that correct, so what's the value in the test?
We want the test data to be something the model has never seen before, so that we can test how it evaluates new data, as it will in production.
3. Robustness
A robust model is one that is able function correctly in the presence of unfamiliar, sensitive or noisy data. Similar to robust infrastructure, as the end user you want the correct result no matter what else is going on in your system. For this, we need to focus on the test data supplied. We need test cases with noisy data, data that is potentially out of scope of the product, and data with minute differences that may be crucial.
An easy example to consider here is computer vision. Imagine an algorithm designed to determine whether an image shows a human or a horse. A robust solution needs to be able to handle an image with thousands of horses, or a single human in a sea of other animals excluding horses, or correctly identify an image with neither. Be creative with your test data!
4. Drift
The quality of an ML system can degrade over time if the data / environment it's subjected to changes over time. Of course you want your system to continue learning, that's the benefit of using machine learning in the first place, but we need to know how it is changing to avoid the model drifting in the wrong direction.
- Test for data drift - is your model learning predominantly from a narrower spread of data?
- Test for concept drift - is the relationship between input and output changing?
Note that drift isn't necessarily bad, for example if your model orientates around sales, there may be some seasonal data drift around things like Black Friday. If we don't understand or notice the drift, then it can lead to problems down the line.
5. Transparency
An important aspect for those working on the system, those using the system and stakeholders is the ability to understand WHY a model made a certain decision. The best way of showing this is dependent on the product, but it can come in the form of human readable audits, decision trees or graphs showing which features of the model influenced the output strongly.
6. Other
Performance, scalability, observability and integration with other systems are all very important considerations. However the approach to testing these aspects doesn't differ too much from traditional software testing approaches, so we won't dive into them here.
Conclusion
Testing AI & ML systems provides a fundamentally different problem than traditional software testing. A cultural shift is needed, one that requires QA’s need to have a deeper understanding of the system under test in order to be truly effective.
That being said, that doesn’t mean the skills that make great QA’s today are no longer useful, QA’s who can look at these systems with a creative mindset, and with great problem solving skills will excel.
The future is bright for those willing to learn!
You may also like


Is Pulumi a worthy contender in the IaC race? Part 1: The current landscape
Insight, imagination and expertly engineered solutions to accelerate and sustain progress.