- *: equivalent contribution, †: corresponding author
| Deep Object-Centric 3D Perception |
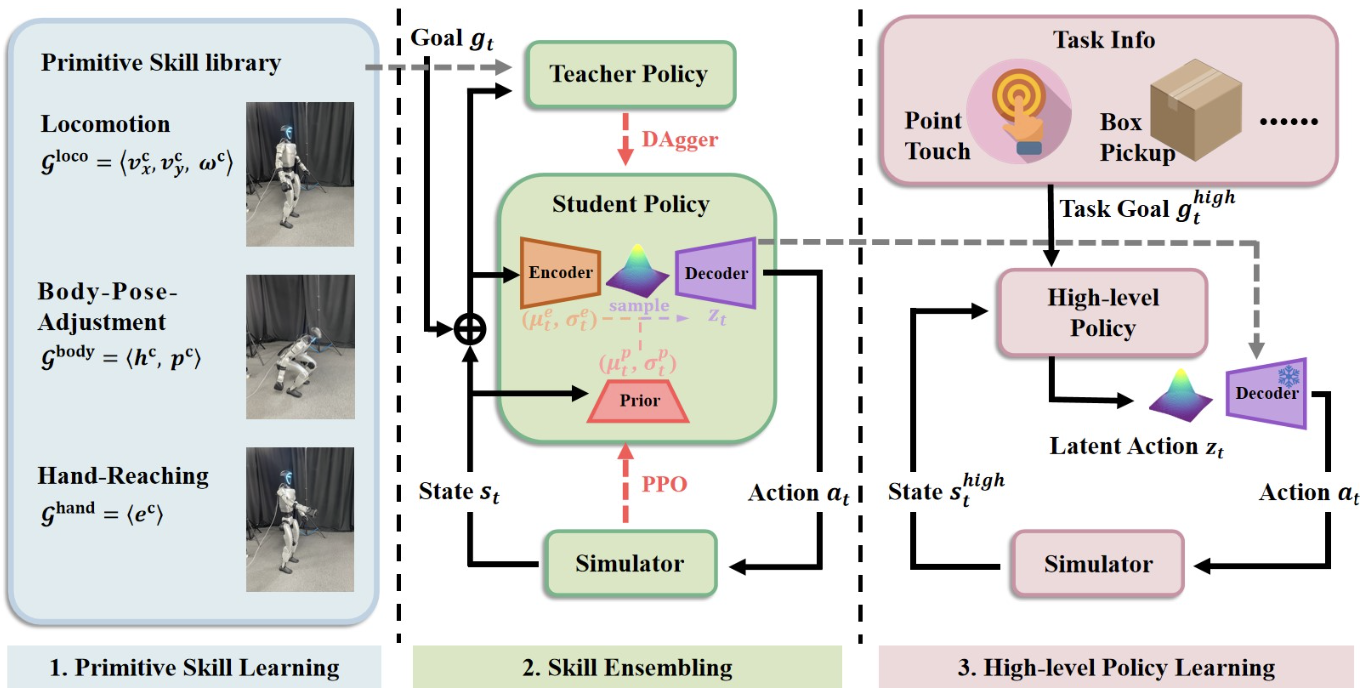
| Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space |
| SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation |
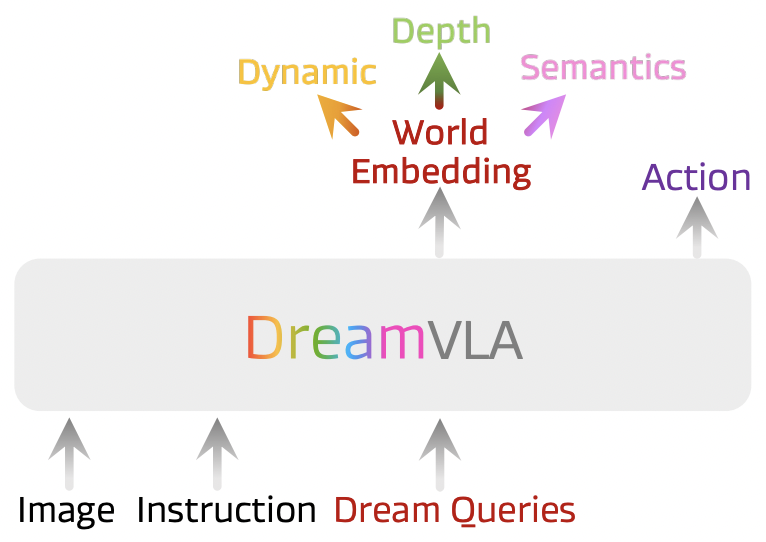
| DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge |
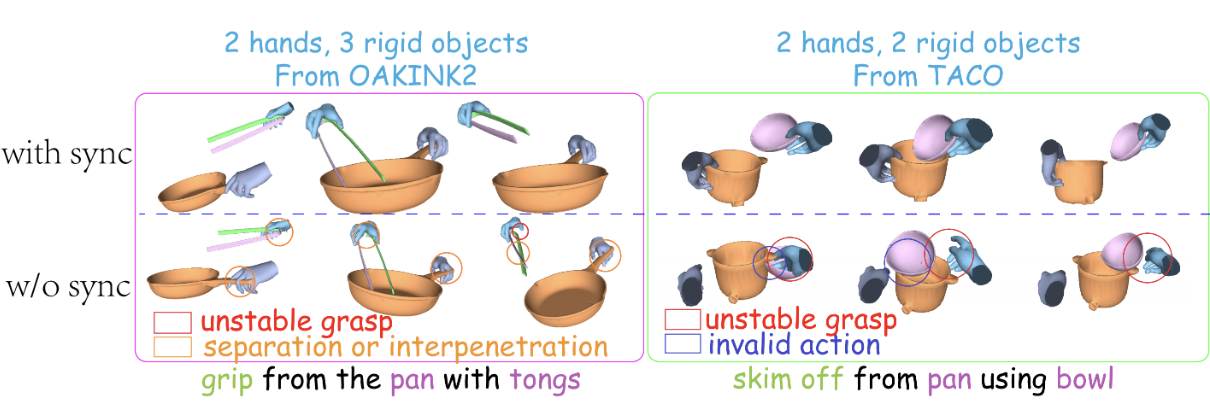
| SyncDiff: Synchronized Motion Diffusion for Multi-Body Human-Object Interaction Synthesis |
| 4DSegStreamer: Streaming 4D Panoptic Segmentation via Dual Threads |
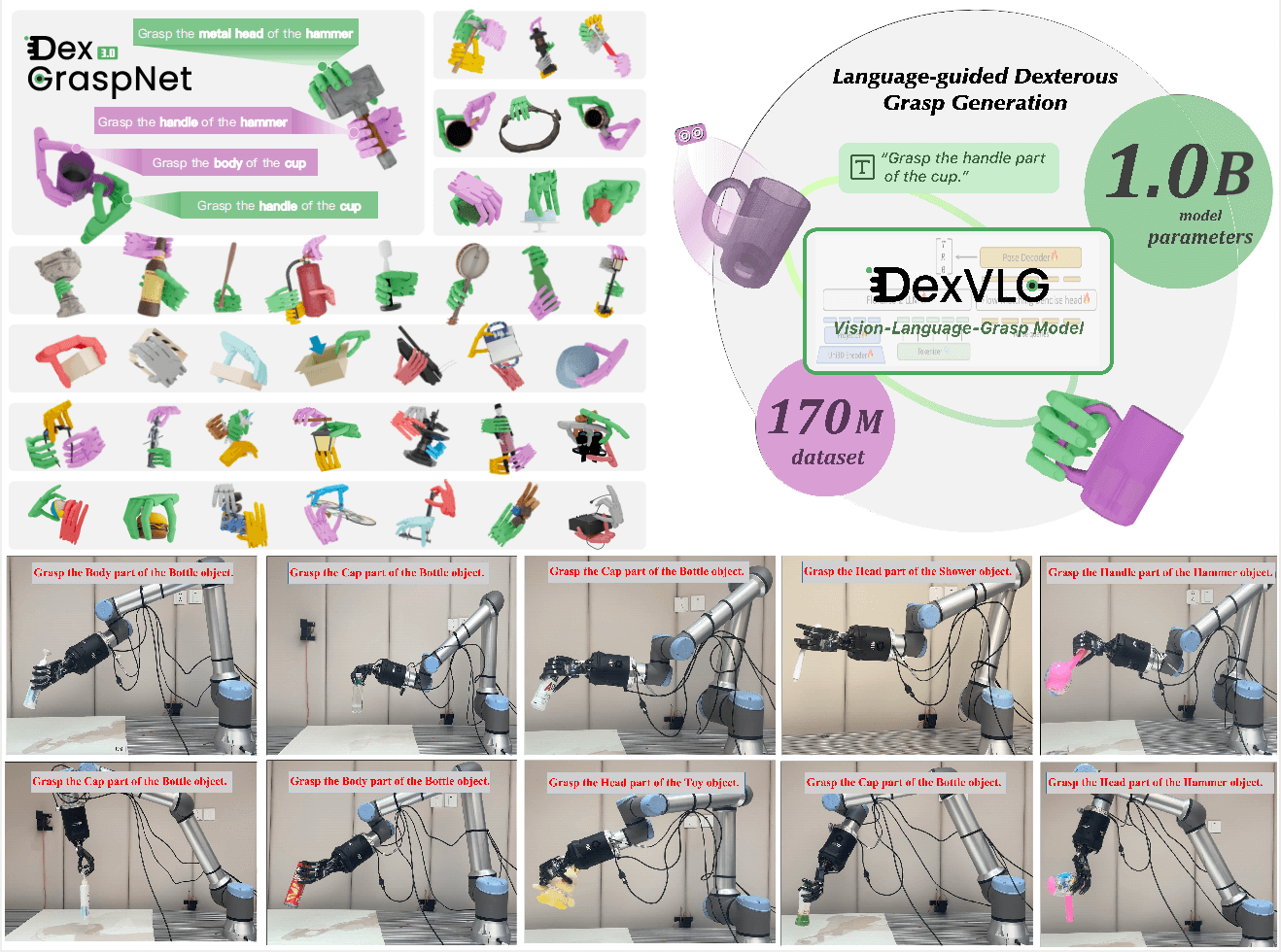
| DexVLG: Dexterous Vision-Language-Grasp Model at Scale |
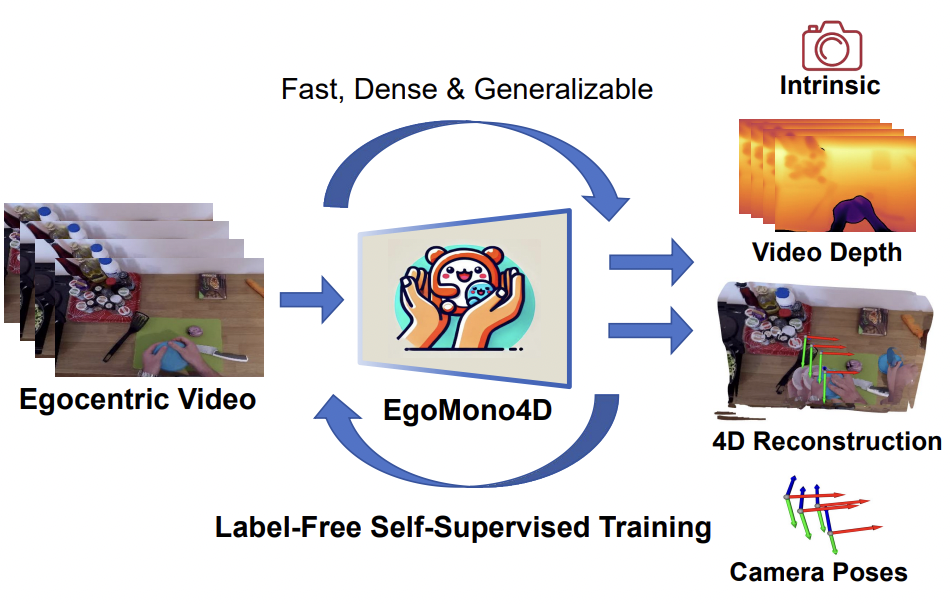
| Self-Supervised Monocular 4D Scene Reconstruction for Egocentric Videos |
| Learning Physics-Based Full-Body Human Reaching and Grasping from Brief Walking References |
| CORE4D : A 4D Human-Object-Human Interaction Dataset for Collaborative Object REarrangement |
| MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data |
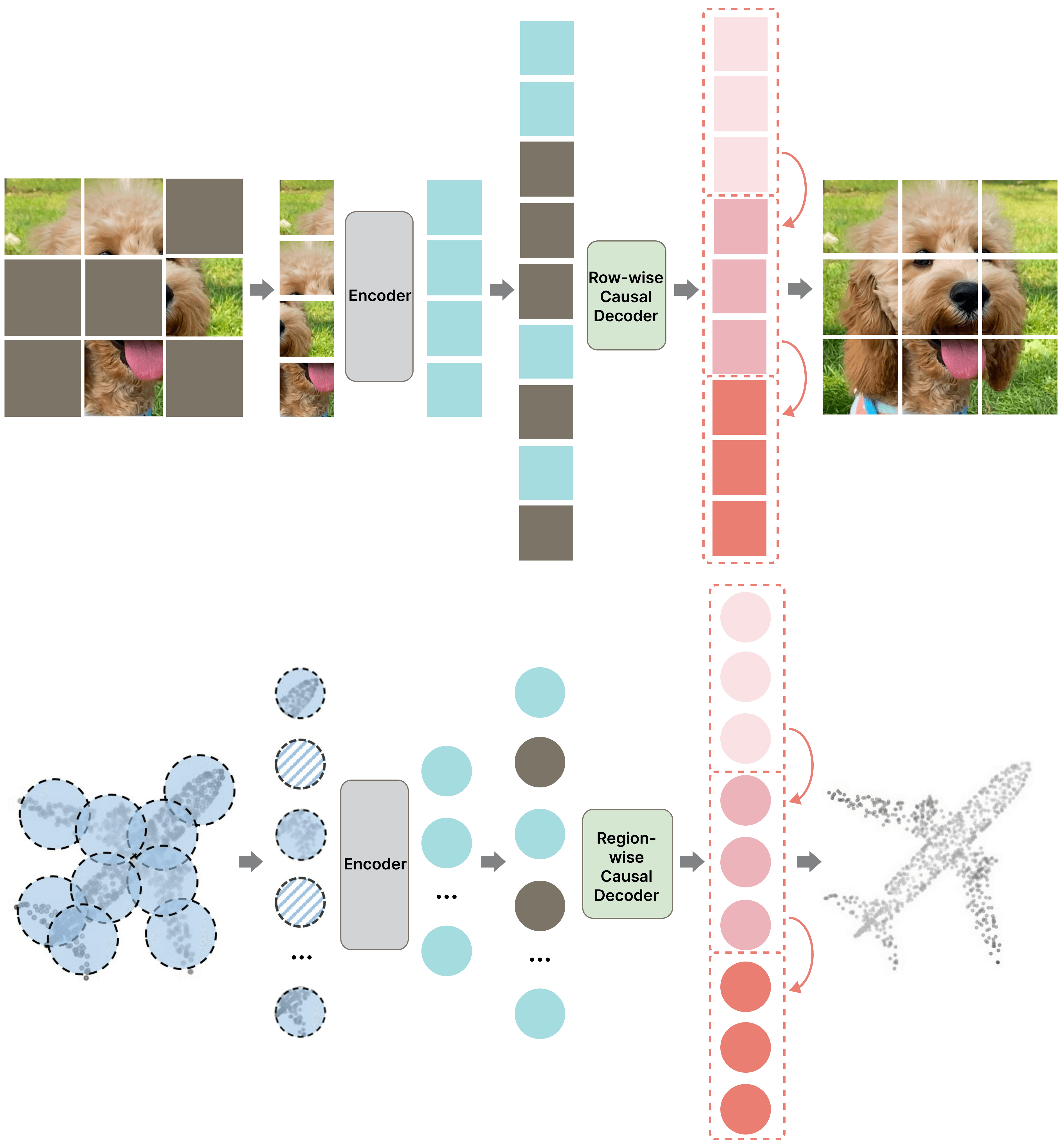
| MAP: Unleashing Hybrid Mamba-Transformer Vision Backbone's Potential with Masked Autoregressive Pretraining |
| PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model |
DexTrack: Towards Generalizable Neural Tracking Control for Dexterous Manipulation from Human References | |
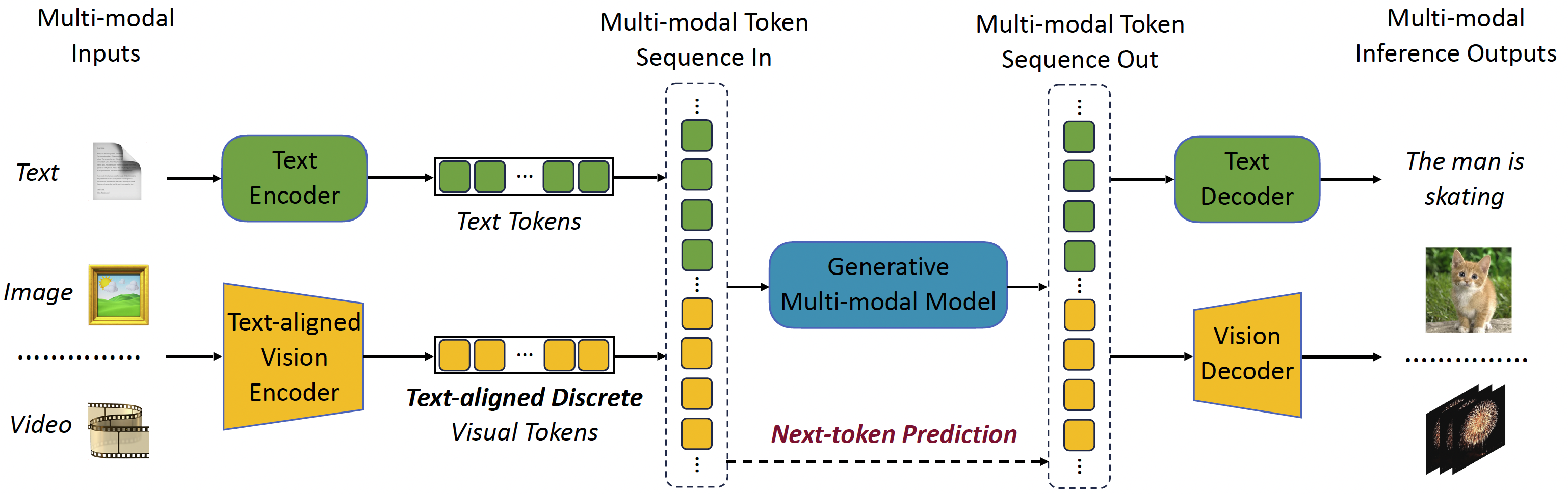
| VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation |
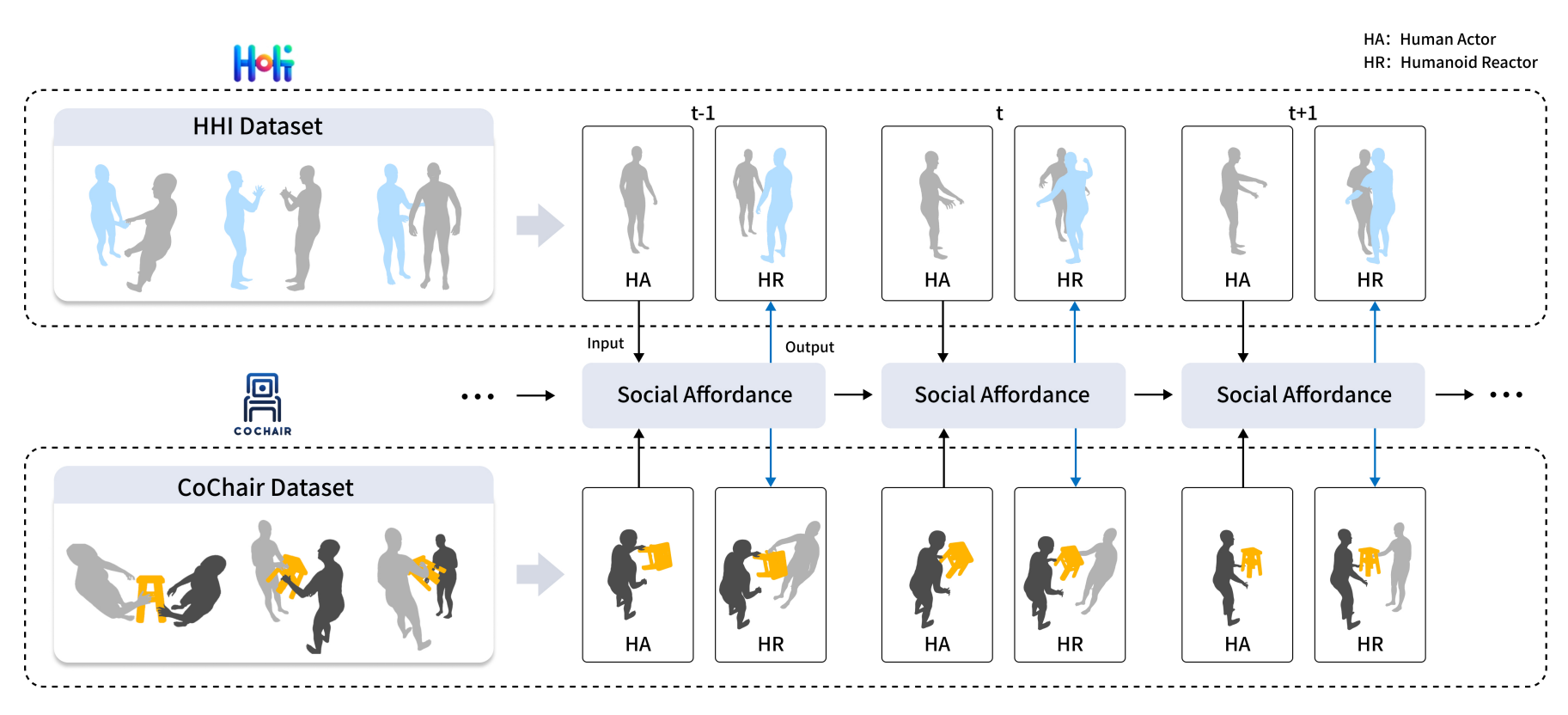
| Interactive Humanoid: Online Full-Body Motion Reaction Synthesis with Social Affordance Canonicalization and Forecasting |
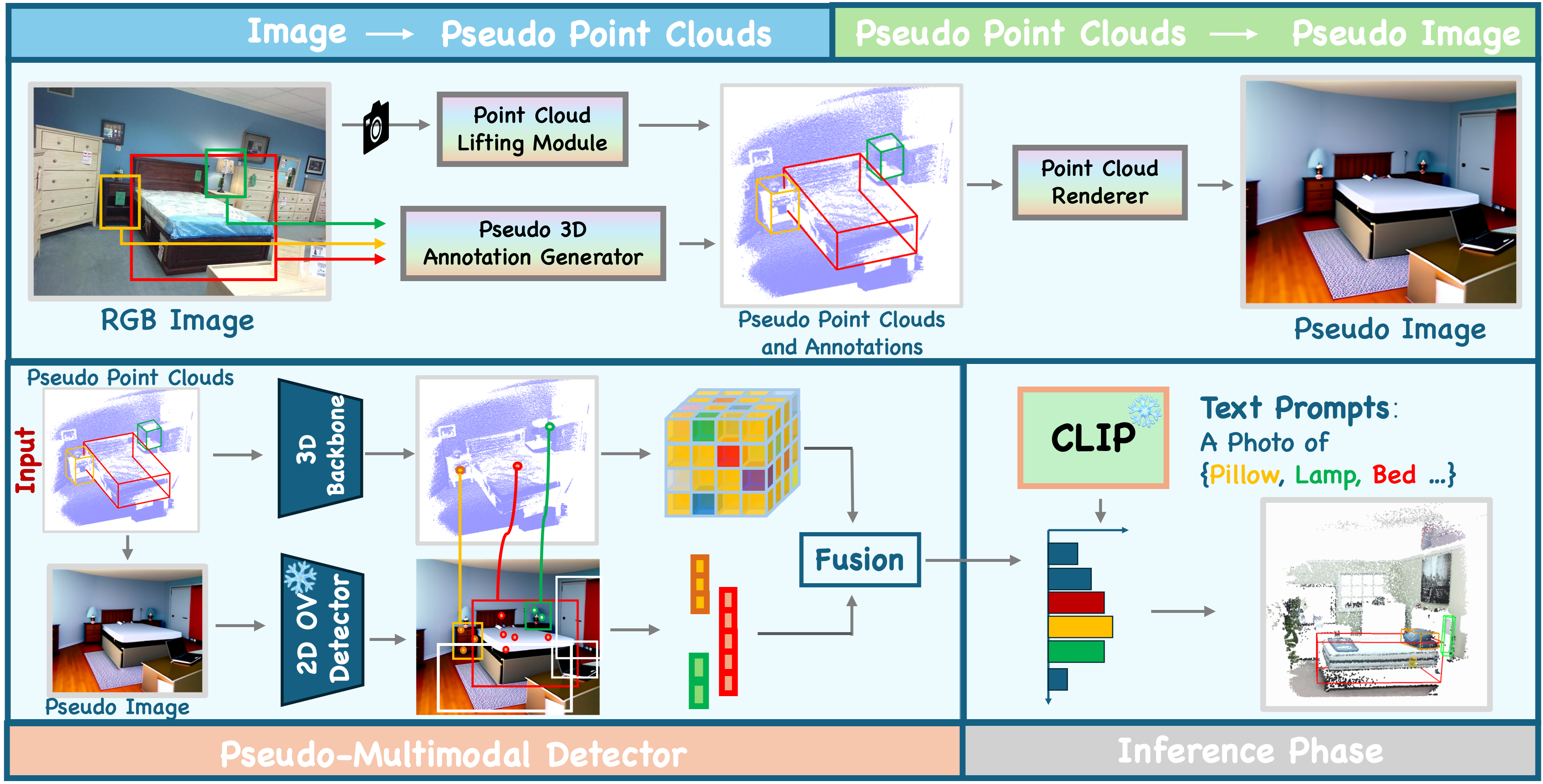
| ImOV3D: Learning Open Vocabulary Point Clouds 3D Object Detection from Only 2D Images |
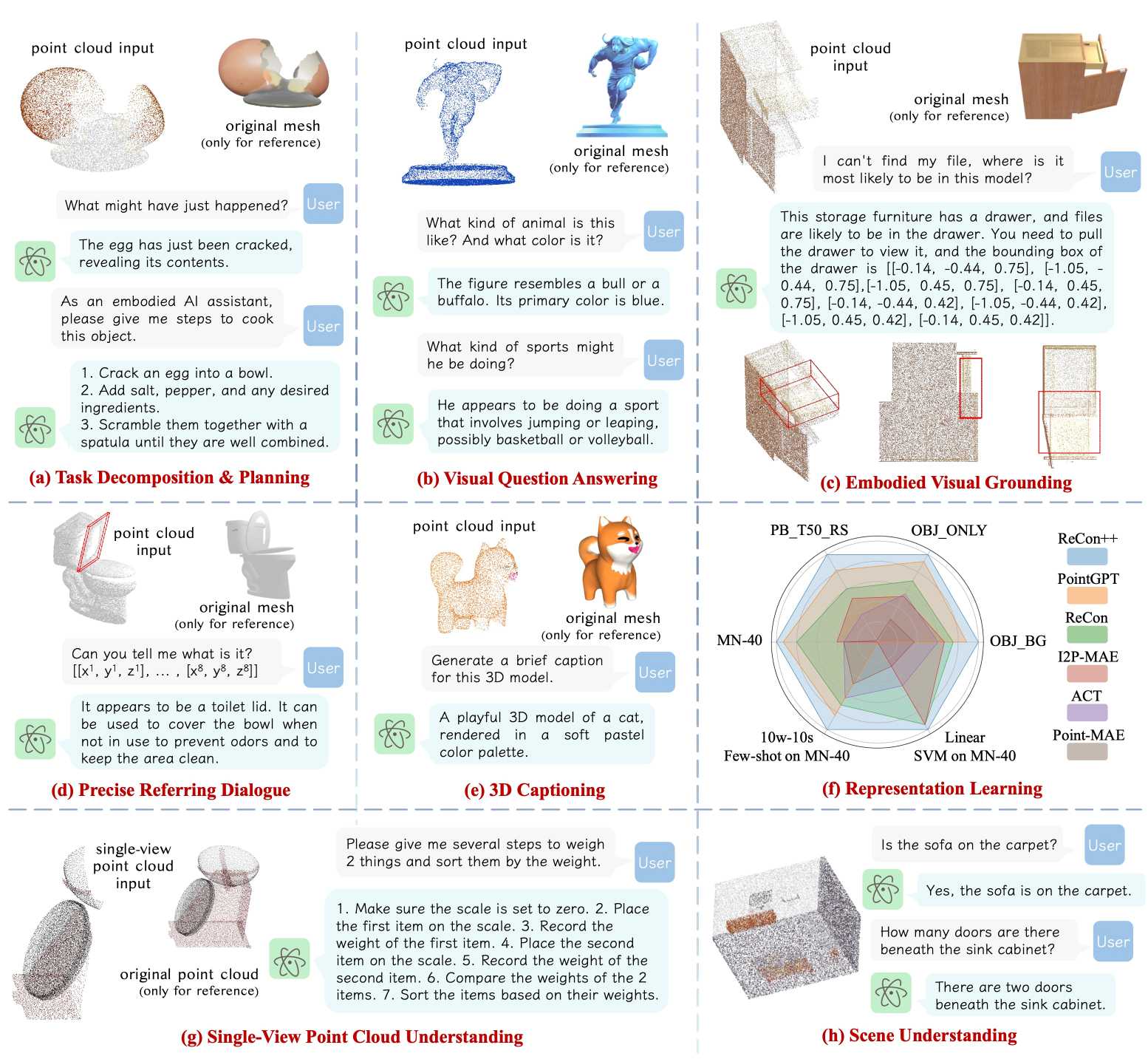
| ShapeLLM: Universal 3D Object Understanding for Embodied Interaction |
QuasiSim: Parameterized Quasi-Physical Simulators for Dexterous Manipulations Transfer | |
| FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models |
| PhysReaction: Physically Plausible Real-Time Humanoid Reaction Synthesis via Forward Dynamics Guided 4D Imitation |
| GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation |
| TACO: Benchmarking Generalizable Bimanual Tool-ACtion-Object Understanding |
| GenN2N: Generative NeRF2NeRF Translation |
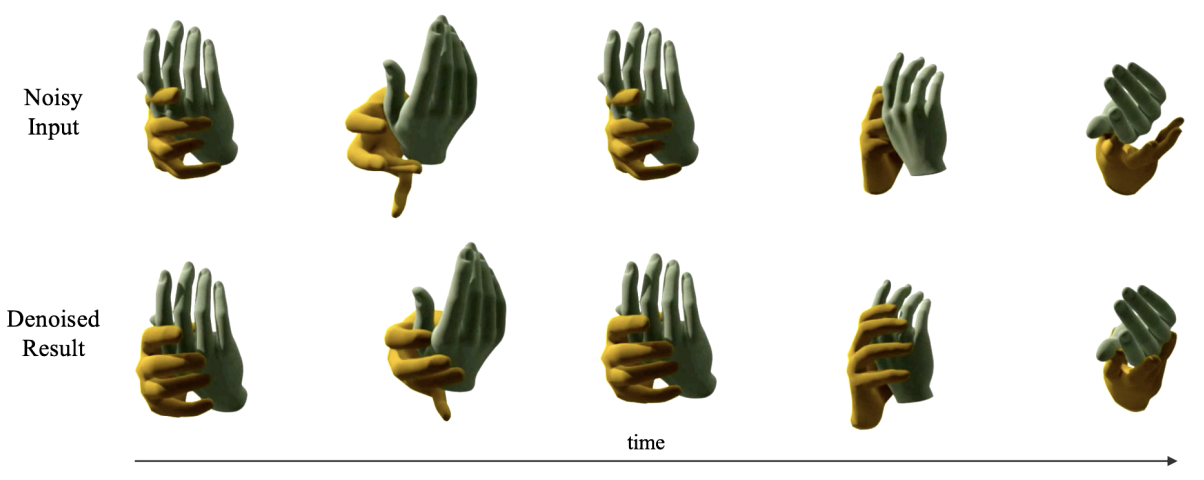
| Physics-aware Hand-object Interaction Denoising |
| DreamLLM: Synergistic Multimodal Comprehension and Creation |
| GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion |
| Enhancing Generalizable 6D Pose Tracking of an In-Hand Object with Tactile Sensing |
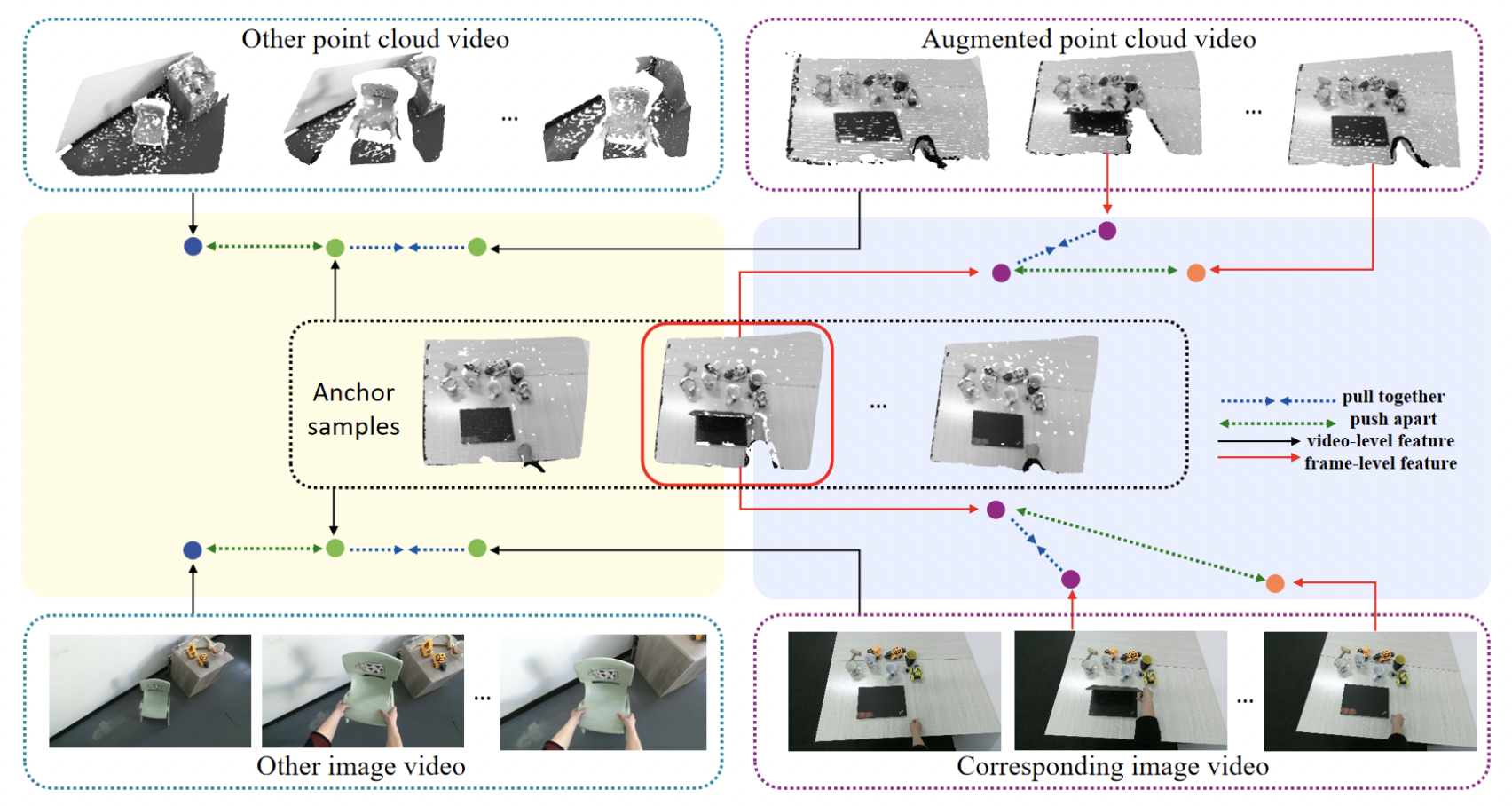
| CrossVideo: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding |
| Semantic Complete Scene Forecasting from a 4D Dynamic Point Cloud Sequence |
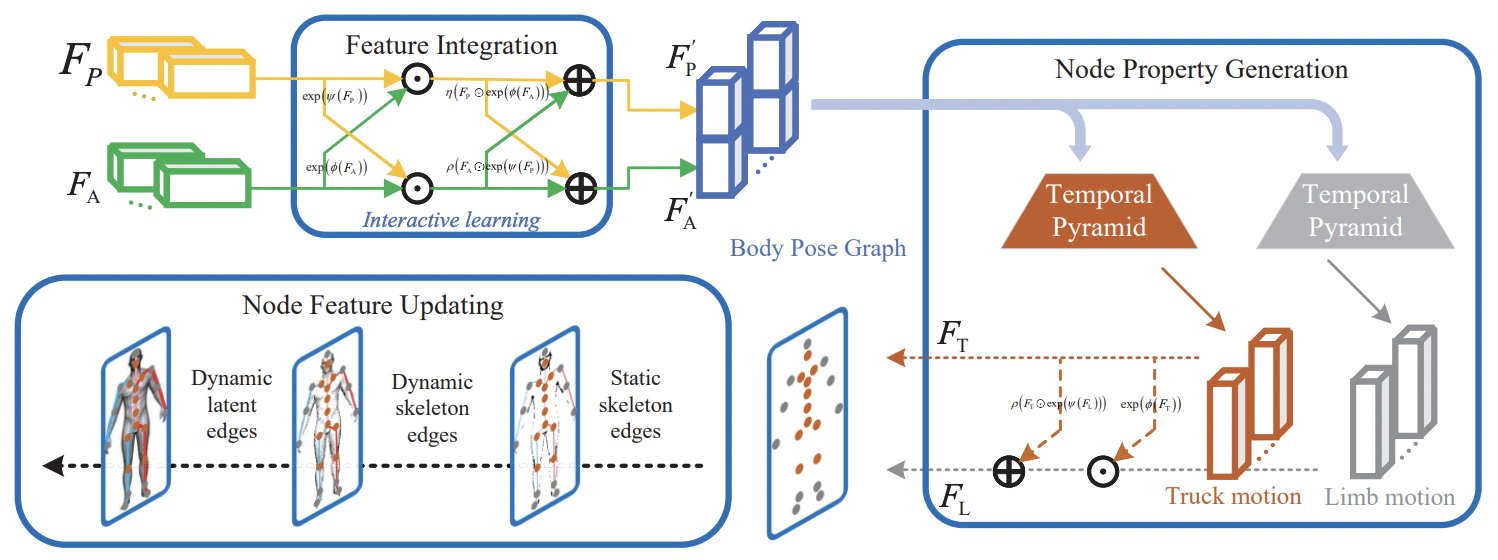
| Full-Body Motion Reconstruction with Sparse Sensing from Graph Perspective |
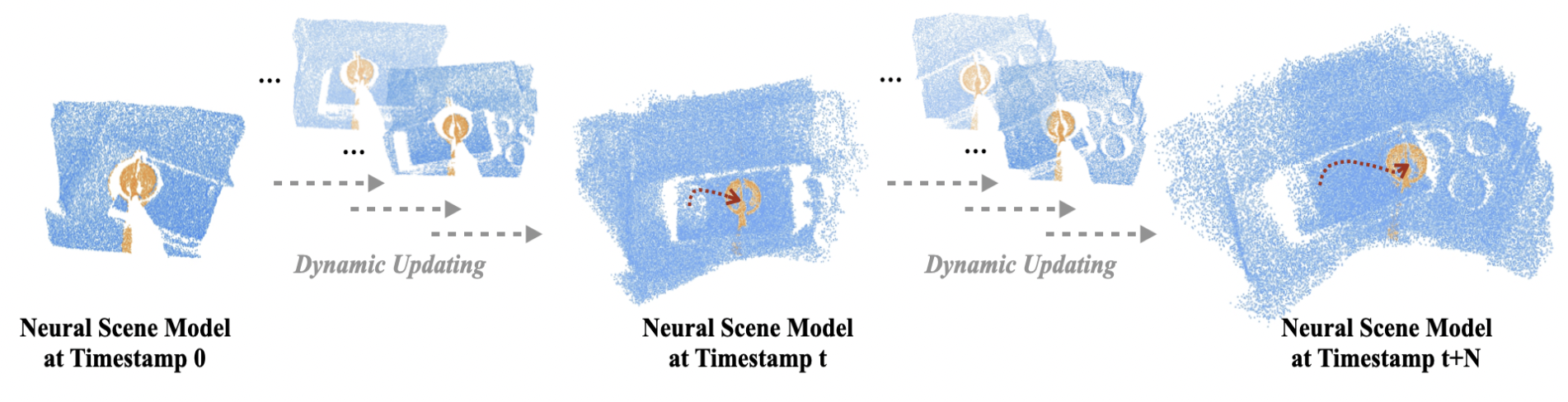
| NSM4D: Neural Scene Model Based Online 4D Point Cloud Sequence Understanding |
| TransTouch: Learning Transparent Objects Depth Sensing Through Sparse Touches |
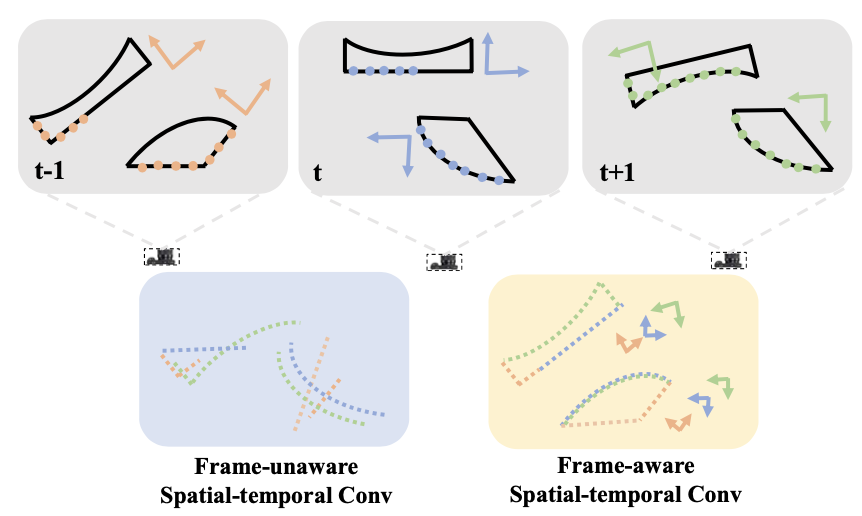
| LeaF: Learning Frames for 4D Point Cloud Sequence Understanding |
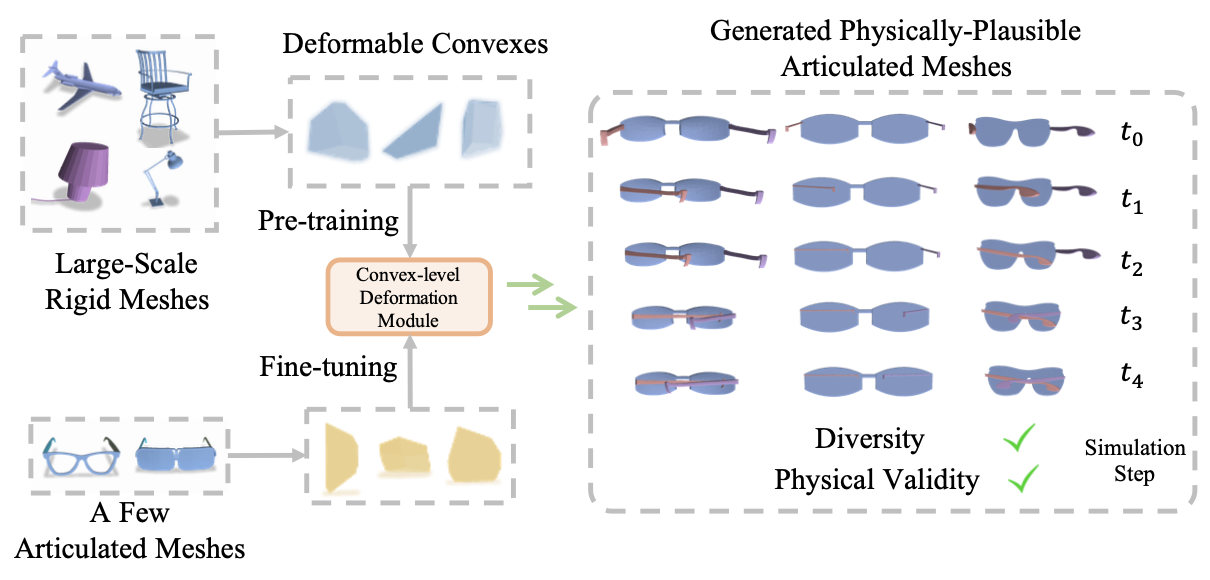
| Few-Shot Physically-Aware Articulated Mesh Generation via Hierarchical Deformation |
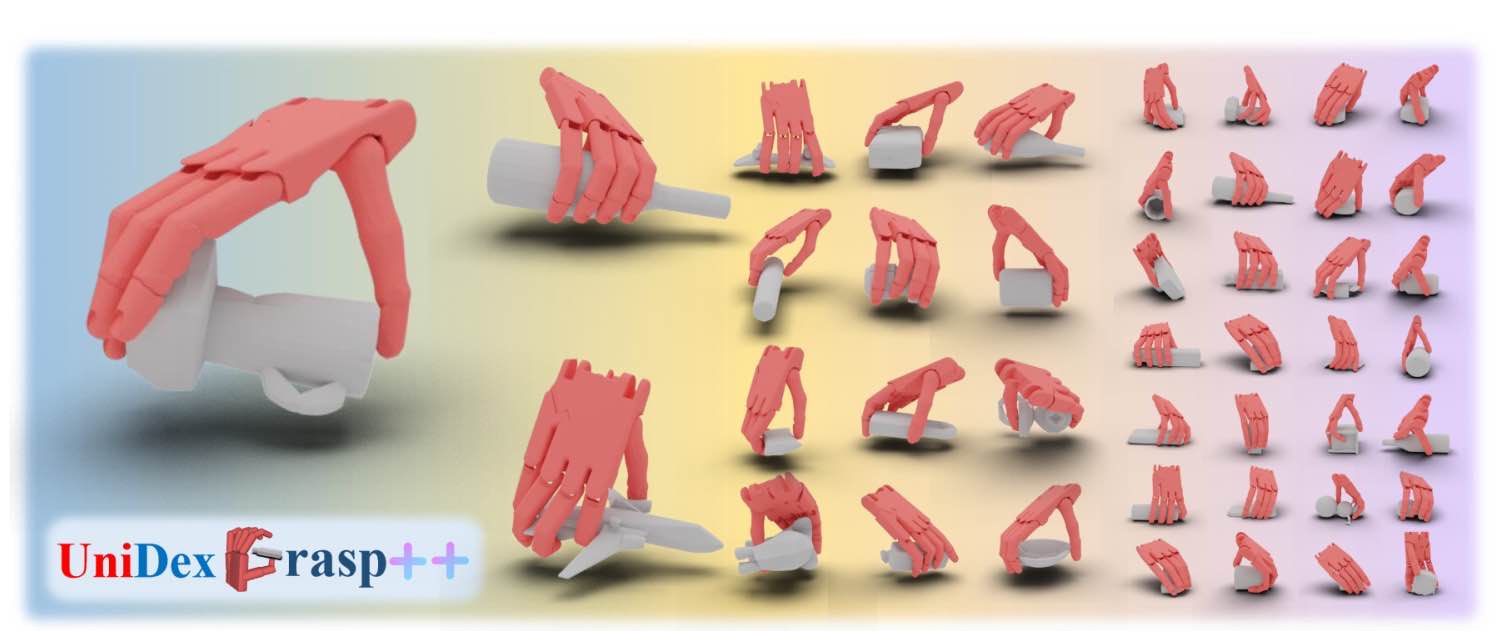
| UniDexGrasp++: Improving Dexterous Grasping Policy Learning via Geometry-aware Curriculum and Iterative Generalist-Specialist Learning |
| 3D Implicit Transporter for Temporally Consistent Keypoint Discovery |
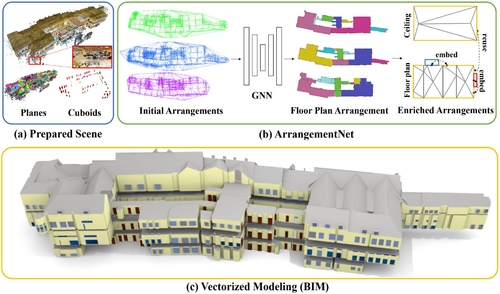
| ArrangementNet: Learning Scene Arrangements for Vectorized Indoor Scene Modeling |
| Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining |
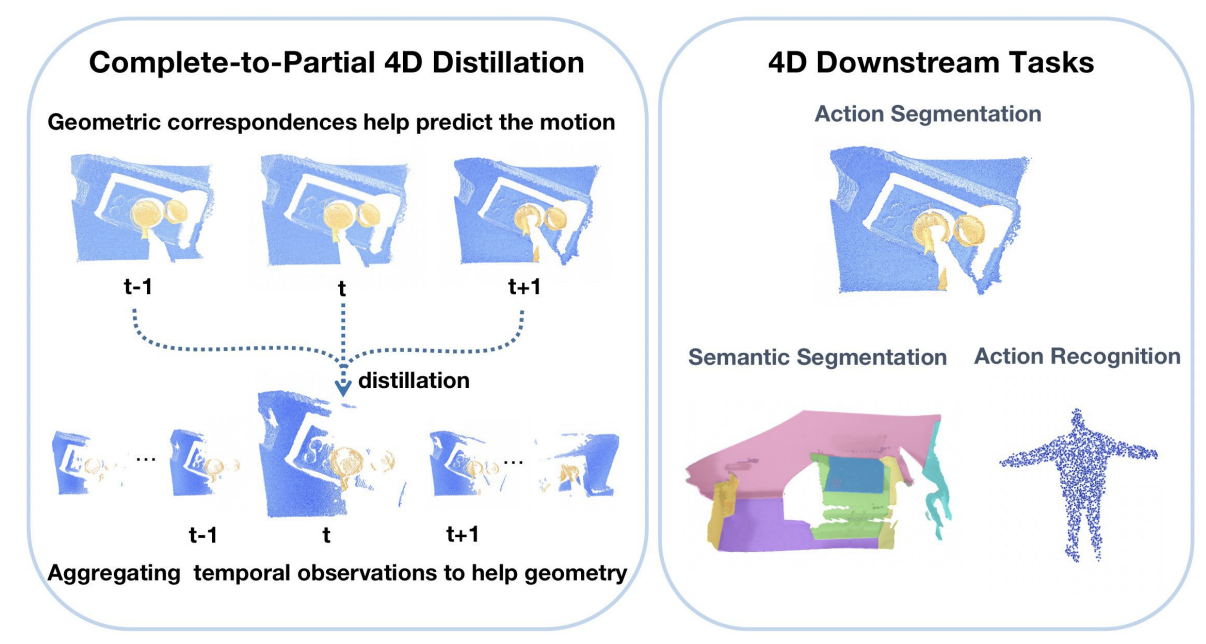
| Complete-to-Partial 4D Distillation for Self-Supervised Point Cloud Sequence Representation Learning |
| CAMS: CAnonicalized Manipulation Spaces for Category-Level Functional Hand-Object Manipulation Synthesis |
| JacobiNeRF: NeRF Shaping with Mutual Information Gradients |
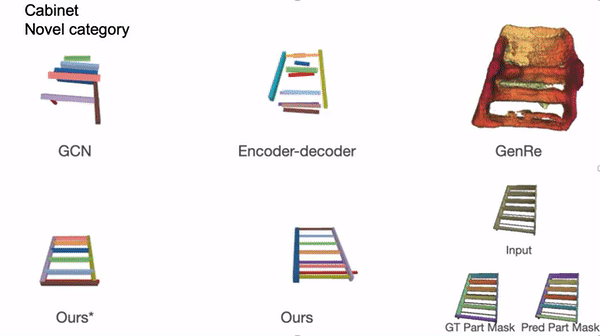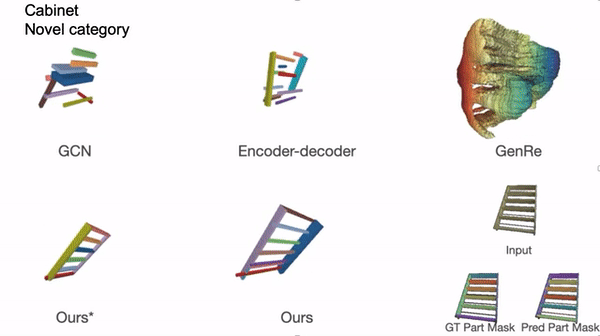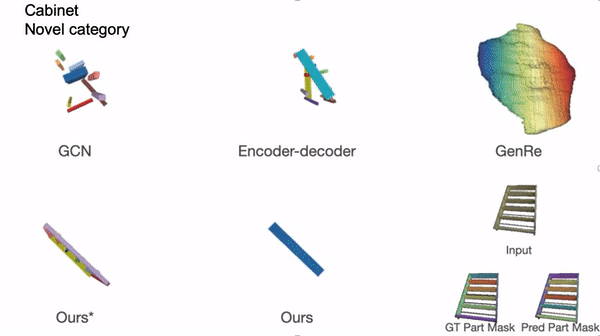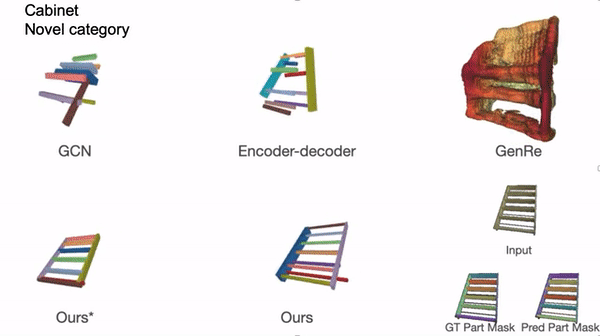
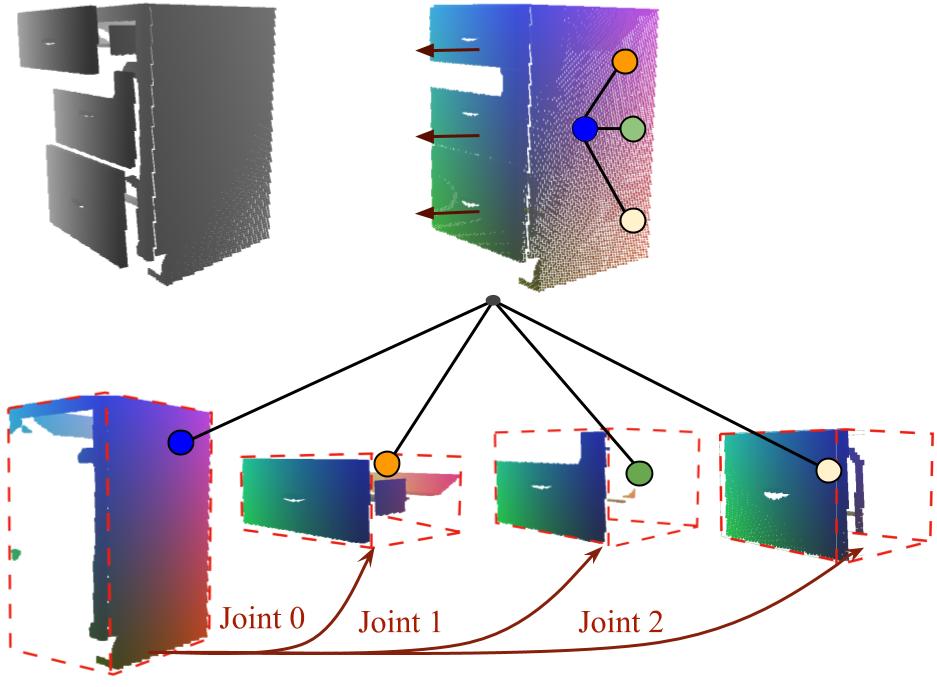
| GAPartNet: Learning Generalizable and Actionable Parts for Cross-Category Object Perception and Manipulation |
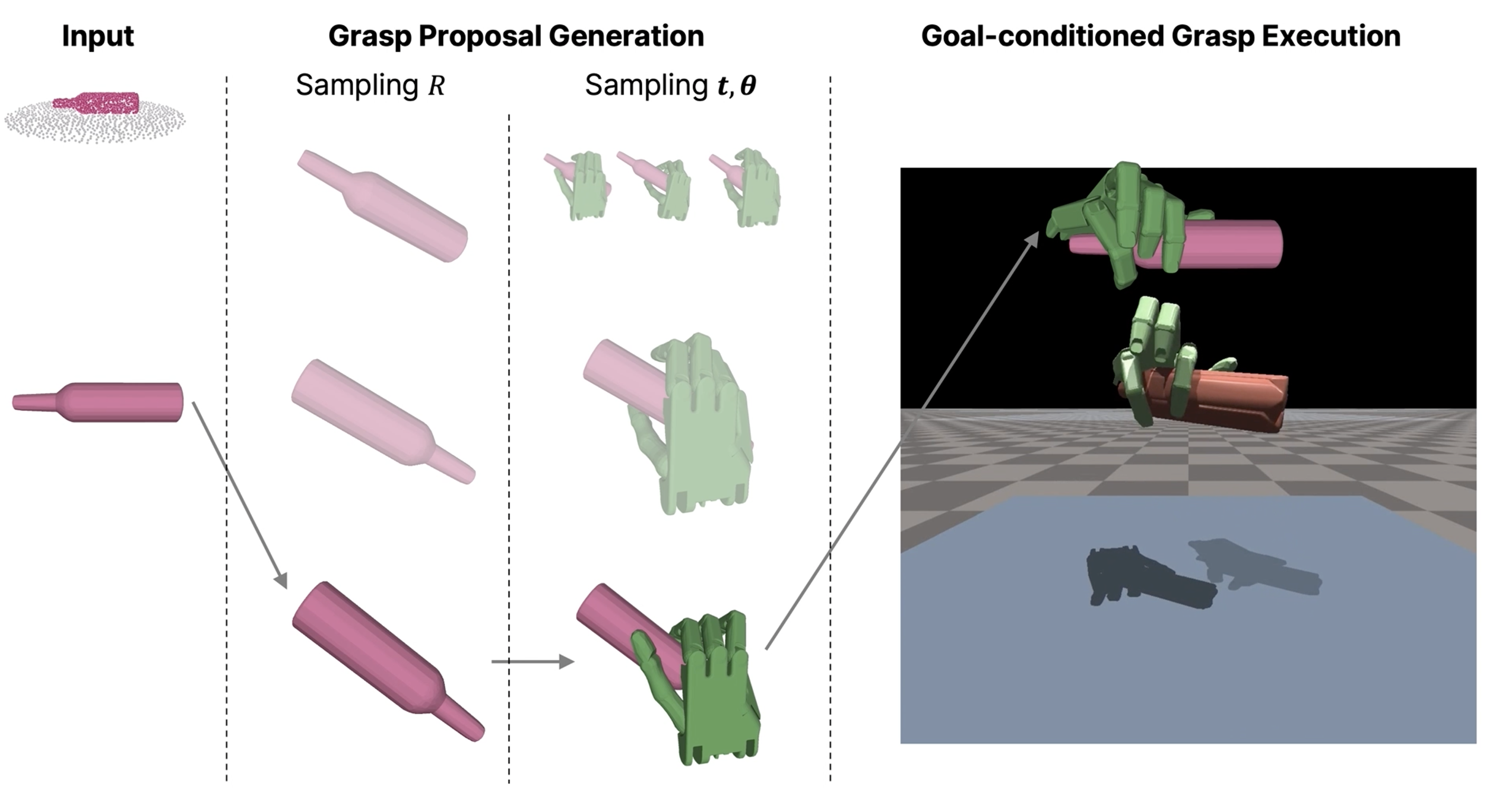
| UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy |
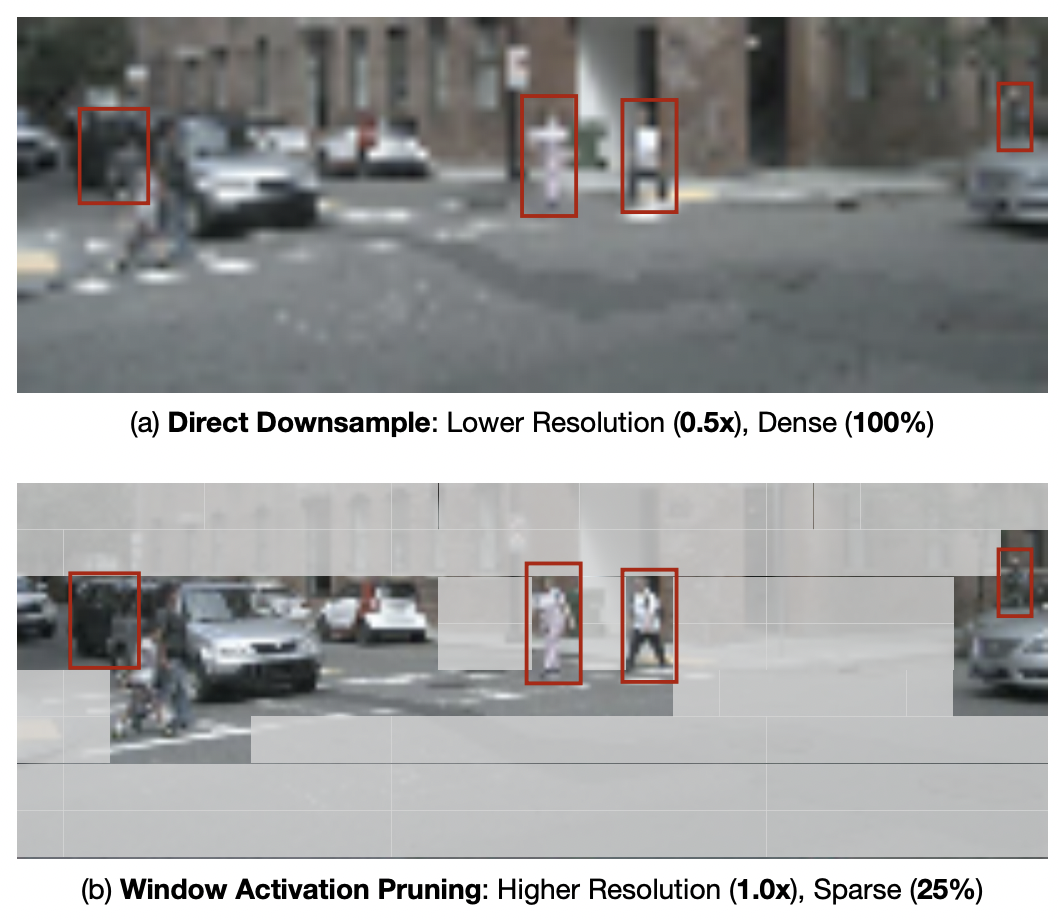
| SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer |
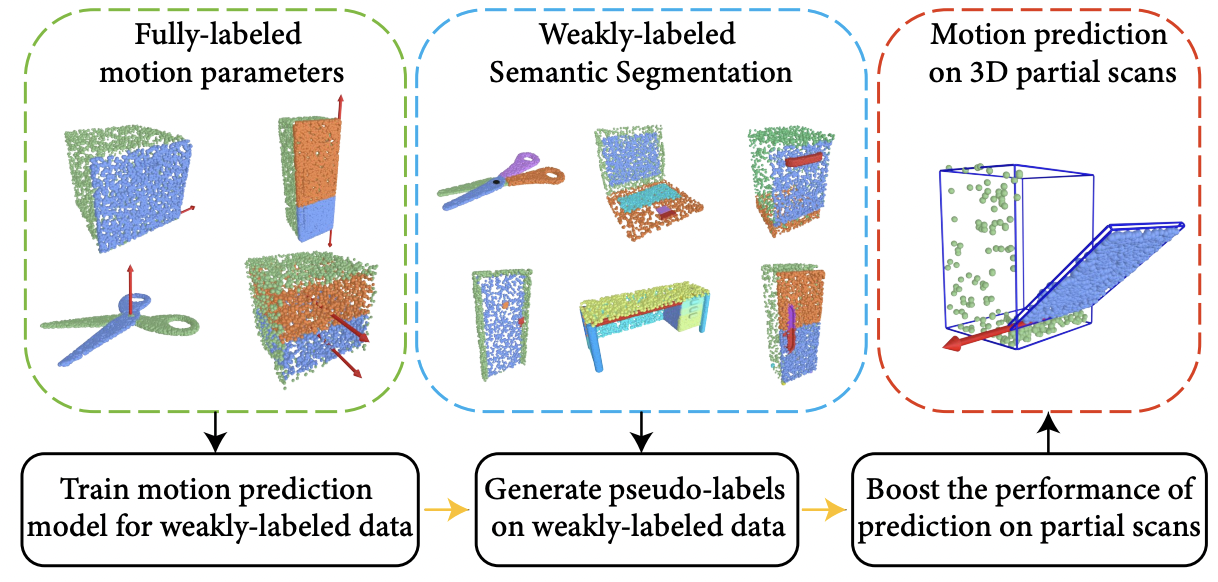
| Semi-Weakly Supervised Object Kinematic Motion Prediction |
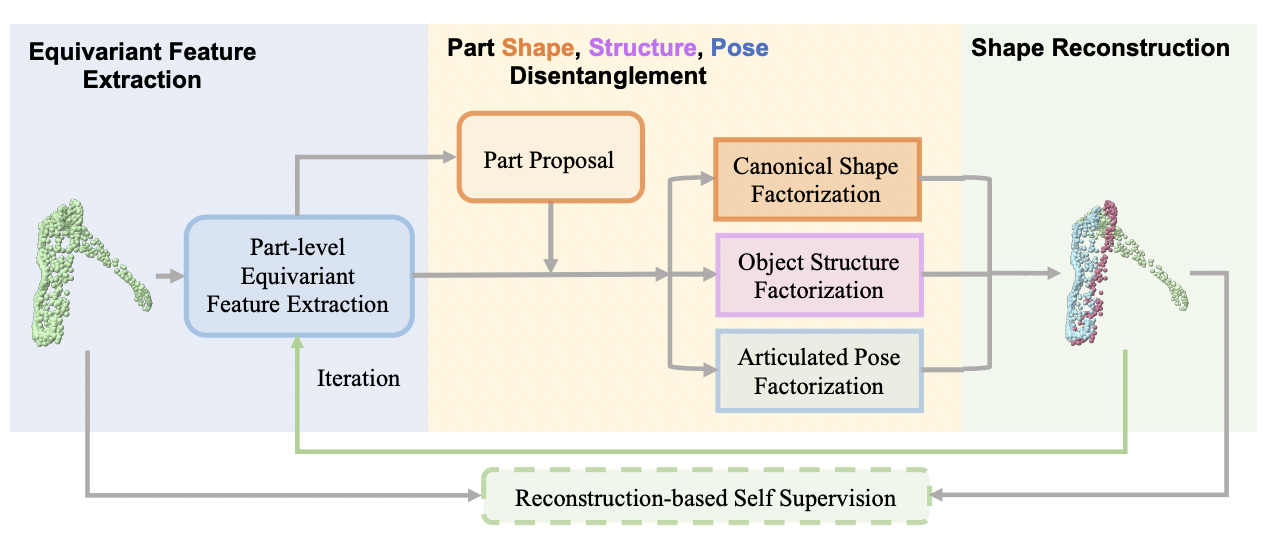
| Self-Supervised Category-Level Articulated Object Pose Estimation with Part-Level SE(3) Equivariance |
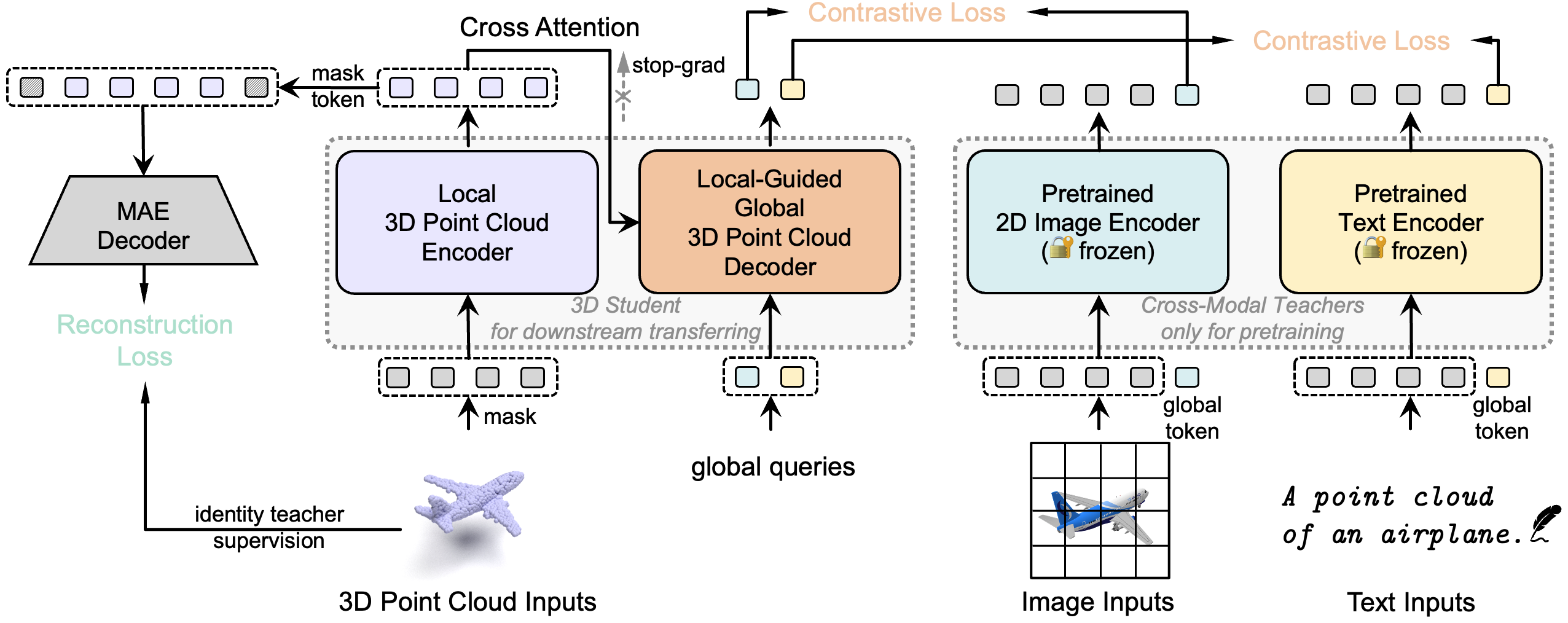
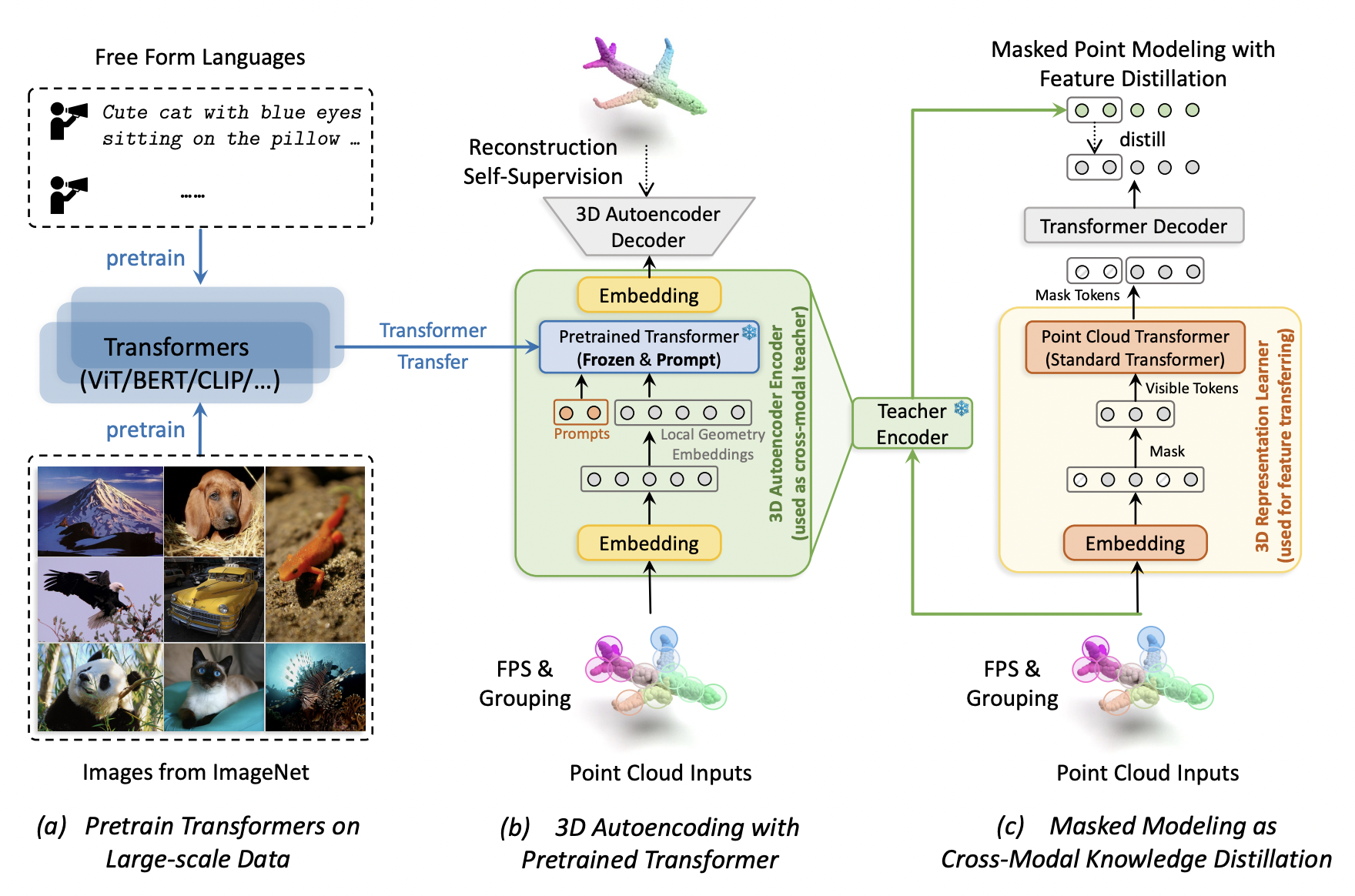
| Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning? |
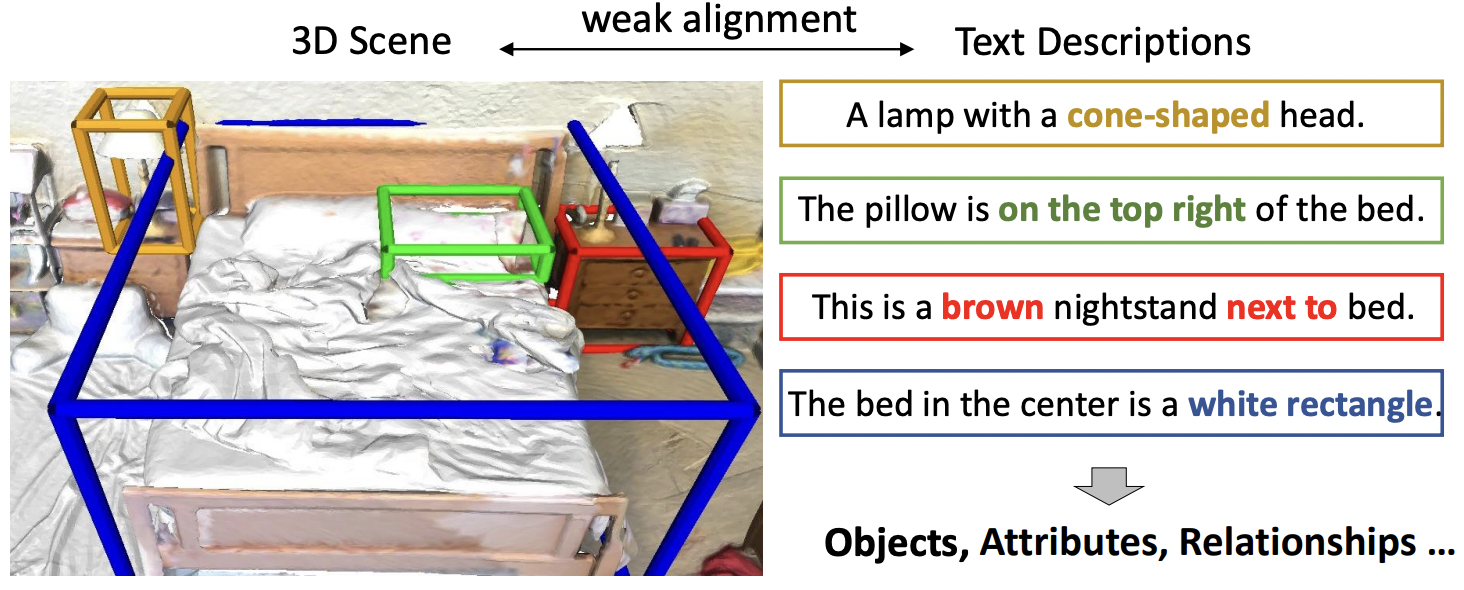
| Language-Assisted 3D Feature Learning for Semantic Scene Understanding |
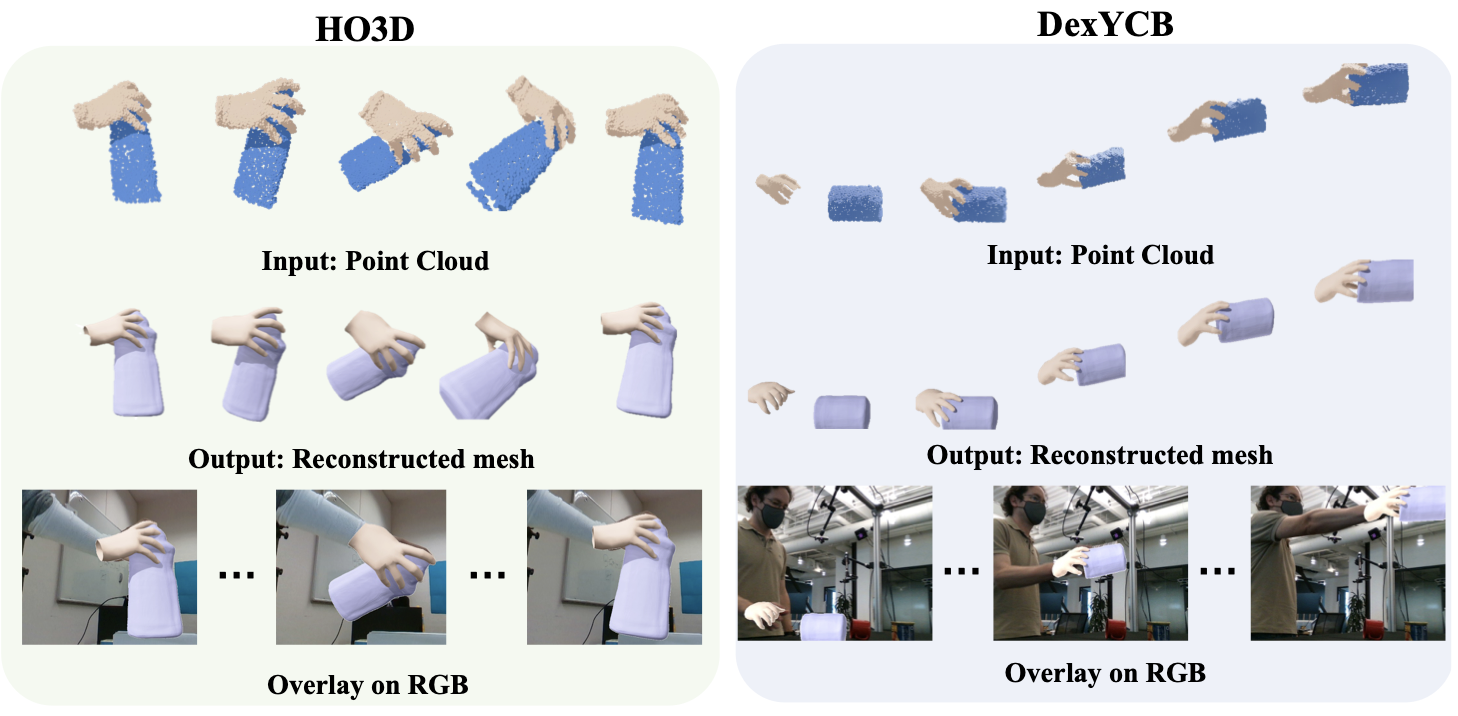
| Tracking and Reconstructing Hand Object Interactions from Point Cloud Sequences in the Wild |
| MoRig: Motion-Aware Rigging of Character Meshes from Point Clouds |
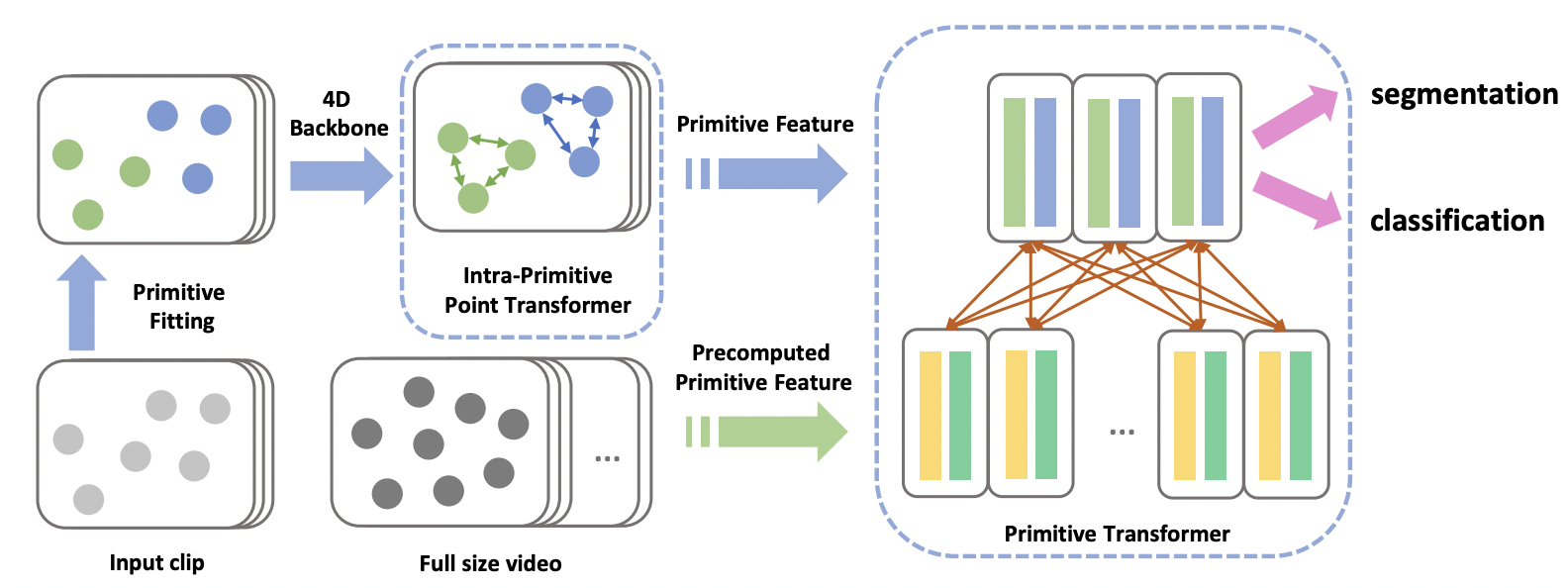
| Point Primitive Transformer for Long-Term 4D Point Cloud Video Understanding |
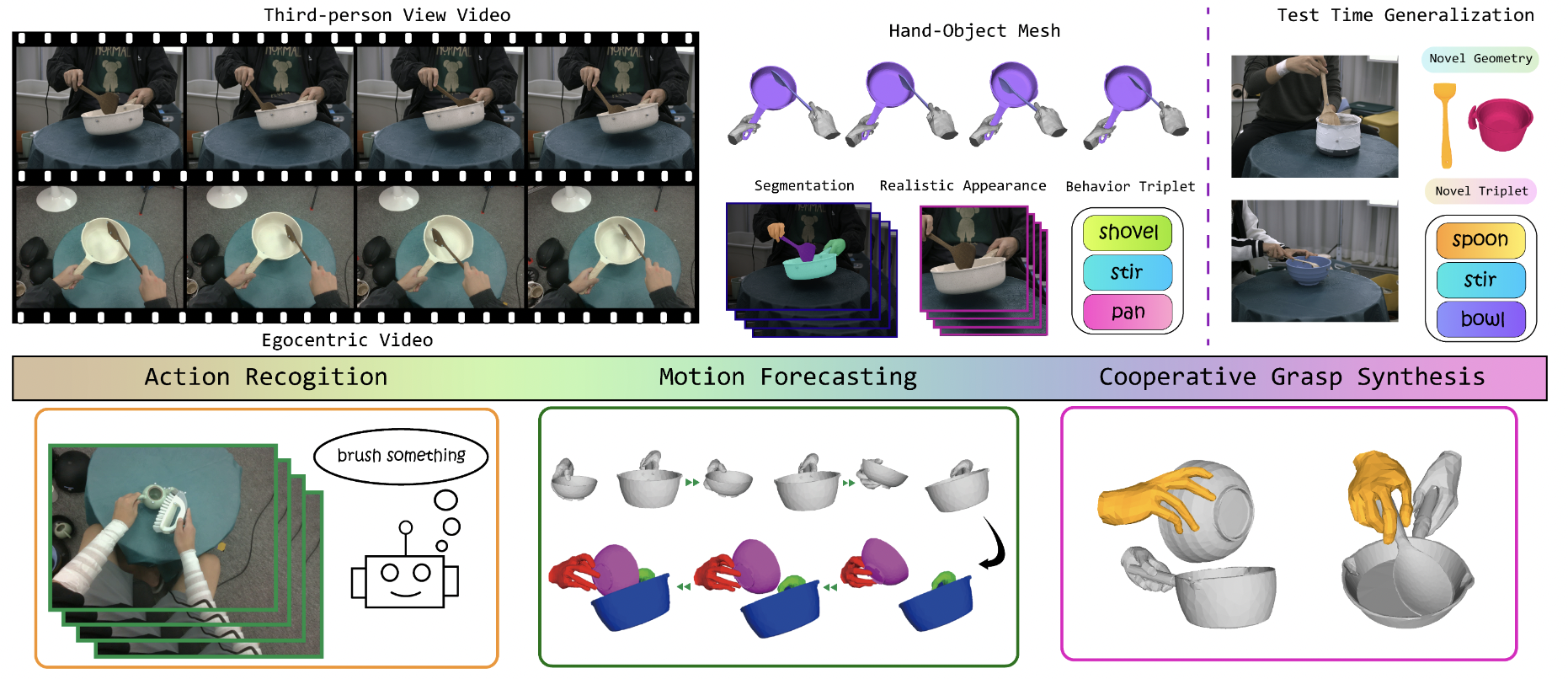
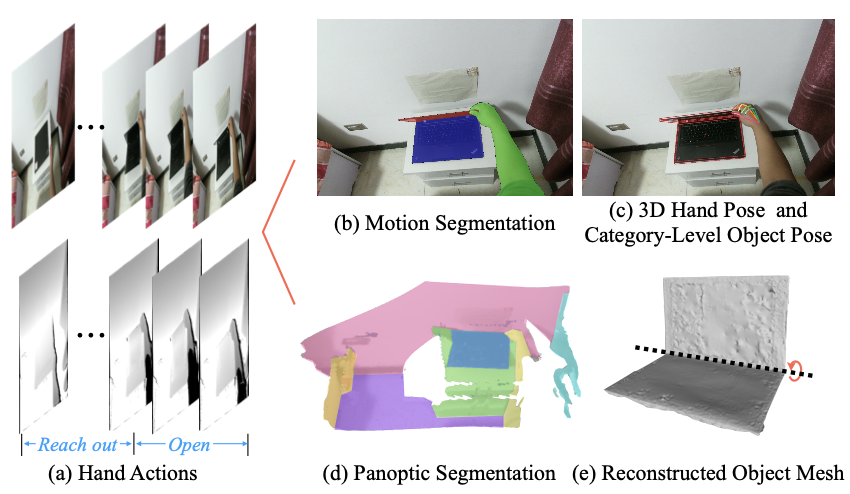
| HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction |
| Rotationally Equivariant 3D Object Detection |
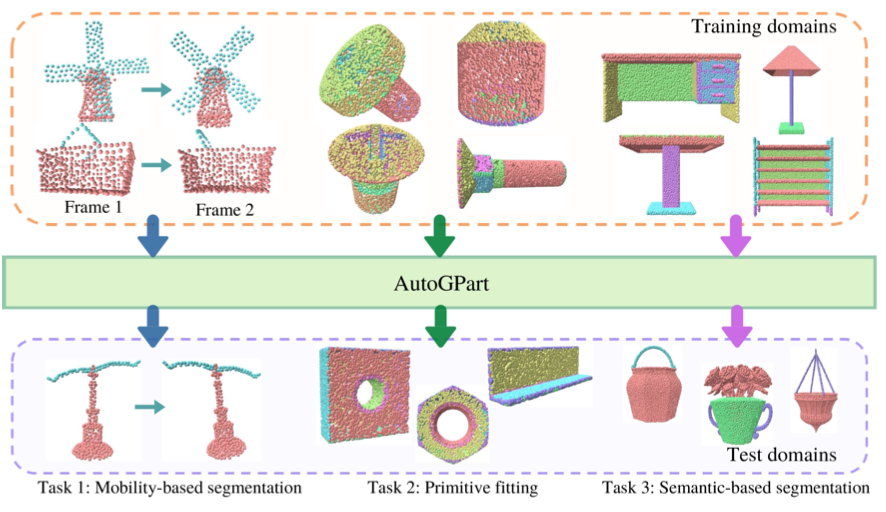
| AutoGPart: Intermediate Supervision Search for Generalizable 3D Part Segmentation |
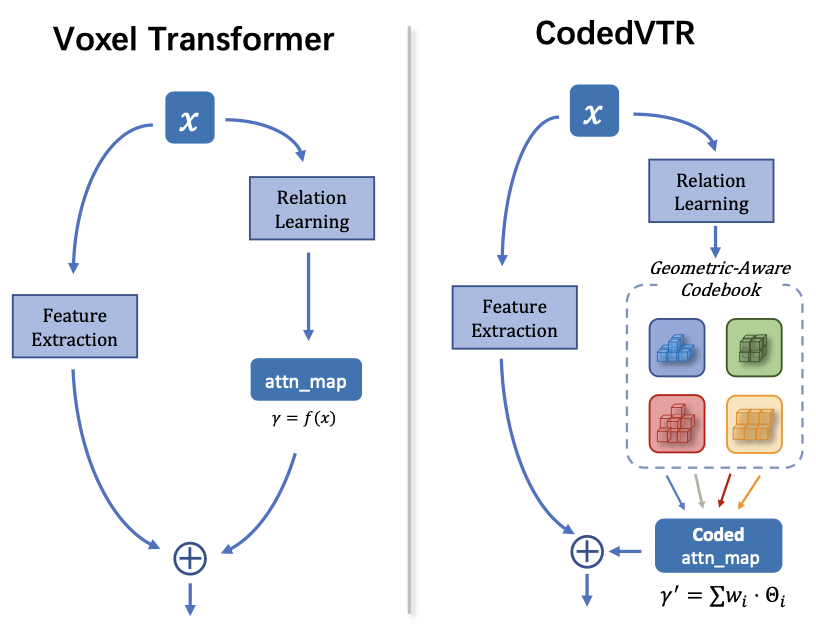
| CodedVTR: Codebook-based Sparse Voxel Transformer with Geometric Guidance |
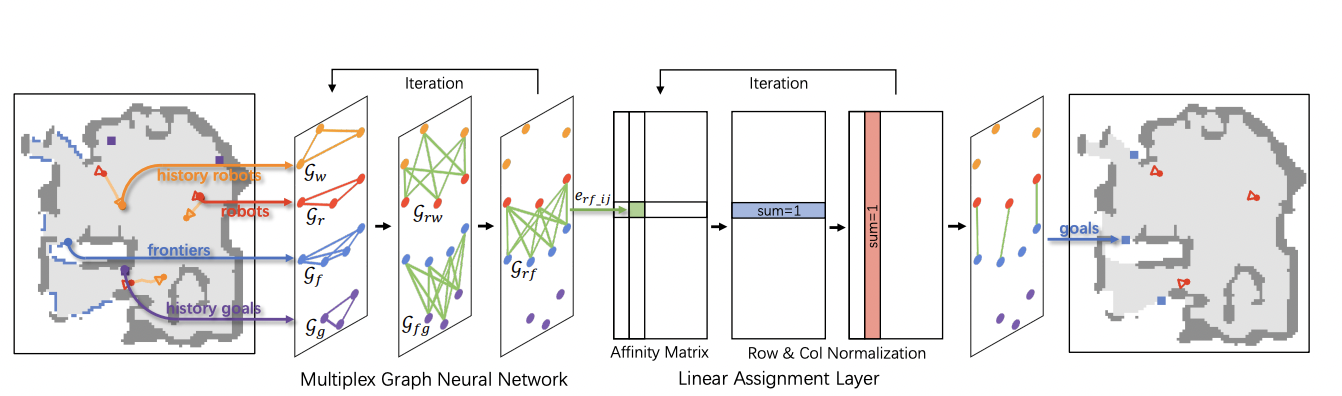
| Multi-Robot Active Mapping via Neural Bipartite Graph Matching |
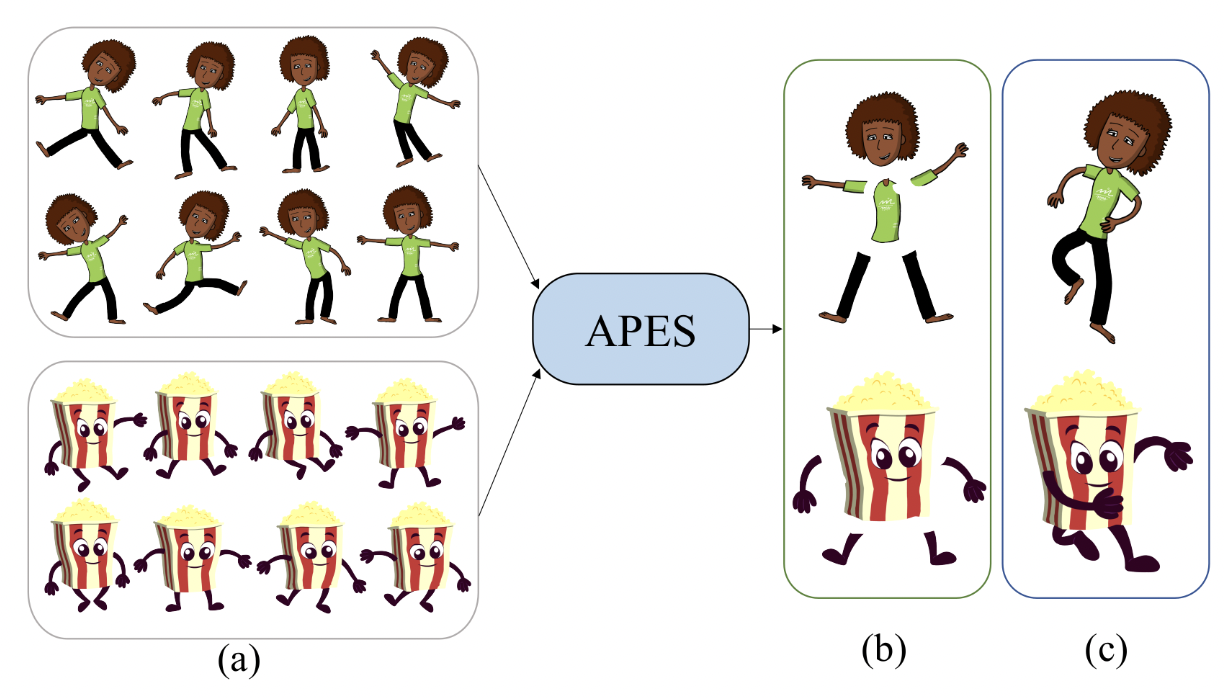
| APES: Articulated Part Extraction from Sprite Sheets |
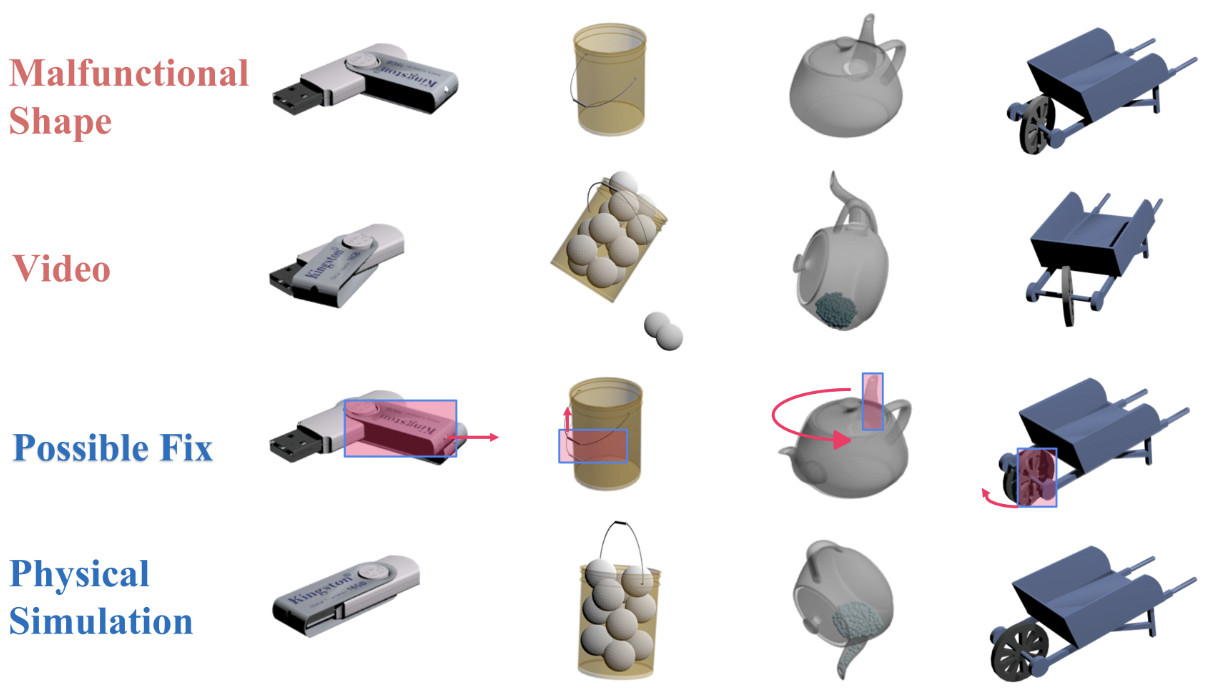
| Fixing Malfunctional Objects With Learned Physical Simulation and Functional Prediction |
| PTR: A Benchmark for Part-based Conceptual, Relational, and Physical Reasoning |
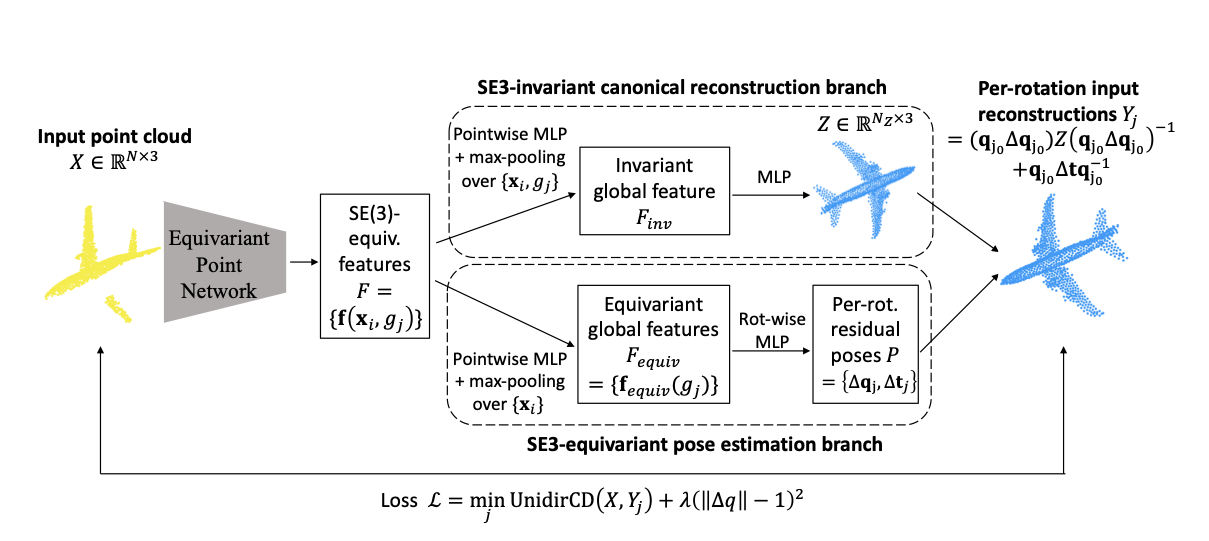
| Leveraging SE(3) Equivariance for Self-supervised Category-Level Object Pose Estimation from Point Clouds |
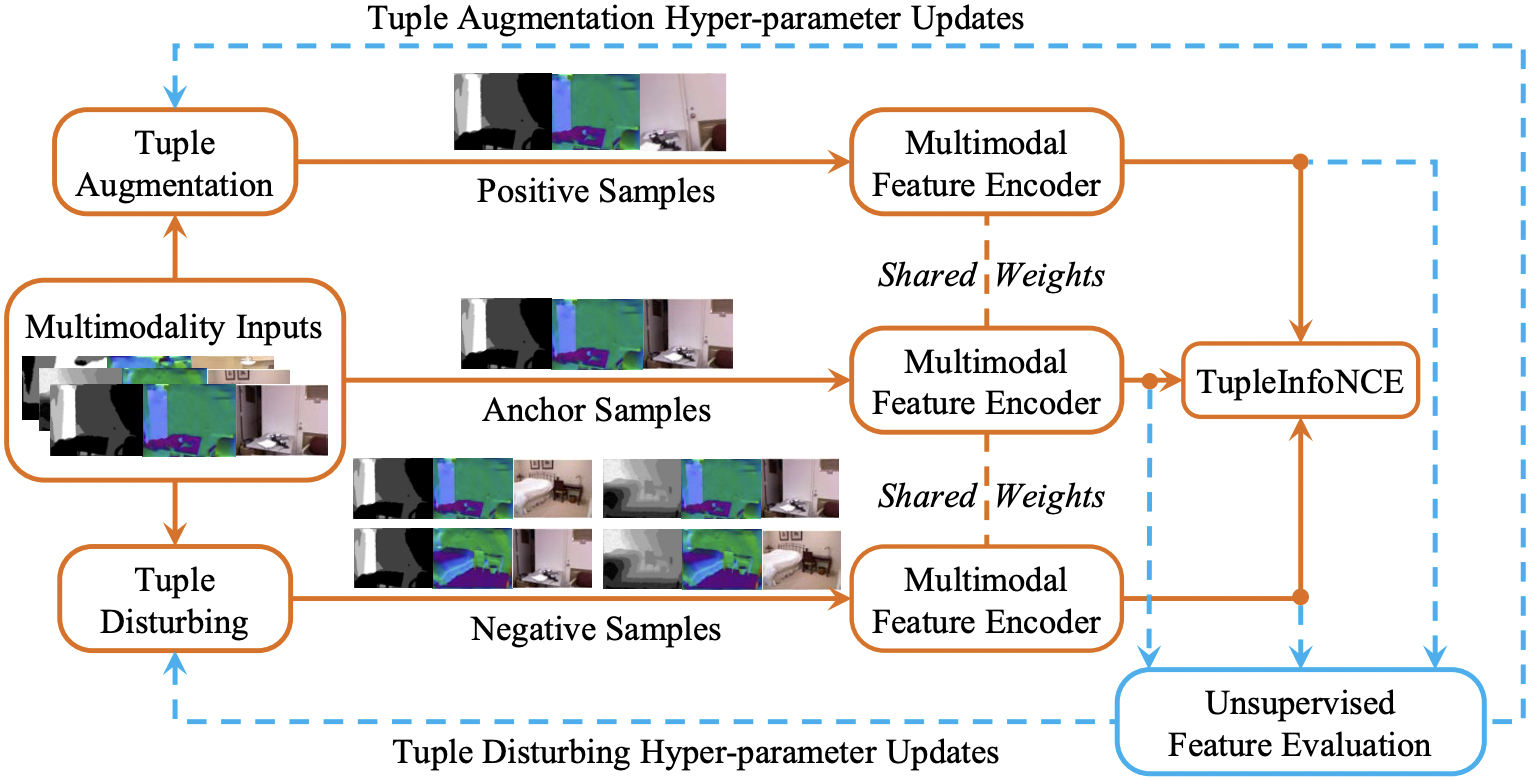
| Contrastive Multimodal Fusion with TupleInfoNCE |
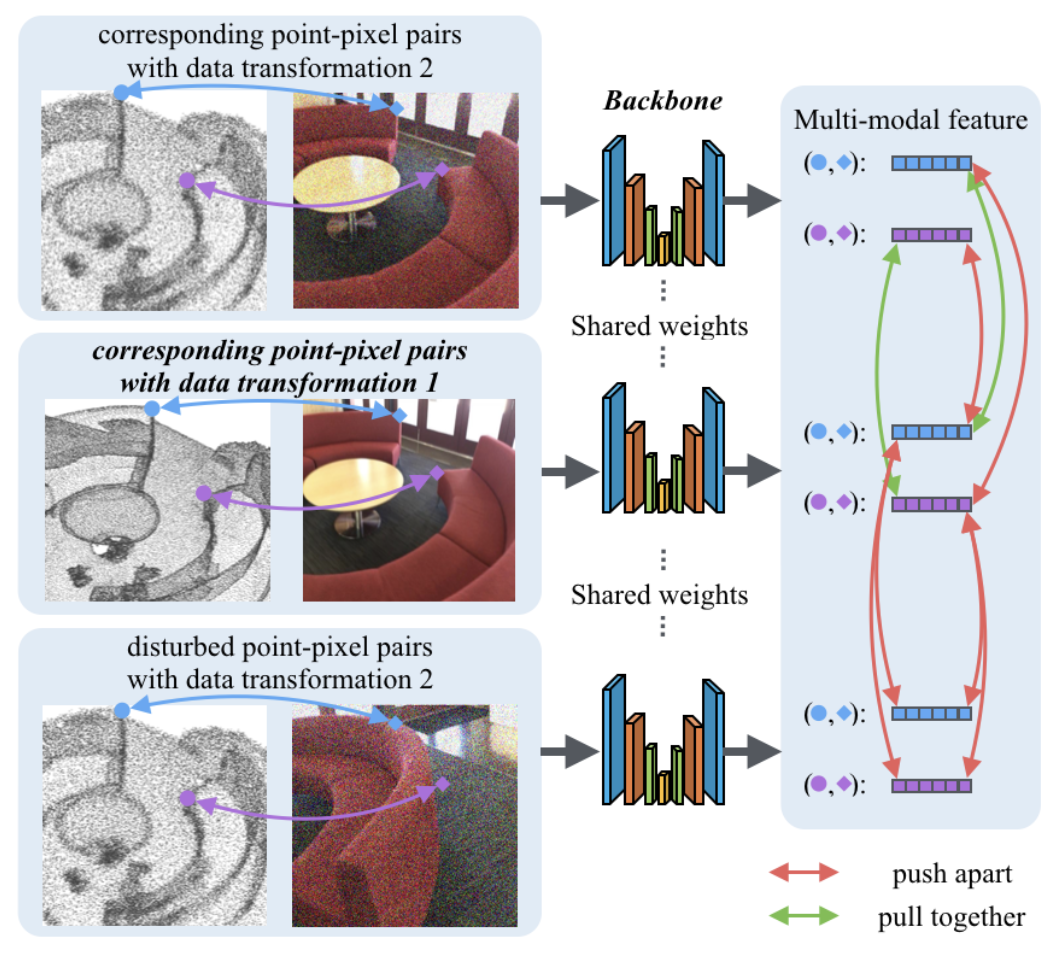
| P4Contrast: Contrastive Learning with Pairs of Point-Pixel Pairs for RGB-D Scene Understanding |
| Compositionally Generalizable 3D Structure Prediction |
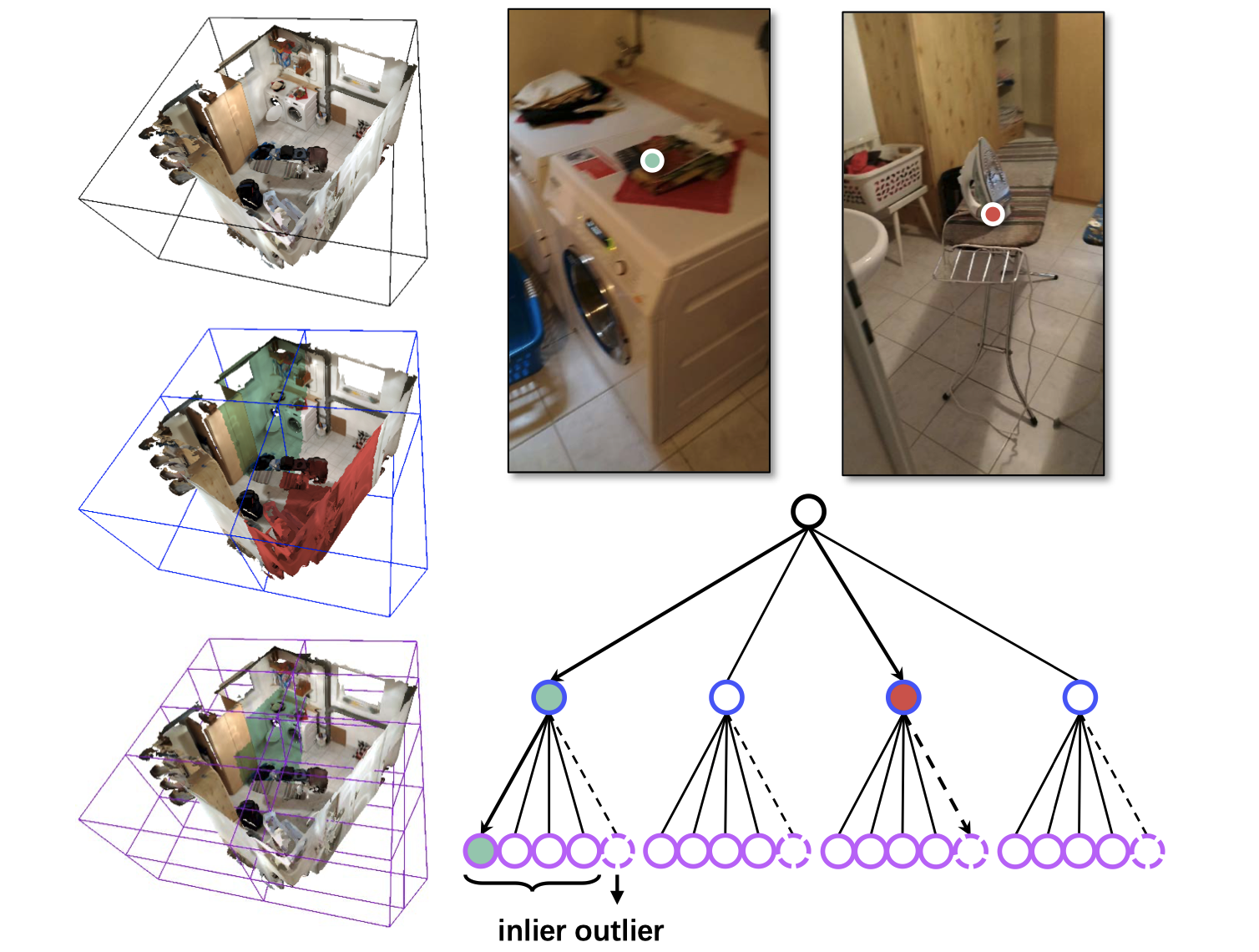
| Robust Neural Routing Through Space Partitions for Camera Relocalization in Dynamic Indoor Environments |
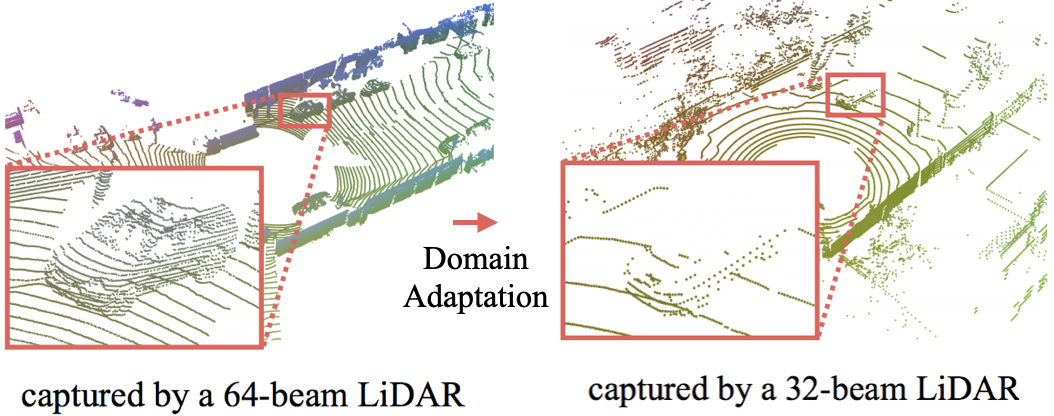
| Complete & Label: A Domain Adaptation Approach to Semantic Segmentation of LiDAR Point Clouds |
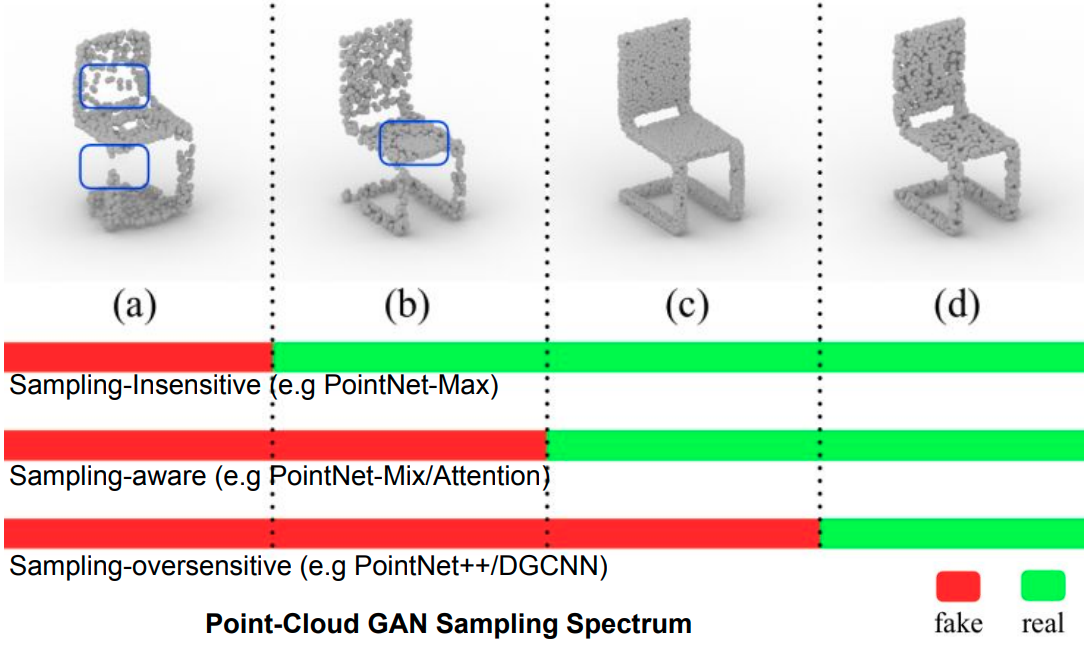
| Rethinking Sampling in 3D Point Cloud Generative Adversarial Networks |
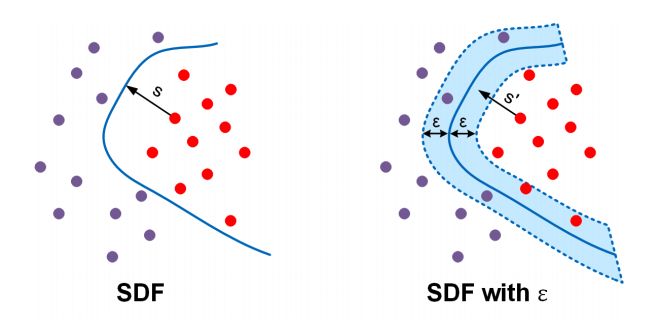
| Curriculum DeepSDF |
| SAPIEN: A SimulAted Part-based Interactive ENvironment |
| Category-Level Articulated Object Pose Estimation |
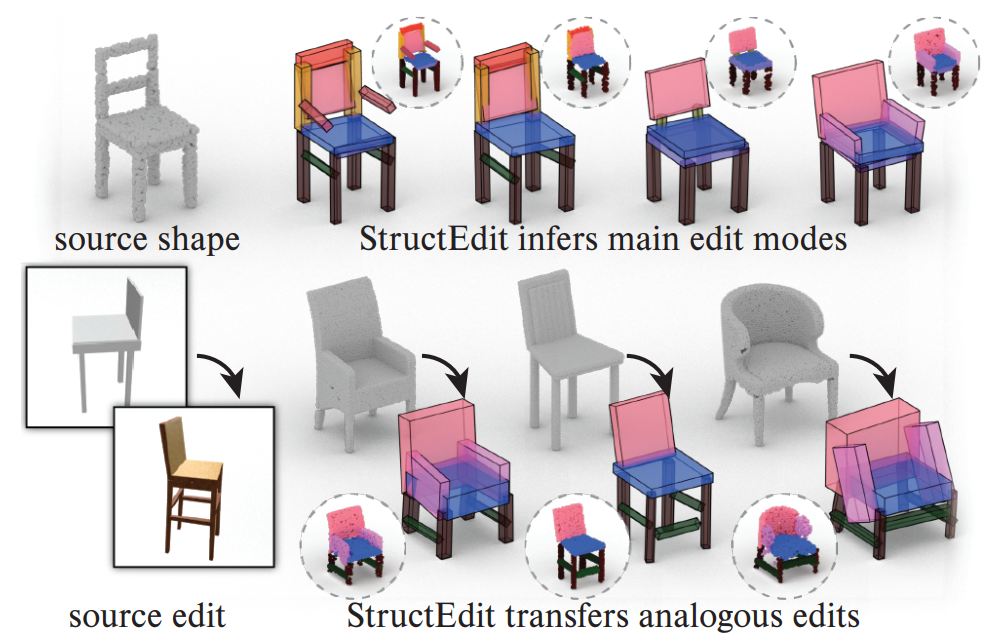
| StructEdit: Learning Structural Shape Variations |
| AdaCoSeg: Adaptive Shape Co-Segmentation with Group Consistency Loss |
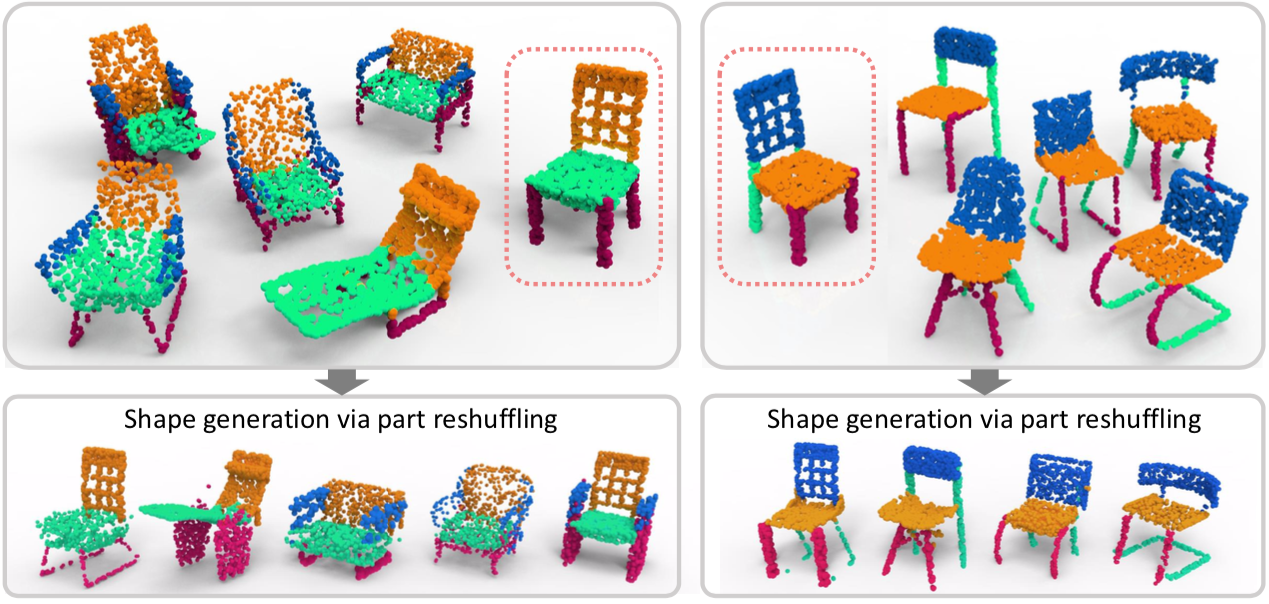
| StructureNet: Hierarchical Graph Networks for 3D Shape Generation |
| GSPN: Generative Shape Proposal Network for 3D Instance Segmentation in Point Cloud |
| TextureNet: Consistent Local Parametrizations for Learning from High-Resolution Signals on Meshes |
| Supervised Fitting of Geometric Primitives to 3D Point Clouds |
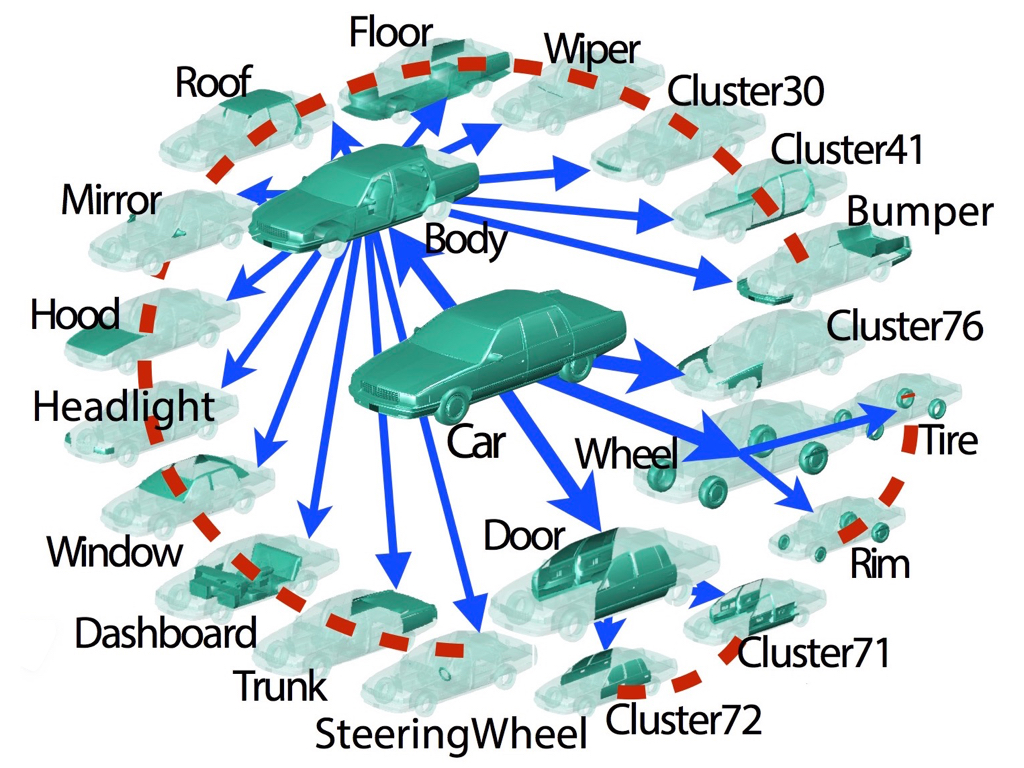
| PartNet: A Large-scale Benchmark for Fine-grained and Hierarchical Part-level 3D Object Understanding |
| GeoNet: Deep Geodesic Networks for Point Cloud Analysis |
| Deep Part Induction from Articulated Object Pairs |
| Beyond Holistic Object Recognition: Enriching Image Understanding with Part States |
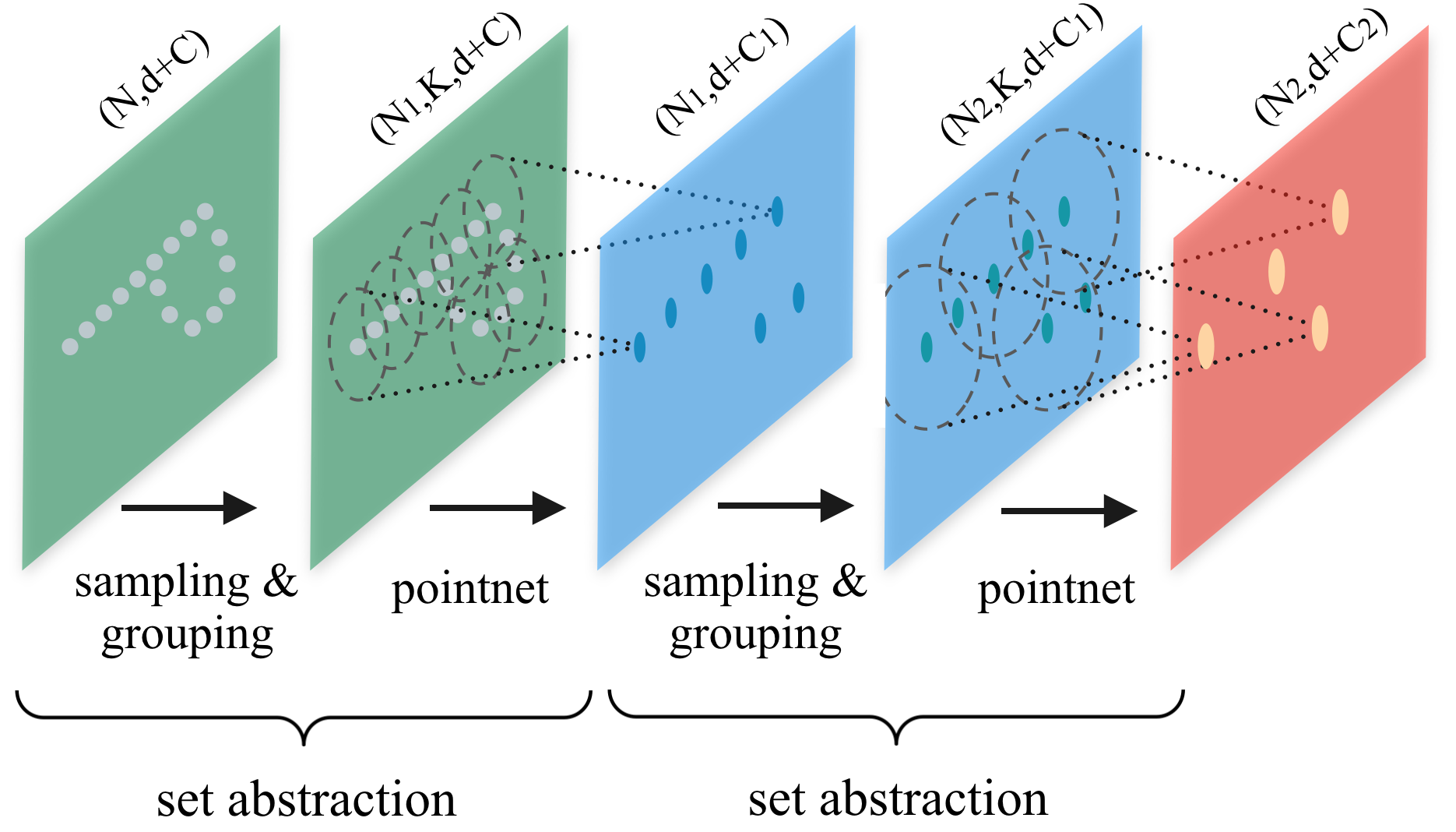
| PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space |
| Learning Hierarchical Shape Segmentation and Labeling from Online Repositories |
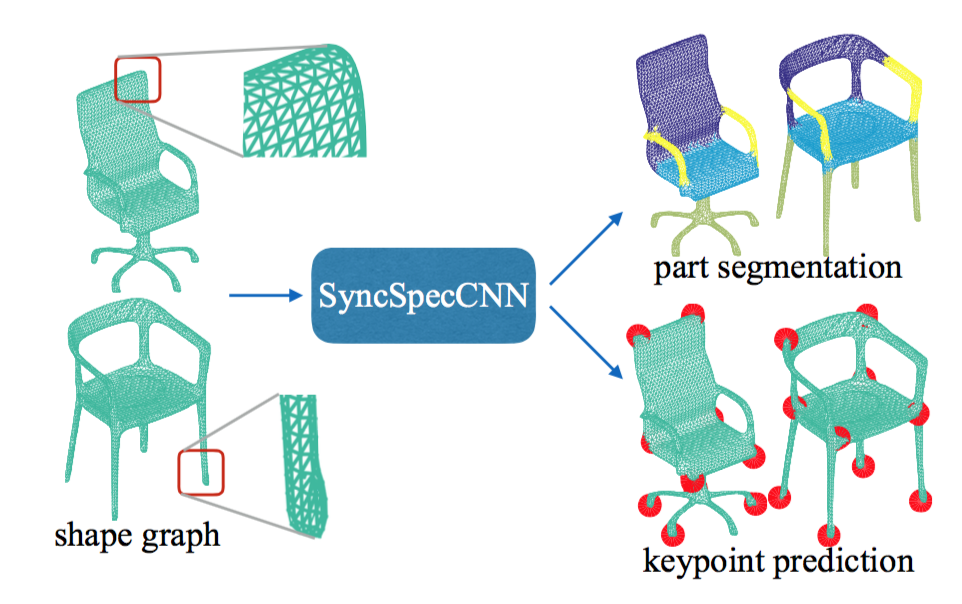
| SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation |
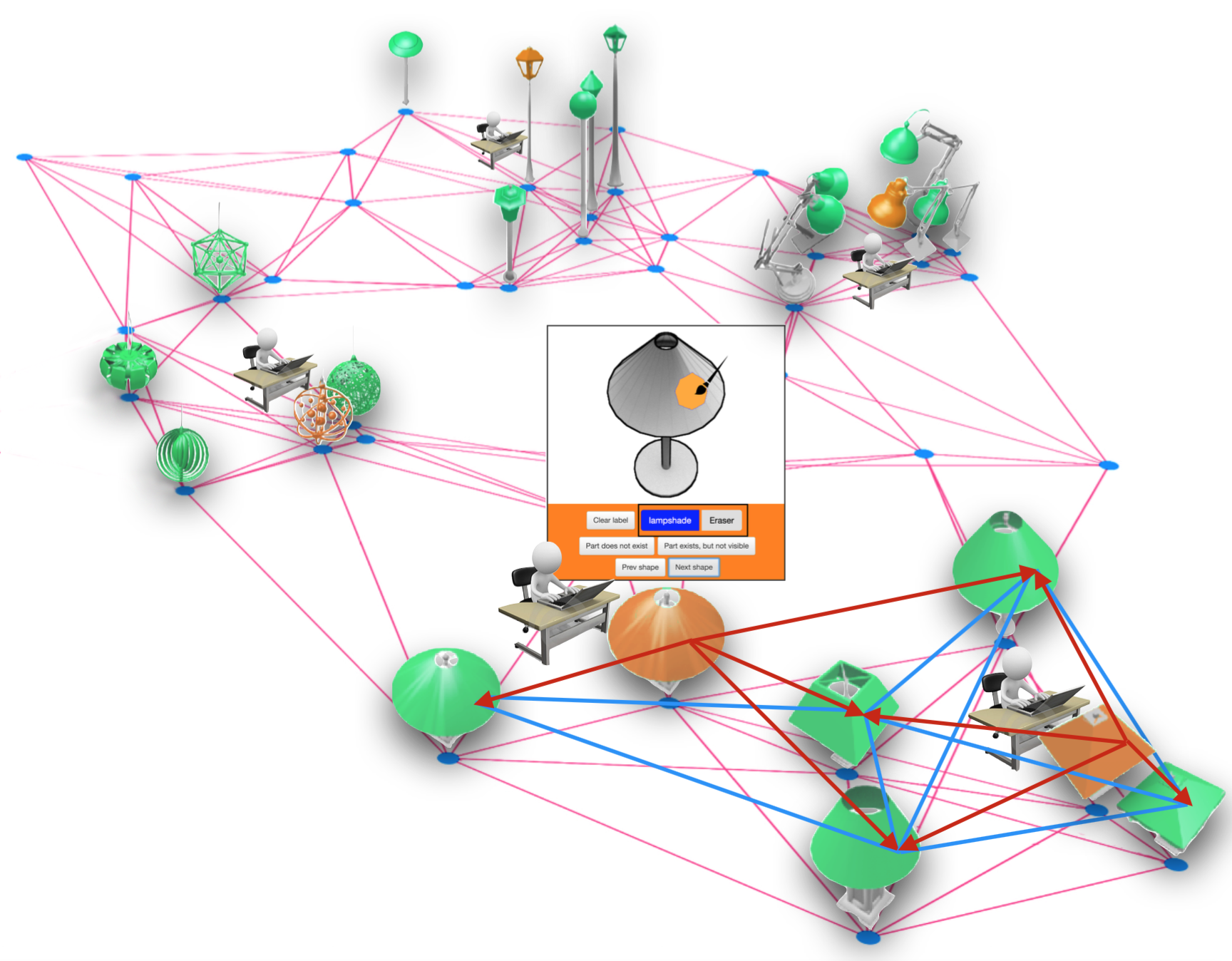
| A Scalable Active Framework for Region Annotation in 3D Shape Collections |
| ShapeNet: An Information-Rich 3D Model Repository |
| 3D-Assisted Image Feature Synthesis for Novel Views of an Object |
| Image Super-Resolution Via Analysis Sparse Prior |