Track experiments
6 minute read
기계 학습 실험 추적, 모델 체크포인트, 팀과의 협업 등을 위해 W&B 를 사용하세요.
이 노트북에서는 간단한 PyTorch 모델을 사용하여 기계 학습 실험을 생성하고 추적합니다. 노트북이 끝나면 팀의 다른 구성원과 공유하고 사용자 정의할 수 있는 대화형 프로젝트 대시보드를 갖게 됩니다. 여기에서 대시보드 예제를 확인하세요.
전제 조건
W&B Python SDK를 설치하고 로그인합니다:
!pip install wandb -qU # W&B 계정에 로그인하세요 import wandb import random import math # wandb-core 사용, wandb의 새로운 백엔드를 위해 임시적으로 사용 wandb.require("core") wandb.login() W&B를 사용하여 기계 학습 실험을 시뮬레이션하고 추적합니다
기계 학습 실험을 생성, 추적 및 시각화합니다. 이렇게 하려면 다음을 수행하세요:
- W&B run을 초기화하고 추적하려는 하이퍼파라미터를 전달합니다.
- 트레이닝 루프 내에서 정확도 및 손실과 같은 메트릭을 기록합니다.
import random import math # 5개의 시뮬레이션된 실험을 시작합니다 total_runs = 5 for run in range(total_runs): # 1️. 이 스크립트를 추적하기 위해 새 run을 시작합니다 wandb.init( # 이 run이 기록될 프로젝트를 설정합니다 project="basic-intro", # run 이름을 전달합니다 (그렇지 않으면 sunshine-lollypop-10처럼 무작위로 할당됩니다) name=f"experiment_{run}", # 하이퍼파라미터 및 run 메타데이터를 추적합니다 config={ "learning_rate": 0.02, "architecture": "CNN", "dataset": "CIFAR-100", "epochs": 10, }) # 이 간단한 블록은 메트릭을 기록하는 트레이닝 루프를 시뮬레이션합니다 epochs = 10 offset = random.random() / 5 for epoch in range(2, epochs): acc = 1 - 2 ** -epoch - random.random() / epoch - offset loss = 2 ** -epoch + random.random() / epoch + offset # 2️. 스크립트에서 W&B로 메트릭을 기록합니다 wandb.log({"acc": acc, "loss": loss}) # run을 완료된 것으로 표시합니다 wandb.finish() W&B 프로젝트에서 기계 학습이 어떻게 수행되었는지 확인합니다. 이전 셀에서 인쇄된 URL 링크를 복사하여 붙여넣습니다. URL은 그래프가 표시된 대시보드를 포함하는 W&B 프로젝트로 리디렉션됩니다.
다음 이미지는 대시보드가 어떻게 보이는지 보여줍니다:
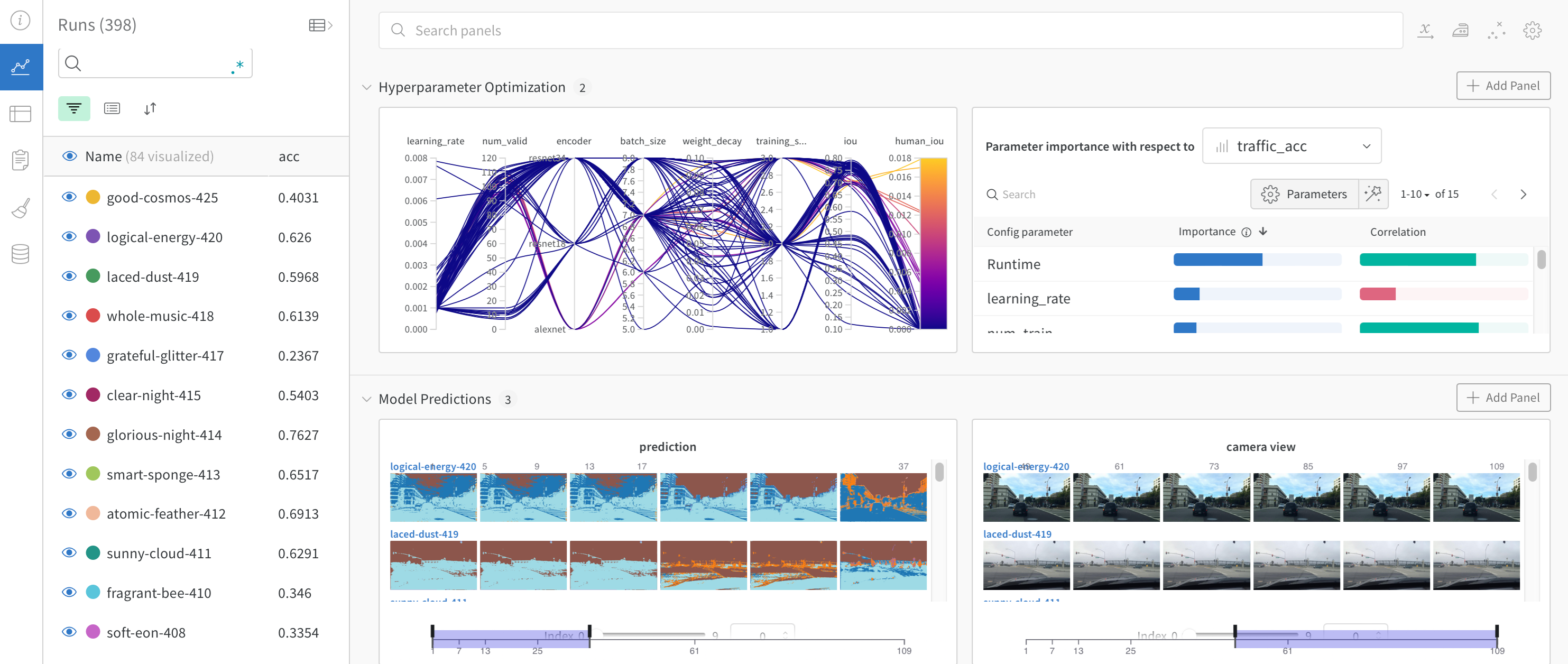
이제 W&B를 유사 기계 학습 트레이닝 루프에 통합하는 방법을 알았으니 기본 PyTorch 신경망을 사용하여 기계 학습 실험을 추적해 보겠습니다. 다음 코드는 조직의 다른 팀과 공유할 수 있는 모델 체크포인트를 W&B에 업로드합니다.
Pytorch를 사용하여 기계 학습 실험 추적
다음 코드 셀은 간단한 MNIST 분류기를 정의하고 트레이닝합니다. 트레이닝하는 동안 W&B가 URL을 출력하는 것을 볼 수 있습니다. 프로젝트 페이지 링크를 클릭하여 결과가 W&B 프로젝트로 실시간 스트리밍되는 것을 확인하세요.
W&B run은 자동으로 메트릭, 시스템 정보, 하이퍼파라미터, 터미널 출력을 기록하고 모델 입력 및 출력이 있는 대화형 테이블이 표시됩니다.
PyTorch Dataloader 설정
다음 셀은 기계 학습 모델을 트레이닝하는 데 필요한 유용한 함수를 정의합니다. 함수 자체는 W&B에 고유하지 않으므로 여기서는 자세히 다루지 않습니다. forward 패스 및 backward 트레이닝 루프를 정의하는 방법, PyTorch DataLoaders를 사용하여 트레이닝을 위해 데이터를 로드하는 방법, torch.nn.Sequential 클래스를 사용하여 PyTorch 모델을 정의하는 방법에 대한 자세한 내용은 PyTorch 설명서를 참조하세요.
# @title import torch, torchvision import torch.nn as nn from torchvision.datasets import MNIST import torchvision.transforms as T MNIST.mirrors = [ mirror for mirror in MNIST.mirrors if "http://yann.lecun.com/" not in mirror ] device = "cuda:0" if torch.cuda.is_available() else "cpu" def get_dataloader(is_train, batch_size, slice=5): "트레이닝 데이터로더를 가져옵니다" full_dataset = MNIST( root=".", train=is_train, transform=T.ToTensor(), download=True ) sub_dataset = torch.utils.data.Subset( full_dataset, indices=range(0, len(full_dataset), slice) ) loader = torch.utils.data.DataLoader( dataset=sub_dataset, batch_size=batch_size, shuffle=True if is_train else False, pin_memory=True, num_workers=2, ) return loader def get_model(dropout): "간단한 모델" model = nn.Sequential( nn.Flatten(), nn.Linear(28 * 28, 256), nn.BatchNorm1d(256), nn.ReLU(), nn.Dropout(dropout), nn.Linear(256, 10), ).to(device) return model def validate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0): "유효성 검사 데이터셋에서 모델의 성능을 계산하고 wandb.Table을 기록합니다" model.eval() val_loss = 0.0 with torch.inference_mode(): correct = 0 for i, (images, labels) in enumerate(valid_dl): images, labels = images.to(device), labels.to(device) # Forward 패스 ➡ outputs = model(images) val_loss += loss_func(outputs, labels) * labels.size(0) # 정확도 계산 및 누적 _, predicted = torch.max(outputs.data, 1) correct += (predicted == labels).sum().item() # 항상 동일한 batch_idx로 대시보드에 이미지 한 배치를 기록합니다. if i == batch_idx and log_images: log_image_table(images, predicted, labels, outputs.softmax(dim=1)) return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset) 예측값과 실제값을 비교하는 테이블 생성
다음 셀은 W&B에 고유하므로 살펴보겠습니다.
셀에서 log_image_table이라는 함수를 정의합니다. 기술적으로 선택 사항이지만 이 함수는 W&B Table 오브젝트를 만듭니다. 테이블 오브젝트를 사용하여 각 이미지에 대해 모델이 예측한 내용을 보여주는 테이블을 만듭니다.
보다 구체적으로 말하면 각 행은 모델에 공급된 이미지와 예측값 및 실제값 (레이블)으로 구성됩니다.
def log_image_table(images, predicted, labels, probs): "이미지, 레이블 및 예측이 포함된 wandb.Table을 기록합니다 (img, pred, target, scores)" # 이미지, 레이블 및 예측을 기록할 wandb Table을 만듭니다. table = wandb.Table( columns=["image", "pred", "target"] + [f"score_{i}" for i in range(10)] ) for img, pred, targ, prob in zip( images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu") ): table.add_data(wandb.Image(img[0].numpy() * 255), pred, targ, *prob.numpy()) wandb.log({"predictions_table": table}, commit=False) 모델을 트레이닝하고 체크포인트를 업로드합니다
다음 코드는 모델 체크포인트를 트레이닝하고 프로젝트에 저장합니다. 일반적으로 모델 체크포인트를 사용하여 트레이닝 중에 모델이 수행된 방식을 평가합니다.
W&B를 사용하면 저장된 모델 및 모델 체크포인트를 팀 또는 조직의 다른 구성원과 쉽게 공유할 수 있습니다. 팀 외부의 구성원과 모델 및 모델 체크포인트를 공유하는 방법에 대한 자세한 내용은 W&B Registry를 참조하세요.
# 다양한 드롭아웃 비율을 시도하면서 3개의 실험을 시작합니다. for _ in range(3): # wandb run을 초기화합니다. wandb.init( project="pytorch-intro", config={ "epochs": 5, "batch_size": 128, "lr": 1e-3, "dropout": random.uniform(0.01, 0.80), }, ) # 구성을 복사합니다. config = wandb.config # 데이터를 가져옵니다. train_dl = get_dataloader(is_train=True, batch_size=config.batch_size) valid_dl = get_dataloader(is_train=False, batch_size=2 * config.batch_size) n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size) # 간단한 MLP 모델 model = get_model(config.dropout) # 손실 및 옵티마이저를 만듭니다. loss_func = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=config.lr) # 트레이닝 example_ct = 0 step_ct = 0 for epoch in range(config.epochs): model.train() for step, (images, labels) in enumerate(train_dl): images, labels = images.to(device), labels.to(device) outputs = model(images) train_loss = loss_func(outputs, labels) optimizer.zero_grad() train_loss.backward() optimizer.step() example_ct += len(images) metrics = { "train/train_loss": train_loss, "train/epoch": (step + 1 + (n_steps_per_epoch * epoch)) / n_steps_per_epoch, "train/example_ct": example_ct, } if step + 1 < n_steps_per_epoch: # wandb에 트레이닝 메트릭을 기록합니다. wandb.log(metrics) step_ct += 1 val_loss, accuracy = validate_model( model, valid_dl, loss_func, log_images=(epoch == (config.epochs - 1)) ) # wandb에 트레이닝 및 유효성 검사 메트릭을 기록합니다. val_metrics = {"val/val_loss": val_loss, "val/val_accuracy": accuracy} wandb.log({**metrics, **val_metrics}) # wandb에 모델 체크포인트를 저장합니다. torch.save(model, "my_model.pt") wandb.log_model( "./my_model.pt", "my_mnist_model", aliases=[f"epoch-{epoch+1}_dropout-{round(wandb.config.dropout, 4)}"], ) print( f"Epoch: {epoch+1}, Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}" ) # 테스트 세트가 있는 경우 요약 메트릭으로 기록할 수 있는 방법입니다. wandb.summary["test_accuracy"] = 0.8 # wandb run을 닫습니다. wandb.finish() 이제 W&B를 사용하여 첫 번째 모델을 트레이닝했습니다. 위의 링크 중 하나를 클릭하여 메트릭을 확인하고 W&B App UI의 Artifacts 탭에서 저장된 모델 체크포인트를 확인하세요.
(선택 사항) W&B Alert 설정
Python 코드에서 Slack 또는 이메일로 알림을 보내도록 W&B Alerts를 만듭니다.
코드에서 트리거된 Slack 또는 이메일 알림을 처음 보내려면 다음 두 단계를 따르세요.
- W&B 사용자 설정에서 Alerts를 켭니다.
- 코드에
wandb.alert()를 추가합니다. 예를 들어:
wandb.alert(title="Low accuracy", text=f"Accuracy is below the acceptable threshold") 다음 셀은 wandb.alert를 사용하는 방법을 보여주는 최소한의 예제를 보여줍니다.
# wandb run을 시작합니다. wandb.init(project="pytorch-intro") # 모델 트레이닝 루프 시뮬레이션 acc_threshold = 0.3 for training_step in range(1000): # 정확도에 대한 임의의 숫자를 생성합니다. accuracy = round(random.random() + random.random(), 3) print(f"Accuracy is: {accuracy}, {acc_threshold}") # wandb에 정확도를 기록합니다. wandb.log({"Accuracy": accuracy}) # 정확도가 임계값보다 낮으면 W&B Alert를 실행하고 run을 중지합니다. if accuracy <= acc_threshold: # wandb Alert를 보냅니다. wandb.alert( title="Low Accuracy", text=f"Accuracy {accuracy} at step {training_step} is below the acceptable theshold, {acc_threshold}", ) print("Alert triggered") break # run을 완료된 것으로 표시합니다 (Jupyter 노트북에서 유용합니다). wandb.finish() 여기에서 W&B Alerts에 대한 전체 문서를 찾을 수 있습니다.
다음 단계
다음 튜토리얼에서는 W&B Sweeps를 사용하여 하이퍼파라미터 최적화를 수행하는 방법을 배웁니다. PyTorch를 사용하여 하이퍼파라미터 스윕
피드백
이 페이지가 도움이 되었나요?
Glad to hear it! If you have more to say, please let us know.
Sorry to hear that. Please tell us how we can improve.