Hugging Face Diffusers
5 minute read
Hugging Face Diffusers는 이미지, 오디오, 심지어 분자의 3D 구조를 생성하기 위한 최첨단 사전학습된 diffusion model을 위한 라이브러리입니다. Weights & Biases 인테그레이션은 사용 편의성을 유지하면서도 대화형 중앙 집중식 대시보드에 풍부하고 유연한 실험 추적, 미디어 시각화, 파이프라인 아키텍처 및 설정 관리를 추가합니다.
단 두 줄로 차원이 다른 로깅을 경험하세요
단 2줄의 코드를 추가하는 것만으로도 실험과 관련된 모든 프롬프트, 부정적 프롬프트, 생성된 미디어 및 설정을 기록할 수 있습니다. 다음은 로깅을 시작하기 위한 2줄의 코드입니다.
# import the autolog function from wandb.integration.diffusers import autolog # call the autolog before calling the pipeline autolog(init=dict(project="diffusers_logging")) 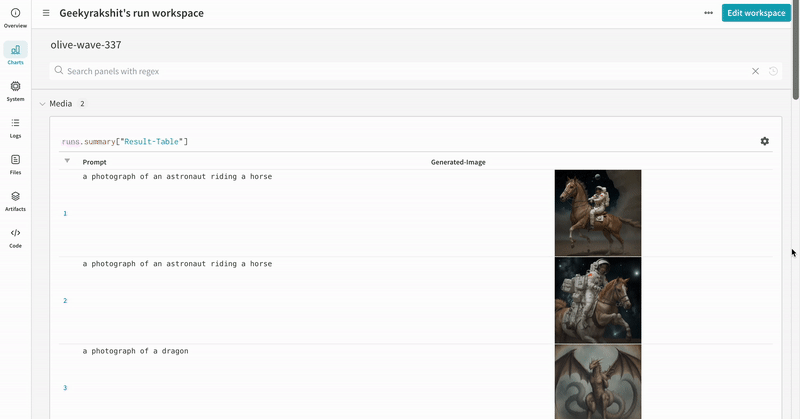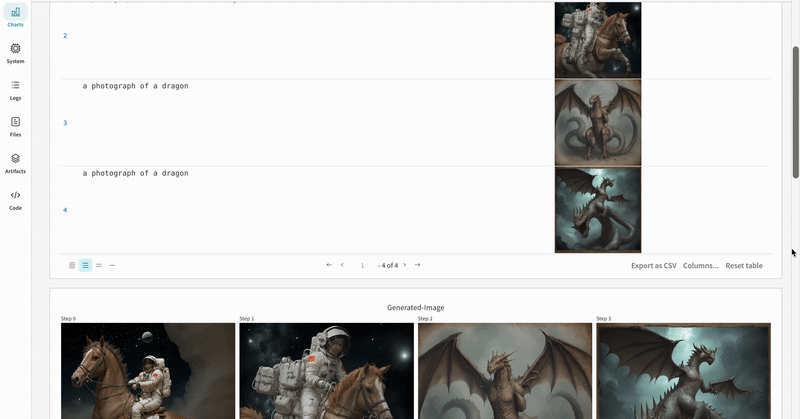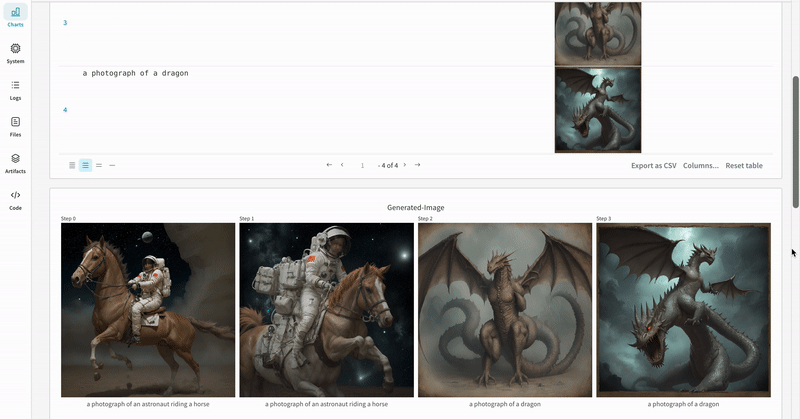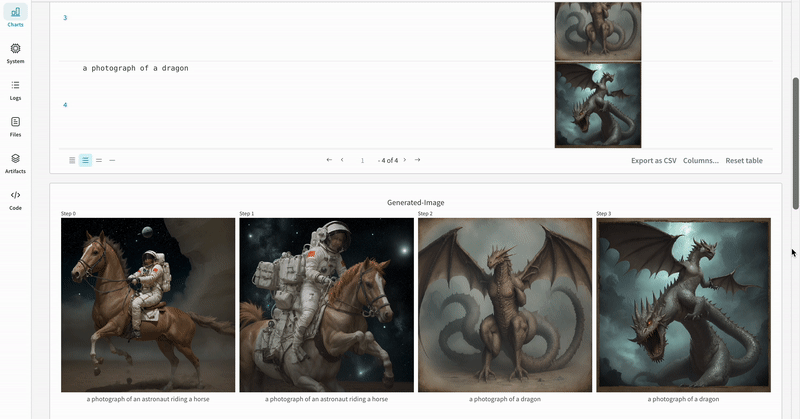 |
|---|
| 실험 결과가 기록되는 방식의 예시입니다. |
시작하기
-
diffusers,transformers,accelerate및wandb를 설치합니다.-
커맨드라인:
pip install --upgrade diffusers transformers accelerate wandb -
노트북:
!pip install --upgrade diffusers transformers accelerate wandb
-
-
autolog를 사용하여 Weights & Biases run을 초기화하고 지원되는 모든 파이프라인 호출에서 입력 및 출력을 자동으로 추적합니다.wandb.init()에 필요한 파라미터의 dictionary를 받는init파라미터로autolog()함수를 호출할 수 있습니다.autolog()를 호출하면 Weights & Biases run이 초기화되고 지원되는 모든 파이프라인 호출에서 입력과 출력을 자동으로 추적합니다.- 각 파이프라인 호출은 워크스페이스의 자체 테이블로 추적되며, 파이프라인 호출과 관련된 설정은 해당 run의 설정에서 워크플로우 목록에 추가됩니다.
- 프롬프트, 부정적 프롬프트 및 생성된 미디어는
wandb.Table에 기록됩니다. - 시드 및 파이프라인 아키텍처를 포함하여 실험과 관련된 다른 모든 설정은 run의 설정 섹션에 저장됩니다.
- 각 파이프라인 호출에 대해 생성된 미디어도 run의 미디어 패널에 기록됩니다.
지원되는 파이프라인 호출 목록은 [여기](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72)에서 확인할 수 있습니다. 이 인테그레이션의 새로운 기능을 요청하거나 관련 버그를 보고하려면 [https://github.com/wandb/wandb/issues](https://github.com/wandb/wandb/issues)에 이슈를 여십시오.예시
Autologging
다음은 autolog의 간단한 엔드투엔드 예시입니다.
import torch from diffusers import DiffusionPipeline # import the autolog function from wandb.integration.diffusers import autolog # call the autolog before calling the pipeline autolog(init=dict(project="diffusers_logging")) # Initialize the diffusion pipeline pipeline = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16 ).to("cuda") # Define the prompts, negative prompts, and seed. prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"] negative_prompt = ["ugly, deformed", "ugly, deformed"] generator = torch.Generator(device="cpu").manual_seed(10) # call the pipeline to generate the images images = pipeline( prompt, negative_prompt=negative_prompt, num_images_per_prompt=2, generator=generator, )import torch from diffusers import DiffusionPipeline import wandb # import the autolog function from wandb.integration.diffusers import autolog # call the autolog before calling the pipeline autolog(init=dict(project="diffusers_logging")) # Initialize the diffusion pipeline pipeline = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16 ).to("cuda") # Define the prompts, negative prompts, and seed. prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"] negative_prompt = ["ugly, deformed", "ugly, deformed"] generator = torch.Generator(device="cpu").manual_seed(10) # call the pipeline to generate the images images = pipeline( prompt, negative_prompt=negative_prompt, num_images_per_prompt=2, generator=generator, ) # Finish the experiment wandb.finish()-
단일 실험의 결과:
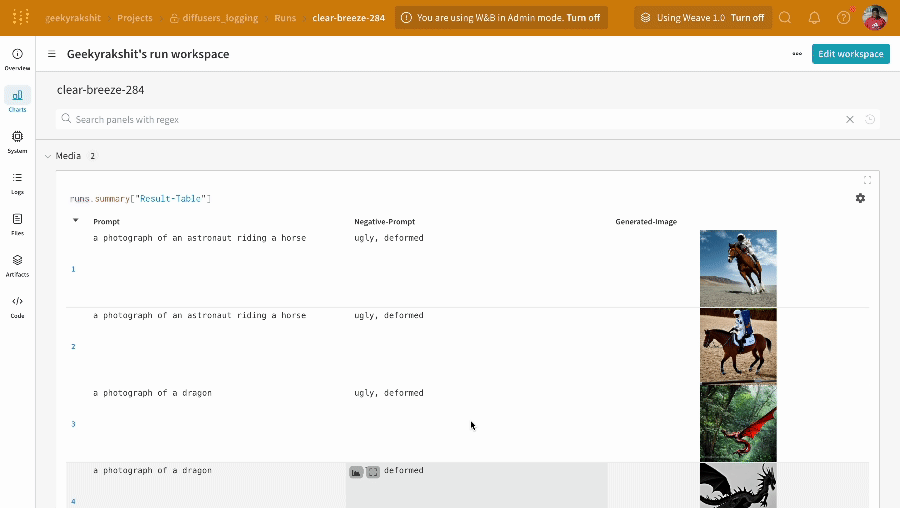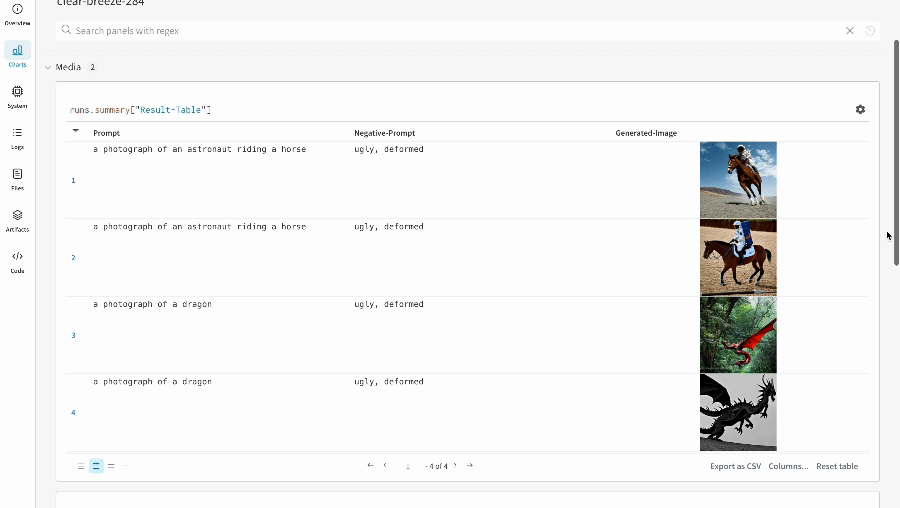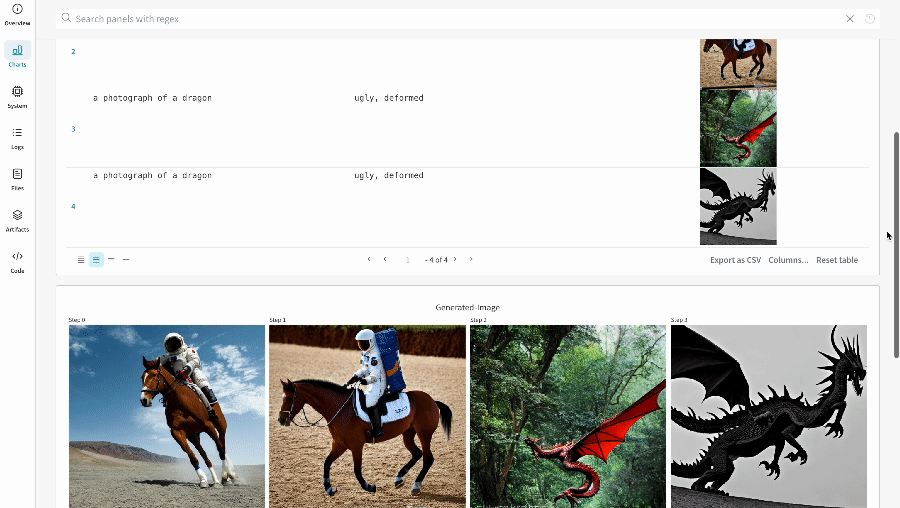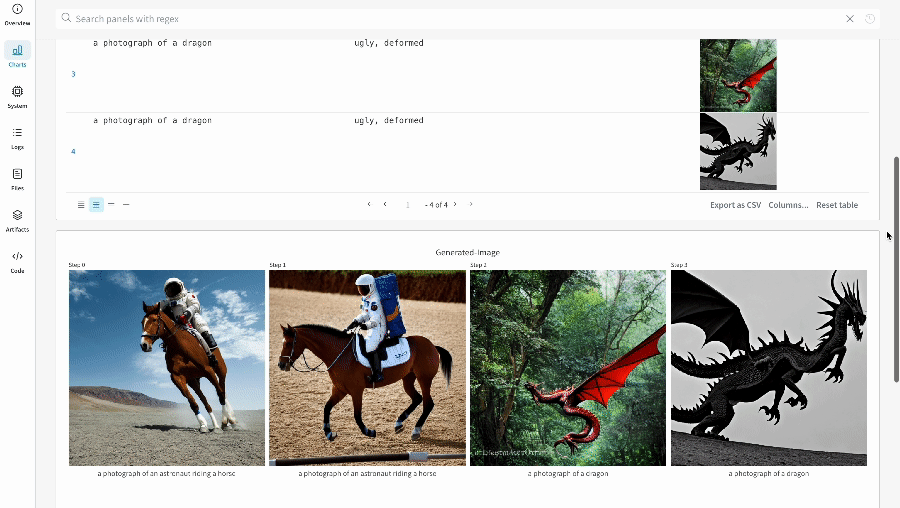
-
여러 실험의 결과:
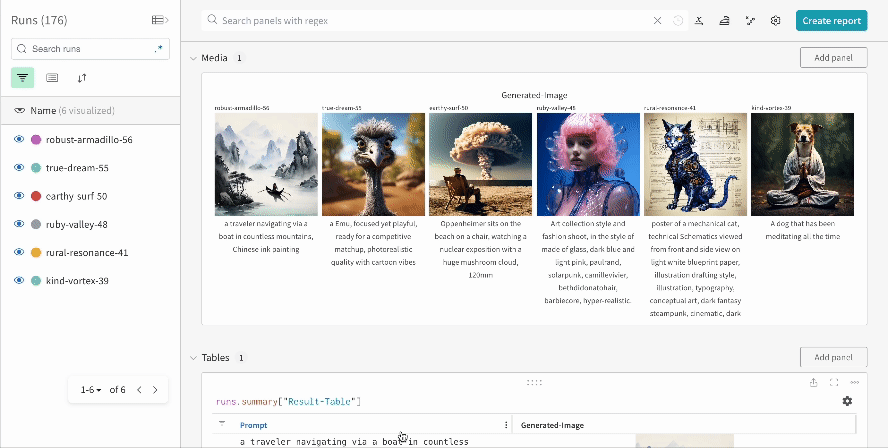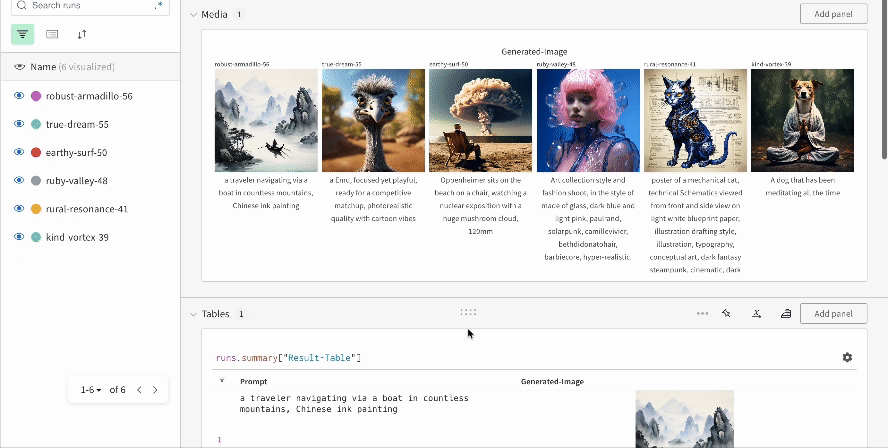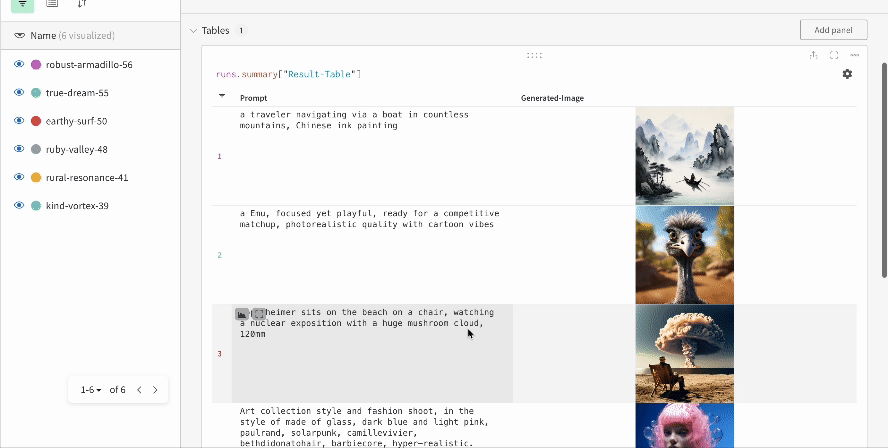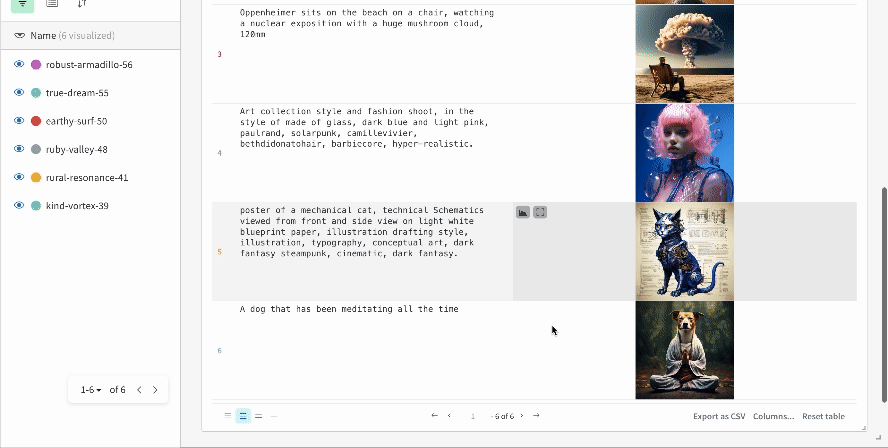
-
실험의 설정:
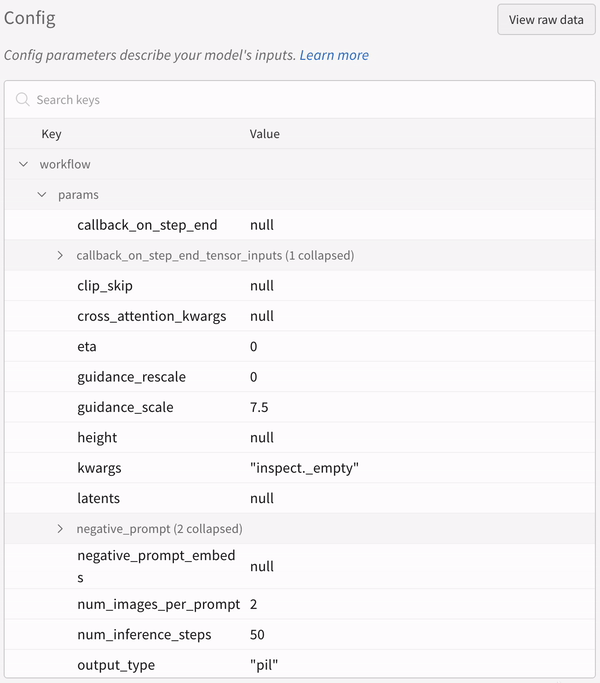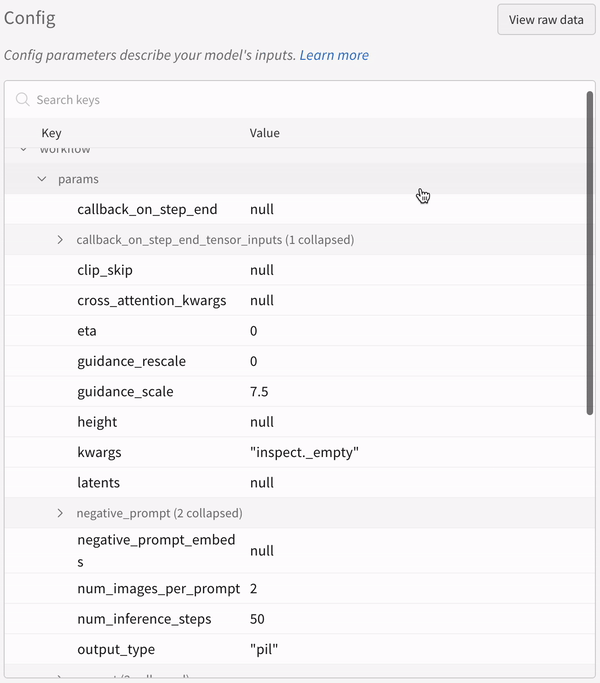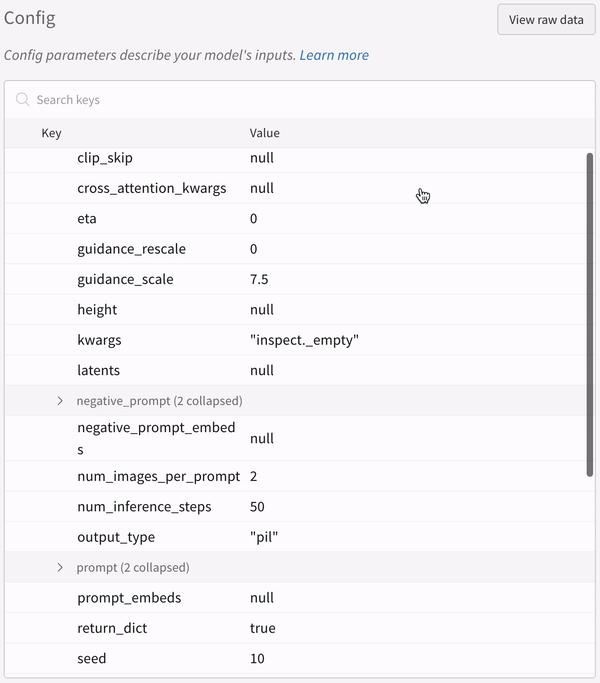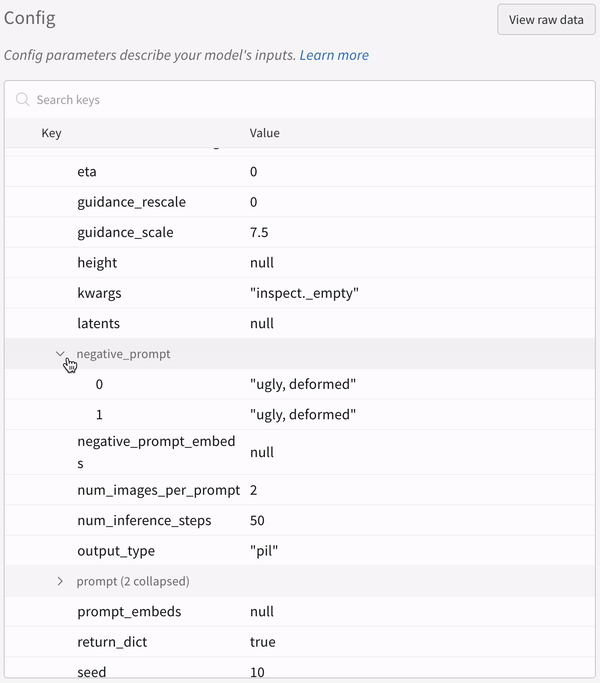
파이프라인을 호출한 후 IPython 노트북 환경에서 코드를 실행할 때는wandb.finish()를 명시적으로 호출해야 합니다. Python 스크립트를 실행할 때는 필요하지 않습니다.다중 파이프라인 워크플로우 추적
이 섹션에서는
StableDiffusionXLPipeline에서 생성된 잠재 변수가 해당 리파이너에 의해 개선되는 일반적인 Stable Diffusion XL + Refiner 워크플로우에서 autolog를 시연합니다.import torch from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline from wandb.integration.diffusers import autolog # initialize the SDXL base pipeline base_pipeline = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True, ) base_pipeline.enable_model_cpu_offload() # initialize the SDXL refiner pipeline refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-refiner-1.0", text_encoder_2=base_pipeline.text_encoder_2, vae=base_pipeline.vae, torch_dtype=torch.float16, use_safetensors=True, variant="fp16", ) refiner_pipeline.enable_model_cpu_offload() prompt = "a photo of an astronaut riding a horse on mars" negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing" # Make the experiment reproducible by controlling randomness. # The seed would be automatically logged to WandB. seed = 42 generator_base = torch.Generator(device="cuda").manual_seed(seed) generator_refiner = torch.Generator(device="cuda").manual_seed(seed) # Call WandB Autolog for Diffusers. This would automatically log # the prompts, generated images, pipeline architecture and all # associated experiment configs to Weights & Biases, thus making your # image generation experiments easy to reproduce, share and analyze. autolog(init=dict(project="sdxl")) # Call the base pipeline to generate the latents image = base_pipeline( prompt=prompt, negative_prompt=negative_prompt, output_type="latent", generator=generator_base, ).images[0] # Call the refiner pipeline to generate the refined image image = refiner_pipeline( prompt=prompt, negative_prompt=negative_prompt, image=image[None, :], generator=generator_refiner, ).images[0]import torch from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline import wandb from wandb.integration.diffusers import autolog # initialize the SDXL base pipeline base_pipeline = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True, ) base_pipeline.enable_model_cpu_offload() # initialize the SDXL refiner pipeline refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-refiner-1.0", text_encoder_2=base_pipeline.text_encoder_2, vae=base_pipeline.vae, torch_dtype=torch.float16, use_safetensors=True, variant="fp16", ) refiner_pipeline.enable_model_cpu_offload() prompt = "a photo of an astronaut riding a horse on mars" negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing" # Make the experiment reproducible by controlling randomness. # The seed would be automatically logged to WandB. seed = 42 generator_base = torch.Generator(device="cuda").manual_seed(seed) generator_refiner = torch.Generator(device="cuda").manual_seed(seed) # Call WandB Autolog for Diffusers. This would automatically log # the prompts, generated images, pipeline architecture and all # associated experiment configs to Weights & Biases, thus making your # image generation experiments easy to reproduce, share and analyze. autolog(init=dict(project="sdxl")) # Call the base pipeline to generate the latents image = base_pipeline( prompt=prompt, negative_prompt=negative_prompt, output_type="latent", generator=generator_base, ).images[0] # Call the refiner pipeline to generate the refined image image = refiner_pipeline( prompt=prompt, negative_prompt=negative_prompt, image=image[None, :], generator=generator_refiner, ).images[0] # Finish the experiment wandb.finish()- Stable Diffisuion XL + Refiner 실험의 예:
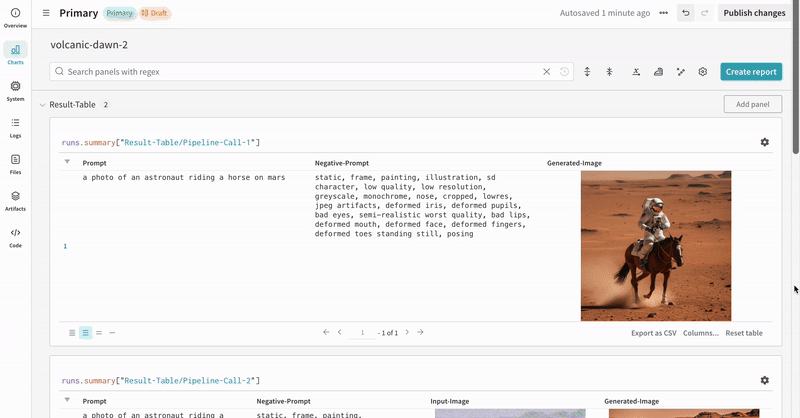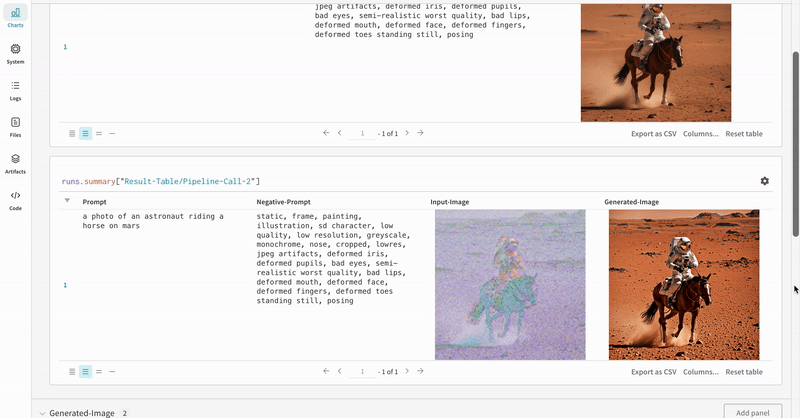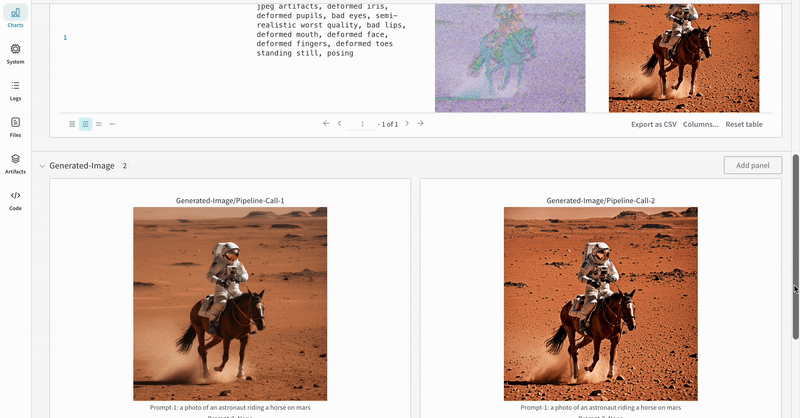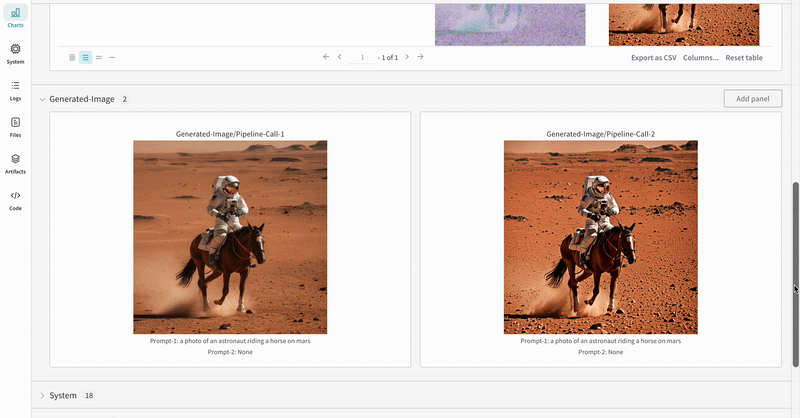
추가 자료
피드백
이 페이지가 도움이 되었나요?
Glad to hear it! If you have more to say, please let us know.
Sorry to hear that. Please tell us how we can improve.