This walkthrough is a follow-up to the Unstructured UI quickstart. However, you do not need to have completed the quickstart to start using this walkthrough.
- Wang, Z., Liu, X., & Zhang, M. (2022, November 23). Breaking the Representation Bottleneck of Chinese Characters: Neural Machine Translation with Stroke Sequence Modeling. arXiv.org. https://arxiv.org/pdf/2211.12781. This 12-page PDF file features English and non-English characters, images, graphs, and complex tables. Throughout this walkthrough, this file’s title is shortened to “Chinese Characters” for brevity.
This walkthrough focuses on a local file for ease-of-use demonstration purposes.This walkthrough does not cover how to use Unstructured to set up connectors to do large-scale batch processing of multiple files and semi-structured data that are stored in remote locations. To learn how to set up connectors and do large-scale batch processing later, see the next steps after you finish this walkthrough.
Step 1: Open the workflow editor
After you complete the Unstructured UI quickstart, the workflow editor should now be visible in your Unstructured account. The workflow editor should look like this: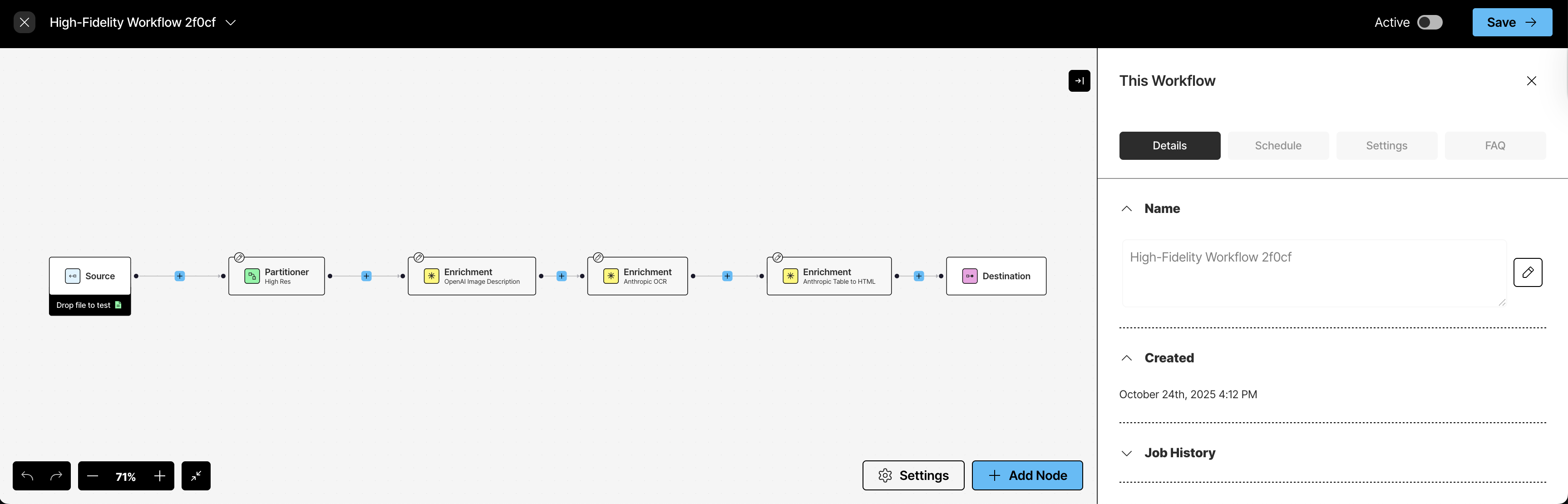
- If you do not already have an Unstructured account, sign up for free. After you sign up, you are automatically signed in to your new Unstructured Let’s Go account, at https://platform.unstructured.io.
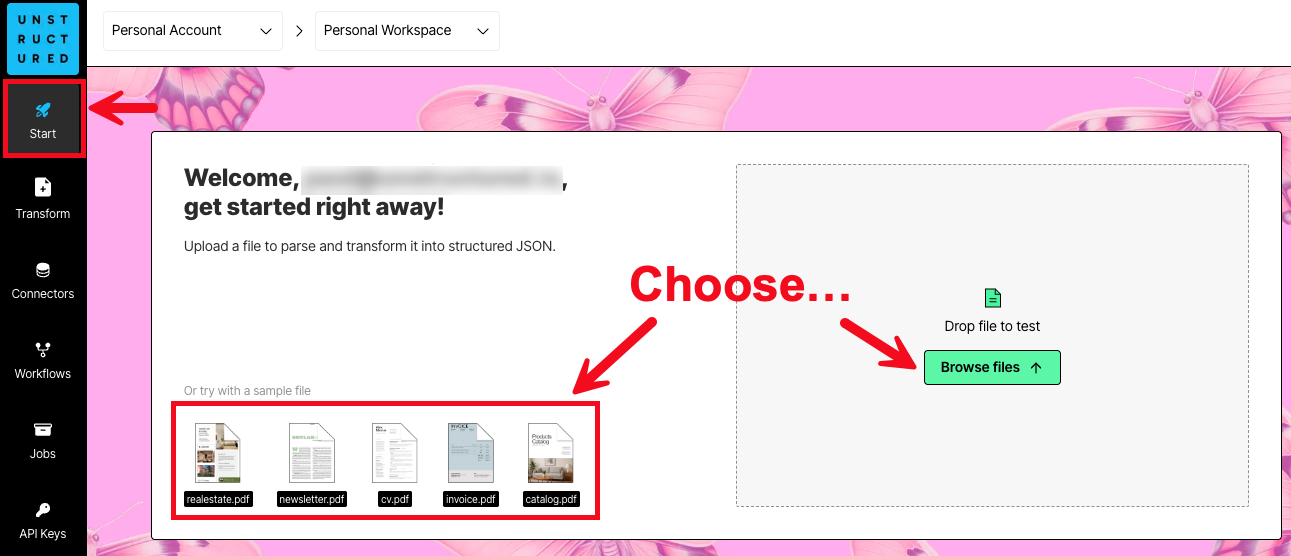
- After you are signed in, the Start page appears.
- In the Welcome area, do one of the following:
- Click one of the sample files, such as realestate.pdf, to have Unstructured parse and transform that sample file.
- Click Browse files, and then browse to and select one of your own files, to have Unstructured parse and transform it. If you choose to use your own file, the file must be 10 MB or less in size.
- Click Edit in Workflow Editor at the right on the title bar.
Step 2: Learn about workflows
In this step, you learn about what workflows are and how they work in your Unstructured account. Workflows are defined sequences of processes that automate the flow of data from your source documents and data into Unstructured for processing. Unstructured then sends its processed data over into your destination file storage locations, databases, and vector stores. Your RAG apps, agents, and models can then use this processed data in those destinations to do things more quickly and accurately such as answering users’ questions, automating business processes, and expanding your organization’s available body of knowledge. Which kinds of sources and destinations does Unstructured support? Unstructured can connect to many types of sources and destinations including file storage services such as Amazon S3 and Google Cloud Storage; databases such as PostgreSQL; and vector storage and database services such as MongoDB Atlas and Pinecone. See the full list of supported source and destination connectors. Which kinds of files does Unstructured support? Unstructured can process a wide variety of file types including PDFs, word processing documents, spreadsheets, slide decks, HTML, image files, emails, and more. See the full list of supported file types. How do I access my existing workflows and create new ones? To access your existing workflows, and to create new workflows, on the sidebar, click Workflows. (Don’t click it right now, though—you already have an existing workflow in progress!)
- Start takes you to the UI home page. The home page features a simple way to process one local file at a time with limited default settings. Learn how.
- Connectors allows you to create and manage your source and destination connectors.
- Jobs allows you to see the results of your workflows that are run manually (on-demand) and automatically (on a regular time schedule). Learn more.
- API Keys allows you to use code to create and manage connectors, workflows, and jobs programmatically instead of by using the UI. Learn more.
- Your user icon at the bottom of the sidebar allows you to manage your Unstructured account. You can also sign out of your account from here. Learn more.
- The settings on the Details tab allow you to change this workflow’s name. You can also see when this workflow was created and which jobs were run for this workflow.
- Schedule allows you to set up a schedule for this workflow to run automatically (on a regular time schedule).
- Settings allows you to specify whether every time this workflow runs, that Unstructured’s results will overwrite any previous results in the destination location. To turn on this behavior, check the Overwrite existing results box. To turn it off, uncheck the box. Note that this setting works only for blog storage destination connectors such as the ones for Amazon S3, Azure Blob Storage, and Google Cloud Storage.
- FAQ contains additional information about how to use the workflow designer.
Step 3: Learn more about partitioning
You already saw from the quickstart that Unstructured uses a process called partitioning to identify and extract content from your source documents and semi-structured data and then output this content as a series of contextually-rich document elements and metadata, which are well-tuned for RAG, agentic AI, and model fine-tuning. Your existing workflow already has a Partitioner node that uses the High Res partitioning strategy. To see the other kinds of partitioning strategies that are available, click the Partitioner node, and then look in the node’s settings pane that appears.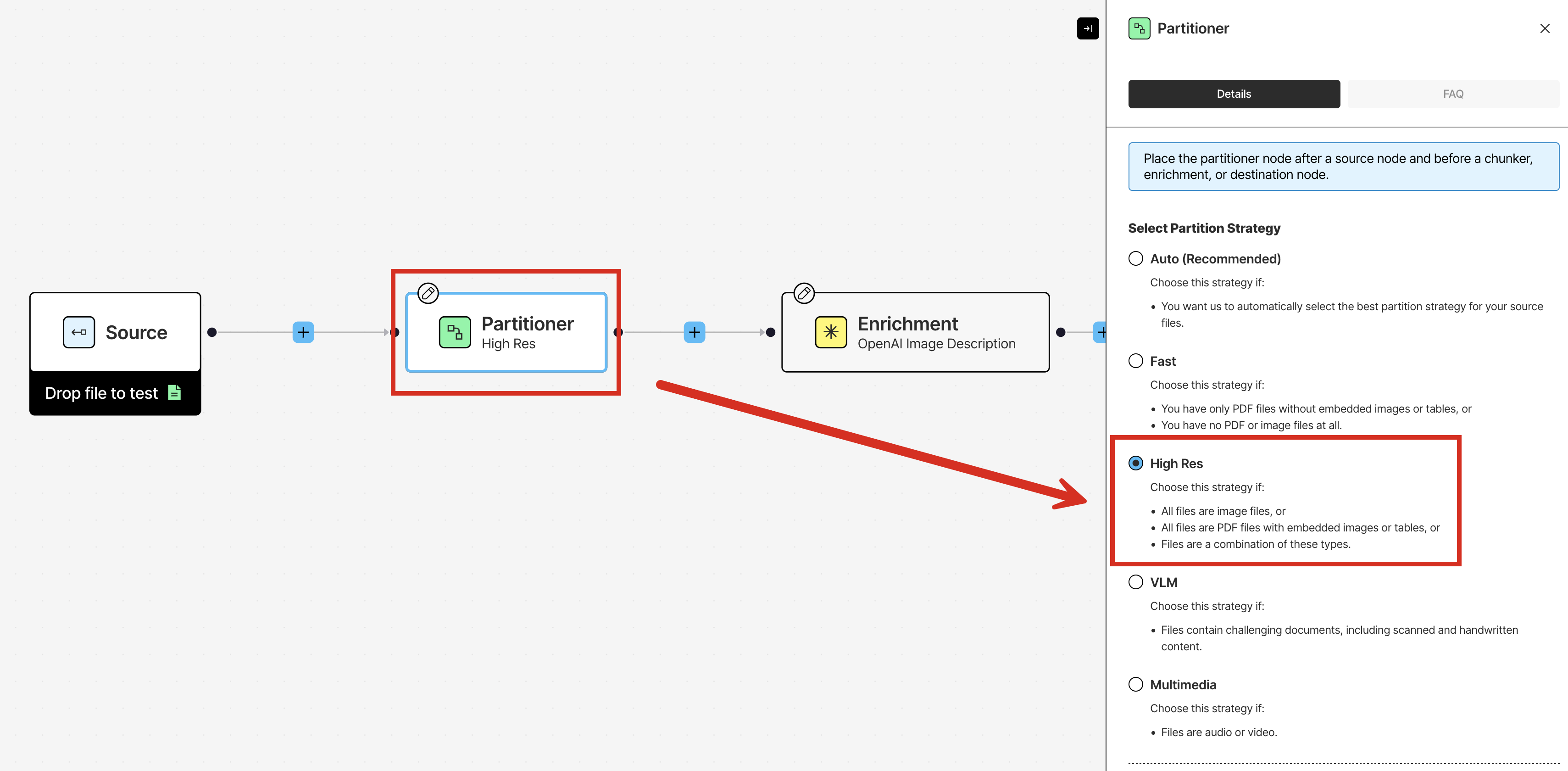
- In the workflow designer, at the bottom of the Source node, click Drop file to test.
- Browse to and select the “Chinese Characters” PDF file that you downloaded earlier.
- Immediately above the Source node, click Test.
- The PDF file appears in a pane on the left side of the screen, and Unstructured’s output appears in a Test output pane on the right side of the screen.
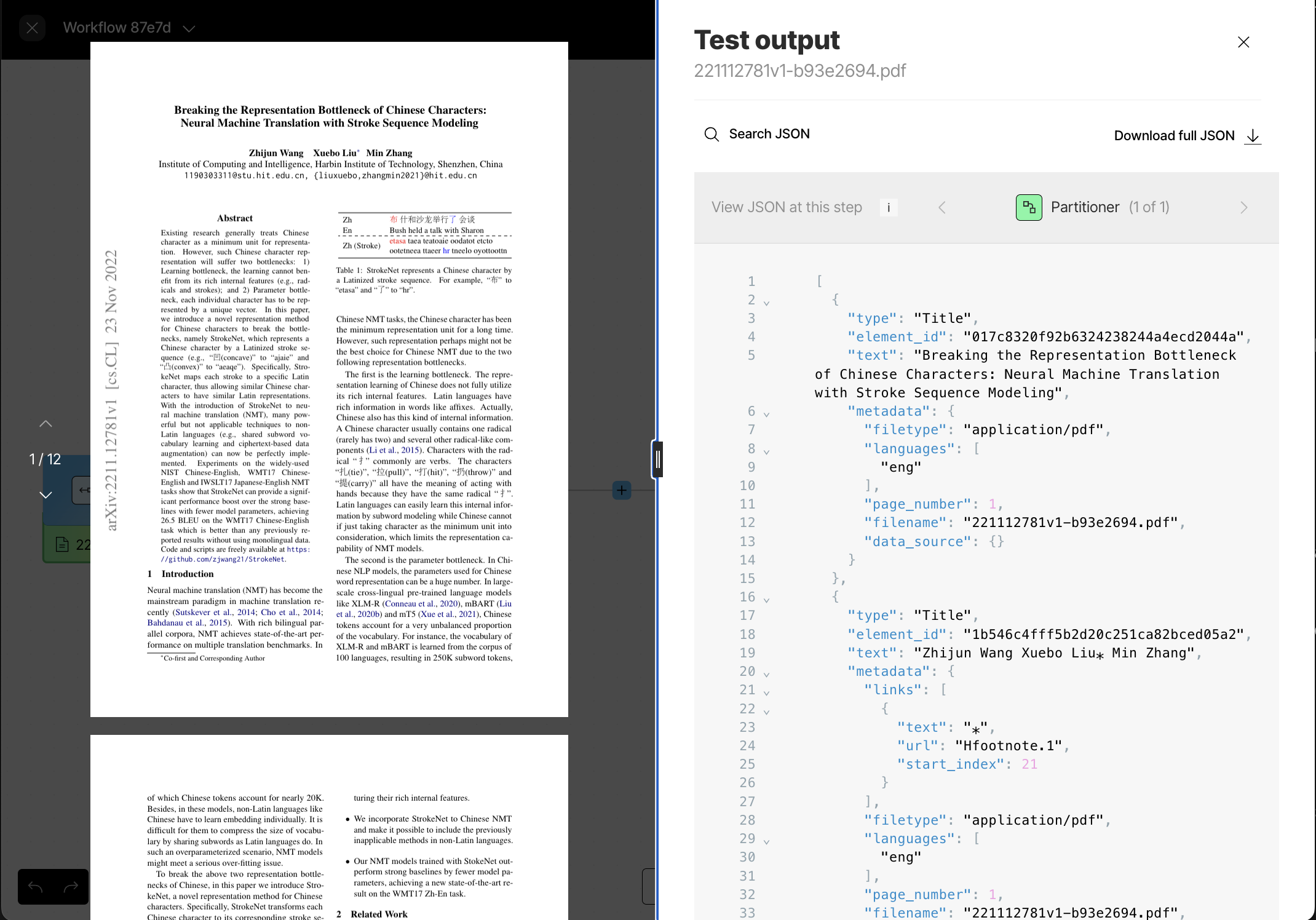
- In the Test output pane, make sure that Table to HTML (4 of 4) is showing. If not, click the right arrow (>) until Table to HTML (4 of 4) appears, which will show the output from the last node in the workflow.

- Some interesting portions of the output include the following, which you can get to be clicking Search JSON above the output:
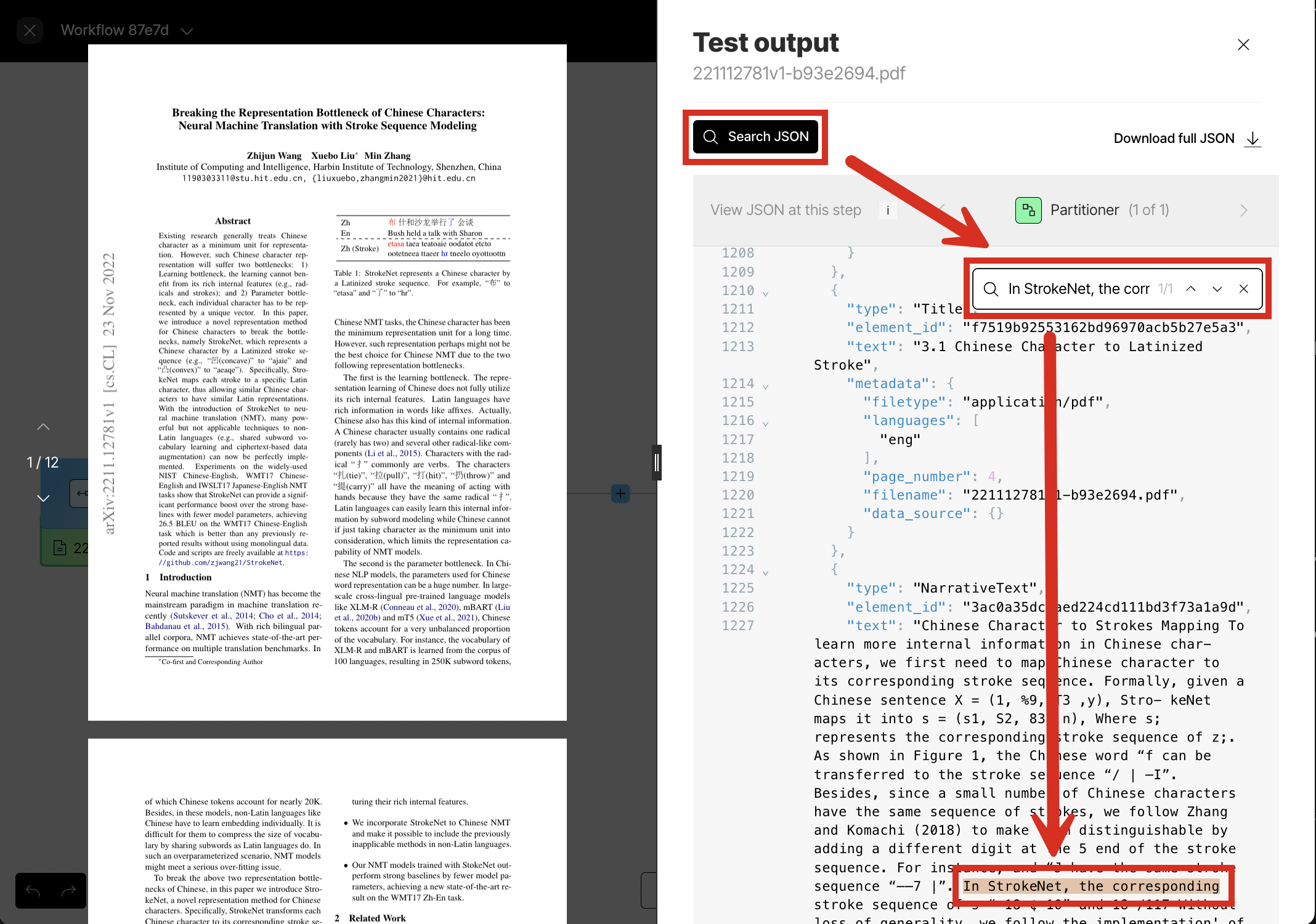
- The Chinese characters on page 1. Search for the text
all have the meaning of acting. Notice how the Chinese characters are captures correctly. - The HTML representations of the seven tables on pages 6-9 and 12. Search for the text
"text_as_html":. - The descriptions of the four diagrams on page 3. Search for the text
\"diagram\",\n \"description\". - The descriptions of the three graphs on pages 7-8. Search for the text
\"graph\",\n \"description\". - The Base64-encoded, full-fidelity representations of the 14 tables, diagrams, and graphs on pages 3, 6-9, and 12. Search for the text
"image_base64":. You can use a web-based tool such as base64.guru to experiment with decoding these representations back into their original visual representations.
- The Chinese characters on page 1. Search for the text
- When you are done, be sure to click the close (X) button above the output on the right side of the screen, to return to the workflow designer for the next step.
Step 4: Add more enrichments
Your existing workflow already has three Enrichment nodes. Recall that these nodes perform the following enrichments:- An image description enrichment, which uses a vision language model (VLM) to provide a text-based summary of the contents of the each detected image.
- A generative OCR enrichment, which uses a VLM to improve the accuracy of each block of initially-processed text.
- A table to HTML enrichment, which uses a VLM to provide an HTML-structured representation of each detected table.
- In the workflow designer, just before the Destination node, click the add (+) icon, and then click Enrich > Enrichment.
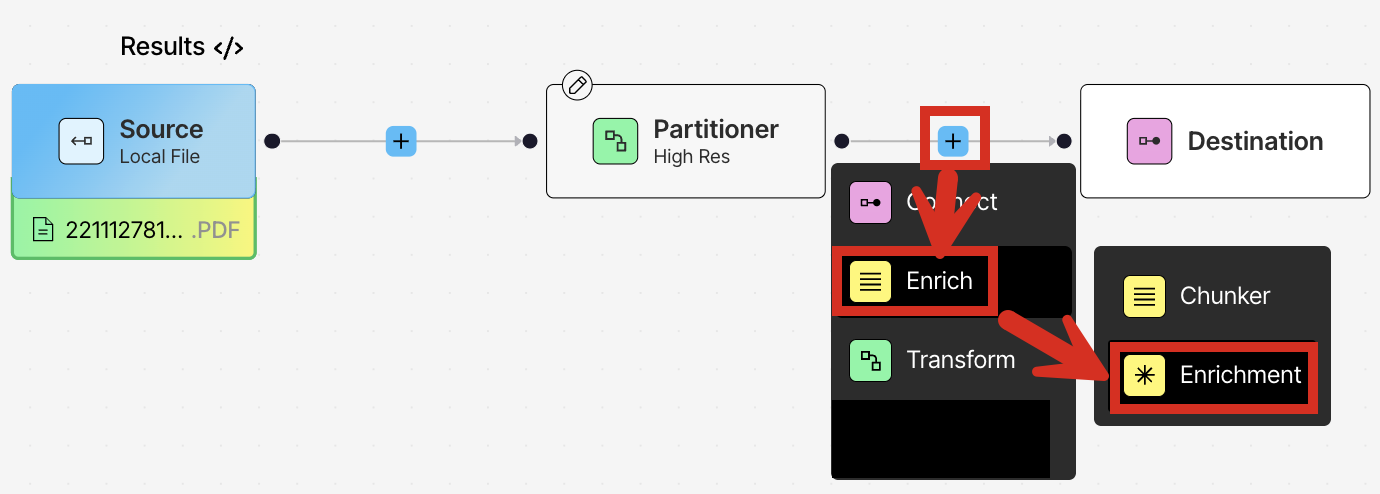
- In the node’s settings pane’s Details tab, click:
- Table under Input Type.
- Anthropic under Provider.
- Claude Sonnet 4 under Model.
- Table Description under Task.
- Add a named entity recognition enrichment (click the add (+) icon to the right of the preceding node, and then click **Enrich > Enrichment). In the node’s settings pane’s Details tab, click:
- Text under Input Type.
- Anthropic under Provider.
- Claude Sonnet 4 under Model.

- Immediately above the Source node, click Test.
- In the Test output pane, make sure that Enrichment (6 of 6) is showing. If not, click the right arrow (>) until Enrichment (6 of 6) appears, which will show the output from the last node in the workflow.
- Some interesting portions of the output include the following:
- The descriptions of the seven tables on pages 6-9 and 12. Search for the text
## Table Structure Analysis\n\n###. - The identified entities and inferred relationships among them. For example, search for the text
Zhijun Wang. Of the eight instances of this name, notice the author’s identification as aPERSONthree times, the author’spublishedrelationship twice, and the author’saffiliated_withrelationship twice.
- The descriptions of the seven tables on pages 6-9 and 12. Search for the text
- When you are done, be sure to click the close (X) button above the output on the right side of the screen, to return to the workflow designer for the next step.
Step 5: Experiment with chunking
In this step, you apply chunking to your workflow. Chunking is the process where Unstructured rearranges the resulting document elements’text content into manageable “chunks” to stay within the limits of an AI model and to improve retrieval precision. - In the workflow designer, just before the Destination node, click the add (+) icon, and then click Enrich > Chunker.
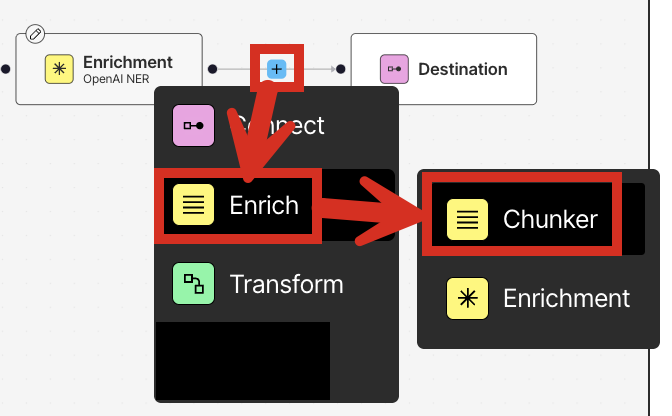
- In the node’s settings pane’s Details tab, select Chunk by Character.
- Under Chunk by Character, specify the following settings:
- Check the box labelled Include Original Elements.
- Set Max Characters to 500.
- Set New After N Characters to 400.
- Set Overlap to 50.
- Leave Contextual Chunking turned off and Overlap All unchecked.

- Immediately above the Source node, click Test.
- In the Test output pane, make sure that Chunker (7 of 7) is showing. If not, click the right arrow (>) until Chunker (7 of 7) appears, which will show the output from the last node in the workflow.
- To explore the chunker’s results, search for the text
"type": "CompositeElement". - Try running this workflow again with the Chunk by Title strategy, as follows: a. Click the close (X) button above the output on the right side of the screen.
b. In the workflow designer, click the Chunker node and then, in the node’s settings pane’s Details tab, select Chunk by Title.
c. Under Chunk by Title, specify the following settings:- Check the box labelled Include Original Elements.
- Set Max Characters to 500.
- Set New After N Characters to 400.
- Set Overlap to 50.
- Leave Contextual Chunking turned off, leave Combine Text Under N Characters blank, and leave Multipage Sections and Overlap All unchecked.
e. In the Test output pane, make sure that Chunker (7 of 7) is showing. If not, click the right arrow (>) until Chunker (7 of 7) appears, which will show the output from the last node in the workflow.
f. To explore the chunker’s results, search for the text"type": "CompositeElement". Notice that the lengths of some of the chunks that immediately precede titles might be shortened due to the presence of the title impacting the chunk’s size. - Try running this workflow again with the Chunk by Page strategy, as follows: a. Click the close (X) button above the output on the right side of the screen.
b. In the workflow designer, click the Chunker node and then, in the node’s settings pane’s Details tab, select Chunk by Page.
c. Under Chunk by Page, specify the following settings:- Check the box labelled Include Original Elements.
- Set Max Characters to 500.
- Set New After N Characters to 400.
- Set Overlap to 50.
- Leave Contextual Chunking turned off, and leave Overlap All unchecked.
e. In the Test output pane, make sure that Chunker (7 of 7) is showing. If not, click the right arrow (>) until Chunker (7 of 7) appears, which will show the output from the last node in the workflow.
f. To explore the chunker’s results, search for the text"type": "CompositeElement". Notice that the lengths of some of the chunks that immediately precede page breaks might be shortened due to the presence of the page break impacting the chunk’s size.
- Try running this workflow again with the Chunk by Similarity strategy, as follows: a. Click the close (X) button above the output on the right side of the screen.
b. In the workflow designer, click the Chunker node and then, in the node’s settings pane’s Details tab, select Chunk by Similarity.
c. Under Chunk by Similarity, specify the following settings:- Check the box labelled Include Original Elements.
- Set Max Characters to 500.
- Set Similarity Threshold to 0.99.
- Leave Contextual Chunking turned off.
e. In the Test output pane, make sure that Chunker (7 of 7) is showing. If not, click the right arrow (>) until Chunker (7 of 7) appears, which will show the output from the last node in the workflow.
f. To explore the chunker’s results, search for the text"type": "CompositeElement". Notice that the lengths of many of the chunks fall well short of the Max Characters limit. This is because a similarity threshold of 0.99 means that only sentences or text segments with a near-perfect semantic match will be grouped together into the same chunk. This is an extremely high threshold, resulting in very short, highly specific chunks of text.
g. If you change Similarity Threshold to 0.01 and run the workflow again, searching for the text"type": "CompositeElement", many of the chunks will now come closer to the Max Characters limit. This is because a similarity threshold of 0.01 provides an extreme tolerance of differences between pieces of text, grouping almost anything together.
- When you are done, be sure to click the close (X) button above the output on the right side of the screen, to return to the workflow designer for the next step.
Step 6: Experiment with embedding
In this step, you generate embeddings for your workflow. Embeddings are vectors of numbers that represent various aspects of the text that is extracted by Unstructured. These vectors are stored or “embedded” next to the text itself in a vector store or vector database. Chatbots, agents, and other AI solutions can use these vector embeddings to more efficiently and effectively find, analyze, and use the associated text. These vector embeddings are generated by an embedding model that is provided by an embedding provider. For the best embedding model to apply to your use case, see the documentation for your target downstream application toolsets.- With the workflow designer active from the previous step, just before the Destination node, click the add (+) icon, and then click Transform > Embedder.
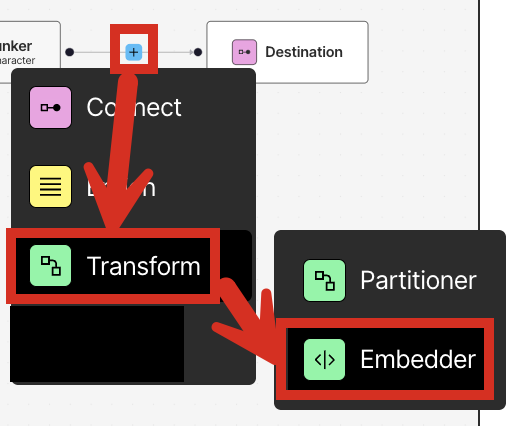
- In the node’s settings pane’s Details tab, under Select Embedding Model, for Azure OpenAI, select Text Embedding 3 Small [dim 1536].
- Immediately above the Source node, click Test.
- In the Test output pane, make sure that Embedder (8 of 8) is showing. If not, click the right arrow (>) until Embedder (8 of 8) appears, which will show the output from the last node in the workflow.
- To explore the embeddings, search for the text
"embeddings". - When you are done, be sure to click the close (X) button above the output on the right side of the screen, to return to the workflow designer so that you can continue designing things later as you see fit.
Next steps
Congratulations! You now have an Unstructured workflow that partitions, enriches, chunks, and embeds your source documents, producing context-rich data that is ready for retrieval-augmented generation (RAG), agentic AI, and model fine-tuning. Right now, your workflow only accepts one local file at a time for input. Your workflow also only sends Unstructured’s processed data to your screen or to be saved locally as a JSON file. You can modify your workflow to accept multiple files and data from—and send Unstructured’s processed data to—one or more file storage locations, databases, and vector stores. To learn how to do this, try one or more of the following quickstarts:- Remote quickstart - This quickstart show you how to begin processing files and semi-structured data from remote source locations at scale, instead of just one local file at a time.
- Dropbox source connector quickstart - If you don’t have any remote source locations available for Unstructured to connect to, this quickstart shows you how to set up a Dropbox account to store your documents in, and then connect Unstructured to your Dropbox account.
- Pinecone destination connector quickstart - If you don’t have any remote destination locations available for Unstructured to send its processed data to, this quickstart shows you how to set up a Pinecone account to have Unstructured store its processed data in, and then connect Unstructured to your Pinecone account.
- Unstructured API quickstart - This quickstart uses the Unstructured Workflow Endpoint to programmatically create a Dropbox source connector and a Pinecone destination connector in your Unstructured account. You then programmatically add these connectors to a workflow in your Unstructured account, run that workflow as a job, and then explore the job’s results.
- Unstructured Python SDK - This article provides an overview of the Unstructured Python SDK and how to use it.
- Unstructured API overview - This article provides an overview of the Unstructured API and how to use it.