
智能家居环境中的AI决策解释:实现以人为中心的可解释性
Shajalal M, Boden A, Stevens G, et al. Explaining AI Decisions: Towards Achieving Human-Centered Explainability in Smart Home Environments[C]//World Conference on Explainable Artificial Intelligence. Cham: Springer Nature Switzerland, 2024: 418-440.
1. 引言与研究动机
智能家居系统正在经历前所未有的快速发展,这些系统通过先进的传感器技术和机器学习算法,为居民提供了监控和控制连接设备的能力。这些应用不仅可以自动做出决策,还能基于ML驱动的技术而非简单的时间表逻辑进行智能调控。在智能家居能源领域,一个值得注意的能源感知智能家居应用是设备级能源需求预测,它能让用户更加了解并优化他们的能源消耗实践。
然而,这些系统面临着一个关键挑战:基于AI的智能家居应用通常依赖于复杂的机器学习模型,这些模型可能涉及数千到数百万个模型参数(特别是深度学习模型),因此常被称为"黑盒"。黑盒模型的决策可能难以理解,并可能以意外的预测让用户感到惊讶。在这种情况下,用户需要解释来理解预测结果。
2. 技术性XAI的数学基础
2.1 SHAP(Shapley Additive Explanations)
SHAP基于博弈论中的Shapley值概念,为每个特征分配一个重要性值。对于特征$i$,其Shapley值定义为:
$$\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!(|N|-|S|-1)!}{|N|!}[f_{S \cup \{i\}}(x) - f_S(x)]$$
其中:
- $N$ 是所有特征的集合
- $S$ 是不包含特征$i$的特征子集
- $f_S(x)$ 是仅使用特征子集$S$的模型预测
- $|S|$ 表示集合$S$的基数
SHAP值满足以下重要性质:
局部准确性(Local Accuracy):
$$f(x) = \phi_0 + \sum_{i=1}^M \phi_i$$
缺失性(Missingness):如果特征$i$对模型预测没有影响,则$\phi_i = 0$
一致性(Consistency):如果模型改变使得特征$i$的边际贡献增加,则$\phi_i$不会减少
2.2 DeepLIFT(Deep Learning Important Features)
DeepLIFT通过比较每个神经元的激活值与参考激活值来分配贡献分数。对于神经元$i$到神经元$j$的贡献,定义为:
$$C_{i \rightarrow j} = (x_i - x_i^0) \cdot \frac{f_j(x) - f_j(x^0)}{x_i - x_i^0}$$
其中$x^0$是参考输入,$f_j$是神经元$j$的激活函数。
对于深度网络,总贡献通过链式规则传播:
$$C_{i \rightarrow \text{output}} = \sum_{\text{path } p} \prod_{(a,b) \in p} C_{a \rightarrow b}$$
2.3 Layer-wise Relevance Propagation (LRP)
LRP通过反向传播将预测分数分解为输入特征的相关性分数。对于层$l$中的神经元$i$和层$l+1$中的神经元$j$,相关性传播规则为:
$$R_i^{(l)} = \sum_j \frac{x_i w_{ij}}{\sum_k x_k w_{kj} + \epsilon} R_j^{(l+1)}$$
其中$w_{ij}$是连接权重,$\epsilon$是一个小的稳定项以避免除零。
3. 实验设计与实施
3.1 能源需求预测系统
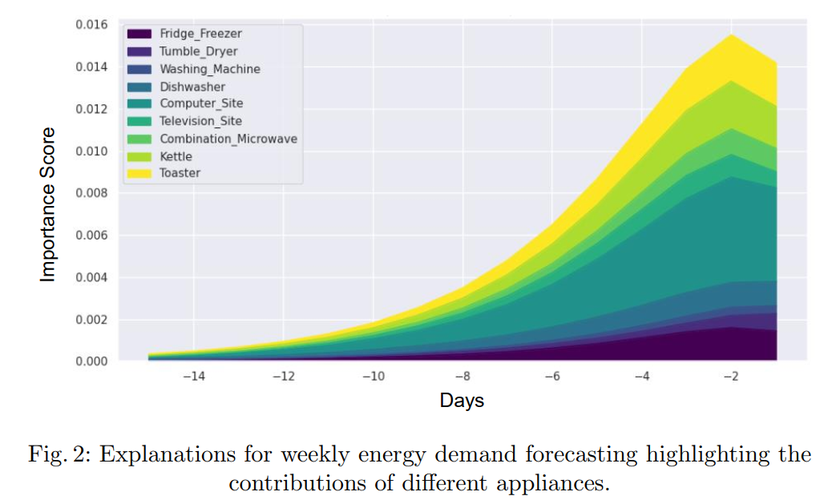
图2描述:该图展示了一周内不同家用电器对总能源消耗的贡献变化。采用堆叠面积图的形式,其中横轴表示时间(从第-14天到第-2天),纵轴表示重要性得分(从0.000到0.016)。图中用不同颜色区分了各种电器:深紫色代表冰箱冰柜(Fridge_Freezer),橙色代表烘干机(Tumble_Dryer),绿色代表洗衣机(Washing_Machine),红色代表洗碗机(Dishwasher),浅蓝色代表电脑(Computer_Site),深蓝色代表电视(Television_Site),粉色代表微波炉和水壶(Combination_Microwave/Kettle),黄色代表烤面包机(Toaster)。从图中可以观察到,随着时间推移,各设备的贡献呈现递增趋势,特别是在接近预测时间点时,重要性得分显著上升。
对于LSTM模型的能源预测,我们使用了如下的时序建模方法。设$X_t = [x_t^{(1)}, x_t^{(2)}, ..., x_t^{(n)}]$为时刻$t$的$n$个设备的能源消耗向量,LSTM的状态更新方程为:
$$f_t = \sigma(W_f \cdot [h_{t-1}, X_t] + b_f)$$
$$i_t = \sigma(W_i \cdot [h_{t-1}, X_t] + b_i)$$
$$\tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, X_t] + b_C)$$
$$C_t = f_t * C_{t-1} + i_t * \tilde{C}_t$$
$$o_t = \sigma(W_o \cdot [h_{t-1}, X_t] + b_o)$$
$$h_t = o_t * \tanh(C_t)$$
其中$f_t$、$i_t$、$o_t$分别是遗忘门、输入门和输出门,$C_t$是细胞状态,$h_t$是隐藏状态。
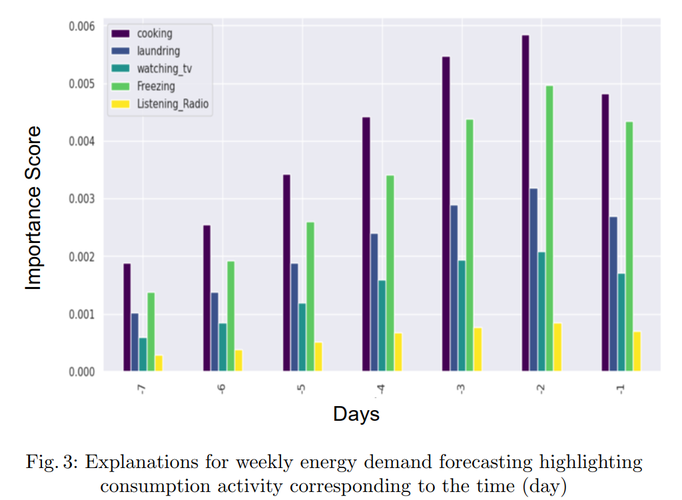
图3描述:该图以条形图形式展示了不同家庭活动在一周内各天的能源消耗贡献。横轴显示了7天的时间序列,纵轴表示重要性得分(从0.000到0.006)。图例显示了五种主要活动类别:烹饪(cooking,紫色)、洗衣(laundering,红色)、看电视(watching_tv,蓝色)、冷冻(Freezing,绿色)和收听广播(Listening_Radio,黄色)。从图中可以看出,烹饪活动在大多数天都占据主导地位,特别是在第3天和第4天达到峰值(约0.0055),而其他活动的贡献相对较小但保持稳定。
3.2 热舒适偏好预测系统
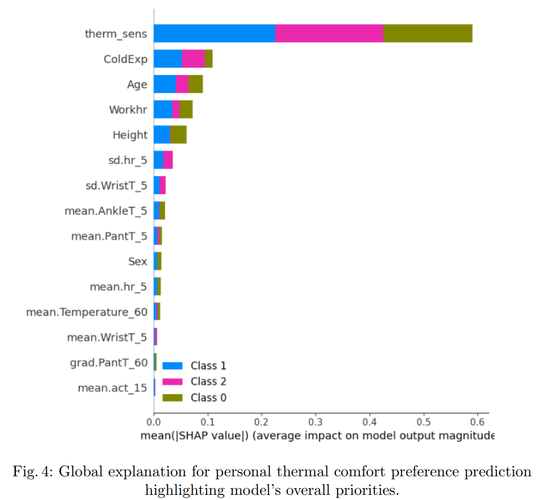
图4描述:这是一个水平条形图,展示了个人热舒适偏好预测模型的全局特征重要性。图中按照SHAP值的平均影响力对特征进行排序。最重要的特征是热敏感性(therm_sens),其SHAP值达到约0.6,远超其他特征。其次是冷体验(ColdExp)、年龄(Age)、工作时间(Workhr)和身高(Height),它们的SHAP值在0.05到0.1之间。图中还显示了其他生理和环境特征,如标准差参数、平均温度等。每个特征旁边的颜色条表示该特征值对三个预测类别(Class 0:凉爽、Class 1:不变、Class 2:温暖)的影响分布。
对于热舒适预测,我们使用了XGBoost模型。其目标函数为:
$$\mathcal{L} = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t)}) + \sum_{k=1}^t \Omega(f_k)$$
其中$l$是损失函数,$\Omega(fk) = \gamma T + \frac{1}{2}\lambda \sum{j=1}^T w_j^2$是正则化项,$T$是叶节点数量,$w_j$是叶节点权重。
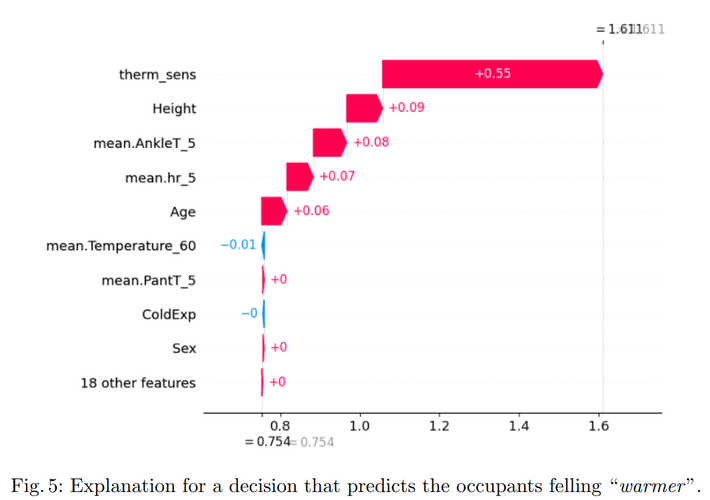
图5描述:这是一个瀑布图,详细展示了单个预测案例中各特征对最终预测"温暖"感觉的贡献。图的底部显示了基准值(E[f(X)] = 0.754),然后逐个特征的贡献被叠加上去。热敏感性(therm_sens)贡献最大(+0.55),将预测值大幅推向"温暖"类别。身高(Height)和平均脚踝温度(mean.AnkleT_5)也有正贡献(分别为+0.09和+0.08)。一些特征如平均温度(mean.Temperature_60)有轻微的负贡献(-0.01)。最终的预测值达到1.611,强烈指向"温暖"类别。
4. 以人为中心的可解释性框架
4.1 系统架构

图1描述:该图展示了以人为中心的XAI智能家居系统的整体架构。系统由五个主要组件组成,通过箭头表示数据流和交互关系。智能家居数据(Smart Home Data)存储在圆柱形数据库中,流入预测模型(Predictive Models)。用户视角(Users' Perspectives)通过文档图标表示,直接影响以人为中心的XAI模块(Human-centered XAI),该模块位于系统中心。预测结果与以人为中心的XAI模块双向交互,最终生成带有HC解释的预测(Prediction with HC-Explanation),由用户图标接收。这种循环架构确保了用户反馈能够持续改进系统的可解释性。
系统的信息流可以形式化表示为:
$$\text{HC-Explanation} = \mathcal{T}(\mathcal{M}(D), U, \mathcal{E})$$
其中$D$是智能家居数据,$\mathcal{M}$是预测模型,$U$是用户视角,$\mathcal{E}$是解释生成函数,$\mathcal{T}$是将技术解释转换为人类可理解形式的转换函数。
4.2 解释的三个层次
研究提出了解释的三层框架:
语法层(Syntactic Level):涉及视觉呈现的数学优化。设$V$为视觉编码函数,$C$为认知负荷,优化问题为:
$$\min_V C(V(E)) \text{ s.t. } I(V(E)) \geq I_{\text{min}}$$
其中$E$是解释,$I$是信息保真度。
语义层(Semantic Level):涉及心理模型的构建。用户的心理模型$M_u$与系统真实模型$M_s$之间的差异可以表示为:
$$\Delta = D_{KL}(M_u || M_s) = \sum_x M_u(x) \log \frac{M_u(x)}{M_s(x)}$$
目标是通过适当的解释最小化这个KL散度。
语用层(Pragmatic Level):涉及实际应用价值。效用函数定义为:
$$U(E) = \alpha \cdot \text{Trust}(E) + \beta \cdot \text{Action}(E) + \gamma \cdot \text{Learning}(E)$$
其中$\alpha$、$\beta$、$\gamma$是权重系数,分别对应信任建立、行动支持和学习促进。
5. HCI方法论
5.1 用户研究方法
图6描述:该图以图标形式展示了四种HCI技术的循环关系。用户研究(User Studies)用人物剪影图标表示,强调对真实用户行为的观察。原型设计(Prototyping)用代码符号表示,体现迭代开发过程。技术探针分析(Technology Probes Analysis)用数据交换图标表示,强调双向信息流。启发式评估(Heuristic Evaluation)用任务清单图标表示,体现系统化的评估过程。四个方法通过隐含的循环关系相连,表明这是一个非线性的迭代过程。
用户研究的效果可以通过以下指标衡量:
$$\text{Effectiveness} = \frac{\text{Correct Understanding}}{\text{Total Explanations}} \times \frac{1}{\text{Average Time}}$$
5.2 原型设计迭代
原型改进的收敛性可以用以下公式描述:
$$U_{n+1} = U_n + \alpha \sum_{i=1}^m w_i \cdot F_i$$
其中$U_n$是第$n$次迭代的可用性分数,$F_i$是用户反馈,$w_i$是反馈权重,$\alpha$是学习率。
附录:数学推导
A. SHAP值的理论证明
定理A.1:SHAP值是唯一满足局部准确性、缺失性、一致性和对称性的特征归因方法。
证明:
考虑一个具有$n$个特征的模型$f$,定义特征子集$S \subseteq N = {1,2,...,n}$的边际贡献为:
$$v(S) = \mathbb{E}[f(x_S, X_{\bar{S}})] - \mathbb{E}[f(X)]$$
其中$xS$表示特征子集$S$的观察值,$X{\bar{S}}$表示补集$\bar{S} = N \setminus S$的随机变量。
根据Shapley定理,唯一的公平分配方案是:
$$\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!(n-|S|-1)!}{n!}[v(S \cup \{i\}) - v(S)]$$
为了证明唯一性,假设存在另一个满足所有公理的归因方法$\psi$。由对称性,对于任何置换$\pi$:
$$\psi_{\pi(i)} = \psi_i$$
由局部准确性:
$$\sum_{i=1}^n \psi_i = v(N) - v(\emptyset)$$
通过归纳法可以证明,对于任意子集$S$:
$$\sum_{i \in S} \psi_i = v(S) - v(\emptyset)$$
这个线性系统有唯一解,即Shapley值。$\square$
B. LSTM能量预测的梯度推导
对于LSTM的反向传播,我们需要计算损失函数$L$关于各个参数的梯度。
设预测的能源需求为$\hat{y}_t = W_y h_t + b_y$,损失函数为:
$$L = \frac{1}{T}\sum_{t=1}^T (y_t - \hat{y}_t)^2$$
梯度计算:
$$\frac{\partial L}{\partial W_o} = \sum_t \frac{\partial L}{\partial h_t} \cdot \frac{\partial h_t}{\partial o_t} \cdot \frac{\partial o_t}{\partial W_o}$$
其中:
$$\frac{\partial h_t}{\partial o_t} = \tanh(C_t)$$
$$\frac{\partial o_t}{\partial W_o} = o_t(1-o_t)[h_{t-1}, X_t]^T$$
类似地,对于细胞状态的梯度:
$$\frac{\partial L}{\partial C_t} = \frac{\partial L}{\partial h_t} \cdot o_t \cdot (1-\tanh^2(C_t)) + \frac{\partial L}{\partial C_{t+1}} \cdot f_{t+1}$$
这种递归结构允许梯度通过时间反向传播。
C. XGBoost的目标函数优化
XGBoost使用二阶泰勒展开来优化目标函数。对于第$t$轮的目标函数:
$$\mathcal{L}^{(t)} = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \Omega(f_t)$$
使用泰勒展开:
$$\mathcal{L}^{(t)} \approx \sum_{i=1}^n [l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2}h_i f_t^2(x_i)] + \Omega(f_t)$$
其中:
$$g_i = \frac{\partial l(y_i, \hat{y}_i^{(t-1)})}{\partial \hat{y}_i^{(t-1)}}$$
$$h_i = \frac{\partial^2 l(y_i, \hat{y}_i^{(t-1)})}{\partial (\hat{y}_i^{(t-1)})^2}$$
对于给定的树结构,叶节点$j$的最优权重为:
$$w_j^* = -\frac{\sum_{i \in I_j} g_i}{\sum_{i \in I_j} h_i + \lambda}$$
相应的最优目标函数值为:
$$\mathcal{L}^{(t)} = -\frac{1}{2}\sum_{j=1}^T \frac{(\sum_{i \in I_j} g_i)^2}{\sum_{i \in I_j} h_i + \lambda} + \gamma T$$
D. 认知负荷的信息论建模
用户理解解释的认知负荷可以用信息论来建模。设用户的先验知识为$P$,解释包含的信息为$E$,理解后的知识为$K$。
信息增益:
$$I(K;E|P) = H(K|P) - H(K|E,P)$$
认知负荷与处理的信息量成正比:
$$C = \alpha \cdot H(E|P) + \beta \cdot D_{KL}(Q_E || P)$$
其中$QE$是解释隐含的概率分布,$D{KL}$是KL散度,衡量用户先验与解释之间的差异。
最优解释应该最大化信息增益同时最小化认知负荷:
$$E^* = \arg\max_E \left[ I(K;E|P) - \lambda C(E) \right]$$
这个优化问题可以通过变分方法求解,得到:
$$p(e|k,p) \propto \exp\left(\frac{1}{\lambda}[\log p(k|e,p) - \alpha H(e|p)]\right)$$
E. 多智能体系统中的解释协调
在智能家居环境中,多个AI系统可能需要协调它们的解释。设有$n$个智能体,每个生成解释$E_i$。
全局一致性约束:
$$\sum_{i=1}^n w_i E_i = E_{\text{global}}$$
其中权重$w_i$通过纳什议价解确定:
$$\max \prod_{i=1}^n (U_i - d_i)$$
subject to:
$$U_i = u_i(E_1, ..., E_n) \geq d_i$$
这里$U_i$是智能体$i$的效用,$d_i$是分歧点。
拉格朗日函数:
$$\mathcal{L} = \sum_{i=1}^n \log(U_i - d_i) + \lambda \left(\sum_{i=1}^n w_i E_i - E_{\text{global}}\right)$$
一阶条件给出:
$$\frac{1}{U_i - d_i} \frac{\partial U_i}{\partial E_j} = \lambda w_j$$
这确保了解释的帕累托最优性和公平性。


