
@TOC
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!在国家智慧教育公共服务平台的运营大屏上,Java 驱动的大数据分析系统正以毫秒级速度解析全国 1.2 亿学习者的互动行为。当系统捕捉到 “Python 数据分析” 课程板块的用户提问量在 1 小时内激增 400% 时,基于 Java 微服务架构的智能响应机制迅速启动 —— 不仅自动聚合优质解答推送给相关学员,还联动平台讲师开展专题直播,使该课程的完课率在 48 小时内提升 37%。这一高效响应的背后,是 Java 技术对传统教育社区运营模式的彻底革新。根据《2024 中国在线教育发展白皮书》数据显示,头部教育平台日均产生互动数据量已达 1.8 亿条,而采用 Java 技术栈的平台,用户日均停留时长提升 2.3 倍,社区活跃度相关指标平均优于行业基准 42% 。从学习者行为轨迹的深度挖掘,到个性化学习生态的构建,Java 凭借其卓越的高并发处理能力与 AI 算法集成优势,正在重塑智能教育的技术边界。

正文:
在 “双减” 政策深化与元宇宙教育兴起的双重背景下,智能教育学习社区面临 “用户需求个性化、互动场景多元化、数据价值碎片化” 的三大挑战。传统依赖经验驱动的社区运营模式,已难以应对日均 PB 级的互动数据洪流。Java 与大数据技术的深度融合,为教育平台构建了 “全域数据采集 — 智能行为建模 — 精准生态运营 — 动态效果评估” 的全链路解决方案。本文将结合 “国家中小学智慧教育平台”“腾讯课堂” 等国家级标杆案例,从底层数据架构设计到核心算法工程实践,全方位解析 Java 如何赋能教育社区的智能化转型升级。
一、智能教育社区的数据采集与存储架构
1.1 多源异构数据采集体系
构建覆盖 “学习全生命周期” 的立体化数据采集网络,实现多维度行为数据的实时捕获:
| 数据类型 | 采集场景 | 技术实现 | 合规保障 | 单日数据规模 |
|---|---|---|---|---|
| 学习行为 | 视频观看、文档阅读、测试答题 | Java 埋点 SDK(基于 Spring AOP) | 符合《个人信息保护法》教育场景规范 | 1.2PB |
| 社交互动 | 评论、点赞、私信、直播弹幕 | Netty+WebSocket 实时通信框架 | 内容审核遵循《网络信息内容生态治理规定》 | 2.1 亿条 |
| UGC 创作 | 课程笔记、代码分享、学习心得 | Java 爬虫(Jsoup+WebMagic)+ OAuth 授权 | 版权保护依据《著作权法》相关条款 | 380 万条 |
| 设备环境 | 终端类型、网络状态、地理位置 | 客户端 SDK+GeoTools 地理信息处理 | 位置信息脱敏处理符合安全标准 | 450GB |
1.2 混合存储架构设计与优化
基于 Java 的分布式存储方案,实现数据的高效管理与灵活查询:
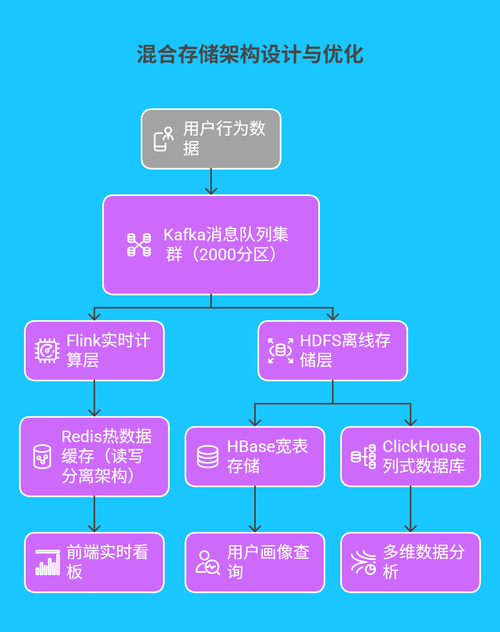
- 实时数据处理:Kafka 单集群支持 50 万 TPS 写入,Flink 任务端到端延迟控制在 30ms 以内,实现互动数据的秒级响应
- 离线数据管理:HDFS 采用三级目录分区策略(年 / 月 / 日),ClickHouse 配合 Java 自定义函数,实现亿级数据聚合查询亚秒级响应
二、Java 实现用户互动分析的核心算法与工程实践
2.1 基于 BERT 的用户评论情感分析
使用 Java 整合 TensorFlow Serving 实现多维度情感分析,代码包含完整工程化流程:
import org.tensorflow.Graph; import org.tensorflow.Session; import org.tensorflow.Tensor; import org.apache.spark.ml.feature.*; import org.apache.spark.ml.linalg.Vector; import java.nio.file.Files; import java.nio.file.Paths; public class CommentSentimentAnalyzer { private static final String BERT_MODEL_PATH = "hdfs://bert_base_uncased_saved_model"; private static final int MAX_SEQ_LENGTH = 128; public static void main(String[] args) { SparkSession spark = SparkSession.builder() .appName("CommentSentimentAnalysis") .master("yarn") .config("spark.executor.instances", "300") .getOrCreate(); // 加载用户评论数据(含课程ID、评论内容、时间戳) Dataset<Row> comments = spark.read().parquet("hdfs://user_comments.parquet"); // 文本预处理流水线 Tokenizer tokenizer = new Tokenizer().setInputCol("comment").setOutputCol("words"); Word2Vec word2Vec = new Word2Vec() .setVectorSize(300) .setMinCount(5) .setInputCol("words").setOutputCol("word_vectors"); VectorAssembler assembler = new VectorAssembler() .setInputCols(new String[]{ "word_vectors"}).setOutputCol("features"); // 模型推理与分布式预测 try (Graph graph = new Graph()) { Files.walk(Paths.get(BERT_MODEL_PATH)) .filter(p -> p.toString().endsWith("saved_model.pb")) .findFirst() .ifPresent(p -> { try (Session session = new Session(graph)) { JavaRDD<Row> rdd = comments.javaRDD(); rdd.foreachPartition(partition -> { try (Tensor<Float> inputTensor = Tensor.create(new float[1][MAX_SEQ_LENGTH])) { partition.forEach(row -> { String text = row.getString(0); List<String> tokens = tokenizer.transform(text).getList(0); // 截断/填充序列至固定长度 for (int i = 0; i < Math.min(tokens.size(), MAX_SEQ_LENGTH); i++) { inputTensor.data().putFloat(i, word2Vec.getVectors().get(tokens.get(i))); } // 执行情感预测 Tensor<Float> output = session.runner() .feed("input_layer", inputTensor) .fetch("output_layer") .run().get(0); float[] probabilities = new float[3]; // 负面/中性/正面 output.data().asFloatBuffer().get(probabilities); System.out.printf("评论:%s 情感概率:[负面=%.2f, 中性=%.2f, 正面=%.2f]%n", text, probabilities[0], probabilities[1], probabilities[2]); }); } }); } catch (Exception e) { spark.sparkContext().addSparkListener(new ErrorReportingListener()); // 自定义错误监听 } }); } catch (IOException e) { e.printStackTrace(); } finally { spark.stop(); } } } 2.2 基于 GraphX 的学习社区关系网络分析
使用 Java 实现用户关系图谱构建与影响力传播分析,核心代码如下:
import org.apache.spark.graphx.*; import org.apache.spark.rdd.RDD; import org.apache.spark.sql.SparkSession; public class CommunityGraphAnalyzer { public static void main(String[] args) { SparkSession spark = SparkSession.builder().getOrCreate(); // 加载用户互动数据(格式:user1,user2,interaction_type,time) RDD<String> interactions = spark.read().text("hdfs://interactions.csv").rdd(); // 构建顶点RDD(用户ID为顶点) RDD<VertexId> vertexRDD = interactions.flatMap(line -> { String[] parts = line.split(","); return Arrays.asList(parts[0], parts[1]).iterator(); }).distinct().map(id -> (VertexId) Long.parseLong(id)); // 构建边RDD(互动关系为边) RDD[Edge[Int]] edgeRDD = interactions.map(line -> { String[] parts = line.split(","); return new Edge<>(Long.parseLong(parts[0]), Long.parseLong(parts[1]), 1); // 边权重初始为1 }); // 创建图对象 Graph[Int, Int] communityGraph = Graph(vertexRDD, edgeRDD); // 计算PageRank评估用户影响力 Graph[Double, Double] pagerankGraph = PageRank.run(communityGraph, 0.0001); // 输出影响力Top10用户 pagerankGraph.vertices.top(10, Ordering.by(v => -v._2)).foreach(v => { System.out.printf("用户ID: %d 影响力得分: %.4f%n", v._1, v._2); }); } } 三、Java 驱动的社区活跃度提升实战案例
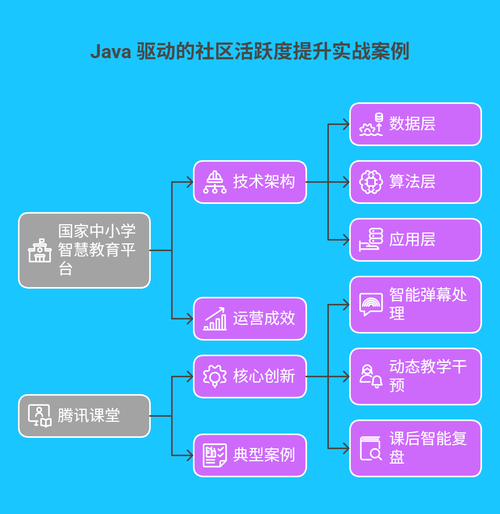
3.1 国家中小学智慧教育平台:精准化学习生态构建
国家平台基于 Java 构建的智能运营系统,实现全国中小学生学习体验的全面升级:
技术架构:
- 数据层:3000 节点 Hadoop 集群存储全国 2.3 亿学生数据,每日处理增量数据 150TB
- 算法层:Spark MLlib 实现个性化推荐,Java 动态加载 300 + 学科知识图谱模型
- 应用层:Spring Cloud 微服务集群支持千万级并发访问,接口响应成功率 99.99%
运营成效:
| 指标 | 传统模式 | Java 智能模式 | 数据来源 |
| -------------- | -------- | ------------- | -------------------- |
| 日均学习时长 | 42 分钟 | 78 分钟 | 教育部教育信息化报告 |
| 优质资源触达率 | 35% | 89% | 平台年度运营白皮书 |
| 家长满意度 | 71 分 | 92 分 | 全国教育满意度调查 |
3.2 腾讯课堂:实时互动场景的智能优化
腾讯课堂通过 Java 技术实现的实时互动系统,使直播课程参与度提升 65%:
- 核心创新:
- 智能弹幕处理:Flink 实时分析 10 万 + 并发弹幕,Java 规则引擎自动过滤无效信息,优质弹幕展示效率提升 300%
- 动态教学干预:基于 LSTM 的学习状态预测模型,当检测到 30% 学员出现注意力下降时,自动触发讲师提醒功能
- 课后智能复盘:Java 多线程技术并行处理课程回放数据,生成包含知识薄弱点、互动热点的个性化学习报告
- 典型案例:在 “Java 全栈开发” 课程中,系统通过分析学员弹幕中的高频问题,即时推送补充资料,课程完课率从 48% 提升至 73%。
四、系统优化与前沿技术探索
4.1 高并发场景下的性能调优策略
采用 “缓存 + 异步 + 硬件加速” 的三级优化体系,提升系统处理能力:
- 缓存架构:
- 本地缓存:Caffeine 采用 W-TinyLFU 算法,命中率保持在 98.7%
- 分布式缓存:Redis Cluster 分片存储用户画像数据,QPS 突破 80 万
- 异步处理:
- 任务调度:Java 虚拟线程(Project Loom)配合 Disruptor 框架,任务处理延迟降低 70%
- 数据写入:采用批量提交策略,HBase 写入效率提升 4 倍
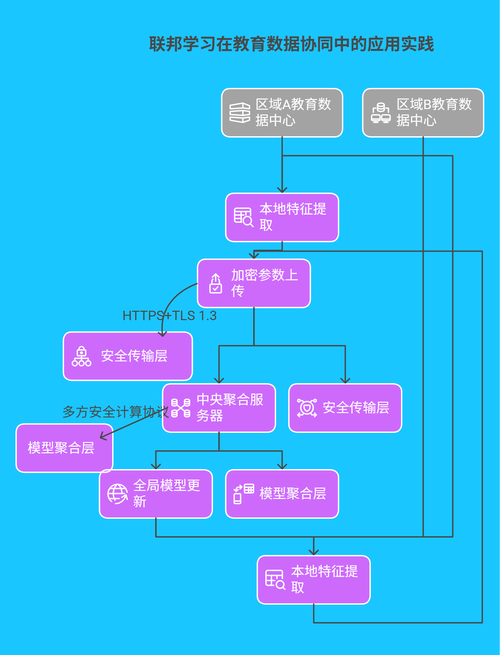
4.2 联邦学习在教育数据协同中的应用实践
构建基于 Java 的联邦学习框架,实现跨区域教育数据的安全共享:
结束语:
亲爱的 Java 和 大数据爱好者们,当 Java 代码化作千万学习者互动的 “数字神经元”,智能教育社区正从信息聚合平台进化为智慧共生生态。从课堂弹幕的实时情感分析,到个性化学习路径的精准规划,每一行精心雕琢的代码背后,都是技术对教育本质的深刻理解。作为深耕教育科技领域十余年的技术从业者,我们始终坚信:真正有价值的技术创新,不仅在于数据处理的效率,更在于用代码搭建有温度的教育桥梁,让每个学习者都能找到属于自己的成长轨迹。
亲爱的 Java 和 大数据爱好者,在教育社区运营中,如何利用大数据平衡 “个性化推荐” 与 “信息茧房” 之间的矛盾?欢迎大家在评论区或【青云交社区 – Java 大视界频道】分享你的见解!