❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 丰富的 AI 工具库 -> 每日更新 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🎮 "设计师集体失业?清华黑科技让照片'活'过来:扔个苹果进画里竟能弹跳!"
大家好,我是蚝油菜花。当别人还在用3D建模软件手动调参数时,这个来自清华的AI已经让静态图像「觉醒」了!你是否也遇到过这些创作困境:
- 👉 想给产品图加动态效果,却卡在3D建模环节半个月
- 👉 物理模拟参数调到怀疑人生,结果物体穿模飞天
- 👉 客户临时要改场景光照,渲染农场排队到下周...
今天要解剖的 PhysGen3D ,正在颠覆数字内容生产流程!这个由清华等顶尖高校打造的「图像魔法引擎」,用三大绝技重新定义创作自由:
✅ 单图造世界:上传照片自动重建3D场景,连阴影角度都完美还原
✅ 物理预言家:用物质点方法模拟真实弹跳/破碎/流体效果
✅ 光影炼金术:基于PBR渲染技术,让合成视频以假乱真
已有团队用它1天做完广告特效,文末附《从照片到好莱坞特效》实战指南——你的创意,是时候突破次元壁了!
🚀 快速阅读
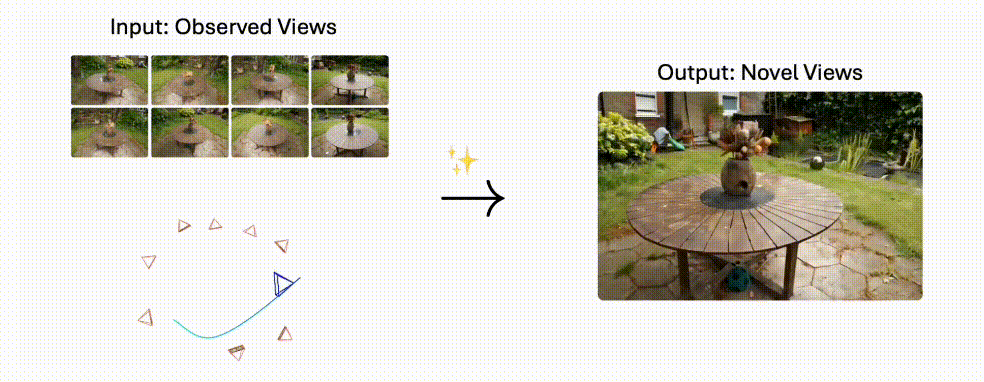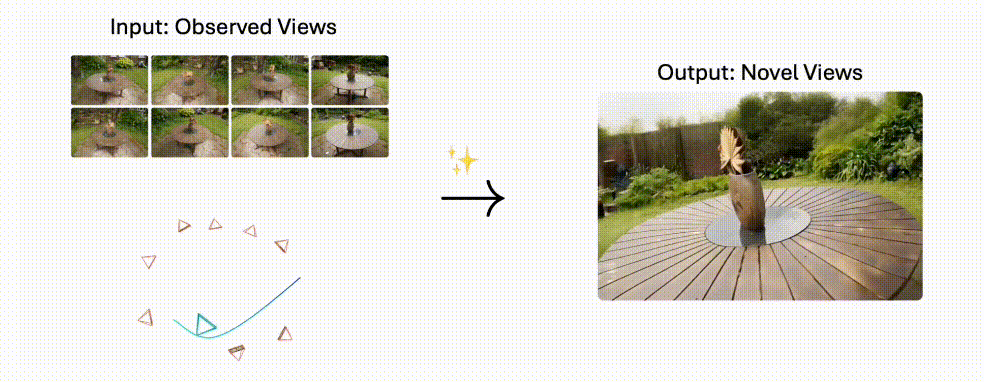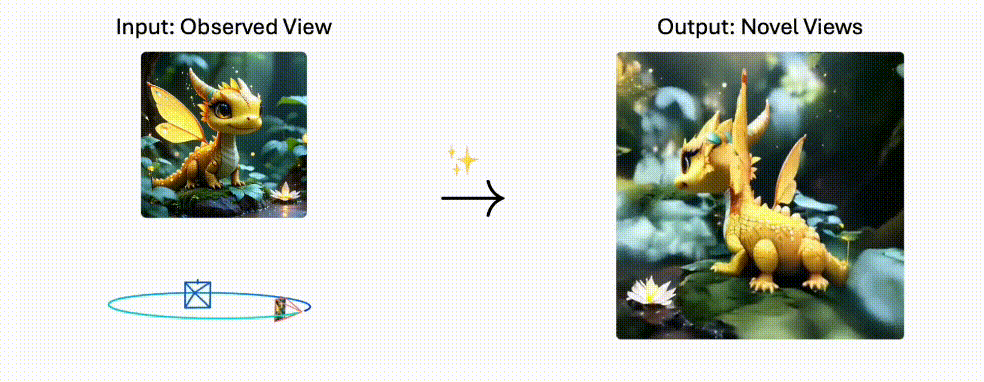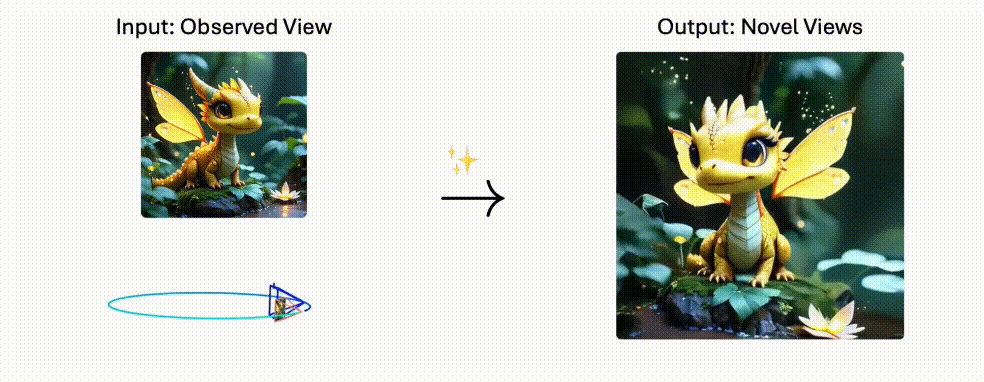
PhysGen3D是一个将单张图像转换为交互式3D场景的创新框架。
- 功能:支持物体跟踪、视频编辑、相机控制等交互操作
- 原理:结合3D重建、物质点方法和物理渲染技术
PhysGen3D 是什么

PhysGen3D 是创新的框架,能将单张图像转换为交互式的 3D 场景,生成具有物理真实感的视频。结合了基于图像的几何和语义理解以及基于物理的模拟,通过从单张图像中推断物体的 3D 形状、姿态、物理和光照属性,创建出以图像为中心的数字孪生。
再基于物质点方法(MPM)模拟物体的反事实物理行为,最终将动态效果无缝整合到原始图像中,生成视觉逼真的结果。该技术突破了传统3D重建的局限,实现了从静态到动态的跨越式发展。
PhysGen3D 的主要功能
- 单图转3D:从单张图像创建完整可交互的3D场景
- 物理模拟:支持物体速度、材质等参数的精确控制
- 动态跟踪:对场景中的物体进行密集3D跟踪
- 视频编辑:跨场景物体交换与背景保持
- 多视角生成:支持自由切换摄像机角度
- 绘画处理:兼容生成图像和手绘作品输入
PhysGen3D 的技术原理
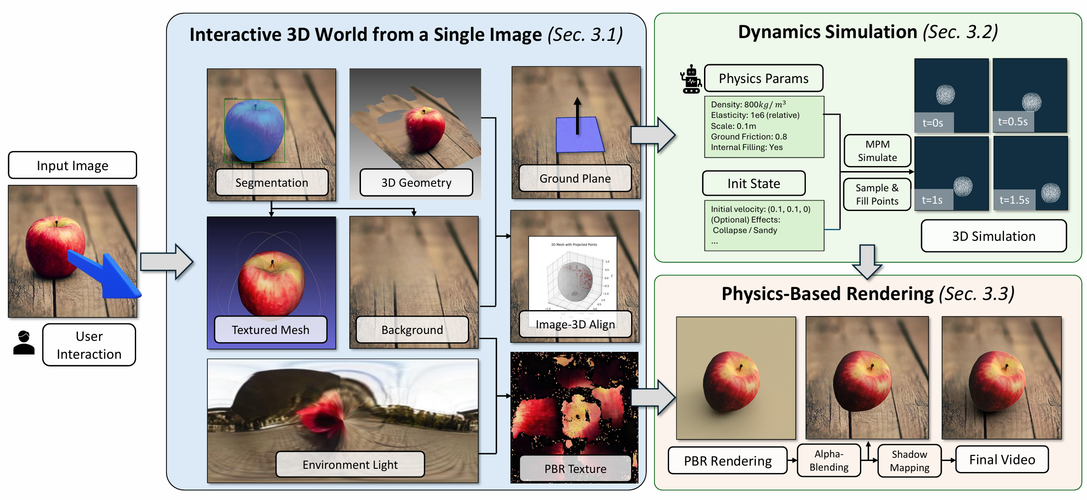
- 3D重建:整合多模态视觉模型,重建几何与外观
- 物质点方法:采用MPM框架模拟真实物理行为
- PBR渲染:通过两遍阴影映射实现光影融合
- 数字孪生:构建包含物理属性的场景表征
如何运行 PhysGen3D
1. 环境安装
conda create -y -n phys python=3.10 conda activate phys git clone --recurse-submodules git@github.com:by-luckk/PhysGen3D.git cd PhysGen3D bash env_install/env_install.sh bash env_install/download_pretrained.sh 2. 感知模块
python perception.py --input_image data/img/teddy.jpg --text_prompt teddy 3. 物理模拟
python simulation.py --config data/sim/teddy.yaml 4. 渲染输出
python rendering.py \ -i ./sim_result/sim_result_${time} \ --path outputs/teddy \ --env data/hdr/teddy.exr \ -b 0 \ -e 100 \ -f \ -s 1 \ -o render_result/1 \ -M 460 \ -p 20 \ --shutter-time 0.0 资源
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 丰富的 AI 工具库 -> 每日更新 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦