
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 🚀 魔都架构师 | 全网30W技术追随者
- 🔧 大厂分布式系统/数据中台实战专家
- 🏆 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 🌍 以技术驱动创新,我们的征途是改变世界!
- 👉 实战干货:编程严选网
1 运行 Ollama
与 qwen2:0.5b 聊天
ollama run qwen2:0.5b 启动成功后,ollama 在本地 11434 端口启动了一个 API 服务,可通过 http://localhost:11434 访问。
2 Dify 中接入 Ollama
2.1 添加模型
在 设置 > 模型供应商 > Ollama 添加模型:
填写 LLM 信息:
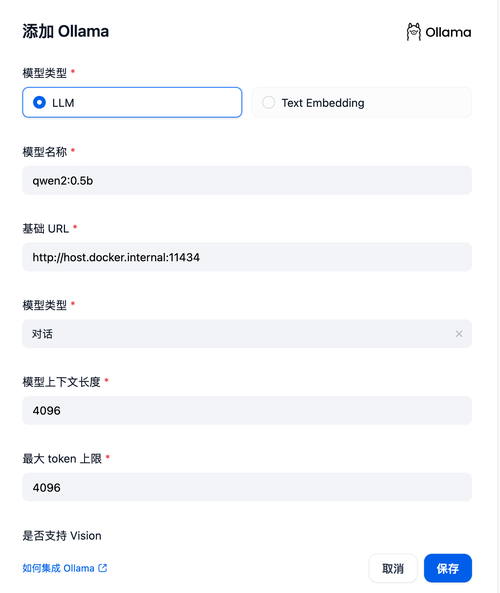
模型名称:以 ollama 返回的为准
$ ollama ls NAME ID SIZE MODIFIED qwen2:0.5b 6f48b936a09f 352 MB 7 months ago 那就得填写:qwen2:0.5b
基础 URL:http://<your-ollama-endpoint-domain>:11434
此处需填写 Ollama 服务地址。如果填写公开 URL 后仍提示报错,请参考常见问题,修改环境变量并使得 Ollama 服务可被所有 IP 访问。
若 Dify 为:http://192.168.65.0:11434
Docker 部署,建议填写局域网 IP 地址,如:
http://192.168.1.100:11434或 Docker 容器的内部 IP 地址,例如:http://host.docker.internal:11434若为本地源码部署,可填
http://localhost:11434模型类型:
对话模型上下文长度:
4096模型的最大上下文长度,若不清楚可填写默认值 4096。
最大 token 上限:
4096模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。
是否支持 Vision:
是当模型支持图片理解(多模态)勾选此项,如
llava。
点击 "保存" 校验无误后即可在应用中使用该模型。

Embedding 模型接入方式与 LLM 类似,只需将模型类型改为 Text Embedding 即可。
2.2 使用 Ollama 模型
进入需要配置的 App 提示词编排页面,选择 Ollama 供应商下的 llava 模型,配置模型参数后即可使用:

3 报错
如用 Docker 部署 Dify 和 Ollama,可能遇到报错:
httpconnectionpool (host=127.0.0.1, port=11434): max retries exceeded with url:/api/chat (Caused by NewConnectionError ('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused')) 3.1 原因
Docker 容器无法访问 Ollama 服务。localhost 通常指的是容器本身,而不是主机或其他容器。要解决此问题,你要将 Ollama 服务暴露给网络。
3.2 解决方案
3.2.1 在 Mac 上设置环境变量
如果 Ollama 作为 macOS 应用程序运行,调用 launchctl setenv 设置环境变量:
$ launchctl setenv OLLAMA_HOST "0.0.0.0" 重启 Ollama 应用程序。
若以上步骤无效,毕竟问题在 docker 内部,你应该连接到 host.docker.internal,才能访问 docker 的主机,所以将 localhost 替换为 host.docker.internal ,服务就可以生效了:
http://host.docker.internal:11434 在 Linux 上设置环境变量
如果 Ollama 作为 systemd 服务运行,应该使用 systemctl 设置环境变量:
通过调用
systemctl edit ollama.service编辑 systemd 服务。这将打开一个编辑器。对于每个环境变量,在
[Service]部分下添加一行Environment:[Service] Environment="OLLAMA_HOST=0.0.0.0"保存并退出。
重载
systemd并重启 Ollama:systemctl daemon-reload systemctl restart ollama
在 Windows 上设置环境变量
在 Windows 上,Ollama 继承了你的用户和系统环境变量。
首先通过任务栏点击 Ollama 退出程序
从控制面板编辑系统环境变量
为你的用户账户编辑或新建变量,比如
OLLAMA_HOST、OLLAMA_MODELS等。点击 OK / 应用保存
在一个新的终端窗口运行
ollama
如何在我的网络上暴露 Ollama?
Ollama 默认绑定 127.0.0.1 端口 11434。通过 OLLAMA_HOST 环境变量更改绑定地址。
参考: