
【Databricks】OLTPデータベースであるLakebaseを触ってみた
データ事業本部のueharaです。
今回は、Databricks上で提供されるOLTPデータベースであるLakebaseを触ってみたいと思います。
はじめに
先日、Databricksから新しいデータベースである「Lakebase」が発表されました。
Lakebaseとは
Lakebaseは、一言でいうとストレージ層とコンピューティング層が分離したサーバレスなPostgresベースのOLTPデータベースです。
Databricksが2025年5月に買収を発表したNeonの技術をベースとしています。
レイクハウスとの統合
従来のアーキテクチャでは業務用DBと分析基盤はサイロ化しており、データを移動するにはETLパイプラインの構築や個別のアクセス制御が必要でした。
Lakebaseはレイクハウスとの統合により、業務レイヤーと分析レイヤー間でほぼリアルタイムの同期を実現するものとなっています。必要に応じて、Unity Catalogを使用してデータへのアクセスを制御することもできます。
Unity Catalogで管理しているテーブルは、Lakebaseに自動的に同期する設定をすることが可能です。
ユースケース
ユースケースとしては、分析基盤で作成した分析データをLakebaseに同期し、それをアプリケーションで使うような構成が考えられます。
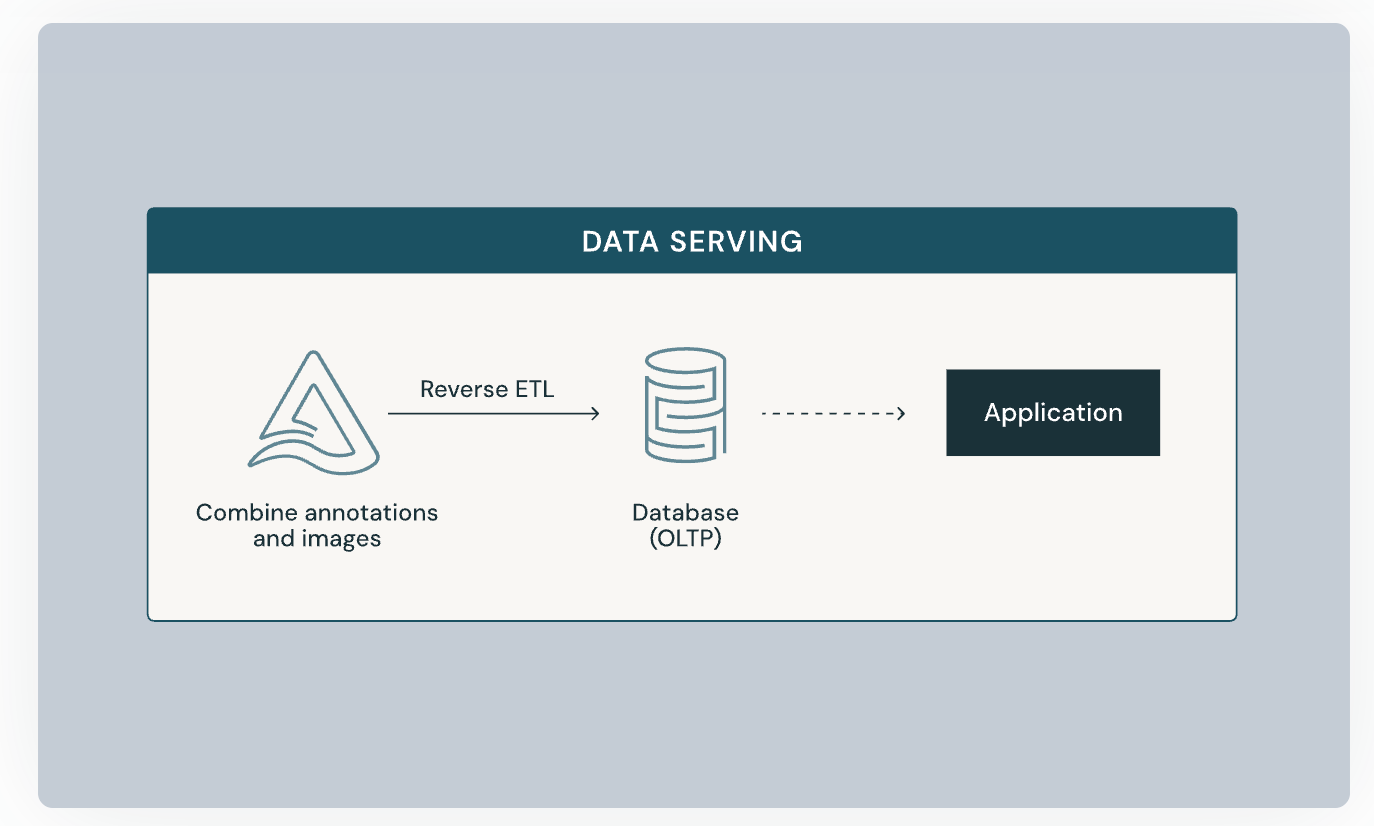
これにより、例えばECにおいては「顧客セグメントに基づくリアルタイムレコメンデーション」を提供することが考えられます。
OLAPなデータベースはあくまで分析に特化しており、トランザクションレベルでのアクセスが必要な業務アプリケーションとしてのAI/MLの活用ユースケースを完璧にカバーできませんでした。
そのため、そのようなユースケースに対応するためのLakebaseという形かなと思います。
前述の通りUnity Catalogで管理しているテーブルからLakebaseへの同期はマネージドな機能を用いて実現可能ですが、アプリケーションからLakebaseに書き込んだデータについては別途ETLを行いLakebaseからUnity Catalogで管理するテーブルに出力することもできます。
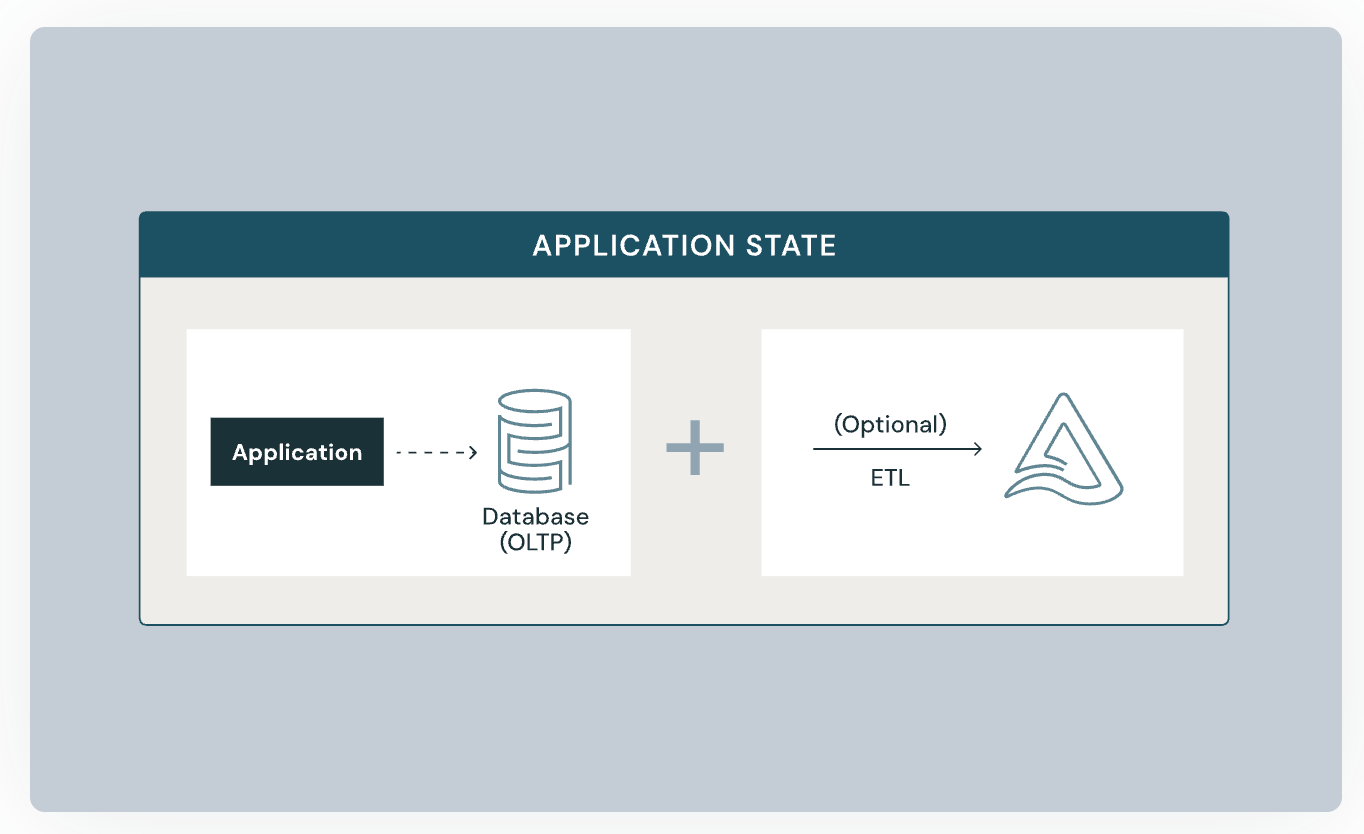
やってみた
事前準備
記事執筆時点ではパブリックプレビューのため、機能有効化の設定から行います。
設定にアクセスするため、Databricksのプロフィールアイコンから『Previews』を選択します。

Previewsの一覧に『Lakebase』があると思うので、これをONにします。

これで事前準備は完了です。
インスタンスの作成
Lakebaseの有効化をすると、『Compute』に『Database instances』のタブが新しく出てきていると思います。
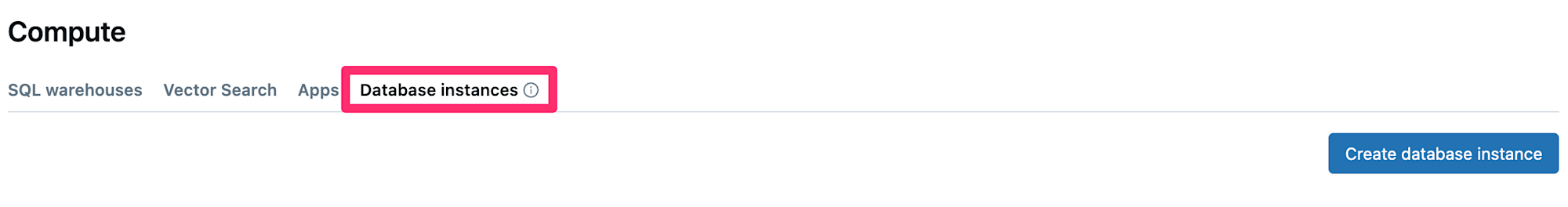
『Create database instance』ボタンを押下し、適当な設定値を入力しインスタンスの作成を行います。
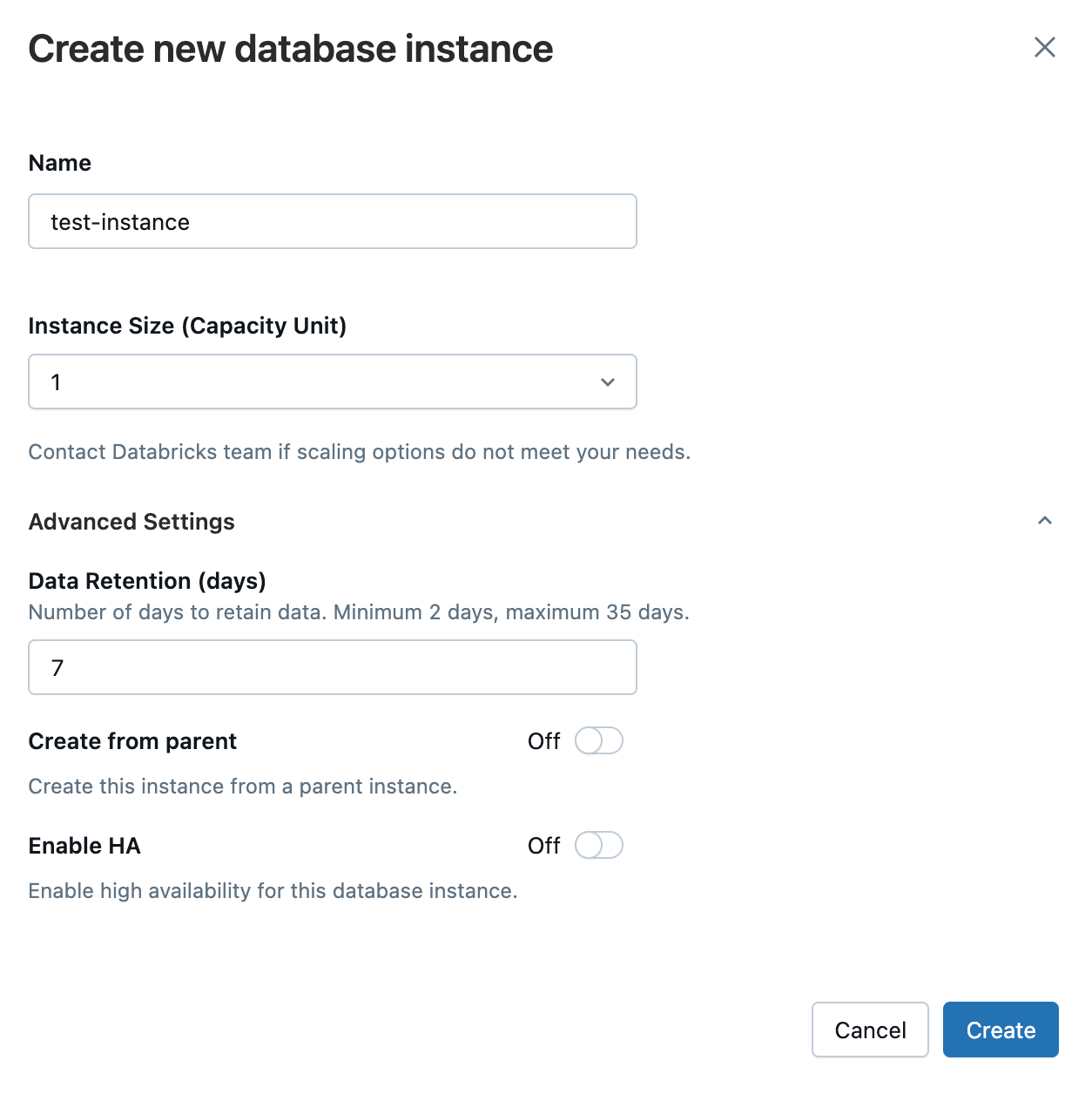
Statusが『Available』となれば作成完了です。
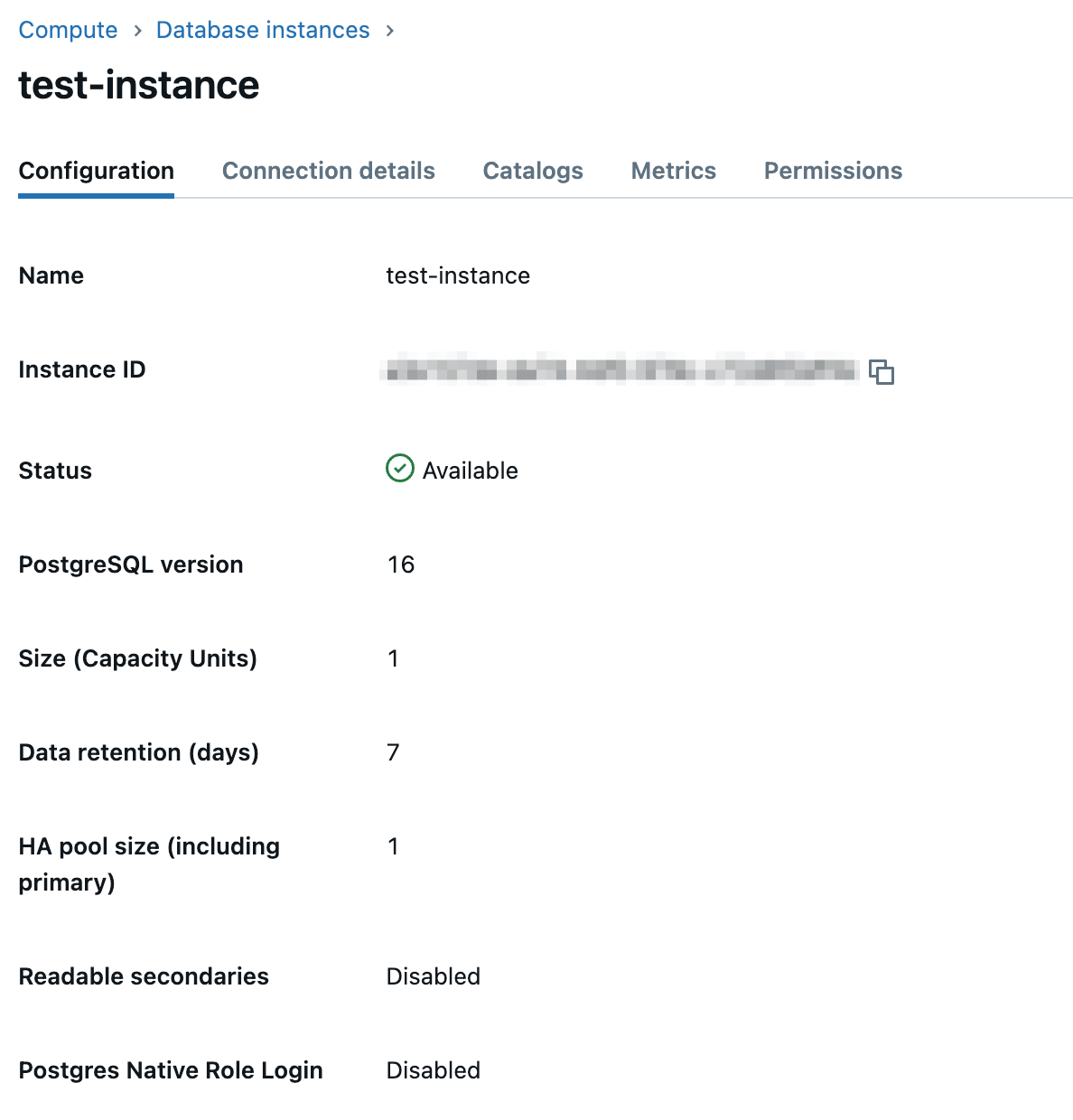
Unity Catalogへ登録
作成したインスタンスの『Catalogs』からUnity Catalogの登録を行います。
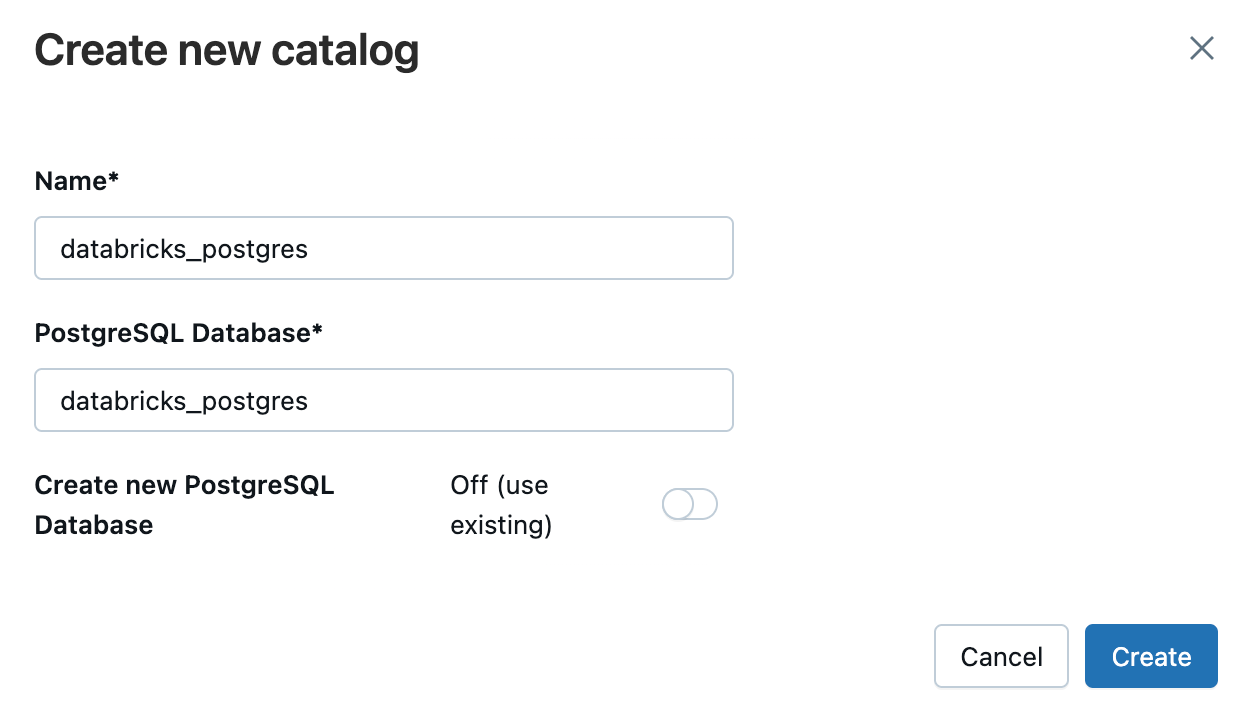
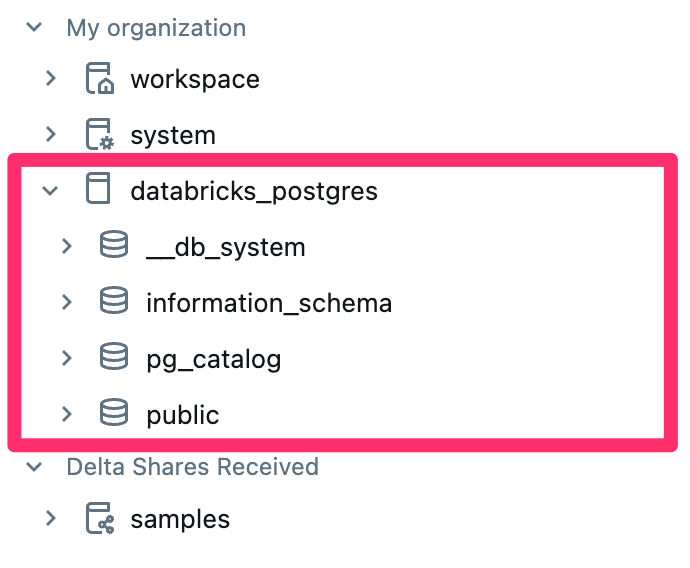
カタログの作成後、Unity Catalog上で確認できるようになっていると思います。
クエリの実行
クエリエディタからクエリを実行してみます。
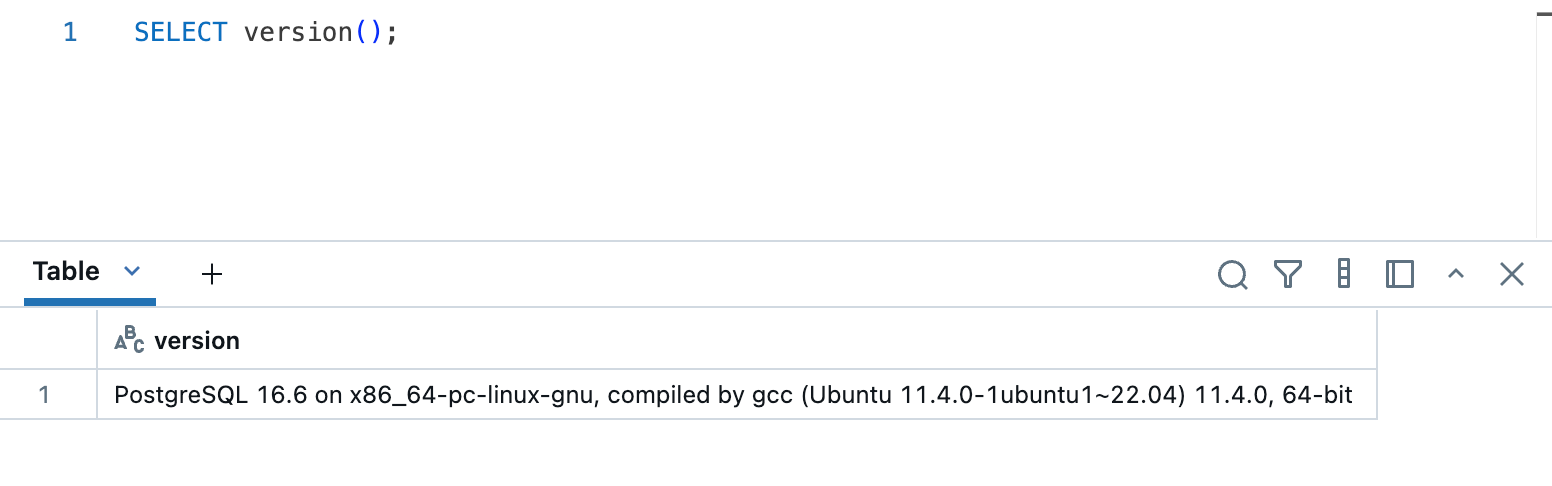
バージョン情報を取得するクエリを実行したところ、特に問題無く取得できました。
Unity Catalogテーブルの同期
Unity Catalogで管理しているテーブルを、Lakebaseに同期してみます。
Catalog上で適当にテーブルを選択し、『Create』ボタンから『Synced Table』を選択します。
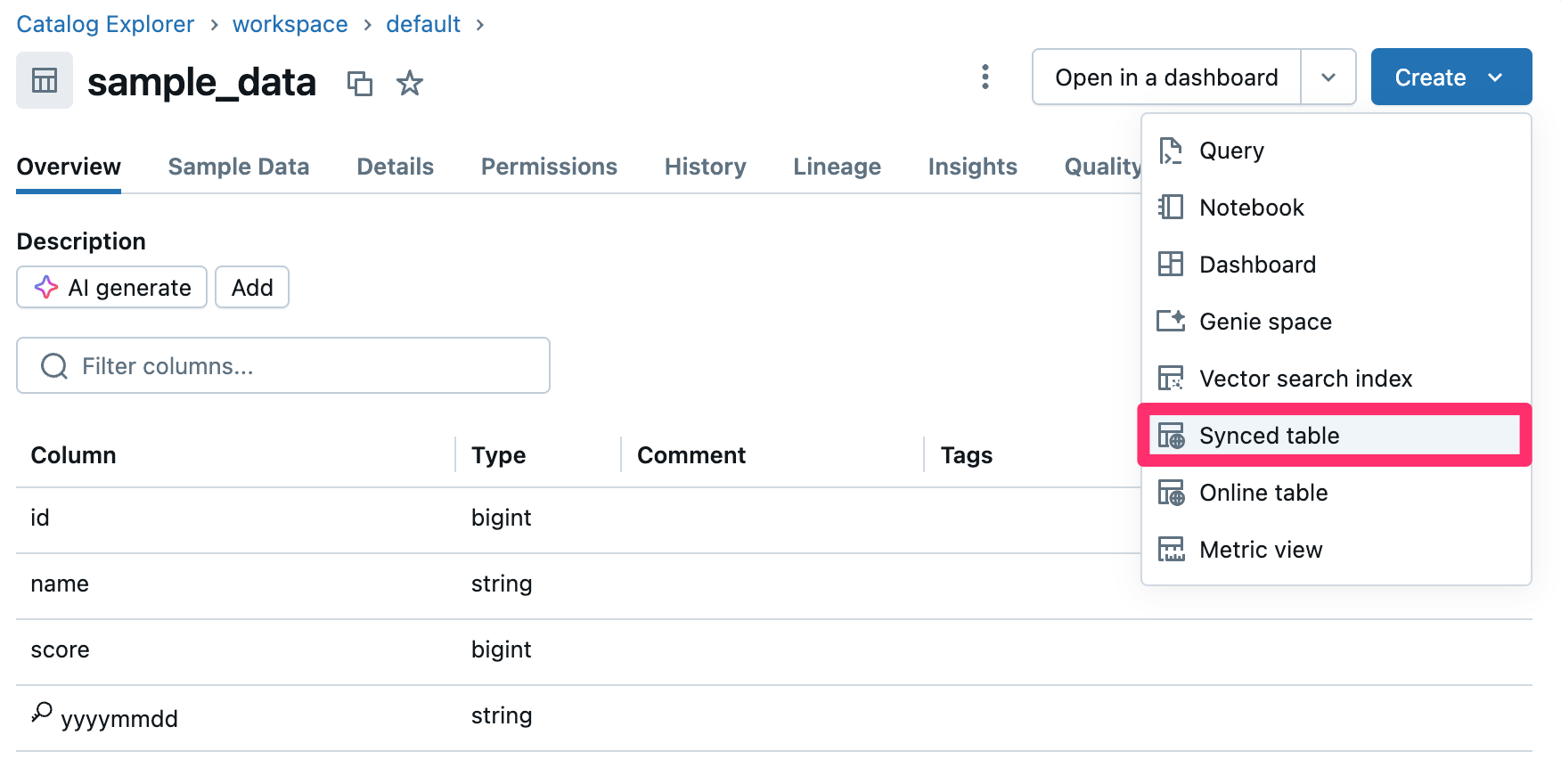
先に作成したLakebaseに同期するよう設定を行います。
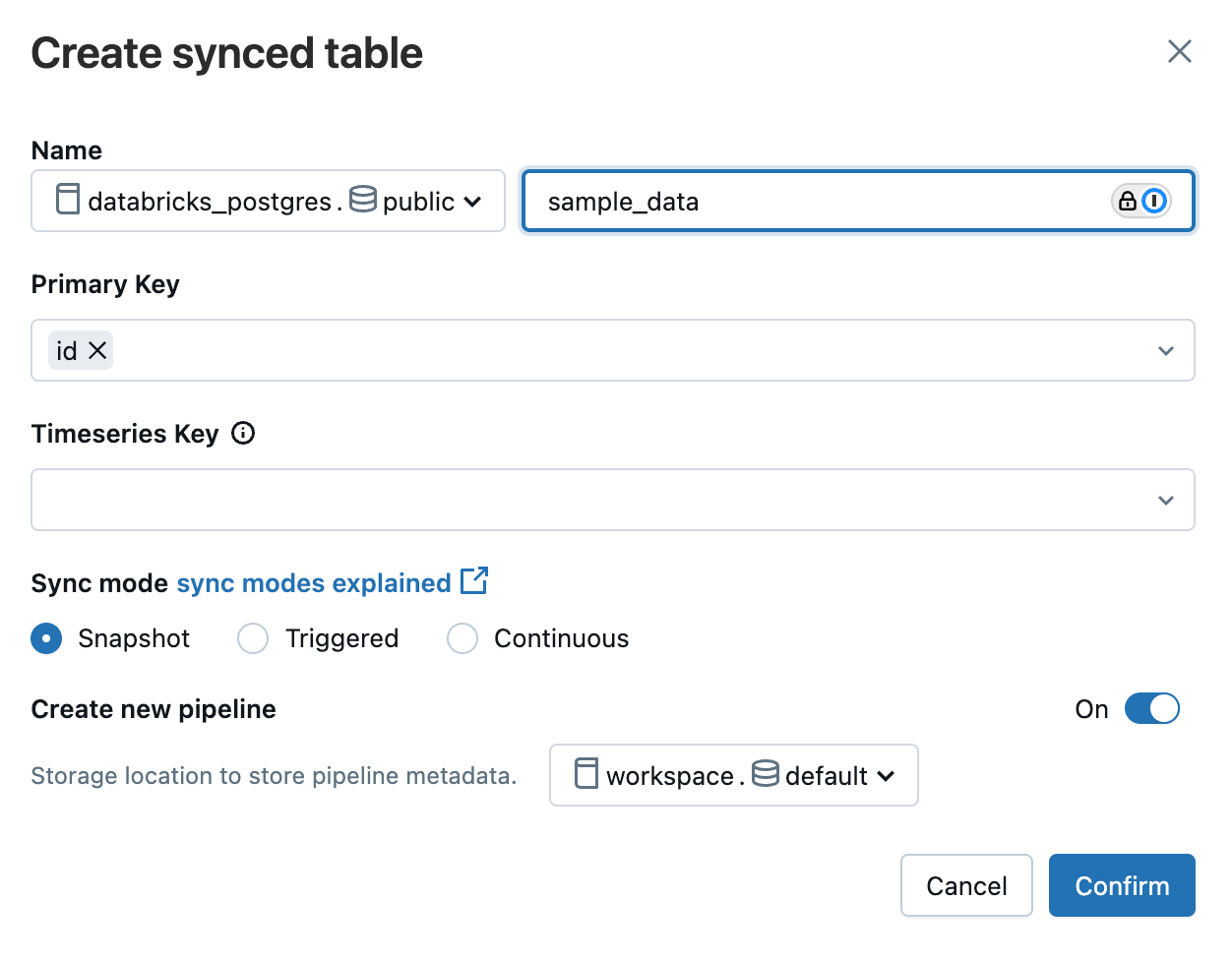
※上記はUnity Catalogで管理される workspace.default.sample_data テーブル をLakebaseの databricks_postgres.public.sample_data テーブルに同期する設定となります。
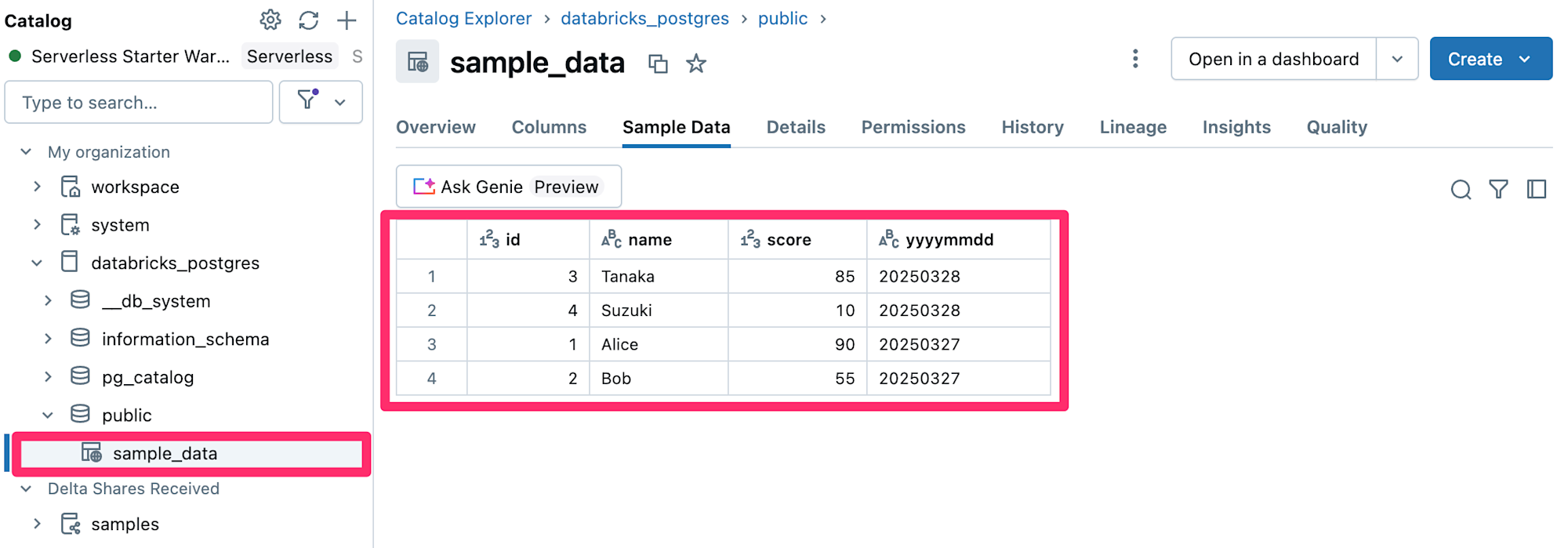
設定が完了すると、以下のようにテーブルデータが同期されたことを確認できました。
補足
冒頭でも少し述べましたが、検証日時点ではLakebaseで作成したテーブルからUnity Catalogで管理しているテーブルへの同期はマネージドな機能としては提供されていないようなのでご留意下さい。
外部から接続してみる
『Compute』から作成したDBインスタンスの『Connection details』にアクセスし、『Get OAuth Token』から認証情報の取得を行います。
作成が完了すると『Copy OAuth Token』ボタンが活性化するので、コピーして環境変数に設定しておきます。
$ export PGPASSWORD=<取得したToken> 提供されている接続情報を元に、以下Pythonスクリプトを作成してみました。
import os import psycopg2 # 環境変数からパスワードを取得 password = os.getenv("PGPASSWORD") # 接続パラメータ conn_params = { "host": "<YOUR_HOST_NAME>", "port": 5432, "database": "databricks_postgres", "user": "<YOUR_USER_NAME>", "password": password, "sslmode": "require", } conn = None cursor = None try: # 接続 conn = psycopg2.connect(**conn_params) cursor = conn.cursor() # クエリ実行例 cursor.execute("SELECT * FROM sample_data;") result = cursor.fetchall() print(result) except psycopg2.Error as e: print(f"データベース接続エラー: {e}") finally: if cursor: cursor.close() if conn: conn.close() ※ <YOUR_HOST_NAME> と <YOUR_USER_NAME> はご自身の環境に合わせて置き換えて下さい。
上記スクリプトを実行してみたところ、無事アクセスおよびデータ取得を確認できました。

モニタリング
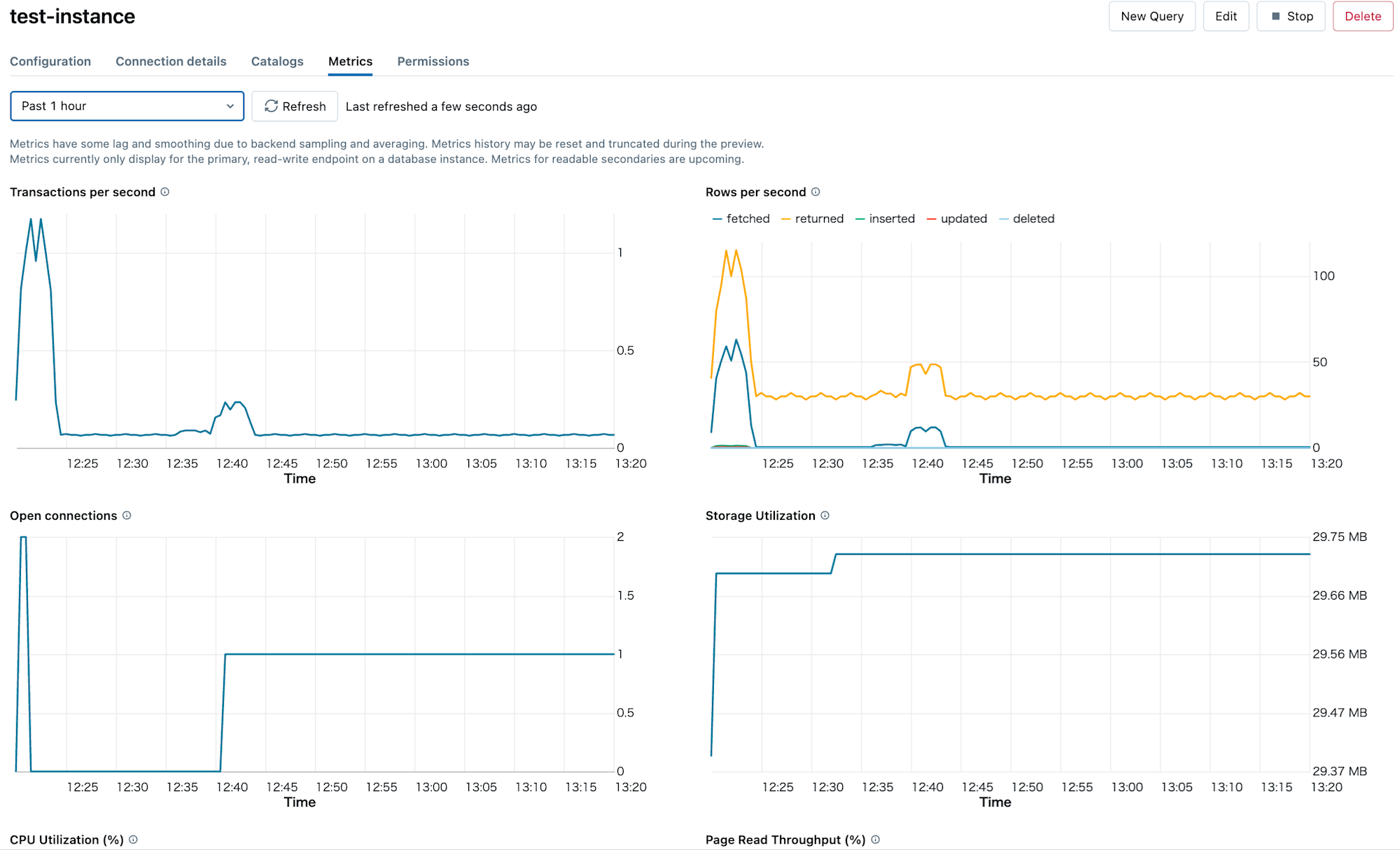
作成したインスタンスの『Metrics』からLakebaseインスタンスのパフォーマンスを確認することができます。
メトリクスには1秒あたりのトランザクション数やアクティブな接続数、ストレージやCPU使用率等があります。
最後に
今回は、Databricks上で提供されるOLTPデータベースであるLakebaseを触ってみました。
Unity Catalogテーブルとの同期も非常に簡単で、かつサーバレスなOLTPデータベースをすぐに使い始められるのは非常に良いと感じました。
参考になりましたら幸いです。










