
Databricks Free Editionでユーザー管理のS3に対する外部テーブル作成・Delta Lakeとしてのデータロードを試してみた
さがらです。
Databricks Free Editionでユーザー管理のS3に対する外部テーブル作成・Delta Lakeとしてのデータロードを試してみたので、その内容を本記事でまとめてみます。
事前準備:Databricks Free Editionのアカウント作成
まず、Databricks Free Editionで検証しますのでそのアカウント作成を行います。
以下の記事が参考になると思います。
S3バケットの作成
databricks-bucket-sagaraという名前で、各設定はデフォルト値でS3バケットを作成します。
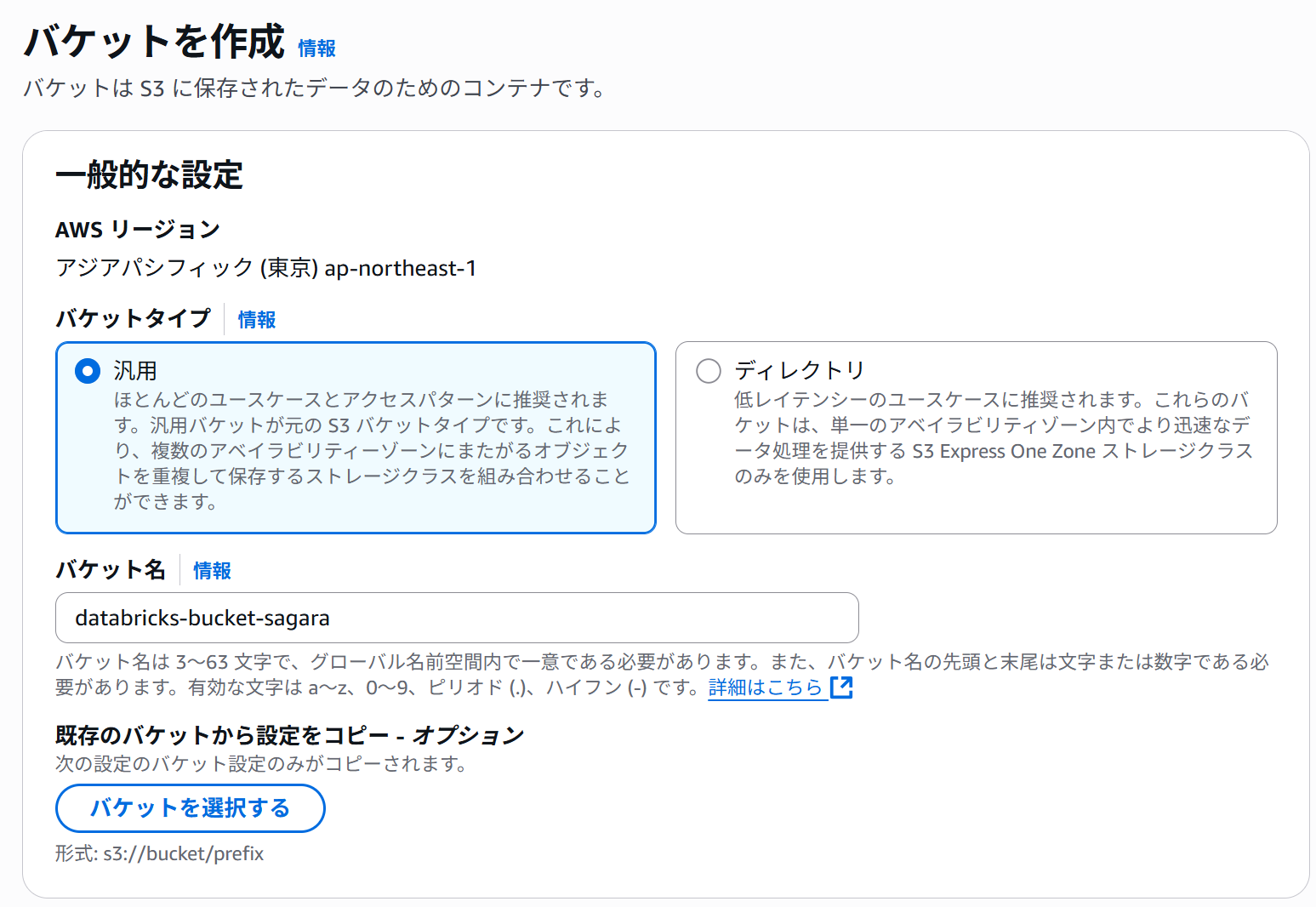
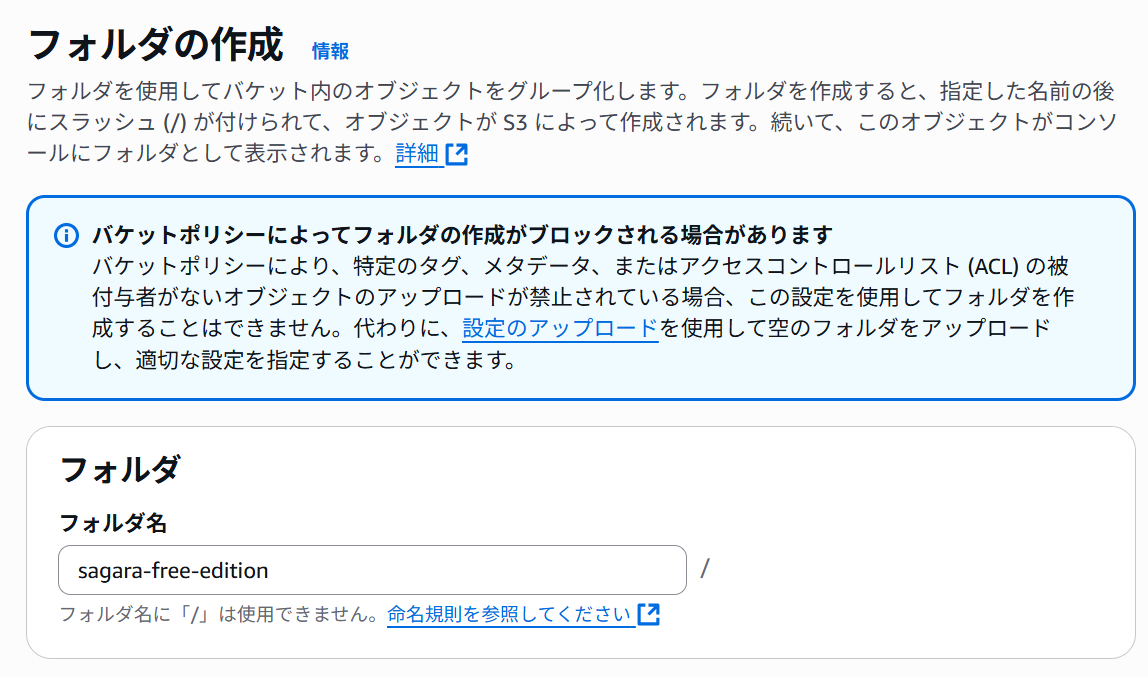
おまけで、Free Edition用のフォルダも作成しておきます。(これは任意です。)
IAMロールの作成
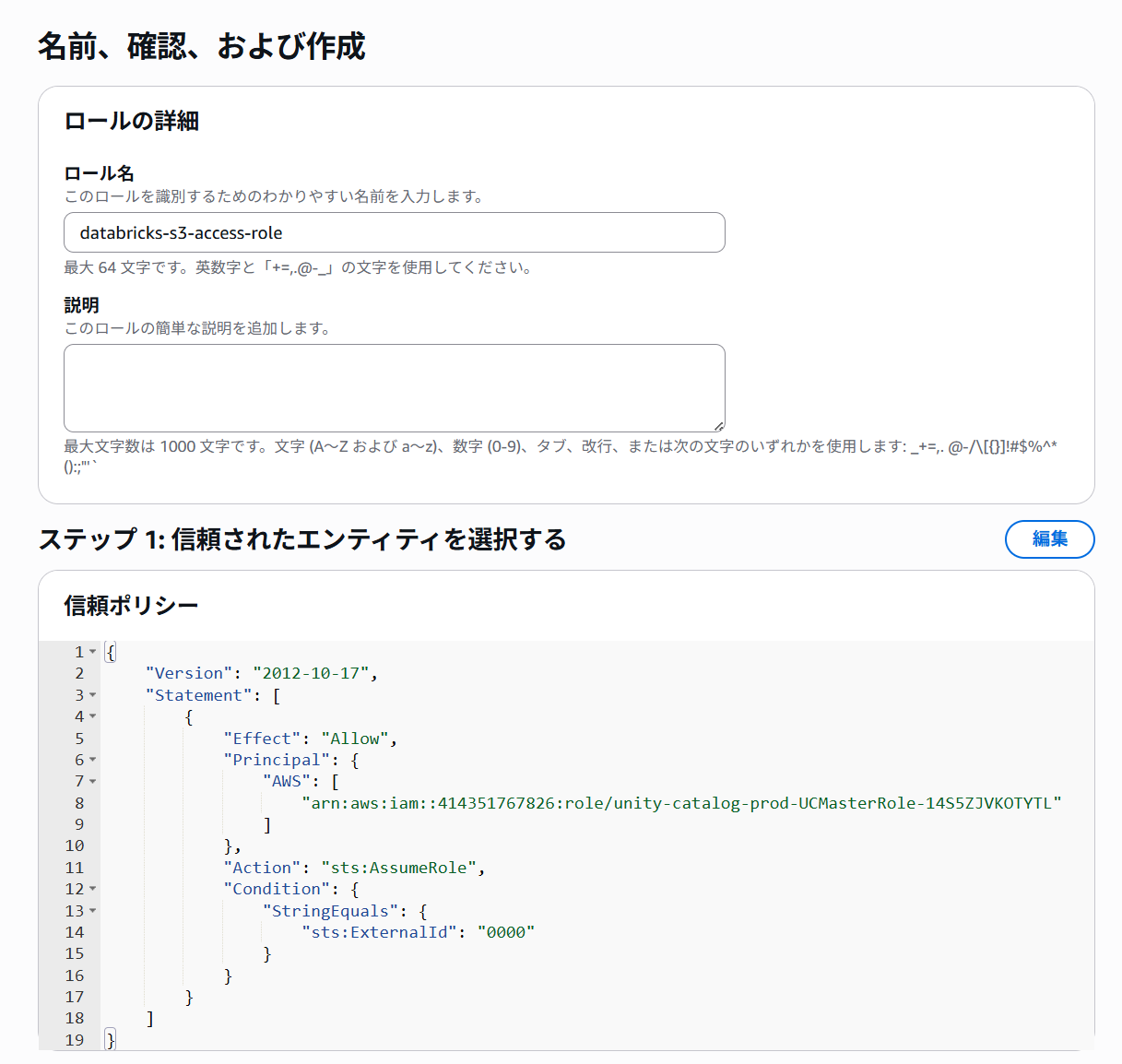
カスタム信頼ポリシーを下記のように設定して、IAMロールを作成します。
このポリシーでは、 Unity Catalogがバケット内のデータにアクセスするロールを引き受けることができるように、アカウント間の信頼関係を確立します。(これはPrincipalセクションのARNによって指定されます。)
sts:ExternalIdの値は後で変更するため、暫定値として公式ドキュメントに沿って0000を入れています。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": ["arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"] }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "0000" } } } ] } IAMロール名はdatabricks-s3-access-roleとしました。
IAMポリシーの作成
以下、2つのIAMポリシーを先ほど作成したIAMロールのインラインポリシーとして作成します。
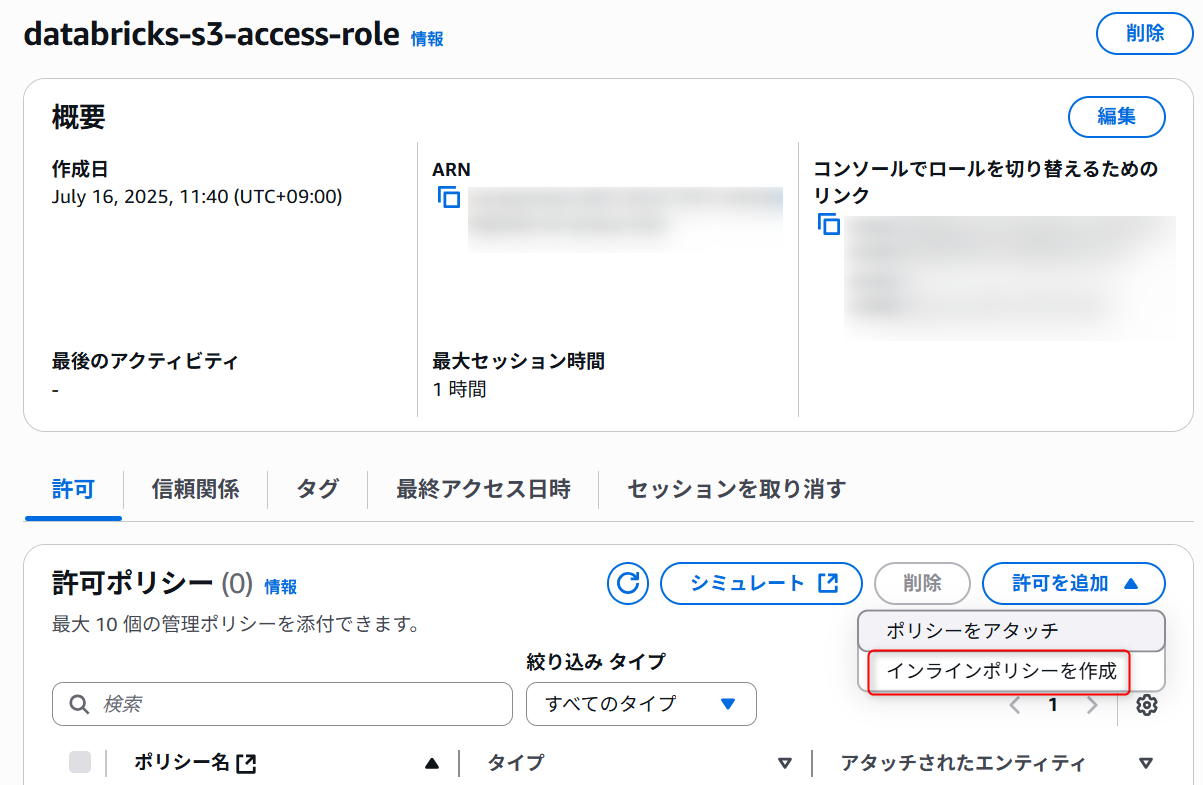
1つ目:S3バケットに対する読み書きのアクセス権限
- 1つ目:S3バケットに対する読み書きのアクセス権限(
databricks-s3-read-write-policyとして作成)<BUCKET>:作成したS3バケット名- 本記事では
databricks-bucket-sagaraが該当
- 本記事では
<AWS-ACCOUNT-ID>:使用しているAWSアカウントID<AWS-IAM-ROLE-NAME>:作成したIAMロール名- 本記事では
databricks-s3-access-roleが該当
- 本記事では
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucket", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads", "s3:ListMultipartUploadParts", "s3:AbortMultipartUpload" ], "Resource": ["arn:aws:s3:::<BUCKET>/*", "arn:aws:s3:::<BUCKET>"], "Effect": "Allow" }, { "Action": ["sts:AssumeRole"], "Resource": ["arn:aws:iam::<AWS-ACCOUNT-ID>:role/<AWS-IAM-ROLE-NAME>"], "Effect": "Allow" } ] } 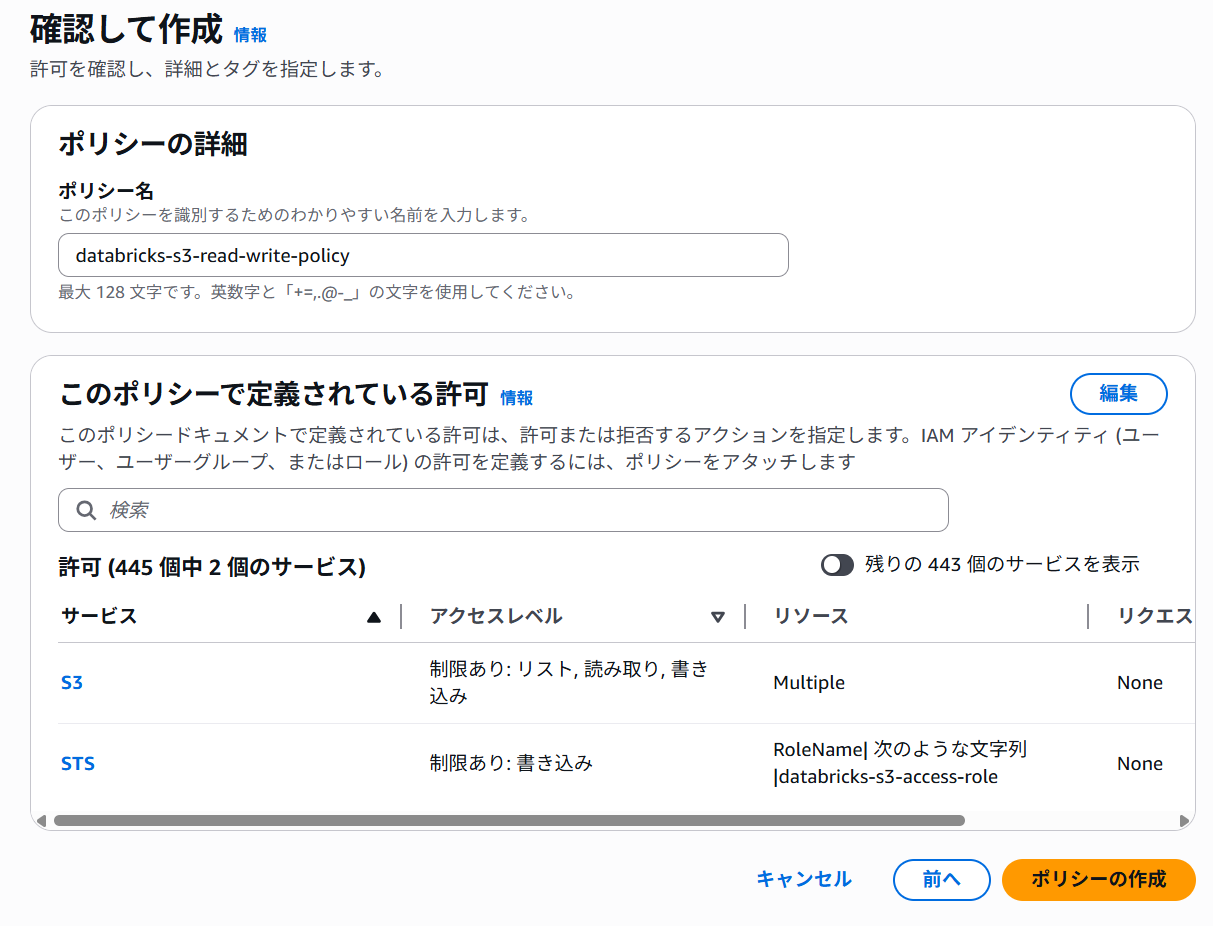
2つ目:Databricksでファイルイベントを設定する場合に必要な権限
- 2つ目:Databricksでファイルイベントを設定する場合に必要な権限(
databricks-s3-file-event-policy)<BUCKET>:作成したS3バケット名- 本記事では
databricks-bucket-sagaraが該当
- 本記事では
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ManagedFileEventsSetupStatement", "Effect": "Allow", "Action": [ "s3:GetBucketNotification", "s3:PutBucketNotification", "sns:ListSubscriptionsByTopic", "sns:GetTopicAttributes", "sns:SetTopicAttributes", "sns:CreateTopic", "sns:TagResource", "sns:Publish", "sns:Subscribe", "sqs:CreateQueue", "sqs:DeleteMessage", "sqs:ReceiveMessage", "sqs:SendMessage", "sqs:GetQueueUrl", "sqs:GetQueueAttributes", "sqs:SetQueueAttributes", "sqs:TagQueue", "sqs:ChangeMessageVisibility", "sqs:PurgeQueue" ], "Resource": ["arn:aws:s3:::<BUCKET>", "arn:aws:sqs:*:*:csms-*", "arn:aws:sns:*:*:csms-*"] }, { "Sid": "ManagedFileEventsListStatement", "Effect": "Allow", "Action": ["sqs:ListQueues", "sqs:ListQueueTags", "sns:ListTopics"], "Resource": ["arn:aws:sqs:*:*:csms-*", "arn:aws:sns:*:*:csms-*"] }, { "Sid": "ManagedFileEventsTeardownStatement", "Effect": "Allow", "Action": ["sns:Unsubscribe", "sns:DeleteTopic", "sqs:DeleteQueue"], "Resource": ["arn:aws:sqs:*:*:csms-*", "arn:aws:sns:*:*:csms-*"] } ] } 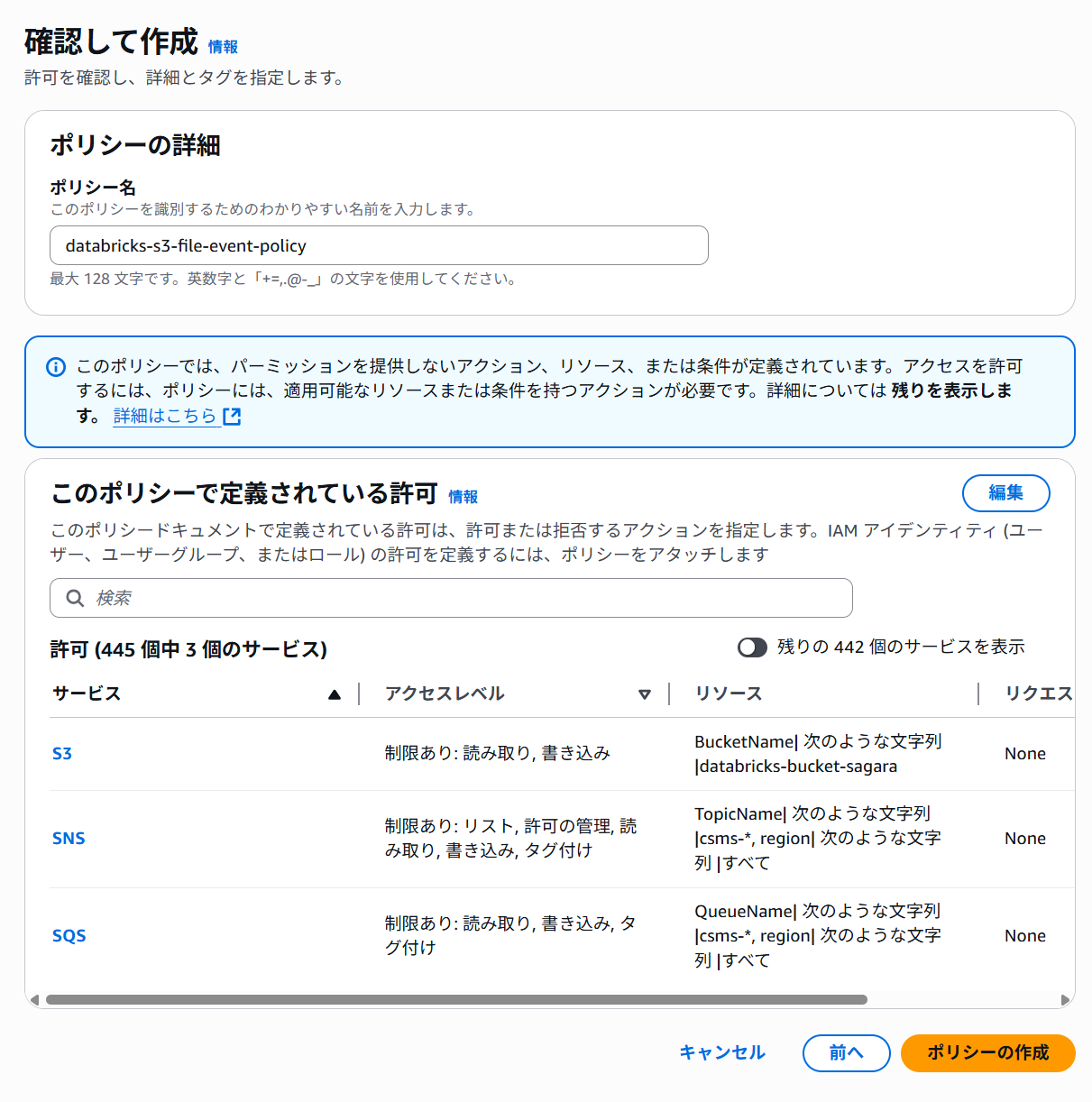
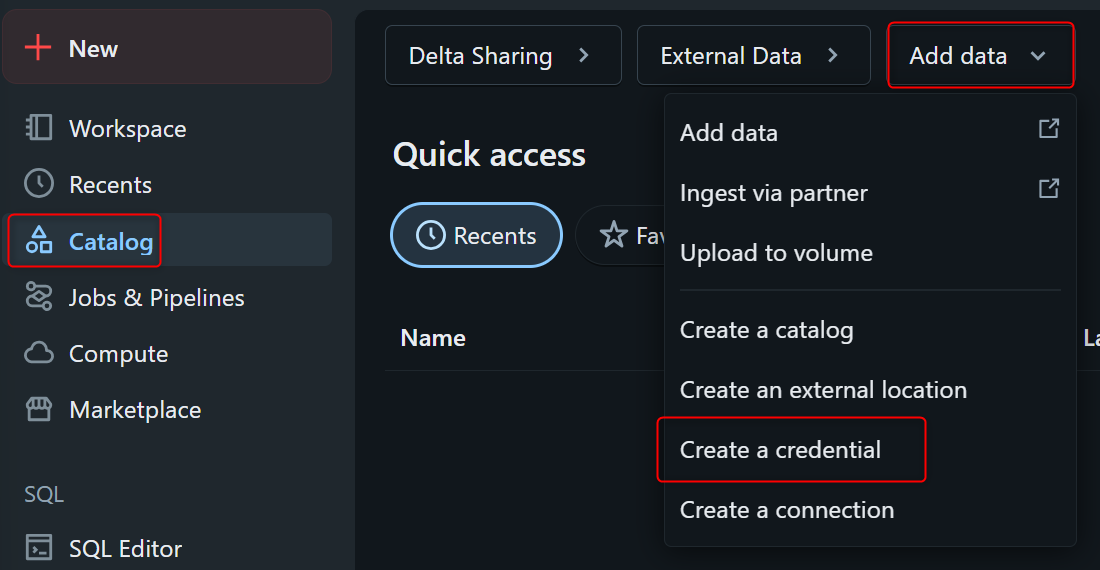
Credentialの作成
Databricksの画面で、CatalogからAdd dataを押し、Create a credentialを押します。
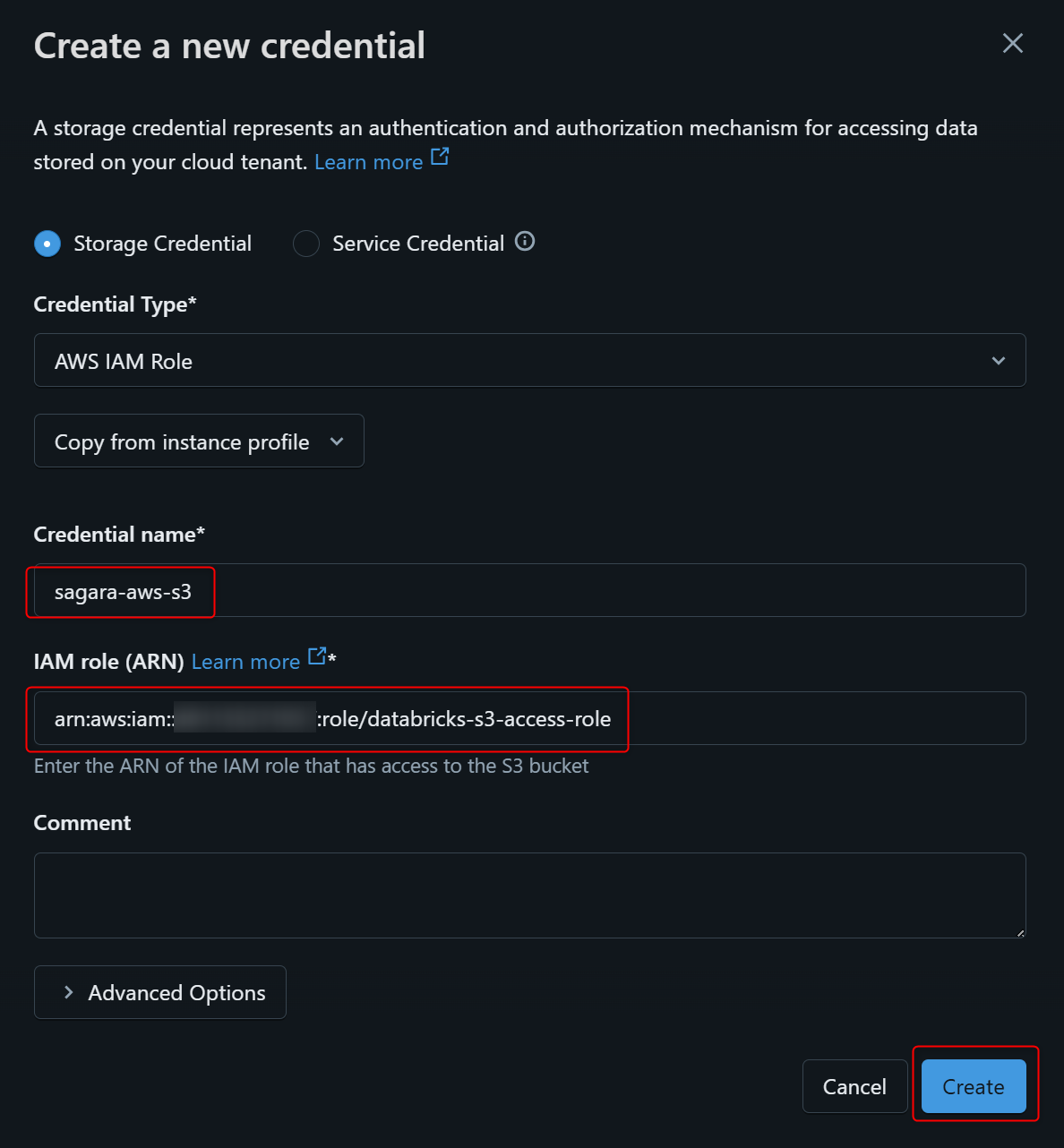
表示された画面でCredential nameを入れて、IAM role(ARN)は先程作成したIAMロールのARNを入れます。
下図のように表示されますので、Trust policyの内容をコピーします。
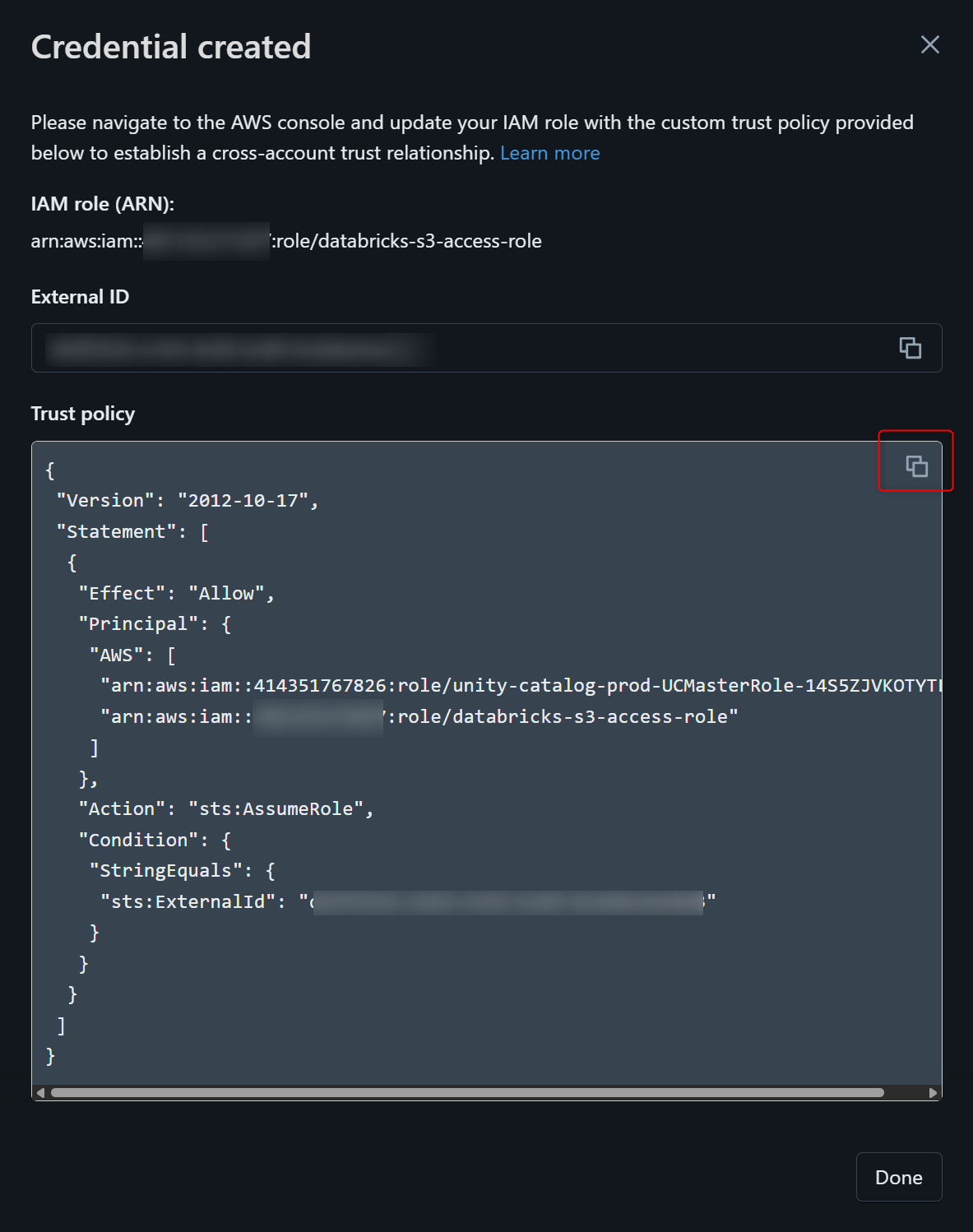
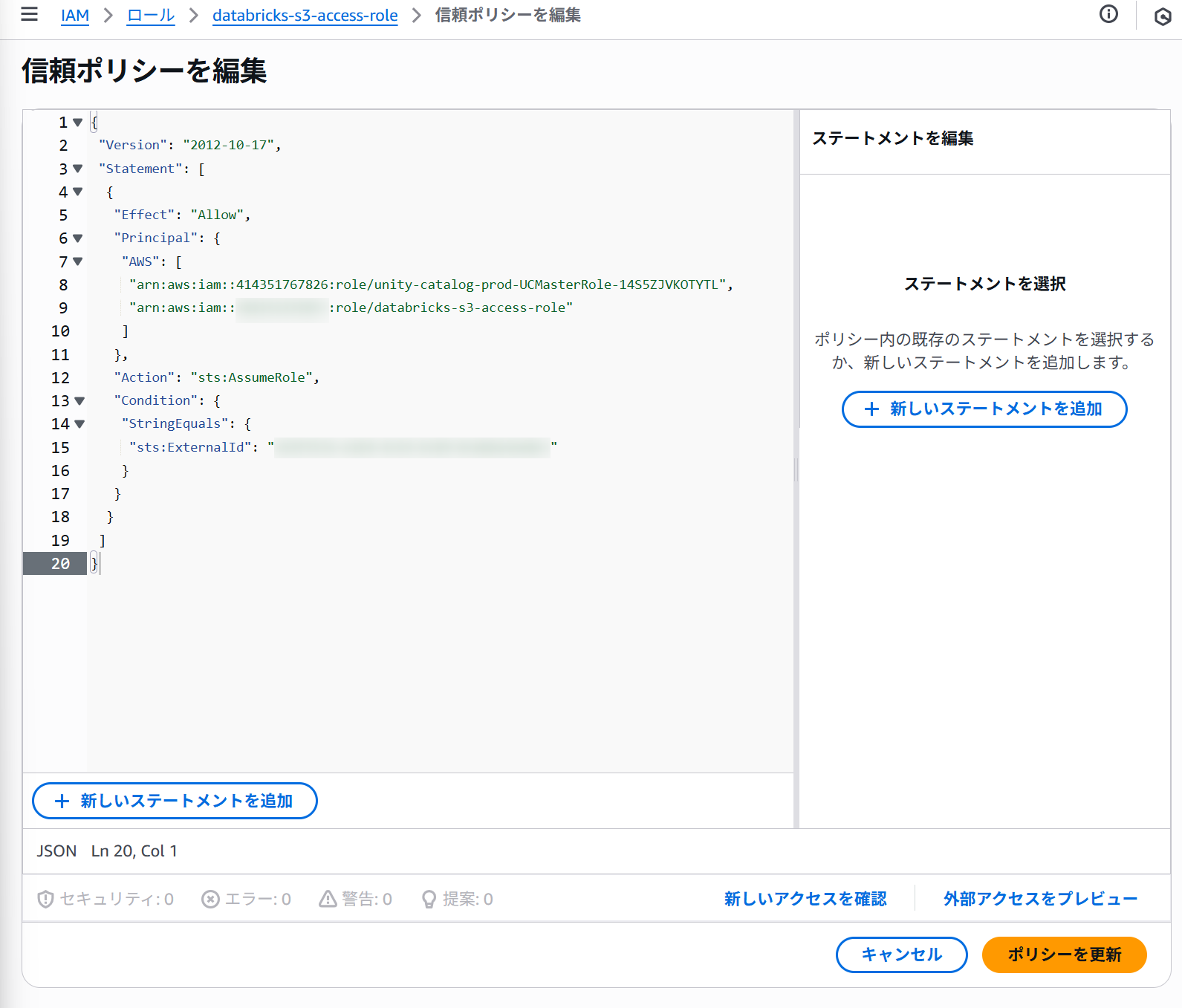
コピーした内容で、作成したIAMロールの信頼ポリシーを書き換えます。
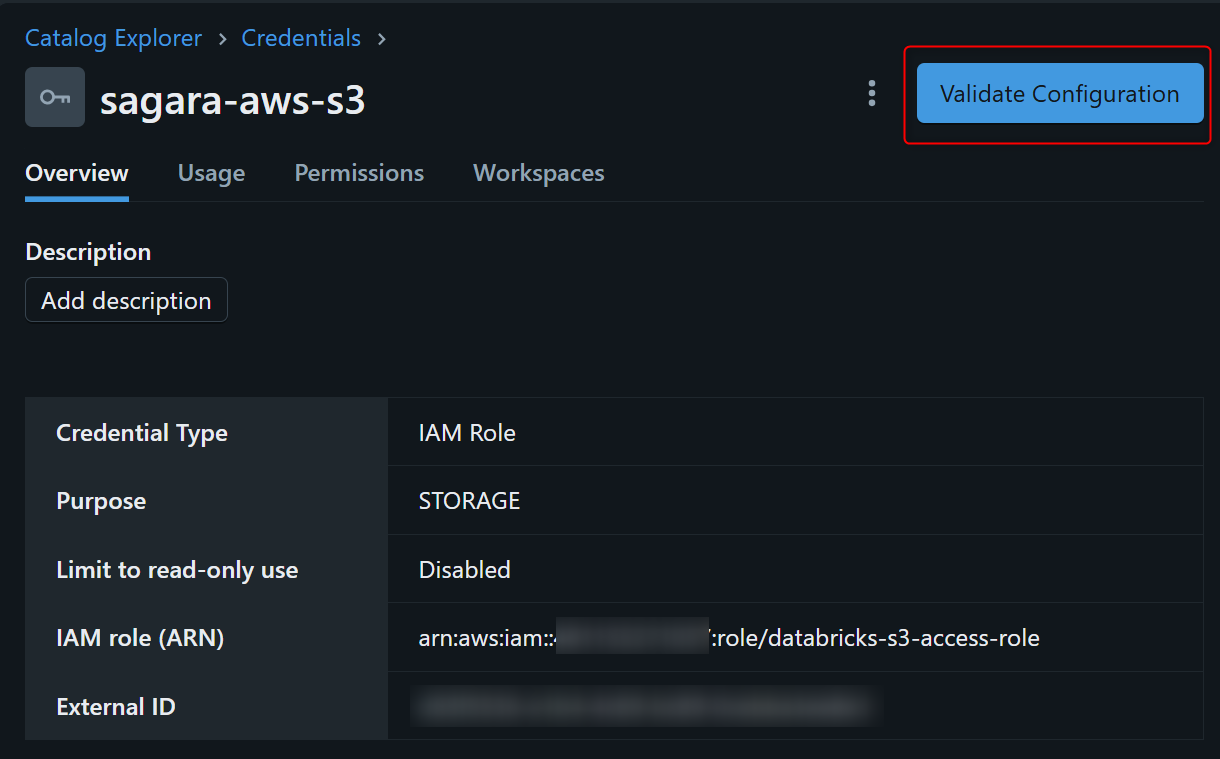
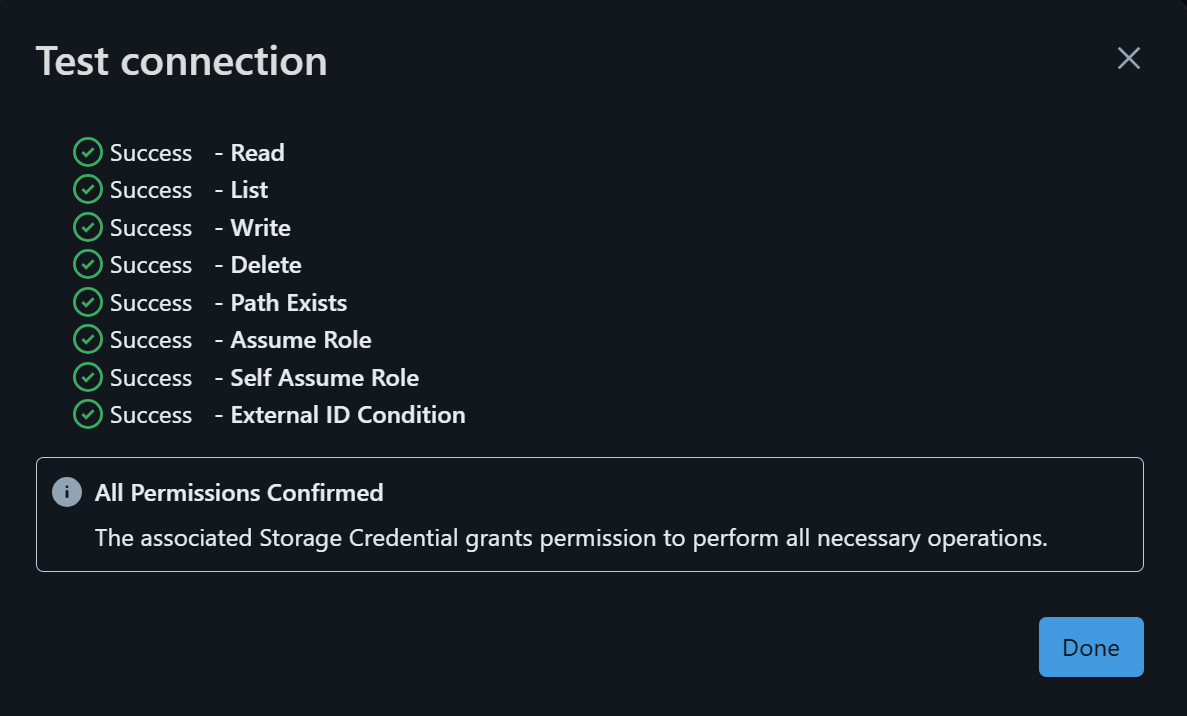
この後にDatabricksの画面に戻り、作成したCredentialの画面右上でValidate Configurationを押すと、下図のように表示されるはずです。こうなっていれば無事に設定できている、という状態となります。
External Locationsの作成
Databricksの画面で、CatalogからAdd dataを押し、Create an external locationを押します。
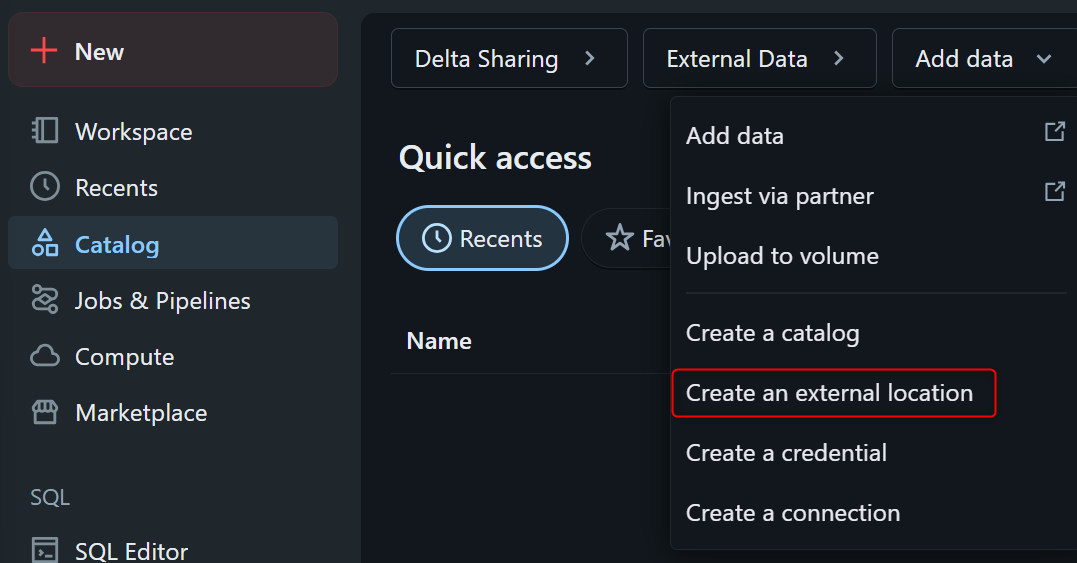
Storage Credentialは先程作成済のため、Manualで進めます。
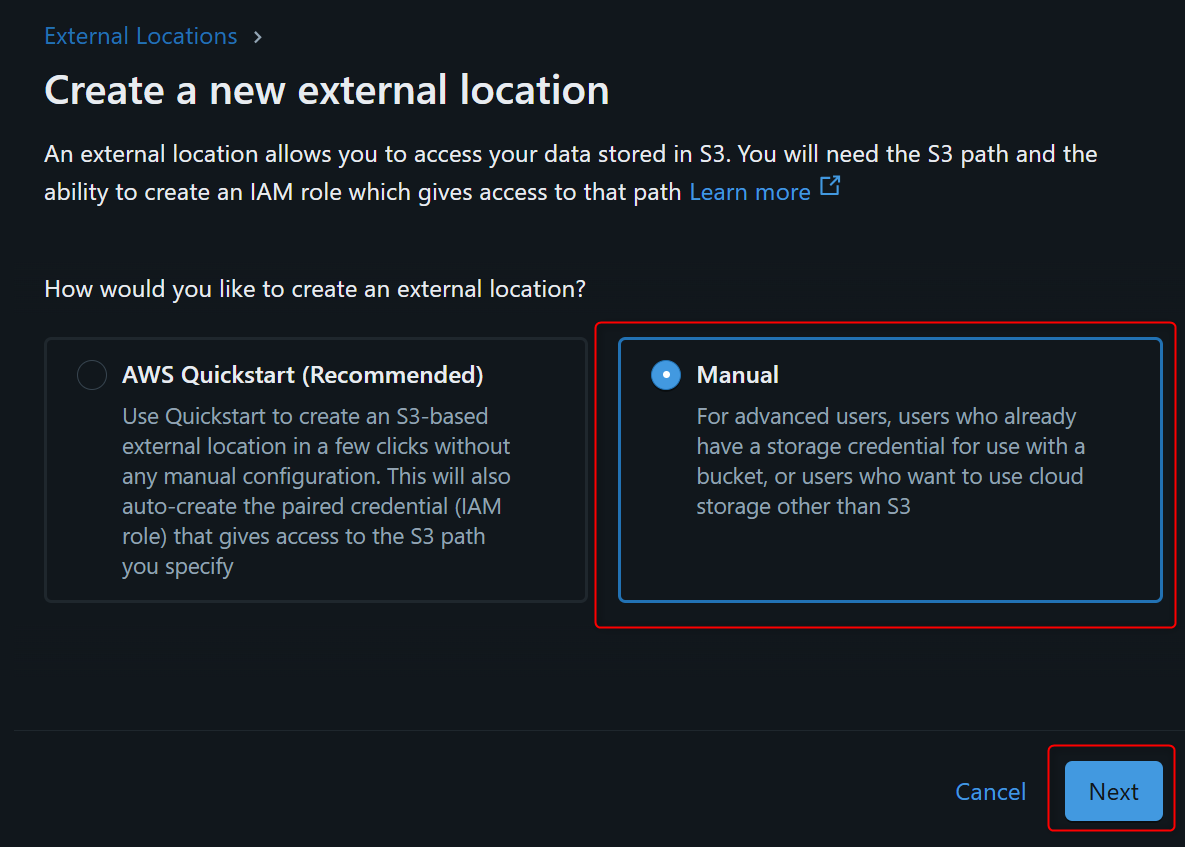
External location nameを入れて、URLは対象のS3バケットのURIを入力し、Storage credentialは先程作成したCredentialを指定します。
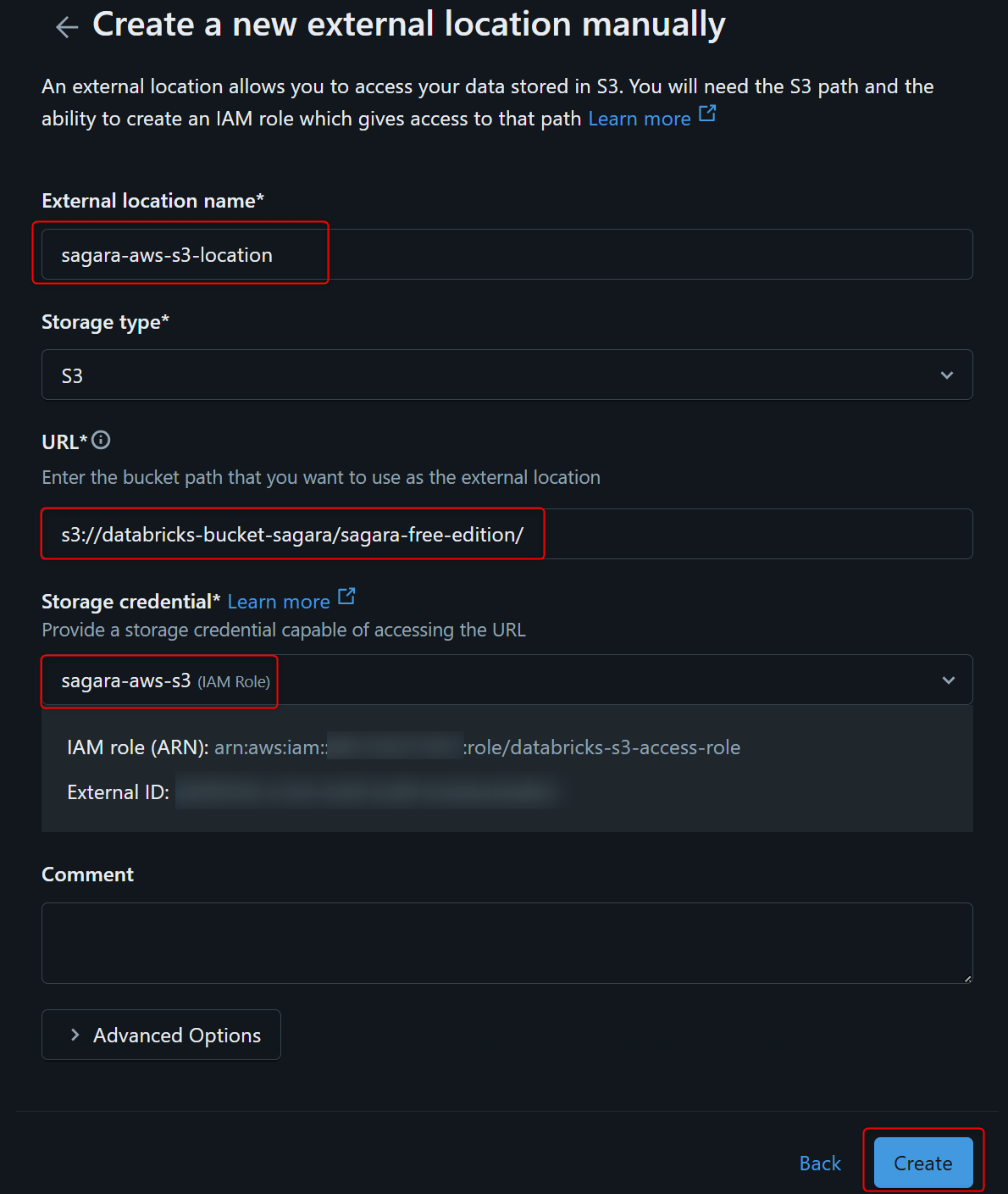
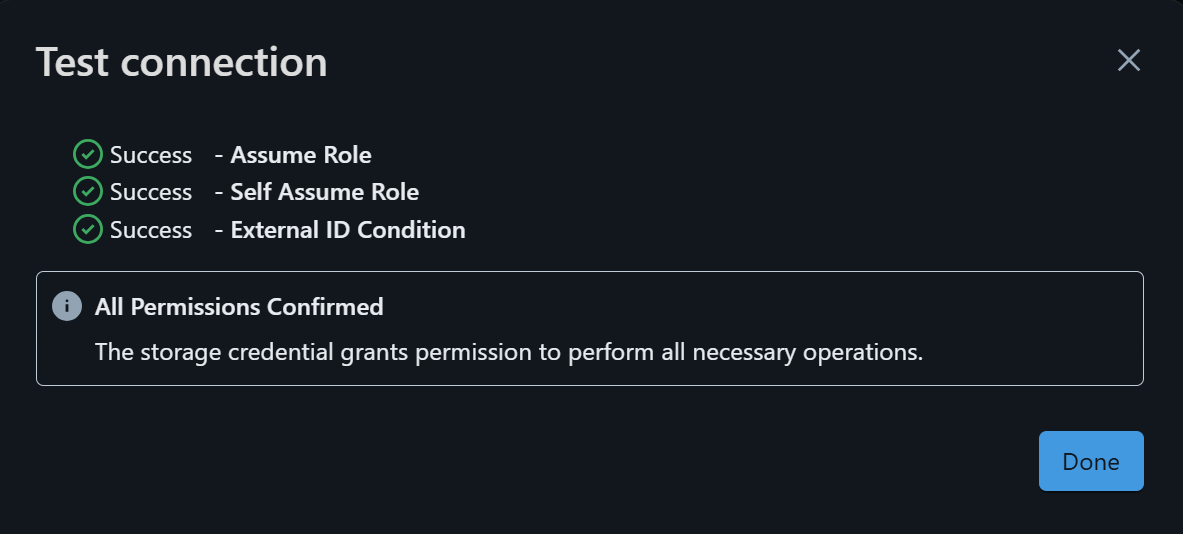
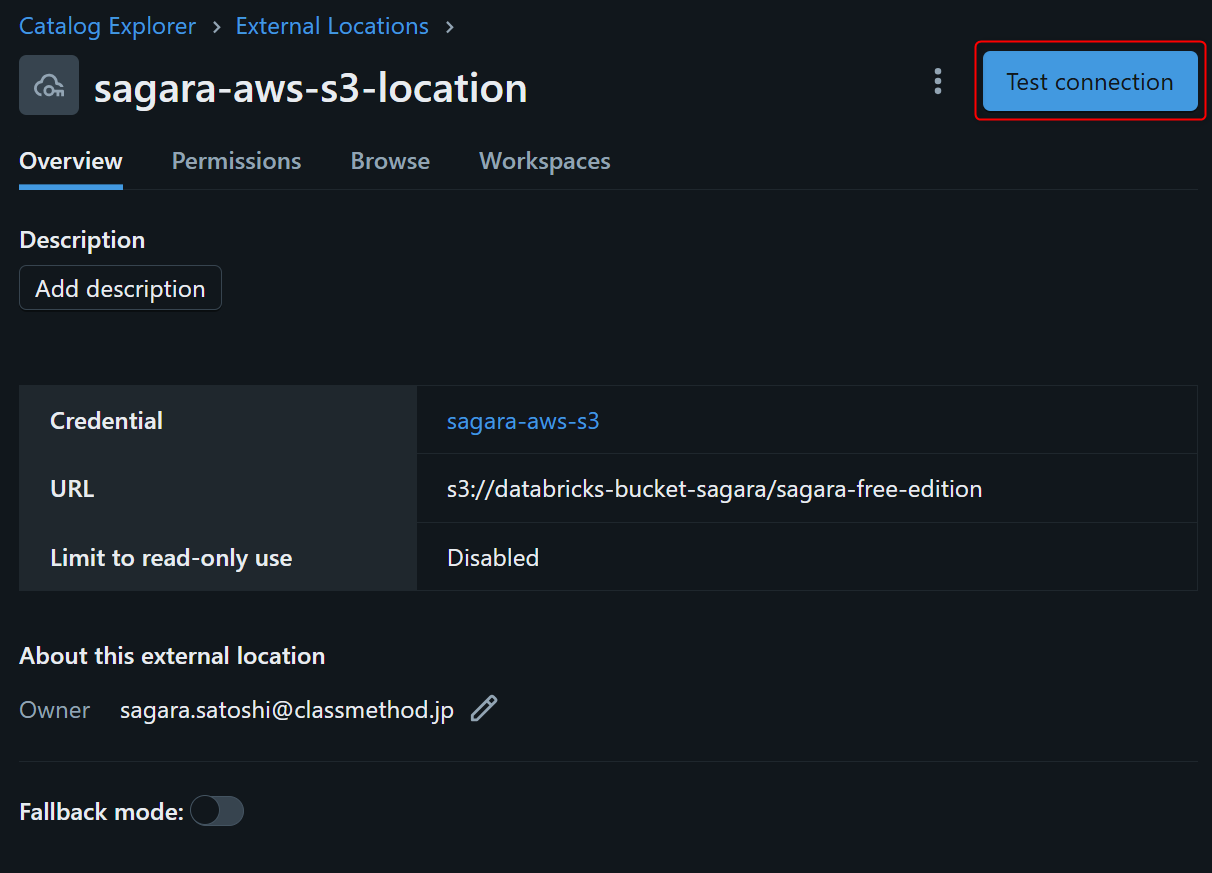
下図の画面に切り替わりますので、右上のTest connectionを押します。その後下図のように表示されれば、ユーザー管理のS3にDatabricks Free Editionから繋がっている状態となります!
外部テーブルの作成・クエリ
外部テーブルを作成し、クエリしてみます。
データの準備
s3://databricks-bucket-sagara/sagara-free-edition/内でrawというフォルダを作成し、以下の内容の東北地方.csvというファイルをアップロードしておきます。
pref_name,population,area_km2 青森県,1237984,9645.64 岩手県,1210534,15275.01 宮城県,2301996,7282.29 秋田県,959502,11637.52 山形県,1068027,9323.15 福島県,1833152,13784.14 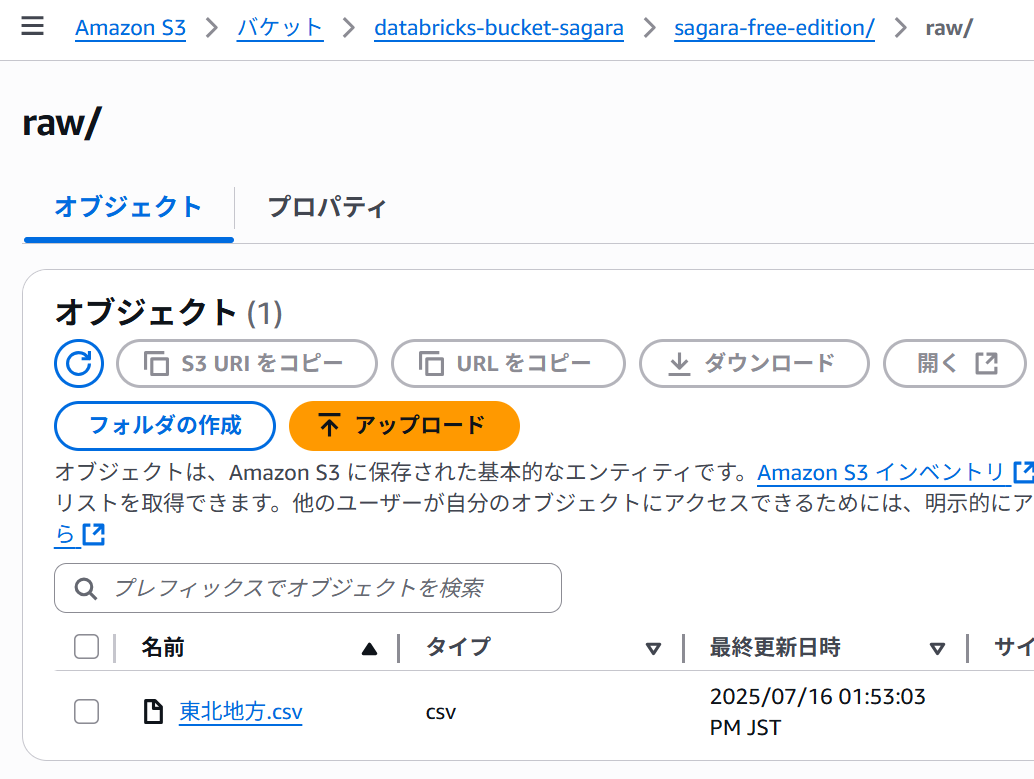
外部テーブルの作成・クエリ
以下のクエリをSQL Editorで実行して、デフォルトのカタログ・スキーマに対して外部テーブルを作成します。
CREATE EXTERNAL TABLE workspace.default.prefectures_jp ( `pref_name` STRING, `population` INT, `area_km2` DOUBLE ) USING CSV OPTIONS ( header "true", delimiter ",", encoding "UTF-8" ) LOCATION "s3://databricks-bucket-sagara/sagara-free-edition/raw/"; この後、作成した外部テーブルに対してクエリを行います。下図のように表示されたので、無事にクエリが出来ました。
SELECT * FROM workspace.default.prefectures_jp; 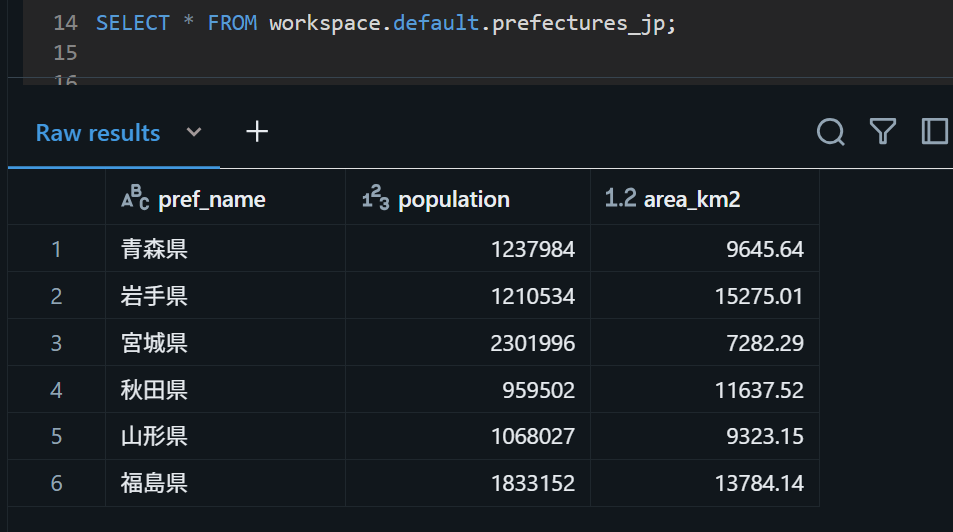
新しくカタログを作成してCOPY INTOでロード
新しくカタログを作成して、COPY INTOでロードすることを試してみます。
データの準備
※先ほどの外部テーブルのときと同じデータを利用します。
s3://databricks-bucket-sagara/sagara-free-edition/内でrawというフォルダを作成し、以下の内容の東北地方.csvというファイルをアップロードしておきます。
pref_name,population,area_km2 青森県,1237984,9645.64 岩手県,1210534,15275.01 宮城県,2301996,7282.29 秋田県,959502,11637.52 山形県,1068027,9323.15 福島県,1833152,13784.14 カタログの作成
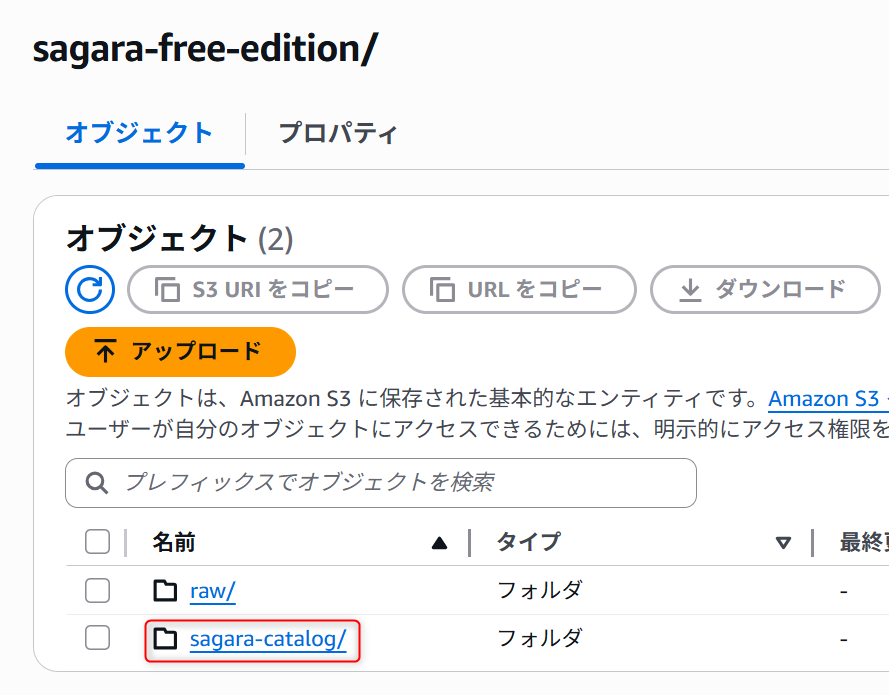
事前に、下図のようにsagara-catalogというフォルダをS3で作成しておきます。※これは任意です。
Databricksの画面で、Catalog⇛Add dataから、Create Catalogを押します。
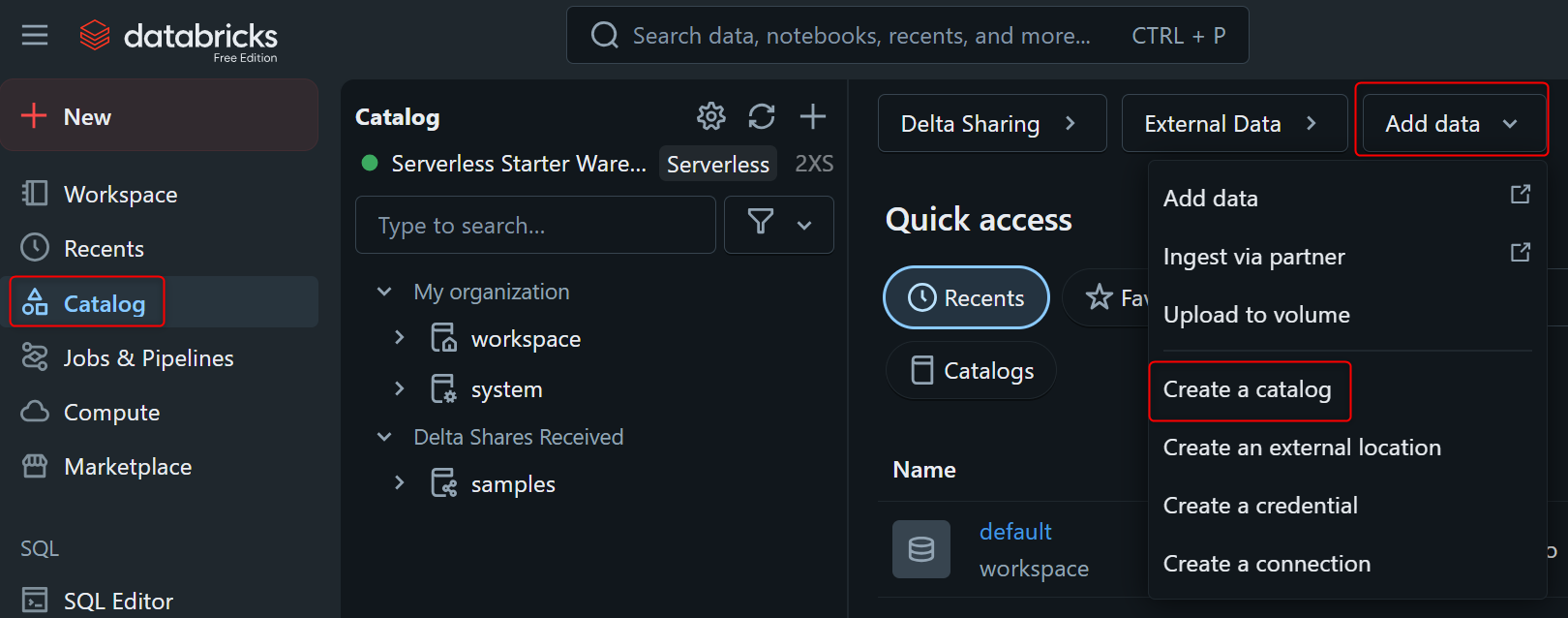
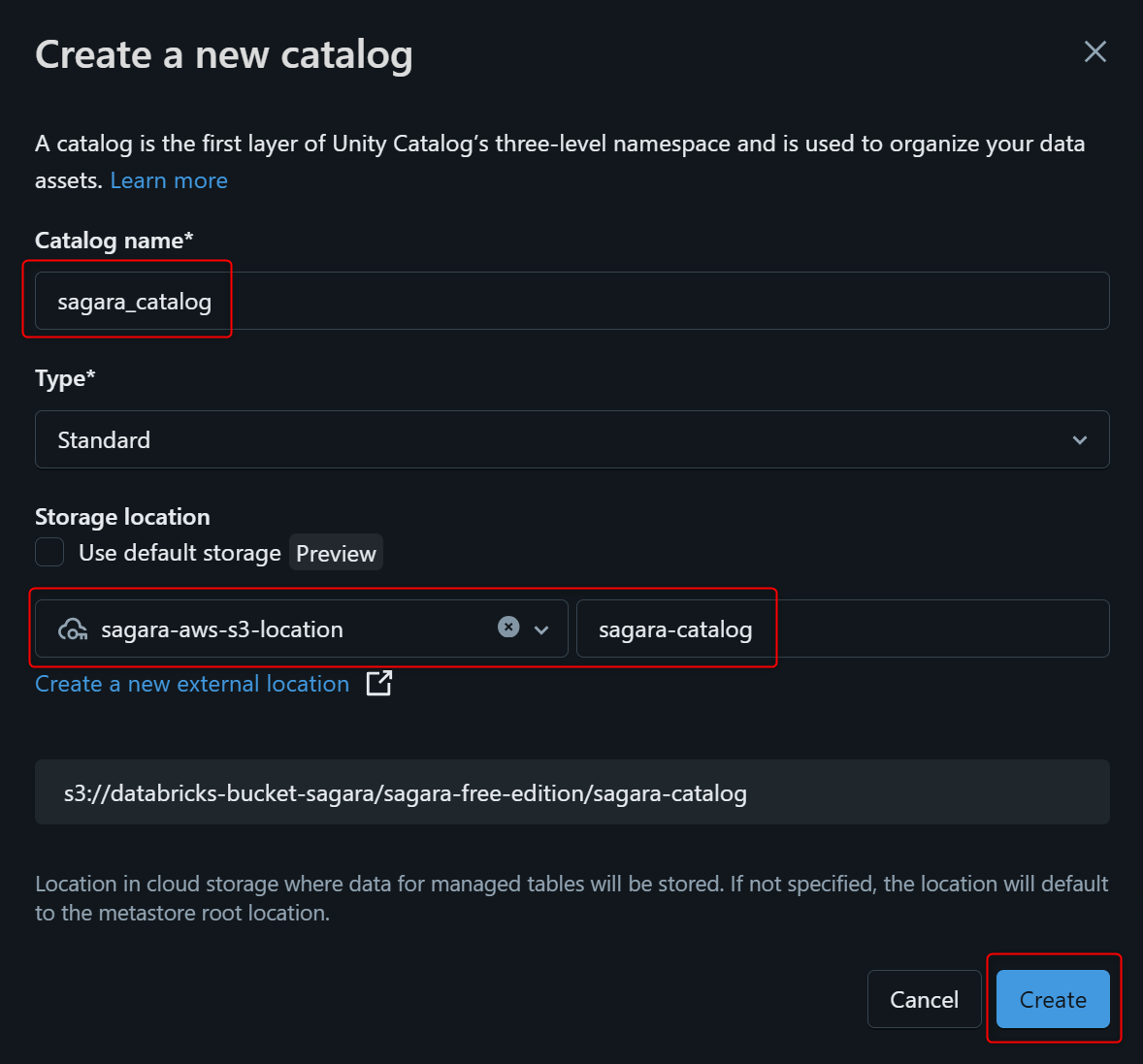
下図のようにStorage locationは作成したものを入力し、Createを押します。
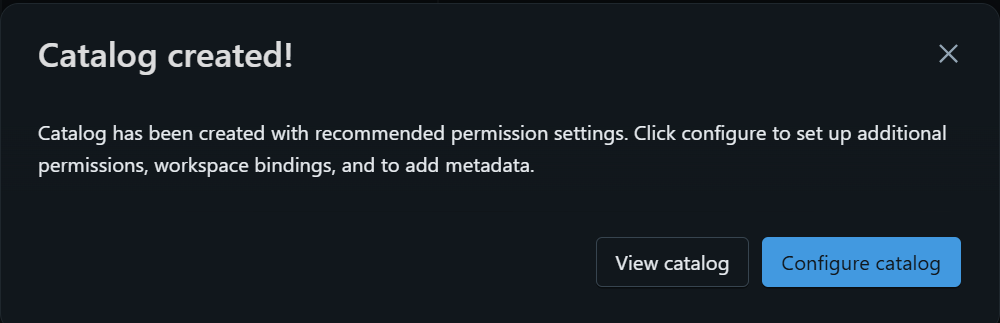
下図のように表示されたら、カタログの作成は完了です。
スキーマ・テーブルを作成しCOPY INTOでロード
以下のクエリをSQL Editorで実行して、作成したカタログのdefaultスキーマに対してテーブルを作成してCOPY INTOでロードをします。
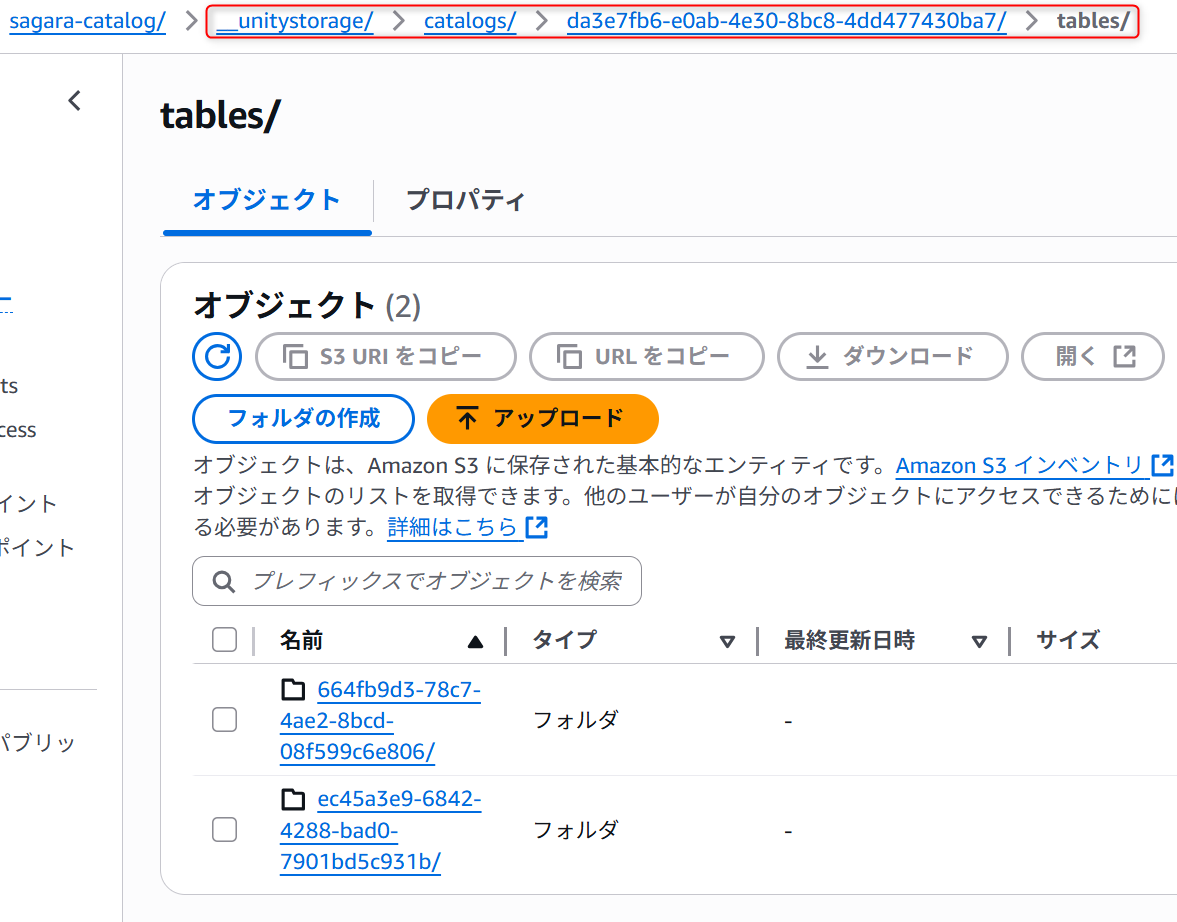
CREATE TABLE sagara_catalog.default.prefectures_jp ( pref_name STRING, population INT, area_km2 DOUBLE ) USING DELTA; COPY INTO sagara_catalog.default.prefectures_jp FROM 's3://databricks-bucket-sagara/sagara-free-edition/raw/' FILEFORMAT = CSV FORMAT_OPTIONS ( 'header' = 'true', 'inferSchema' = 'true', 'delimiter' = ',', 'encoding' = 'UTF-8' ) COPY_OPTIONS ( 'mergeSchema' = 'false' ); この状態で対象のS3を見ると、_unitystorageなどのフォルダが作成されて、末端のフォルダにはlogとparquetが保存されていました。
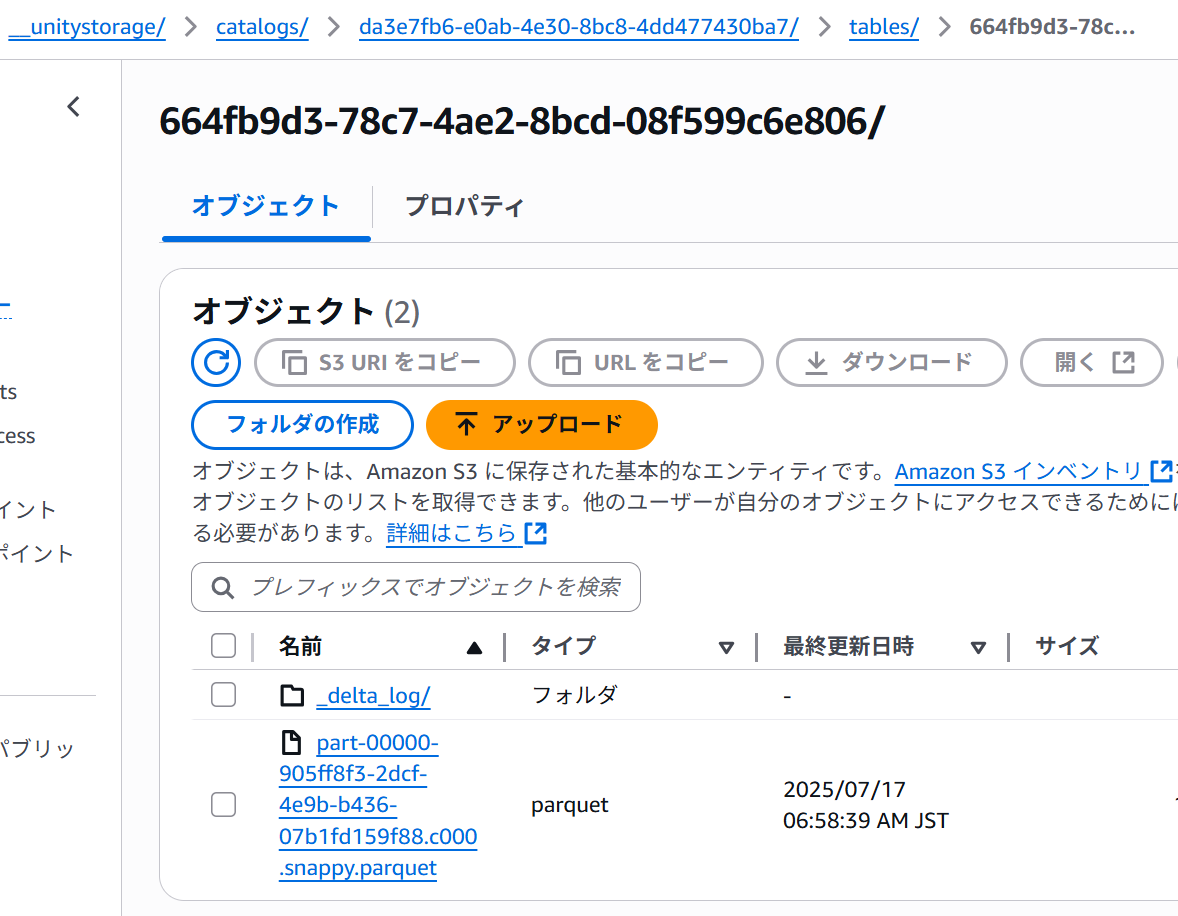
この上で、作成したテーブルに対してクエリを行うと、無事にロードされたデータが確認できました。
SELECT * FROM sagara_catalog.default.prefectures_jp; 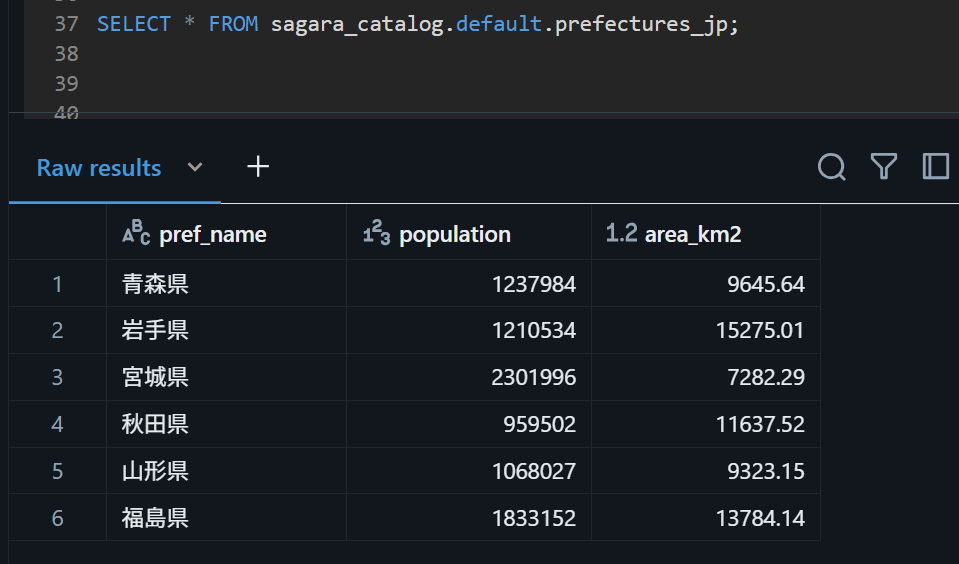
Streaming Tableを作成して自動でデータロード
S3バケットにデータが置かれたらデータロードを指定した時間間隔で自動で行うことができるStreaming Table機能を使ってデータロードを行ってみます。
Streaming Tableについては以下の記事も参考になります。
Streaming Tableの制約事項については以下の公式ドキュメントをご覧ください。
データの準備~カタログ作成
こちらについては、上述の「新しくカタログを作成してCOPY INTOでロード」で作成したものをそのまま利用します。
Streaming Tableの作成
以下のクエリを実行します。(私が実行したときには、XXSサイズのウェアハウスで1分30秒ほどかかりました。)
このクエリではSCHEDULE REFRESH CRONのところで「1分おきにテーブルのリフレッシュを行う」ように設定しています。
CREATE OR REFRESH STREAMING TABLE sagara_catalog.default.prefectures_jp_streaming SCHEDULE REFRESH CRON '0 */1 * ? * *' AT TIME ZONE 'UTC' AS SELECT pref_name, CAST(population AS INT) AS population, CAST(area_km2 AS DOUBLE) AS area_km2 FROM STREAM read_files( 's3://databricks-bucket-sagara/sagara-free-edition/raw/', format => 'csv', header => 'true', delimiter => ',', encoding => 'UTF-8' ); この上でテーブルに対してクエリをすると、対象のS3バケットに元々あったデータがロードされていました。
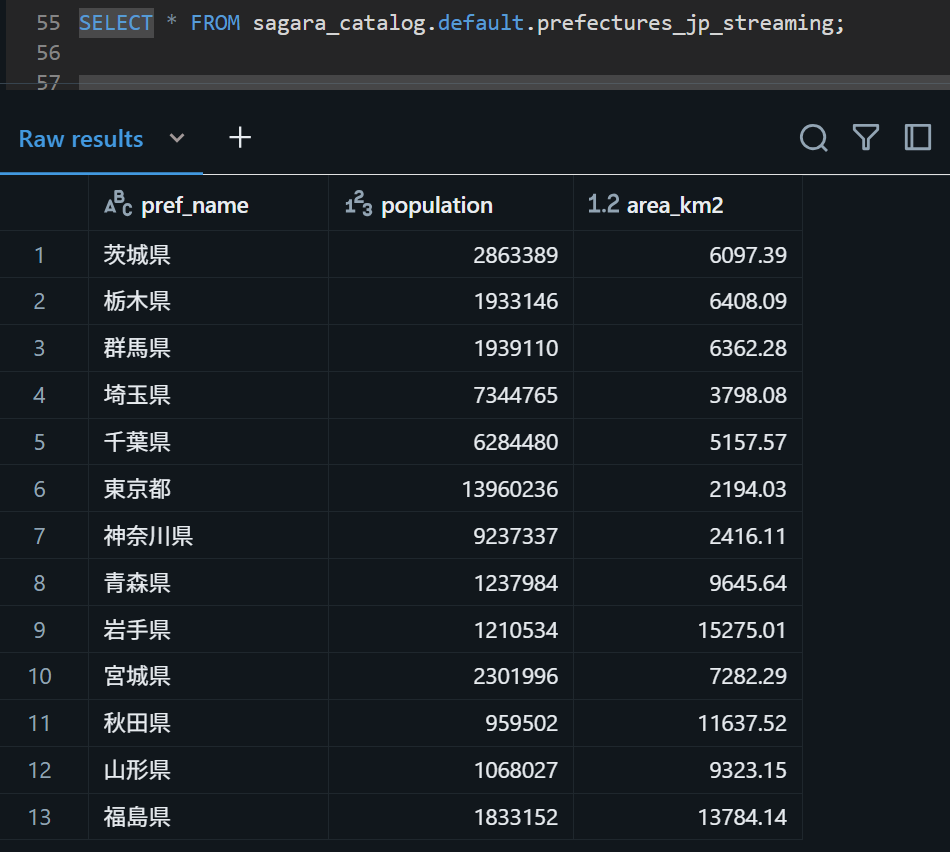
SELECT * FROM sagara_catalog.default.prefectures_jp_streaming; 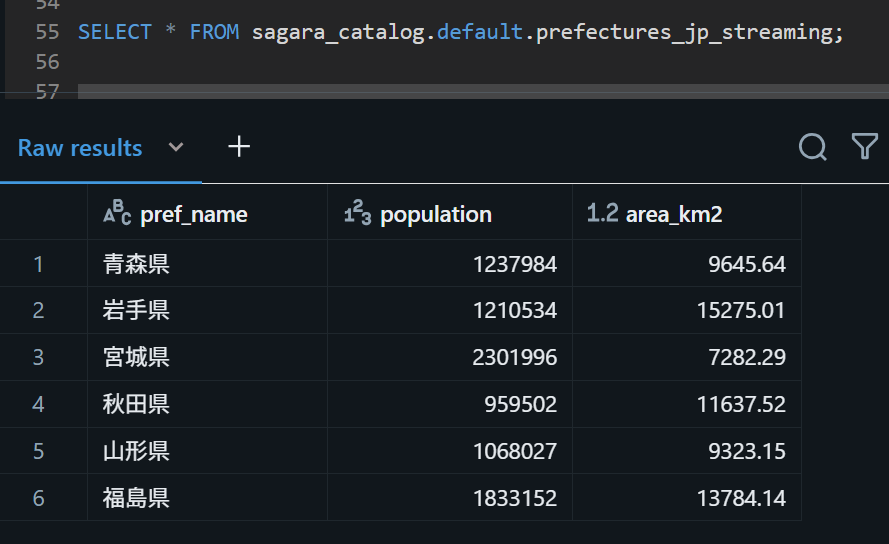
新しいデータを追加してS3バケットにアップロード
1分おきに自動でデータロードが行われるかを確認するため、以下のデータを関東地方.csvとして作成してS3バケットにアップロードします。
pref_name,population,area_km2 茨城県,2863389,6097.39 栃木県,1933146,6408.09 群馬県,1939110,6362.28 埼玉県,7344765,3798.08 千葉県,6284480,5157.57 東京都,13960236,2194.03 神奈川県,9237337,2416.11 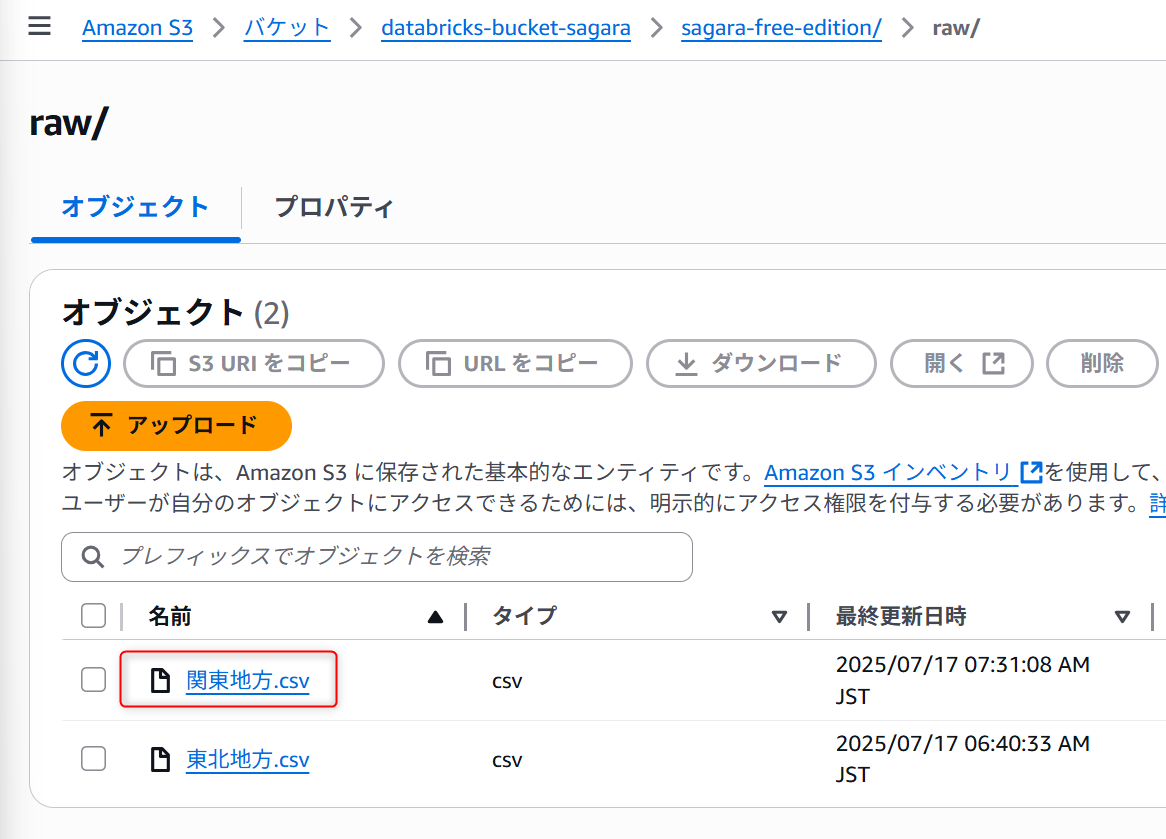
アップロード後、約1分後にテーブルをクエリしてみると、関東地方.csvのデータが無事にロードされていました。
Volumeについて
※この章は2025/7/18に追記した内容となります。
DatabricksではS3など外部ストレージを扱うための機能としてVolumeという機能があります。
このVolumeを使うことで、大きく以下の3つのメリットを得られます。
- Volumeとして設定したS3バケットに対して、DatabricksのワークスペースのUIから、ファイルの確認・追加が可能
/Volumes/<カタログ名>/<スキーマ(データベース)名>/<ボリューム名>/という統一されたパスでアクセス可能となる- Volumeはカタログ⇛スキーマ配下のオブジェクトのため、外部ストレージに保持された情報をUnity Catalogの管理化にすることが可能
今回この記事ではVolumeの設定については触れませんが、以下の記事で詳しく説明しているため、ぜひこちらの記事を併せてご覧ください。
最後に
Databricks Free Editionでユーザー管理のS3に対する外部テーブル作成・Delta Lakeとしてのデータロードを試してみました。
試した中で特に驚いた点としては、「Auto Loader機能も試してみるか」くらいの軽い気持ちでStreaming Tableを試してみたのですが、「こんなに楽に自動でデータロードを行ってくれるテーブルが作れていいの…?」という衝撃がありましたねw










