Latest Blog Posts
#PostgresMarathon 2-009: Prepared statements and partitioned table lock explosion, part 1
Posted by Nikolay Samokhvalov in Postgres.ai on 2025-10-28 at 05:00
In #PostgresMarathon 2-008, we discovered that prepared statements can dramatically reduce LWLock:LockManager contention by switching from planner locks (which lock everything) to executor locks (which lock only what's actually used). Starting with execution 7, we saw locks drop from 6 (table + 5 indexes) to just 1 (table only).
There we tested only a simple, unpartitioned table. What happens if the table is partitioned?
The following was tested on Postgres 18.0 with default settings:
-
enable_partition_pruning = on -
plan_cache_mode = auto
Postgres behavior in this field might change in the future — there are WIP patches optimizing performance.
Let's create a simple partitioned table with multiple partitions:
create table events (
event_id bigint,
event_time timestamptz,
event_data text
) partition by range (event_time);
-- Create 12 monthly partitions
do $$
declare
i int;
start_date date;
end_date date;
begin
for i in 0..11 loop
start_date := '2024-01-01'::date + make_interval(months => i);
end_date := start_date + interval '1 month';
execute format(
'create table events_%s partition of events for values from (%L) to (%L)',
to_char(start_date, 'YYYY_MM'),
start_date,
end_date
);
end loop;
end $$;
Result:
test=# \d+ events
Partitioned table "public.events"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
------------+--------------------------+-----------+----------+---------+----------+-------------+--------------+-------------
event_id | bigint | | | | plain | | |
event_time | timestamp with time zone | | | | plain | | |
event_data | text | | | | extended | | |
Partition key: RANGE (event_The Future of CYBERTEC and PostgreSQL
Posted by Hans-Juergen Schoenig in Cybertec on 2025-10-28 at 05:00
For this second entry into our blog feature to celebrate 25 years of CYBERTEC, our CEO gave some interesting insights into what he expects of the future - for the company as well as PostgreSQL as a whole.
CYBERTEC in another 25 years
Interviewer: Let's talk about the future. Where do you think you see CYBERTEC in another 25 years?
Hans: If I would make a prediction, it would be wrong for sure, but certainly… larger. Certainly, if this is even possible at this point, more international, and definitely the same technology, I would say, but with more ecosystem around it.
More locations, hopefully not more processes. Hopefully similar vibes and hopefully in the same place - physically, I mean.
Interviewer: Alright, so moving away from CYBERTEC a little, where do you see yourself personally in 25 years?
Hans: I don't know. Hopefully alive. [laughs]
Interviewer: That's a great goal to have. [laughs]
Hans: In 25 years I’m 72. I mean, hopefully alive, right?
Interviewer: Yeah.
Hans: I don't know. Wouldn't it be damn boring if you would know?
Interviewer: That's true.
Hans: Why would you wanna know? I mean, I believe that if you wanna know exactly what's gonna happen in 20 years, you have to become a bureaucrat. Otherwise, you don't want to know, I believe. I believe you don't. Even if everything is good, you don't wanna know because that would destroy the fun, I believe.
Interviewer: Okay. Then, looking at a closer future, what would you still like to achieve?
Hans: It's not about achievement. It's not about achievement because achievement is an ego thing. “If I do this, I will be more happy,” whatever. No, achievement, as in big philosophy, I'm not sure if it's about achievement, it's about doing the right thing. Is doing the right thing an achievement? I don’t know, that's quite philosophical, I would say.
But doing the right thing, I don't think that's an achievement. That's something you should do, you know? It’s not about achievements, like: “I ne
[...]Explaining IPC:SyncRep – Postgres Sync Replication is Not Actually Sync Replication
Posted by Jeremy Schneider on 2025-10-27 at 23:12
Postgres database-level “synchronous replication” does not actually mean the replication is synchronous. It’s a bit of a lie really. The replication is actually – always – asynchronous. What it actually means is “when the client issues a COMMIT then pause until we know the transaction is replicated.” In fact the primary writer database doesn’t need to wait for the replicas to catch up UNTIL the client issues a COMMIT …and even then it’s only a single individual connection which waits. This has many interesting properties.
One benefit is throughput and performance. It means that much of the database workload is actually asynchronous – which tends to work pretty well. The replication stream operates in parallel to the primary workload.
But an interesting drawback is that you can get into situation where the primary can speed ahead of the replica quite a bit before that COMMIT statement hits and then the specific client who issued the COMMIT will need to sit and wait for awhile. It also means that bulk operations like pg_repack or VACUUM FULL or REFRESH MATERIALIZED VIEW or COPY do not have anything to throttle them. They will generate WAL basically as fast as it can be written to the local disk. In the mean time, everybody else on the system will see their COMMIT operations start to exhibit dramatic hangs and will see apparent sudden performance drops – while they wait for their commit record to eventually get replicated by a lagging replication stream. It can be non-obvious that this performance degradation is completely unrelated to the queries that appear to be slowing down. This is the infamous IPC:SyncRep wait event.
Another drawback: as the replication stream begins to lag, the amount of disk needed for WAL storage balloons. This makes it challenging to predict the required size of a dedicated volume for WAL. A system might seem to have lots of headroom, and then a pg_repack on a large table might fill the WAL volume without warning.
This is a bit different from storage-level synchronous re
[...]Troubleshooting PostgreSQL Logical Replication, Working with LSNs
Posted by Robert Bernier in Percona on 2025-10-27 at 14:10
 PostgreSQL logical replication adoption is becoming more popular as significant advances continue to expand its range of capabilities. While quite a few blogs have described features, there seems to be a lack of simple and straightforward advice on restoring stalled replication. This blog demonstrates an extremely powerful approach to resolving replication problems using the Log […]
PostgreSQL logical replication adoption is becoming more popular as significant advances continue to expand its range of capabilities. While quite a few blogs have described features, there seems to be a lack of simple and straightforward advice on restoring stalled replication. This blog demonstrates an extremely powerful approach to resolving replication problems using the Log […] Slonik on the Catwalk: PGConf.EU 2025 Recap
Posted by Mayur B. on 2025-10-27 at 11:53

I volunteered as a room host and Slonik guide.
Best gig: posing our elephant. The photographer had runway-level ideas. Slonik delivered every single time.

Community Day ~ people > hype
- PostgreSQL & AI Summit: I sat on the panel and played “Team Human” vs Skynet (As advised by John Connor in the future).
postgresql.eu - “Establishing the PostgreSQL standard: What’s Postgres compatible?”
Half-day workshop, lot of brain storming and discussion split into groups then presenting your group’s conclusion on what makes postgres derivatives compatible with community postgres. We spun up a Telegram group to keep building the rubric post-conference. postgresql.eu

Coffee with CYBERTEC (meeting Laurenz Albe)
- Picked the “Coffee with CYBERTEC” option to meet Laurenz Albe, the most prolific Stack Overflow answerer.
- We traded notes on most popular features to adopt from other databases, their feasibility, and why Postgres avoided them historically.
I left with a starting map for contributing to core.
Talks I caught (and why they stuck)
“Don’t do that!” — Laurenz Albe
A rapid-fire list of Postgres anti-patterns. Simple, blunt, useful from the most beloved speaker of the conference. (postgresql.eu)
Parsing Postgres logs the non-pgBadger way — Kaarel Moppel
Meet pgweasel. Lean CLI. Fast. Cloud-friendly. For prod support, less noise beats glossy graphs. I’m convinced. (postgresql.eu)
https://github.com/kmoppel/pgweasel
Improved freezing in VACUUM — Melanie Plageman
Cleaner anti-wraparound story. Scan all-visible (not all-frozen) pages early; fewer emergency freezes later. Sensible, much nee
Returning Multiple Rows with Postgres Extensions
Posted by Shaun Thomas in pgEdge on 2025-10-27 at 05:09
Creating an extension for Postgres is an experience worthy of immense satisfaction. You get to contribute to the extension ecosystem while providing valuable functionality to other Postgres users. It’s also an incredibly challenging exercise in many ways, so we’re glad you’ve returned to learn a bit more about building Postgres extensions.In the previous article in this series, we discussed creating an extension to block DDL. That sample extension was admittedly fairly trivial, in that it only added a single configuration parameter and utilized one callback hook. A more complete extension would provide a function or view to Postgres so users could interact with the extension itself. So let’s do just that!
Deciding on Data
Once again we’re faced with choosing a topic for the extension. Users will sometimes ask the question: how much memory is Postgres using? Using various tools like top or ps will show a fairly inaccurate picture of this, limiting results to opaque fields like VIRT, RES, SHR, PSS, RSS, and others. Some are aggregates, others include Postgres shared buffers, and none really describe how memory is being used.Luckily on Linux systems, there’s an incredibly handy /proc filesystem that provides a plethora of information about several process metrics, including memory. The smaps file in particular reports several process-specific memory categories, and does so on a per-allocation basis. What if we could parse that file for every Postgres backend process and return output in a table? Admins could then see exactly which user sessions or worker processes are using the most memory and why, rather than an imprecise virtual or resident memory summary.Sounds interesting!Starting the Extension
As with our previous extension, we need to bootstrap the project with a few files. Start with creating the project folder:And create a file with these contents:As before, we just need to name the extension, give it a version, and provide an installation path for the resulting library file. Nothing surprising [...]Contributions for week 43, 2025
Posted by Cornelia Biacsics in postgres-contrib.org on 2025-10-26 at 20:20
In October 2025, PostgreSQL Conference Europe brought the community together in Riga, Latvia from the 21st to the 24th.
Organizers
- Andreas Scherbaum
- Chris Ellis
- Dave Page
- Ilya Kosmodemiansky
- Jimmy Angelakos
- Karen Jex
- Magnus Hagander
- Marc Linster
- Samed Yildirim
- Valeria Kaplan
Talk selection committee
- Karen Jex (non voting chair)
Application Developer and Community Subcommittee
- Dian Fay
- Hari P Kiran
- Johannes Paul
- Kai Wagner
Postgres Internals and DBA Subcommittee
- Anastasia Lubennikova
- Dirk Krautschick
- Samed Yildirim
- Teresa Lopes
Code of Conduct Committee
- Floor Drees
- Pavlo Golub
- Celeste Horgan
Community Events Day
Extensions Showcase - Organizers
- Alastair Turner
- David Wheeler
- Floor Drees
- Yurii Rashkovskii
PostgreSQL on Kubernetes Summit - Organizers
- Floor Drees
- Gülçin Yıldırım Jelinek
Speakers
- Gülçin Yıldırım Jelínek
- Floor Drees
- Oleksii Kliukin
- Polina Bungina
- Thomas Boussekey
- Pavel Lukasenko
- Danish Khan
- Esther Minano
- Gabriele Bartolini
- Andrew Farries
- Jonathan Gonzalez V.
- Jonathan Battiato
Establishing the PostgreSQL standard: What's Postgres compatible? - Organizers
- Jimmy Angelakos
- Henrietta Dombrovskaya
- Boriss Mejías
Community Summit – PGConf EU Edition - Organizers
- Teresa Giacomini
- Andreas Scherbaum
Crafty Slonik - Organized by
- Chris Ellis
PostgreSQL & AI Summit - Organizers
- Gülçin Yıldırım Jelinek
- Ellyne Phneah
- Torsten Steinbach
Speakers
- Ellyne Phneah
- Marc Linster
- Bruce Momjian
- Torsten Steinbach
- Gulcin Yildirim Jelinek
- Miguel Toscano
- Luigi Nardi
- Bertrand Hartwig-Peillon
- Daniel Krefl
- Adrien Obernesser
- Jimmy Angelakos
- Mohsin Ejaz
- Gleb Otochkin
- Erik Hellsten
Panel Discussion – Moderator: Torsten Steinbach, Panelist: Gul
[...]Temporal Joins
Posted by Christopher Winslett in Crunchy Data on 2025-10-24 at 13:00
My first thought seeing a temporal join in 2008 was, “Why is this query so complex?” The company I was at relied heavily on database queries, as it was a CRM and student success tracking system for colleges and universities. The query returned a filtered list of users and their last associated record from a second table. The hard part about the query isn’t returning the last timestamp or even performing joins, it’s returning only their last associated record from a second table.
Back in 2008, we didn’t have window functions or CTEs, so the query algorithm was a series of nested tables that looked like this:
SELECT * FROM users, ( -- find the record for the last second_table by created_at and user_id SELECT second_table.* FROM second_table, ( -- find the last second_table created_at per user_id SELECT user_id, max(created_at) AS created_at FROM second_table GROUP BY 1 ) AS last_second_table_at WHERE last_second_table_at.user_id = second_table.user_id AND second_table.created_at = last_second_table_at.created_at ) AS last_second_table WHERE users.id = last_second_table.user_id; See the Sample Code section below for the schema and data to run these queries.
But, even that query was wrong because the second table may have records with duplicate created_at values. That was the source of a bug back in 2008 that resulted in duplicate rows being listed.
Obviously, we weren't using Postgres at the time because there has always been a simpler way to do this in Postgres using DISTINCT ON:
SELECT DISTINCT ON (u.id) u.id, u.name, s.created_at AS last_action_time, s.action_type FROM users u JOIN second_table s ON u.id = s.user_idLoading The Titanic Passenger Data Into PostgreSQL With DBeaver Part 2
Posted by Dave Stokes on 2025-10-22 at 12:08
In the last edition of this blog, the passenger list data from the HMS Titanic was loaded into a preliminary database. Now it is time to refine.
I am using DBeaver Enterprise 25.2.0. PostgreSQL 18, and Github Copilot with Gpt-4.
Prompt: Any recommendations on improving this table for storage efficiency? This prompt was entered into the DBeaver AI Assistant.
To improve the storage efficiency of the "titanic" table, we can consider the following recommendations:
### 1. **Optimize Data Types**
- **"PassengerId"**: If the number of passengers is not expected to exceed 2,147,483,647, the `int4` type is fine. However, if the range is smaller (e.g., less than 32,767), you could use `int2` (smallint) to save space.
- **"Survived"**: Since this is likely a binary value (0 or 1), you can use `boolean` instead of `int4`.
- **"Pclass"**: If the class is limited to 1, 2, or 3, you can use `int2` (smallint) instead of `int4`.
- **"Sex"**: If this column only contains "male" and "female", consider using an `enum` type or a `char(1)` ('M' or 'F') to save space.
- **"Age"**: If precision beyond one decimal place is not required, consider reducing the precision or using `numeric` with a defined scale.
- **"SibSp" and "Parch"**: If these values are small integers (e.g., number of siblings/spouses or parents/children), you can use `int2` (smallint).
- **"Ticket"**: If ticket numbers are of fixed length, consider using `char(n)` instead of `varchar`.
- **"Fare"**: If precision beyond two decimal places is not required, consider using `numeric` with a defined scale (e.g., `numeric(10,2)`).
- **"Cabin"**: If cabin identifiers are of fixed length, consider using `char(n)` instead of `varchar`.
- **"Embarked"**: If this column only contains a small set of values (e.g., 'C', 'Q', 'S'), consider using an `enum` type or `char(1)`.
Comment: This is what I was looking for. Saving sp
Say Hello to OIDC in PostgreSQL 18!
Posted by Jan Wieremjewicz in Percona on 2025-10-22 at 11:00
If you’ve ever wondered how to set up OpenID Connect (OIDC) authentication in PostgreSQL, the wait is almost over.
We’ve spent some time exploring what it would take to make OIDC easier and more reliable to use with PostgreSQL. And now, we’re happy to share the first results of that work.
Why OIDC, and why now?
We’ve spoken to some of our customers and noticed a trend of moving away from LDAP to OIDC. Our MongoDB product is already providing OIDC integration and the team working on PostgreSQL products saw an opportunity coming with PostgreSQL 18.
Waiting for PostgreSQL 19 – Support COPY TO for partitioned tables.
Posted by Hubert 'depesz' Lubaczewski on 2025-10-22 at 10:05
Understanding the Execution Plan of a Hash Join
Posted by Chao Li in Highgo Software on 2025-10-22 at 08:26
A hash join is one of the most common join methods used by PostgreSQL and other relational databases. It works by building a hash table from the smaller input (called the build side) and then probing it with rows from the larger input (the probe side) to find matching join keys.
Hash joins are especially efficient for large, unsorted datasets—particularly when there are no useful indexes on the join columns.
This post uses a concrete example to explain how a hash join works. The example is run on PostgreSQL 18.
Preparing the Data
-- Create tables CREATE TABLE regions ( id SERIAL PRIMARY KEY, region_name TEXT ); CREATE TABLE customers ( id SERIAL PRIMARY KEY, name TEXT, region_id INT ); -- Insert sample data INSERT INTO regions (region_name) SELECT 'region_' || g FROM generate_series(1, 10) g; INSERT INTO customers (name) SELECT 'customer_' || g FROM generate_series(1, 100000) g; -- Assign each customer a region UPDATE customers SET region_id = (random() * 9)::int + 1;The Query
EXPLAIN SELECT c.id, c.name, r.region_name FROM regions r LEFT JOIN customers c ON c.region_id = r.id;Output:
Hash Right Join (cost=38.58..2575.95 rows=100000 width=50) Hash Cond: (c.region_id = r.id) -> Seq Scan on customers c (cost=0.00..2274.00 rows=100000 width=22) -> Hash (cost=22.70..22.70 rows=1270 width=36) -> Seq Scan on regions r (cost=0.00..22.70 rows=1270 width=36) At first glance, this seems weird: the SQL uses LEFT JOIN, but the plan shows RIGHT JOIN. Why does that happen? This post is going to explain the puzzle.
Understanding JOIN Types
Let’s assume simplified data:
customers
| id | name | region_id |
|---|---|---|
| 1 | Alice | 1 |
| 2 | Bob | 2 |
Contributions for week 42, 2025
Posted by Pavlo Golub in postgres-contrib.org on 2025-10-21 at 13:13
Belgium Meetup: Tuesday, 14 October 2025 - organized by Boriss Mejias & Stefan Fercot
Speakers:
- Niradj Selvam
- Stefan Fercot
Contributions for week 41, 2025
Posted by Pavlo Golub in postgres-contrib.org on 2025-10-21 at 13:12
Barcelona PostgreSQL User Group met on Tuesday, Oct 7, organized by Dave Pitts & Lauro Ojeda
Speakers - Dave Pitts - Lauro Ojeda
Ellyne Phneah released two books: * The Social Code: Building a PostgreSQL Community Wired for Belonging * Decode PostgreSQL: Understanding the World's Most Powerful Open-Source Database Without Writing Code
Benefits of a DESCending index
Posted by Laurenz Albe in Cybertec on 2025-10-21 at 06:00

© Tobi Albe 2025
PostgreSQL can scan B-tree indexes in both directions. That means that there is little need to create a index in descending order (one created with the DESC clause). However, there are some cases where you need a descending index. There are also some corner cases where a descending index performs better than an ascending one. Follow me to explore use cases for the DESC clause!
Mixed ORDER BY clauses
This is the obvious use case for a descending index. There is a reason why CREATE INDEX offers the same clauses as ORDER BY: if you want a B-tree index to support an ORDER BY clause, its sorting order must match the ORDER BY clause precisely. So, to support a query like
SELECT col2 FROM tab ORDER BY col1 DESC NULLS LAST;
you need to create an index like
CREATE INDEX tab_col1_desc_idx ON tab (col1 DESC NULLS LAST);
But since PostgreSQL can scan indexes in both directions, the following index will also work:
CREATE INDEX tab_col1_idx ON tab (col1 NULLS FIRST);
However, you cannot avoid the DESC clause if you want to support an ORDER BY clause with both ascending and descending columns:
SELECT col2 FROM tab ORDER BY col1 DESC, col2 NULLS LAST;
In a previous article, I wrote some more about mixed ORDER BY clauses in the context of keyset pagination. There, you can find some more creative ideas for using descending indexes.
Descending indexes for space efficiency
This is a somewhat more exotic use case. I'll demonstrate it with the following table:
CREATE UNLOGGED TABLE large( id bigint NOT NULL ); CREATE INDEX large_id_idx ON large(id); CREATE INDEX large_id_desc_idx ON large (id DESC);
One of these two indexes is clearly redundant. But look what happens if I INSERT rows in descending order:
INSERT INTO large (id) SELECT * FROM generate_series(10000000, 1, -1); SELECT ind AS index_name, pg_size_pretty(pg_relation_size(ind)) AS index_size FROM (VALUES ('large_id_idx'::regclass), ('large_id_desc_idx'::regclass)) AS i(ind); index_na[...] Postgres in Kubernetes: the commands every DBA should know
Posted by Gabriele Bartolini in EDB on 2025-10-21 at 05:18
For many Postgres DBAs, Kubernetes feels like a new, complex world. But what if your existing skills were the key to unlocking it? This article demystifies cloud-native Postgres by revealing a first handful of kubectl and kubectl cnpg commands that act as your direct translator. I’ll move past the intimidating YAML to focus on the practical, imperative commands you’ll actually use to troubleshoot, inspect, and even perform a production switchover. You’ll see how your core DBA work maps directly to this new environment, helping you build the confidence to take the next step into the cloud-native world.
PostGIS Performance: pg_stat_statements and Postgres tuning
Posted by Paul Ramsey in Crunchy Data on 2025-10-20 at 13:00
In this series, we talk about the many different ways you can speed up PostGIS. Today let’s talk about looking across the queries with pg_stat_statements and some basic tuning.
Showing Postgres query times with pg_stat_statements
A reasonable question to ask, if you are managing a system with variable performance is: “what queries on my system are running slowly?”
Fortunately, PostgreSQL includes an extension called “pg_stat_statements” that tracks query performance over time and maintains a list of high cost queries.
CREATE EXTENSION pg_stat_statements; Now you will have to leave your database running for a while, so the extension can gather up data about the kind of queries that are run on your database.
Once it has been running for a while, you have a whole table – pg_stat_statements – that collects your query statistics. You can query it directly with SELECT * or you can write individual queries to find the slowest queries, the longest running ones, and so on.
Here is an example of the longest running 10 queries ranked by duration.
SELECT total_exec_time, mean_exec_time, calls, rows, query FROM pg_stat_statements WHERE calls > 0 ORDER BY mean_exec_time DESC LIMIT 10; While “pg_stat_statements” is good at finding individual queries to tune, and the most frequent cause of slow queries is just inefficient SQL or a need for indexing - see the first post in the series.
Occasionally performance issues do crop up at the system level. The most frequent culprit is memory pressure. PostgreSQL ships with conservative default settings for memory usage, and some workloads benefit from more memory.
Shared buffers
A database server looks like an infinite, accessible, reliable bucket of data. In fact, the server orchestrates data between the disk – which is permanent and slow – and the random access memory – which is volatile and fast – in order to provide the illusion of such a system.
When the balance between slow storage and fast memory is out of whack, syste
[...]Check out my new repo: logs_processing
Posted by Henrietta Dombrovskaya on 2025-10-20 at 10:18
I finally shared the set of functions that I use to process pgBadger raw output.
There will be more documentation, I promise, but at least the code is there, along with two of many presentations.
PgPedia Week, 2025-10-12
Posted by Ian Barwick on 2025-10-20 at 06:15
Scaling Postgres
Posted by Ibrar Ahmed in pgEdge on 2025-10-20 at 04:38
Postgres has earned its reputation as one of the world's most robust and feature-rich open-source databases. But what happens when your application grows beyond what a single database instance can handle? When your user base explodes from thousands to millions, and your data grows from gigabytes to terabytes?This is where Postgres scaling becomes critical. The good news is that Postgres offers multiple pathways to scale, each with its own advantages and use cases. Since pgEdge Distributed Postgres and pgEdge Enterprise Postgres are 100% Postgres, all of the scaling techniques that follow also apply to your pgEdge cluster.In this comprehensive guide, we'll explore three fundamental scaling approaches:
- vertical scaling
- (enhancing the power of your current server)
- horizontal
- scaling
- (adding additional servers)
- and
- high availability
- strategies (ensuring your system remains online in the event of failures).
Postgres Architecture
Before diving into scaling strategies, it's crucial to understand how Postgres works under the hood. Unlike some databases that use threads, Postgres uses a process-based architecture. This design choice has significant implications for how we approach scaling.The Postgres Process Family
When Postgres runs, it creates several specialized processes, each with a specific job:- Postmaster
- : The master process that coordinates everything else
- Backend processes
- : One for each client connection - they handle your SQL queries
- WAL Writer
- : Manages the Write-Ahead Log, ensuring data durability
- Checkpointer
- : Periodically flushes data from memory to disk
- Background Writer
- : Smooths out disk I/O by gradually writing data
- Autovacuum Workers
- : Clean up dead rows and maintain database health
- Replication processes
- : Handle data copying to other servers
Part 2: PostgreSQL’s incredible trip to the top with developers
Posted by Tom Kincaid in EDB on 2025-10-19 at 20:33
In August of this year, I published a blog entitled PostgreSQL’s incredible trip to the top with developers which shows how Postgres has become the most used, most loved and most desired database according to the Stack Overflow annual developer survey. In that blog I said, I want to do the series in two parts. After some thought, I have decided to make it a 3 part series. It will break down as follows:
- Part 1: The aforementioned blog was just the facts regarding Postgres becoming the most loved, most desired and most used database by developers according to the stack overflow survey.
- Part 2
Part 2: Postgres incredible journey to the top with developers.
Posted by Tom Kincaid in EDB on 2025-10-19 at 20:33
In August of this year, I published a blog entitled PostgreSQL’s incredible trip to the top with developers which shows how Postgres has become the most used, most loved and most desired database according to the Stack Overflow annual developer survey. In that blog I said, I want to do the series in two parts. After some thought, I have decided to make it a 3 part series. It will break down as follows:
Part 1: The aforementioned blog was just the facts regarding Postgres becoming the most loved, most desired and most used database by developers according to the stack overflow survey.
Part 2
Create and debug PostgreSQL extension using VS Code
Posted by Sergey Solovev on 2025-10-18 at 15:27
In this tutorial we will create PostgreSQL extension ban_sus_query. It will check that DML queries contain predicates, otherwise will just throw an error.
Next, in order not to mislead up, I will use term
contribfor PostgreSQL extension, and forextensionfor PostgreSQL Hacker Helper VS Code extension.
This tutorial is created not only for newbies in PostgreSQL development, but also as a tutorial for VS Code extension PostgreSQL Hacker Helper. Documentation for it you can find here.
Creating initial files
PostgreSQL has infrastructure for contrib building and installation. In short, contribs have a template architecture - most parts are common for all.
So, for faster contrib creation we will use command: PGHH: Bootstrap extension.

It will prompt us to bootstrap some files - choose only C sources.
After that we will have our contrib files created:

Initial code
Query execution pipeline has 3 stages:
- Parse/Semantic analysis - query string parsing and resolving tables
- Plan - query optimization and creating execution plan
- Execution - actual query execution
Our logic will be added to the 2 stage, because we must check real execution plan, not Query.
This is because after multiple transformations query can be changed in multiple ways - predicates can be deleted or added, therefore we may get a completely different query than in the original query string.
To implement that we will create hook on planner - planner_hook. Inside we will invoke actual planner and check it's output for the existence of predicates.
Starter code is the following:
#include "postgres.h" #include "fmgr.h" #include "optimizer/planner.h" #ifdef PG_MODULE_MAGIC PG_MODULE_MAGIC; #endif static planner_hook_type prev_planner_hook; void _PG_init(void); void _PG_fini(void); static bool is_sus_query(Plan *plan) { /* ... */ return false; } static PlannedStmt * ban_sus_query_planner_hook(Query *parse, const char *query_string,Revising the Postgres Multi-master Concept
Posted by Andrei Lepikhov in pgEdge on 2025-10-18 at 10:39
One of the ongoing challenges in database management systems (DBMS) is maintaining consistent data across multiple instances (nodes) that can independently accept client connections. If one node fails in such a system, the others must continue to operate without interruption - accepting connections and committing transactions without sacrificing consistency. An analogy for a single DBMS instance might be staying operational despite a RAM failure or intermittent access to multiple processor cores.
In this context, I would like to revisit the discussion about the Postgres-based multi-master problem, including its practical value, feasibility, and the technology stack that needs to be developed to address it. By narrowing the focus of the problem, we may be able to devise a solution that benefits the industry.
I spent several years developing the multi-master extension in the late 2010s until it became clear that the concept of essentially consistent multi-master replication had reached a dead end. Now, after taking a long break from working on replication, changing countries, residency, and companies, I am revisiting the Postgres-based multi-master idea to explore its practical applications.
First, I want to clarify the general use case for multi-master replication and highlight its potential benefits. Apparently, any technology must balance its capabilities with the needs it aims to address. Let's explore this balance within the context of multi-master replication.
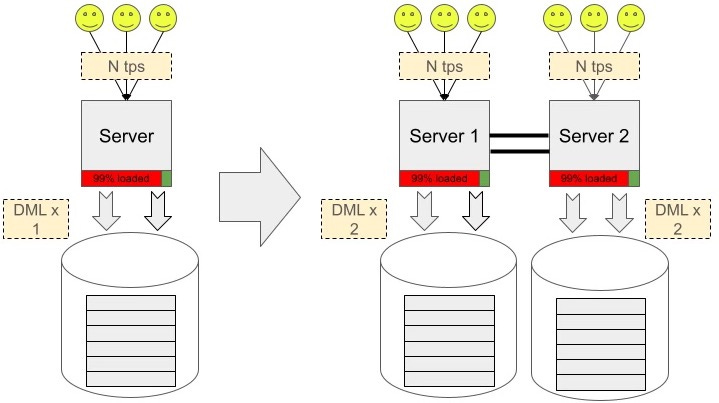
Typically, clients consider a multi-master solution when they hit a limit in connection counts for their OLTP workloads. They often have a large number of clients, an N transaction-per-second (TPS) workload, and a single database. They envision a solution that involves adding another identical server, setting up active-active replication, and doubling their workload.
[...]
PGConf.EU 2025: The Underground Map for Database Nerds
Posted by Mayur B. on 2025-10-17 at 22:57

PGConf.EU schedule can feel like a parallel query gone wild, so many great talks but not enough CPU.
I built this guide to help my fellow database nerds skip the overwhelm and enjoy the best prod-DBA focussed sessions without a single deadlock.
Follow this path, and you’ll cruise through the conference like a perfectly tuned autovacuum.
🗓️ Wednesday, Oct 22 — Warming Up the Buffers
11:15 – 12:05 in Omega 1 : Don’t Do That!
Laurenz Albe reminds us that every bad Postgres habit comes with a sequel called “incident report.”
13:05 – 13:35 in Omega 2 : Parsing Postgres Logs the Non-pgBadger Way
Kaarel Moppel shows that pgweasel and caffeine can out-analyze any dashboard.
13:45–14:35 in Alfa : Improved Freezing in Postgres Vacuum: From Idea to Commit
Melanie Plageman walks us through the icy depths of tuple immortality.
14:45–15:35 in Omega 2 : Operational Hazards of Running PostgreSQL Beyond 100 TB
Teresa Lopes shares real stories and engineering lessons from scaling Postgres into the terabyte realm, where every decision costs you.
16:05–16:55 in Omega 2 : What You Should Know About Constraints (and What’s New in 18)
Gülçin Yıldırım Jelínek explores how new enhancement to constraints in PG 18 make data integrity both smarter and more flexible.
17:05–17:55 in Omega 1 : Hacking pgvector for Performance
Daniel Krefl reveals clever hacks to push filtering and indexing deeper into pgvector for faster, leaner similarity searches.
🧱 Thursday, October 23 — The Day of Observability and Enlightenment
09:25–10:15 in Omega 2 : Unified Observability: Monitoring Postgres Anywhere with OpenTelemetry (Yogesh Jain)
Learn how to unify metrics, logs, and traces across cloud, containers, and bare-metal Postgres instances using OpenTelemetry to build scalable, vendor-agnostic observability.
10:25–10:55 in Omega
Is Postgres Read Heavy or Write Heavy? (And Why You Should You Care)
Posted by David Christensen in Crunchy Data on 2025-10-17 at 12:00
When someone asks about Postgres tuning, I always say “it depends”. What “it” is can vary widely but one major factor is the read and write traffic of a Postgres database. Today let’s dig into knowing if your Postgres database is read heavy or write heavy.
Of course write heavy or read heavy can largely be inferred from your business logic. Social media app - read heavy. IoT logger - write heavy. But …. Many of us have mixed use applications. Knowing your write and read load can help you make other decisions about tuning and architecture priorities with your Postgres fleet.
Understanding whether a Postgres database is read-heavy or write-heavy is paramount for effective database administration and performance tuning. For example, a read-heavy database might benefit more from extensive indexing, query caching, and read replicas, while a write-heavy database might require optimizations like faster storage, efficient WAL (Write-Ahead Log) management, table design considerations (such as fill factor and autovacuum tuning) and careful consideration of transaction isolation levels.
By reviewing a detailed read/write estimation, you can gain valuable insights into the underlying workload characteristics, enabling informed decisions for optimizing resource allocation and improving overall database performance.
Read and writes are not really equal
The challenge here in looking at Postgres like this is that reads and writes are not really equal.
- Postgres reads data in whole 8kb units, called blocks on disk or pages once they’re part of the shared memory. The cost of reading is much lower than writing. Since the most frequently used data generally resides in the shared buffers or the OS cache, many queries never need additional physical IO and can return results just from memory.
- Postgres writes by comparison are a little more complicated. When changing an individual tuple, Postgres needs to write data to WAL defining what happens. If this is the first write after a checkpoint, this could inc
Configuring Linux Huge Pages for PostgreSQL
Posted by Umair Shahid in Stormatics on 2025-10-17 at 10:28
Hacking Workshop for November 2025
Posted by Robert Haas in EDB on 2025-10-16 at 13:36
For next month, I'm scheduling 2 or 3 discussions of Matthias van de Meent's talk, Improving scalability; Reducing overhead in shared memory, given at 2025.pgconf.dev (talk description here). If you're interested in joining us, please sign up using this form and I will send you an invite to one of the sessions. Thanks to Matthias for agreeing to attend the sessions, and to Melanie Plageman for agreeing to serve as host. (I normally host, but am taking a month off. We will also skip December due to the end-of-year holidays.)
Sanitized SQL
Posted by Jeremy Schneider on 2025-10-16 at 03:57
A couple times within the past month, I’ve had people send me a message asking if I have any suggestions about where to learn postgres. I like to share the collection of links that I’ve accumulated (and please send me more, if you have good ones!) but another thing I always say is that the public postgres slack is a nice place to see people asking questions (Discord, Telegram and IRC also have thriving Postgres user communities). Trying to answer questions and help people out can be a great way to learn!
Last month there was a brief thread on the public postgres slack about the idea of sanatizing SQL and this has been stuck in my head for awhile.

The topic of sensitive data and SQL is actually pretty nuanced.
First, I think it’s important to directly address the question about how to treat databases schemas – table and column names, function names, etc. We can take our cue from the large number industry vendors with data catalog, data lineage and data masking products. Schemas should be internal and confidential to a company – but they are not sensitive in the same way that PII or PCI data is. Within a company, it’s desirable for most schemas to be discoverable by engineers across multiple development teams – this is worth the benefits of better collaboration and better architecture of internal software.
Unfortunately, the versatile SQL language does not cleanly separate things. A SQL statement is a string that can mix keywords and schema and data all together. As Benoit points out in the slack thread – there are prepared (parameterized) statements, but you can easily miss a spot and end up with literal strings in queries. And I would add to this that most enterprises will also have occasional needs for manual “data fixes” which may involve basic scripts where literal values are common.
Benoit’s suggestion was to run a full parse of the query text. This is a good idea – in fact PgAnalyze already maintains a standalone open-source library which can be used to directly leverage Postgres’
[...]Prairie Postgres Birthday Meetup
Posted by Henrietta Dombrovskaya on 2025-10-16 at 03:04
Huge thanks to everyone who came to the Prairie Postgres meetup and celebrated our first birthday with us! Thank you for helping me to rehearse my talk, and for your insightful questions!
Here are my presentation slides:
And we had a cake!
Top posters
Number of posts in the past two months
 Nikolay Samokhvalov (Postgres.ai) - 9
Nikolay Samokhvalov (Postgres.ai) - 9- Jeremy Schneider - 8
- Ian Barwick - 7
- Hubert 'depesz' Lubaczewski - 5
- Hans-Juergen Schoenig (Cybertec) - 5
- Dave Stokes - 4
- Laurenz Albe (Cybertec) - 4
- Umut TEKIN (Cybertec) - 4
- Henrietta Dombrovskaya - 4
- Mayur B. - 3
Top teams
Number of posts in the past two months
- Cybertec - 21
- EDB - 12
- Crunchy Data - 11
- postgres-contrib.org - 9
- Postgres.ai - 9
- Stormatics - 8
- pgEdge - 7
- Xata - 5
- Percona - 4
- Fundación PostgreSQL - 2
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.