
概述
电商场景中,卖家为获取流量,常常出现重复铺货现象,当用户发布上传图像或视频时,在客户端进行图像特征提取和指纹生成,再将其上传至云端指纹库对比后,找出相似图片,杜绝重复铺货造成的计算及存储资源浪费。

该方法基于图像相似度计算,可广泛应用于安全、版权保护、电商等领域。
摘要
端上的图像相似度计算与传统图像相似度计算相比,对计算复杂度及检索效率有更高的要求。本文通过设计实验,对比三类图像相似度计算方法:感知哈希算法、基于局部不变性的图像相似度匹配算法以及基于卷积神经网络的图像相似度算法,权衡其在计算复杂度及检索效率方面的优劣,最终选取 Hessian Affine 进行特征提取,SIFT 特征描述生成指纹,作为端上的图像相似度计算模型。
关键词:图像相似度计算、特征提取、计算复杂度、检索效率
引言
图像相似度计算在当前的云计算处理方式,会将客户端数据上传至云端,进行图像、视频检索相似度计算等一系列复杂逻辑处理后将结果反馈给终端,虽然在计算能力上云端优势明显,但该方式同时存在严重的存储、计算资源及流量的浪费且无法满足实时性要求。
随着手机计算能力的提升,一种显而易见的方式是将部分数据在客户端进行处理后,再将有价值的数据上传云端存储及进一步处理。对于电商场景中的重复铺货现象,可在用户发布上传图像、视频时,在客户端进行图像相似度计算,做到实时反馈,对于重复图像及视频不进行云端存储,避免了存储及计算资源的浪费。
图像检索算法的基本步骤包括特征提取、指纹生成和相似度匹配。业界常用的图像相似度计算方法大致分为三类,传统的感知哈希算法、基于局部不变性的图像相似度匹配算法以及利用深度学习算法进行的图像相似度计算方法。
1.传统的 hash 算法
自 2011 年百度借助 TinEye 发布百度识图后不久,google 发布了类似的以图搜图图片搜索服务,“感知哈希算法”在图像搜索过程中发挥了重要作用。大致流程如下:

1.1 感知哈希算法理论简介:
- 均值 hash: 通过对原始图像进行压缩(8*8)和灰度处理后计算压缩后的图像像素均值,用 8*8 图像的 64 个像素与均值对比,大于均值为 1,小于均值为 0,得到的 64 位二进制编码即为原图像的 ahash 值。算法速度快,但精确度较低。
- 差异 hash:与均值 hash 相比,差异 hash 同样要进行图像压缩和灰度处理,然后用每行的前一个像素与后一个像素对比,大于为 1,小于为 0,来生成指纹信息。算法精确度较高,速度较快。
- 感知 hash:通过对原始图像进行压缩(32*32)和灰度处理后计算压缩,对其进行离散余弦变换后,用 32*32 图像的前 8*8 像素计算均值,8*8 像素值大于均值为 1,小于均值为 0,得到 64 位指纹信息为原始图像的 phash 值。算法精准度较高,速度较差。
根据以上三种算法可计算出两张图像响应的 hash 值,利用两张图像 hash 值得汉明距离,可判别出其相似程度,其中汉明距离越大,相似度越低,汉明距离越小,相似度越高。
1.2 各个算法之间的抗干扰能力对比
从视频内容中选取两组测试集,通过设计抗干扰能力实验,对三种经典感知哈希算法进行对比。
测试集 1:

结果对比
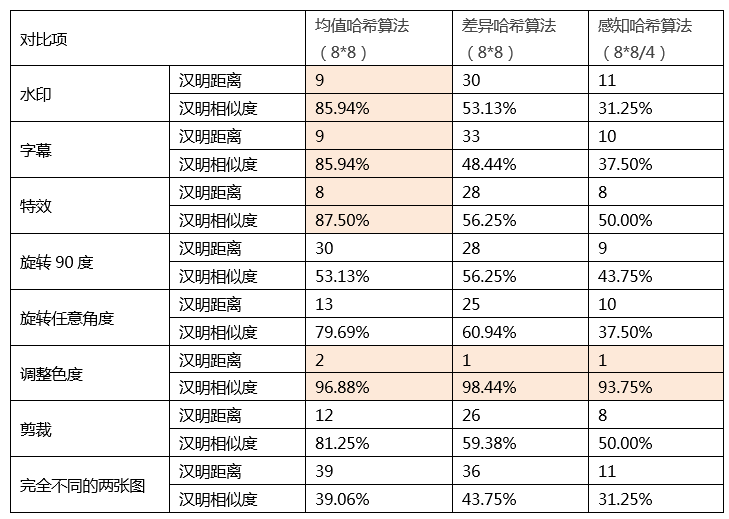
测试集2

结果对比
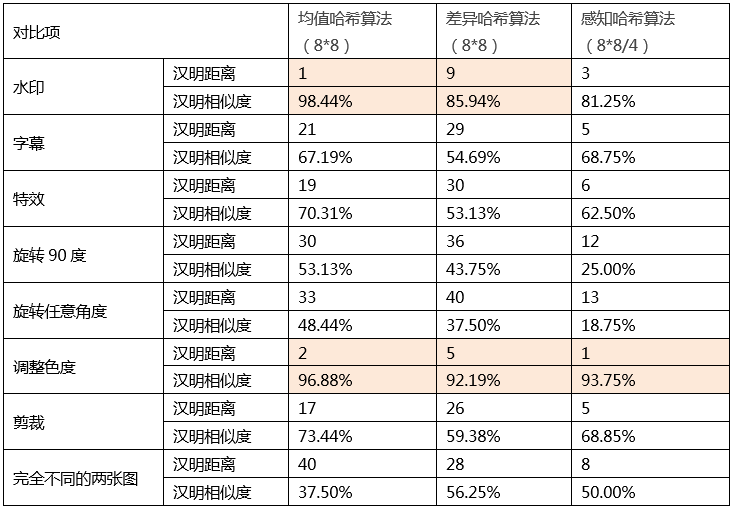
通过实验结果发现Hash 在图像相似度计算上,准确度较低,无法满足实际业务需求。
2.利用卷积神经网络计算图片相似度
2.1 端到端的方式
利用卷积神经网络计算相似度时,一种方法是直接采用端到端的方式,利用卷积层提取两张图片的特征,再用全连接层输出两张图片的“匹配度”。可参考 [1] 2015 年 CVPR 文章: 《Learning to Compare Image Patches via Convolutional Neural Networks》,相关中文解释可参考 [2] : http://blog.csdn.net/hjimce/article/details/50098483
该方法对于少量图像相似度计算优势明显,但不适用于从大量图像中进行相似度匹配的场景,如视频检索。通常,视频检索大致步骤如下:
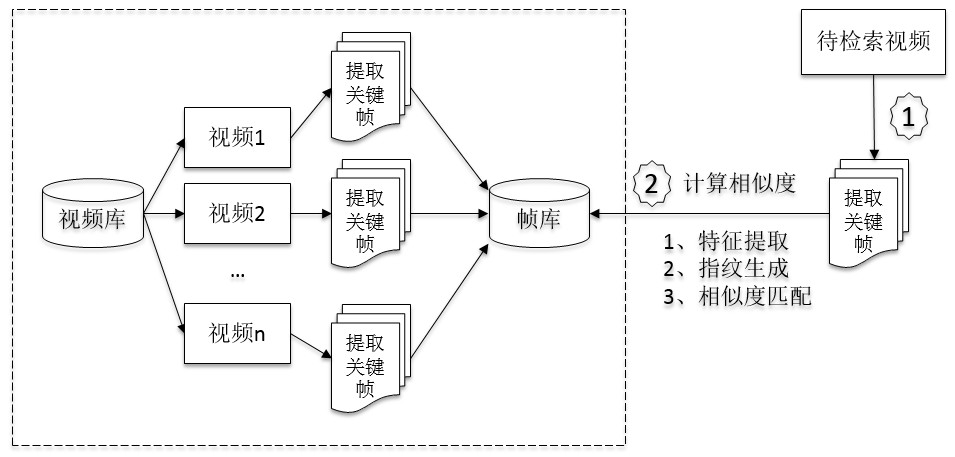
假设视频库中的存量视频有1 万个,每个视频抽取10 张图片,则帧库有10 万张图片,一次视频查询需要的比对次数为:10 x 100000 = 100 万次。
因此,尽管该方法对于图像相似度计算有较高的准确性,但在进行视频检索时计算量过大。
2.2 提取中间产物方式
由于卷积操作的本质即为特征提取,卷积层输出的矩阵天然代表各种特征,通过对两张图片的特征矩阵进行相减,计算差值平方和(或者其他方式)得到的数值作为两张图片的相似度判断依据,即为利用卷积神经网络进行图像相似度计算的第二种方式。
利用预训练好的 VGG16 模型来做测试,网络结构如下(不带全连接层):
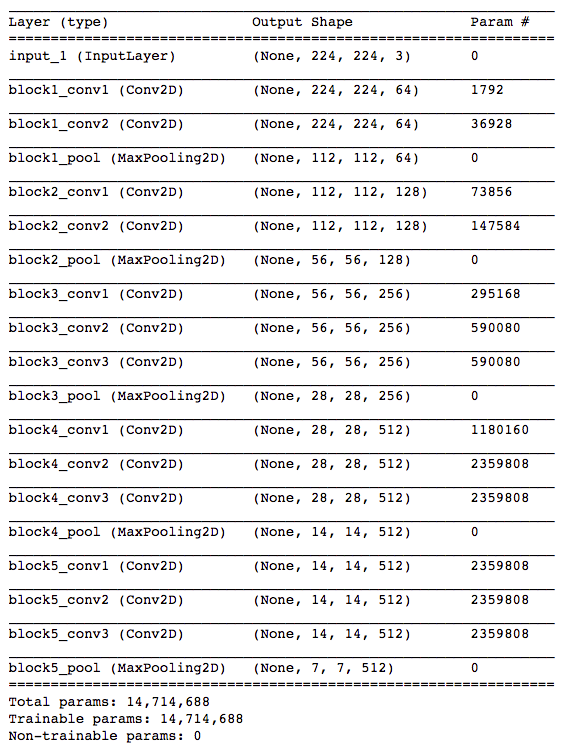
以 block5_pool 输出的结果作为目标产物(也可以用其它层),可以看到这一层输出的是形状为 (7,7,512) 的矩阵, 我们先用一组图片(来源网络)做测试,来验证输出的结果是否大致符合预期:

以上六张测试图片分别为:原图、加少量文字、修改少量底部、底部裁剪、修改底部一半、完全不同的另一张图片。
对每张图片用卷积模型计算得到 7x7x512 形状的数组后,分别计算第一张图片与后面五张图片的特征数组差值的平方和,并将结果归一化处理以方便观察,结果如下:
Diff 1 - 2: 2
Diff 1 - 3: 128
Diff 1 - 4: 182
Diff 1 - 5: 226
Diff 1 - 6: 377
从观测结果中可以看出,第一张图片与其后的图片差异越来越大的。并且 2 和 377 这两个值代表非常相似和完全不同的图片,具有一定辨识度。
进一步设计实验,用视频测试裁剪、加字幕、亮度调整、旋转、以及完全不一样的另一个视频等抗干扰能力。

针对视频的diff 计算方式为:每个视频每隔1 秒抽一帧图片,循环比对两个视频每个对应位置的图片帧,计算差异值,最后除以帧数得到平均差异。对于两个帧数不一致的情况,以较少帧为准,多出来的帧不处理。图片间的差异值计算方式同上,结果如下:
Diff 0 - 1: 6
Diff 0 - 2: 4
Diff 0 - 3: 2
Diff 0 - 4: 22
Diff 0 - 5: 26
从实验结果可以看出,对于裁剪、字幕、亮度调整的情况,差异值都在同一个数量级上,明显小于不同视频的情况,但是对于旋转的情况,该方法无效。
3.基于局部不变特征的相似度匹配算法
除了基于哈希和基于卷积神经网络的相似度匹配算法外,局部特征检测算法在相似度计算、图像检索、物体识别等领域具有重要意义。相对于像素级的全局特征,局部特征在描述图像特征时更加灵活,其中 SIFT(Scale-invariant feature transform)是比较常用的,具有较好的尺度不变性,即使改变旋转角度或者拍摄角度,仍然能够得到较好的检测效果。
3.1 抗干扰能力测试
用 OpenCV+Python,对测试图片提取 SIFT 特征:

进一步测试同样的裁剪、旋转等情况的特征点匹配情况:
裁剪:

字幕+ 改变大小:

亮度调整:

旋转90 度:
不同视频:

从测试结果上看,SIFT 做特征检测具有良好的抗干扰能力。
3.2 检索效率测试
初步确定采用局部不变特征来做特征提取后,需要做进一步的测试:搭建测试集,构建特征提取、检索系统,以测试准确率、召回率等指标。通过参考 2017 年 Araujo 和 Bernd Girod 的论文:《Large-Scale Video Retrieval Using Image Queries》,基于其工程进行测试。
数据集准备:
- 图片库:取线上 1000 个视频,对每个视频每隔 1 秒抽一张视频帧图片,作为总图片库。
- 待查询图片:定义 7 种图片变换方式:旋转、拉伸、调整亮度、裁剪、加字幕、无处理,每种变换生成 100 个样本。每个样本的生成方式为:从 1000 个视频里随机选取一个视频,并从所有图片帧里随机取一帧。这样总共得到 700 个待查询图片。
局部特征提取包含两部分内容:特征点检测和特征点描述。
3.2.1 SIFT 特征提取 +SIFT 描述子
对所有的库存图片以及待查询图片用 SIFT 提取特征,并利用特征从检索库里检索 700 个测试样本,计算召回率和准确率如下:
对比项
召回率
准确率
F 值 (2PR/(P+R))
亮度
82.00%
8.25%
0.149948
字幕
41.00%
92.86%
0.568837
饱和度
91.00%
8.40%
0.153651
裁剪
90.00%
7.60%
0.140041
原图
93.00%
9.42%
0.171175
拉伸
89.00%
7.27%
0.134440
旋转
93.00%
8.53%
0.156358
综合
82.71%
8.76%
0.158463
结果显示准确率较低,通过观察错误结果发现,部分图片提取到的特征数目较少,甚至只有个位数,而正常图片能达到几百到上千个特征点,特征点缺失会导致检索时易匹配到错误的样本。通过设置“最低样本数”限制,当样本数大于阈值时,认为其查询结果“可信”。
经测试,将“最低样本数”阈值定为 30,并加入“排除率”指标,表示未达到最低样本数,该查询记录不可信。将特征数太少的样本排除后,再次测试结果如下:
对比项
排除率
召回率
准确率
F 值 (2PR/(P+R))
亮度
20.00%
80.00%
75.90%
0.77898
字幕
0.00%
41.00%
92.86%
0.568837
饱和度
25.00%
90.67%
62.62%
0.740753
裁剪
30.00%
88.57%
75.61%
0.815789
原图
20.00%
92.50%
92.50%
0.925
拉伸
23.00%
87.01%
40.36%
0.55144
旋转
28.00%
91.67%
85.53%
0.884901
综合
20.86%
79.78%
68.71%
0.738342
结果显示在增加了“最低样本数”和“排除率”指标后,准确率大幅度提升,但仍有 20% 左右的排除率,即有五分之一的查询是没有返回可信结果的。
3.2.2 Hessian Affine 特征提取 +SIFT 描述子
为进一步提升准确率,参考 [4] 工程描述,将 SIFT 特征点检测换成 Hessian-Affine 特征检测会有更好的效果,即先用 Hessian-Affine 检测特征点,后用 SIFT 描述子描述特征。换用 Hessian-Affine 后,测试结果如下;
对比项
排除率
召回率
准确率
F 值 (2PR/(P+R))
亮度
6.00%
80.85%
87.35%
0.839779
字幕
2.00%
60.20%
83.08%
0.698148
饱和度
4.00%
83.33%
94.12%
0.883978
裁剪
7.00%
87.10%
98.78%
0.925714
原图
2.00%
78.57%
86.52%
0.823529
拉伸
4.00%
87.50%
97.67%
0.923077
旋转
3.00%
87.63%
97.70%
0.923913
综合
4.00%
80.65%
92.43%
0.861405
结果显示,召回率和准确率均有所提升,且排除率降至 4%。
4. 结论
通过设计实验测试结果发现,基于局部不变特征做相似度计算具有良好的抗干扰能力,准确度优于传统感知哈希算法,对旋转不变性的支持优于卷积神经网络。最终权衡计算复杂度和检索效率,在端上选取 Hessian-Affine 做特征点检测,SIFT 做描述子的方式进行图像相似度计算。
5. 趋势展望
尽管基于局部特征不变性的图像相似度计算在抗干扰能力及计算复杂度上占优,但仅能表达图像浅层特性,而卷积神经网络具有多层次语义表达能力,不同层所提取的图像特征具有不同含义,低层次表达角点特征,中间层聚合角点特征表达物体部件,高层进一步表达整个物体,选择不同卷积层会提取出不同层次的特征。在计算复杂度及检索效率高要求的客户端将局部特征提取与卷积神经网络相结合互相弥补不足,突出优势,可能会带来更好的效果,未来将进一步探索。
参考:
[1] 2015 CVPR《Learning to Compare Image Patches via Convolutional Neural Networks》
[2] http://blog.csdn.net/hjimce/article/details/50098483
[3] Araujo, A. and Girod, B 《Large-Scale Video Retrieval Using Image Queries》2017
[4] https://github.com/andrefaraujo/videosearch .

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...

评论